引言
随着AB实验的普及与深入人心,很多人觉得只要做了AB实验,根据实验数据来做业务决策,就科学严谨、万无一失了。然而,事实并不是如此!为什么呢?今天的话题就是其中一个关键的影响因素:策略的长期影响和短期影响不一致的问题。
如果我们用来做决策的AB实验短期影响和长期影响不一致,这就会导致错误的业务决策。由于受到资源的限制、产品快速迭代的要求,通过短期实验数据去预测长期影响难度又非常高,很多团队在这个地方都没有做好,这也是当下实验领域研究的一个重点方向。
一、长期影响评估重要但是难度高
在AB实验的场景下,由于实验资源的限制、产品策略快速迭代的要求,一个实验通常只能观测1-2周左右,所以我们通过实验观察到的效果是一个相对短期的实验效果。但我们关心的实验效果,实际是实验的长期影响,是实验策略上线后1-2个月,甚至更长时间才能显现出的实验效果。
最理想的情况是,短期效果和长期效果是一致的。实际的情况是,由于各种各样的原因,这两者是不一致的。比如,搜索结果中加入更多广告,但是提高收入但是会慢慢失去用户,长期营收会降低;比如信息流的内容中,增加更多广告可以提高短期营收,但影响用户体验,长期来看会降低收入;比如新的推荐算法需要一定时间去学习用户的行为特征,从而长期的推荐效果比短期更好。
在非常多的产品场景中,我们都需要更加关注新策略带来的长期影响,这使得AB实验的长期影响估计成为实验领域一个非常重要的话题。但是由于受到很多因素的制约,估计实验长期影响,难度还是很高的,当前这个问题也是数据科学研究的一个重点方向。
二、导致长短期影响不一致的主要原因
导致长短期影响不一致主要有几类原因:
用户学习效应
网络效应
延迟的体验和数据反应
生态系统变化
此处对几种原因的产生机理不再赘述,详细可见《AB实验-科学归因与增长利器》书中第9章-AB实验的长期影响:
三、目前评估长期影响的主要方法
