龙芯2/Nehalem处理器架构深度对比分析
Execution
执行
在读取好参数之后,指令们就可以送入执行单元执行了,龙芯2具有两个整数执行单元和两个浮点执行单元,Nehalem则具有三个通用执行端口,每个执行端口都可以进入整数或者浮点指令;AMD K8架构则和龙芯2一样,整数单元和浮点单元具有不同的入口,并使用不同的寄存器文件。

Godson-2:执行单元
整数执行单元包括两个:ALU1和ALU2,浮点执行单元也是两个:FALU1和FALU2,它们的实现细节分别如下(基于2005年的文档):
ALU1:执行整数加/减,逻辑/移位,比较/陷阱以及分支指令,所有的指令都能在1个时钟周期内完成。
ALU2:执行整数加/减/乘/除,逻辑/移位/比较,整数乘使用全流水线设计,执行需要4个时钟周期;整数除使用了非全流水线设计的SRT(以斯维尼、罗伯逊、托克尔三个独立提出算法的人命名)迭代算法,执行延迟从4个到37个时钟周期不等。
FALU1:执行浮点加/减/绝对值/反值/转换/比较以及分支,加/减/转换指令需要4个时钟周期,其它的指需要2个时钟周期。
FALU2:执行浮点乘/除以及平方根,浮点乘采用了全流水线两位Booth编码Wallace树算法,执行需要5个时钟周期。浮点除和平方根都使用非全流水线的SRT算法(和ALU中的一样),执行延迟是4-10个时钟周期(单精度浮点除)或者4-17个时钟周期(双精度浮点除)、4-16个时钟周期(单精度浮点平方根)或4-31个时钟周期(双精度浮点平方根)。
执行单元的算法影响着处理器的性能,特别是需要相对较长执行时间的浮点运算,这方面也比较考验设计团队的实力。据说,龙芯2F还实现了一个SIMD单元。龙芯2F之前通过浮点单元来执行一种龙芯独有的双单精度浮点指令来完成一次计算两个双精度计算。
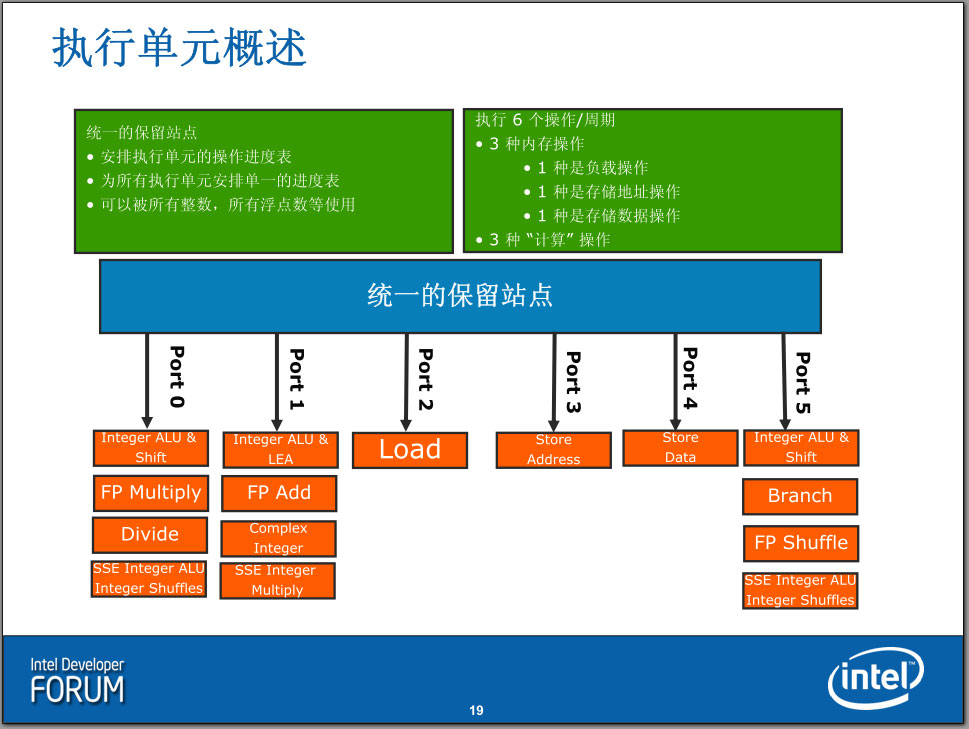
Nehalem:Superscalar Execution Unit超标量执行单元
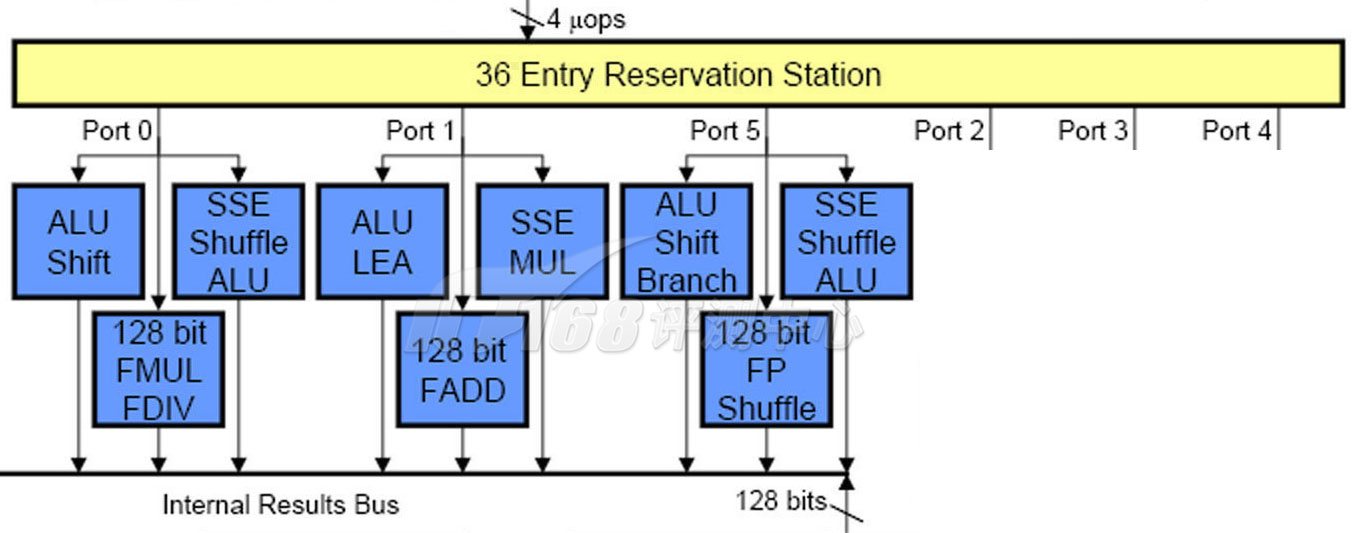
Nehalem: "Computional" Unit