长期影响的评估方法从原理来看,目前主要有以下几类:1、一类是依赖拉长时间来观测,这一类方法包括长周期实验、holdout方法等。2、一类是通过实验设计和建模去估计长期影响,这一类方法包括后期分析法、CCD法等。3、固定群组法,就是把实验组对照组的人群的id固定下来进行长期的跟踪,这个原理比较好理解。4、代理指标法,通过对代理指标和目标指标迭代建模的方法去预测未来的目标指标,从而估计长期影响。
下面我们对这些方法中几种具有代表性的方法进行介绍。
(一)长周期实验
最简单、直接的一种做法,是把实验周期拉长。
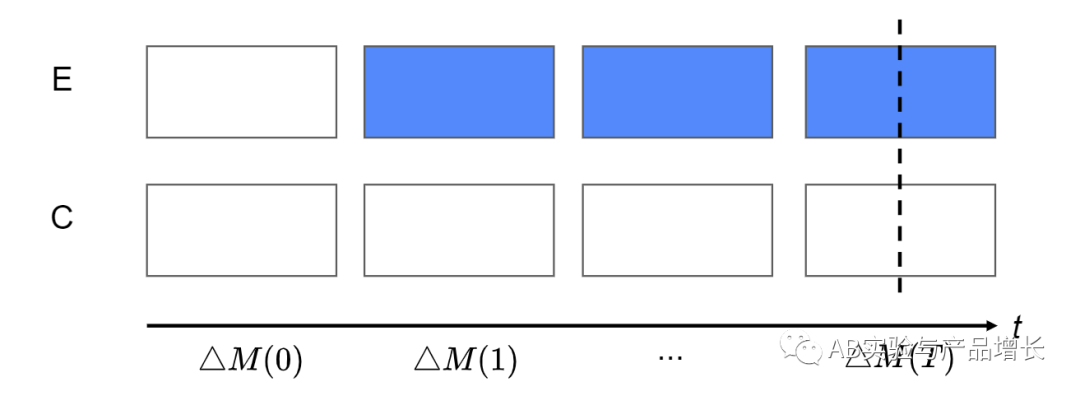
如上图所示:
E-实验组,C-对照组,t=1时刻实验组开始策略(蓝色)
t=1,实验组和对照组的差值可视为短期影响
t=T,实验组和对照组的差值可视为长期影响(T足够长)
这种方法的问题是实际操作中无法大量进行,不仅流量存在瓶颈,也无法满足产品快速迭代的诉求。所以这个方法适用于某些重大实验、重要产品迭代中,而不适用于大部分普通的实验场景。
(二)holdout实验
holdout实验法是指,一个策略前期验证过后全量上线,大盘用户都变了新策略,只保留一小部分用户(比如5%)holdout住不上该策略,长期观察这部分holdout用户与大盘用户的指标差异。
长周期实验和holdout实验有点相似但有差异,对比示意图如下:
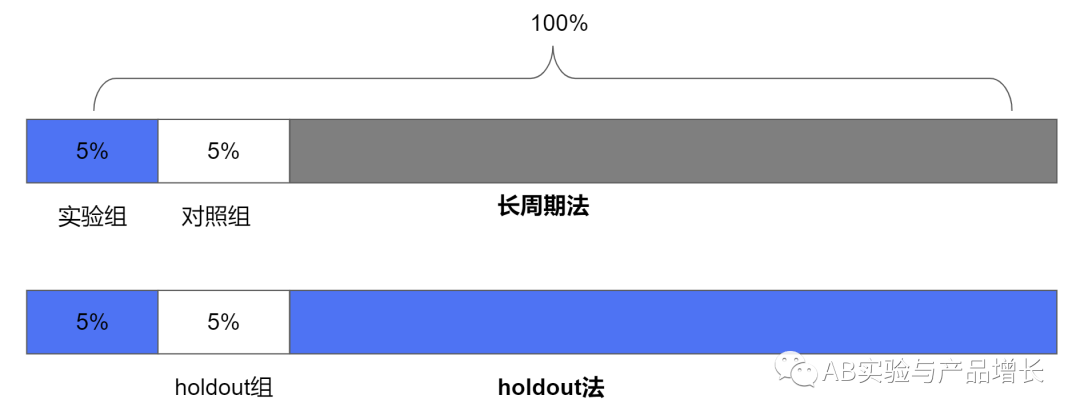
据了解,很多团队对于AB实验的长期影响的评估,也就做到长周期实验、或者holdout实验这个程度,并没有更进一步的深究和探索了。
(三)后期分析法和CCD方法
后期分析法基于一个关键洞察,两组无差异的用户(E、C)如果前期、后期策略一样,实验组(E)中间有一段时间被给予新策略(蓝色),那么实验组和对照组在后期(时刻T)的差异,就是先前实验期间的延续效应 ,即策略引起的用户行为改变,也可以理解为实验期间发生的学习效应(如下图所示)。一个策略的长期影响可以视为即刻影响加上长期的学习效应。图中t=1时刻的差值就是即刻影响,t=T时刻的差值就是长期的学习效应。
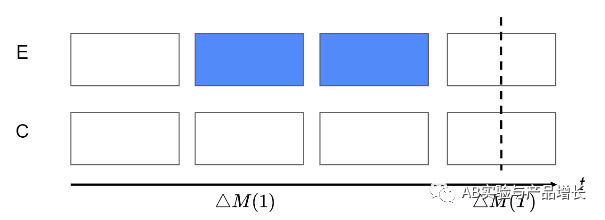
使用这个方法需要注意遗忘效应:由于E和C在T时刻后接受相同的处理,它们的行为随着时间的推移会变得越来越相似,即会发生遗忘。因此, 测量的理想时间只能是在实验组策略被撤销的短时间内进行的。为了避免这个问题,又设计了一个新的实验方式,如下图所示:
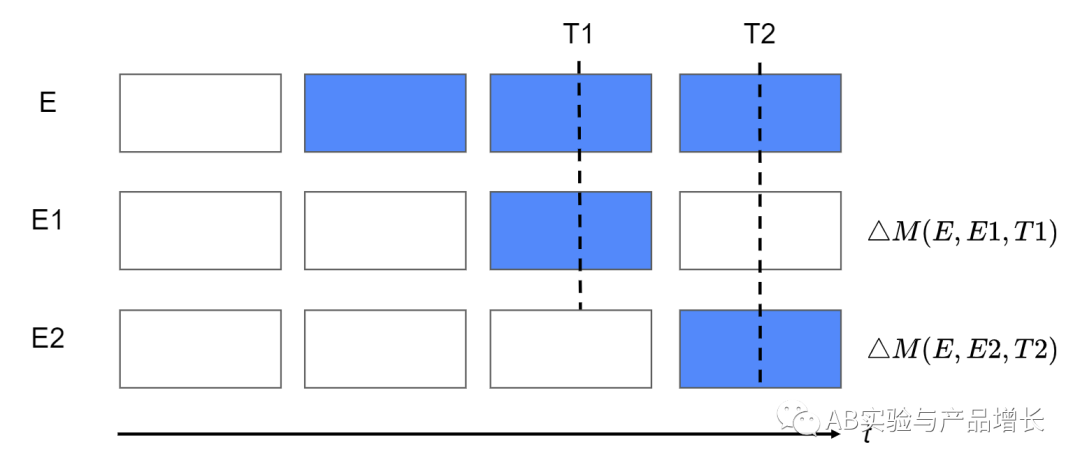
在每一个需要测量的时间段,新开启一个新的实验组,比如在T1时刻,E和E1组都在进行实验,它们之前的差别是E组更早开始实验,如果有学习效应,会在E组用户身上开始体现出来。两组的效果差 ,就是长期的学习效应。同样的,比如在T2时刻 ,E2组开始实验,两组的效果差 ,就是T2时刻的长期的学习效应,如果进行,我们会获得一系列的学习效应,可以以此来估计学习效应的大小和变化趋势。显而易见这个方法比较浪费流量。在这个基础上,又想出一个新实验方法来解决流量的问题,如下图所示:
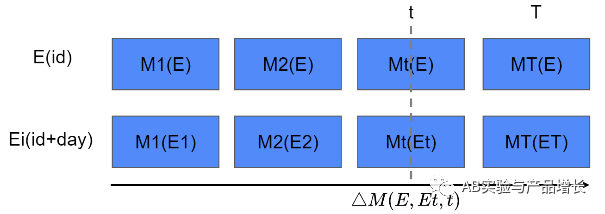
实验组E,采用id分流是固定的;实验组Ei,采用的是id+time分流,这个time可以是day,也可以是week,如果是day表示每天相当于都是新的分组,Ei中的一小部分之前已经在实验中,但是占很小的一部分,可以近似视为每天获得一个全新的分组Ei与E进行对比。表示的是E组和第t天的Et组的效果差异,这个差异也就是在第t个时刻的长期学习效应,如果为正表示,长期学习效应是正向的,用户越来越喜欢这个功能,反之则表示这个功能长期来看是负向的。
这个实验设计的核心是基于已知的离散的不同时间段用户学习效应的变化,建立参数模型,用于预测长期效应。这里首先需要假设长期效应的分布符合该参数模型,对延续效应进行建模,而且本身实验也是比较复杂的。 这个方法呢,还有一个问题,部分用户会遇到反复进出实验组的问题, 所以适用于算法类感知不明显的实验,如果UI类用户感知会比较明显,就不是很合适。
(四)代理指标预测法
有没有一种更加更普适的模型,不涉及复杂的实验设计,能够直接通过短期实验的结果,结合用户的行为,估计出策略的长期影响?这里有一个关键假设是,大部分时候用户行为改变的发生是渐变式的,而不是突发式的。如果在短周期的实验期间,我们能捕捉到这些变化,并把这些变化和我们想要观察的目标建立起某种稳定的联想,那么我们就可以通过短期的指标的变化去预测更长期的结果的变化。
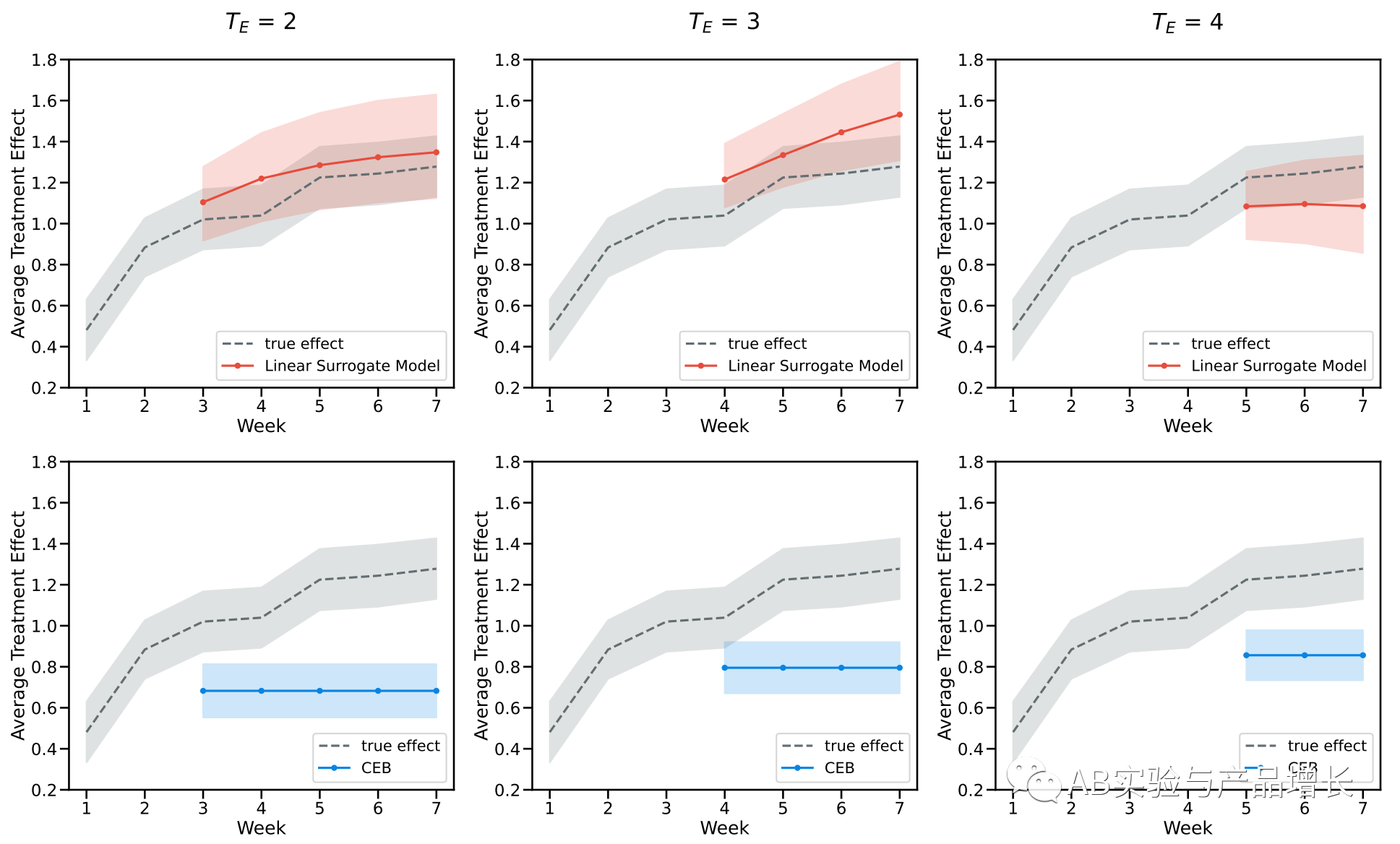
今年微信团队发表了一篇基于这个方法的实践,其核心思路如下:
(1)首先明确实验的长期目标指标Y
(2)挑选一些代理指标surrogates(结果Y也作为一种特殊代理)
对于长期指标Y和代理指标有如下的假设,t时刻的实验分组W(i,t)会影响t时刻的代理指标S(i,t)和目标指标Y(t),t时刻的代理指标会影响下一个时刻t+1时刻的代理指标S(i,t+1)和目标指标Y(t+1)。t时刻的实验分组W(i,t)不会直接影响下一个时刻的代理指标S(i,t+1)和目标指标Y(t+1)。
这个假设其实不难理解,因为实验分组一定会影响当期所有指标,这也就是我们所看到的短期实验效果。而未来的实验效果是在当前实验作用的基础上叠加产生的。

(3)训练模型:在以上的假设下,我们可以进行进一步建模:
对每个代理指标Si,以t=E时刻值为模型标签,1到E-1时刻的值为特征,训练出n个模型,然后可以以此类推,代入2到E时刻的值,预测出E+1时刻的Si值,直到获得T时刻的Si值
对于目标值Y,以t=E时刻值Y(E)为模型标签,E-1时刻的n个S值为特征,训练出模型,然后代入E时刻n个S值,得到Y(E+1),以此类推,直到获得T时刻的Y值,也就是我们希望等到目标指标的长期效果
对实验组和对照组要分别建立预测模型,获得差值就是实验带来的长期效果的增量值了。
微信实验团队在微信小程序搜索场景的实验数据如下图所示, 效果还是非常不错的: