B站直播S14保障全解析:高效保障技术实践
导读
在高并发、大流量的互联网时代,如何在大型活动期间保障系统的稳定性和用户的流畅体验,是每个技术团队都面临的挑战。本文以B站直播团队在英雄联盟2024赛季全球总决赛(S14)期间的保障实践为例,详细解析了他们如何通过创新的方法和工具,实现了高效、低成本的赛事保障。
通过阅读本文,您将了解到B站直播团队在S14赛事保障中的创新实践,包括如何有效地梳理业务场景、精准地进行资源预估、提高故障演练和压测的效率,以及如何通过工具和平台的优化,实现大型活动保障的降本增效。这些经验和方法对任何需要应对高并发、大流量挑战的技术团队都具有参考价值。
背景
英雄联盟2024赛季全球总决赛是由拳头游戏所举办的第14届《英雄联盟》全球总决赛。本届比赛共有来自8个赛区的20支队伍参与,比赛时间为2024年9月25日至11月2日。在伦敦决赛现场,BLG最终以2:3惜败于T1,在此也恭喜T1荣获冠军。
S赛期间也是B站直播流量最高的时段,在本次S14中,最高同时在线人数 近千万 ,大幅超过去年同期。如何应对这流量洪峰,也给我们带来了巨大的挑战。为了保障赛事直播功能的稳定和正常运行,我们是如何做到的呢?本文将会为你一一揭秘。
目标
今年是B站直播S赛的第7年。在过去的赛事保障实践中,有一个问题一直困扰着直播团队:赛事前用于保障的研发耗时过高。S赛开赛前通常需要提前两个月进行活动保障的准备,赛事也会持续一个多月,期间会有数十到上百位研发同学共同参与保障工作。而第三季度也是直播业务的冲刺季,保障工作对研发的负担较重,这几个月时间里业务需求的交付能力会有比较明显的降低。为此,本次赛事保障由业务架构团队主导,助力研发同学提升保障效率。
挑战:
赛事保障共涉及公司内十多个团队、上百名研发人员,如何在保证低成本的前提下,实现高效的协同保障?
保障链路长且复杂,涉及众多业务,如何尽可能全面地覆盖所有保障场景,避免遗漏关键环节?
我们的目标:
主目标:保证赛事在洪峰流量期间能提供稳定的功能和流畅的用户体验。
次目标:保障工作不会降低业务需求迭代的交付速度。
尽可能降低活动赛事的研发保障成本,实现整体的效率提升。
保障流程分析
在过去几年中,直播团队积累了丰富的应对赛事的经验。总体来说,活动保障分为以下几个步骤:
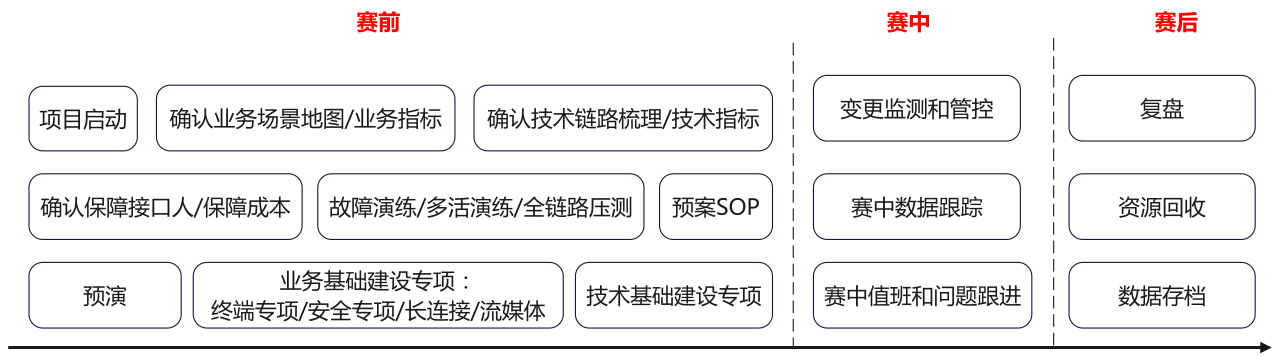
其中较为耗时的事项有:
赛前:
明确保障的功能范围并梳理场景地图(需要梳理70+场景)
确认每个场景和功能的技术链路
根据请求链路进行容量预估
分析、统计、汇总并申请资源预算
进行故障演练,包括接口故障注入和依赖的故障注入
制定压测目标、扩容、进行赛前压测验证系统容量
收集压测结果,进行容量、限流等调整
赛中:
变更管控
赛时数据回收与问题跟进
更高的要求意味着需要我们采用有别于过去的新方法、新工具来完成,接下来我们将依次介绍在每个步骤是如何实现高效保障的。
活动保障方案
场景梳理
场景定义:场景是指某个产品功能以及实现这个功能的客户端与后端的数据交互以及相关后端链路的组合。
场景元信息建模:名称、业务等级、表现、研发与测试责任人、以及5W2H(Who、When、Where、What、Why、How、How Much)
场景依赖:客户端接口、相关后端服务、数据库、缓存、消息队列、数据埋点等。
场景梳理的目标是为了更好地识别和理解业务逻辑,这也是保障的基础。过去的几年,业务场景的梳理做法是通过研发经验,将信息梳理在文档上,但这种做法容易遗漏,也容易随着业务迭代的变化而劣化。而本次保障,我们将场景信息录入在活动保障平台上统一管理。
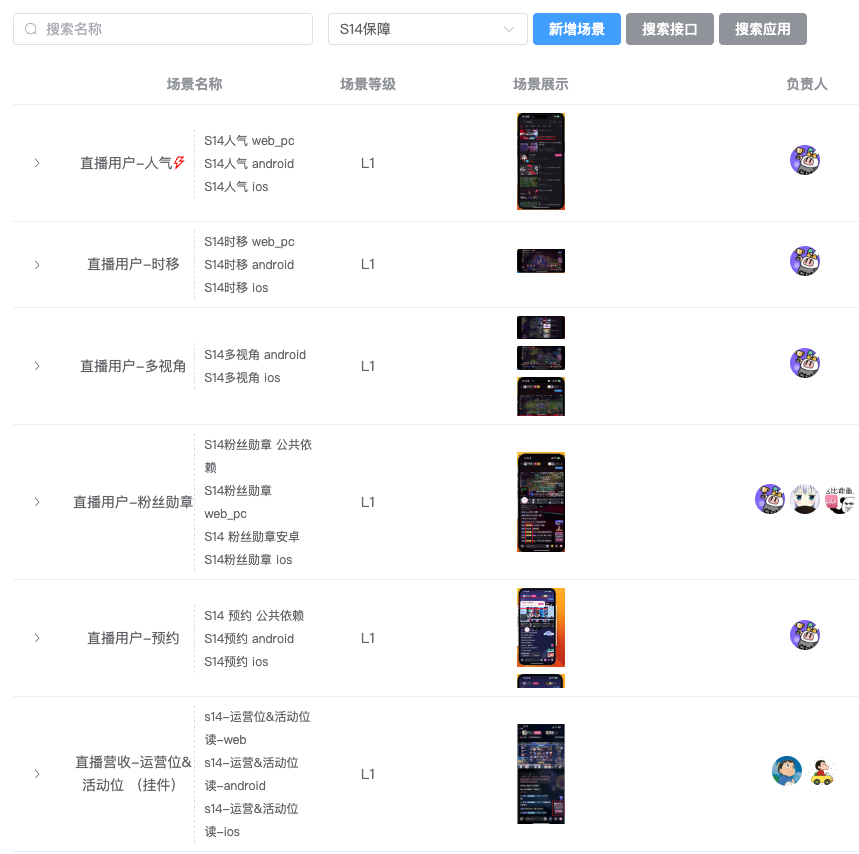

通过场景信息,让我们对技术治理和保障工作更加有针对性,避免胡子眉毛一把抓。场景梳理的难点在于如何尽可能自动化地梳理链路、降低人工梳理的成本,并保障数据链路准确,不缺不漏。
如何避免遗漏呢?
对于客户端接口:在去年S13,我们获取接口信息的方式是触发场景后利用客户端HTTP请求库的hook能力实现数据记录,但存在很多问题。对于非标准的客户端请求库以及gRPC协议的接口无法获取数据。在本次S14中,我们进行了升级迭代,在客户端网络层采用搭建虚拟专用网的方式来记录包括UDP、TCP以及上层HTTP、gRPC、WebSocket等所有的数据流量,有效的解决了数据不完整的问题。
对于后端链路:在客户端触发场景后,我们会记录本次请求路径下的后端链路情况。而在现有的数据量级下,数据全采样的成本过高,当前采样率小于1%。而为了尽可能真实完整地分析链路,我们选择在生产环境进行分析,因此需要能指定全采样的能力。为此,我们也联合基础架构部门,制定了一套特定请求全采样的方式,通过设置特定的请求信息来调整采样策略。如果单个请求不足以完整表现链路依赖,如命中缓存、则不回源存储,会导致链路不够完整,因此我们也提供了多次采样、智能聚合的能力。
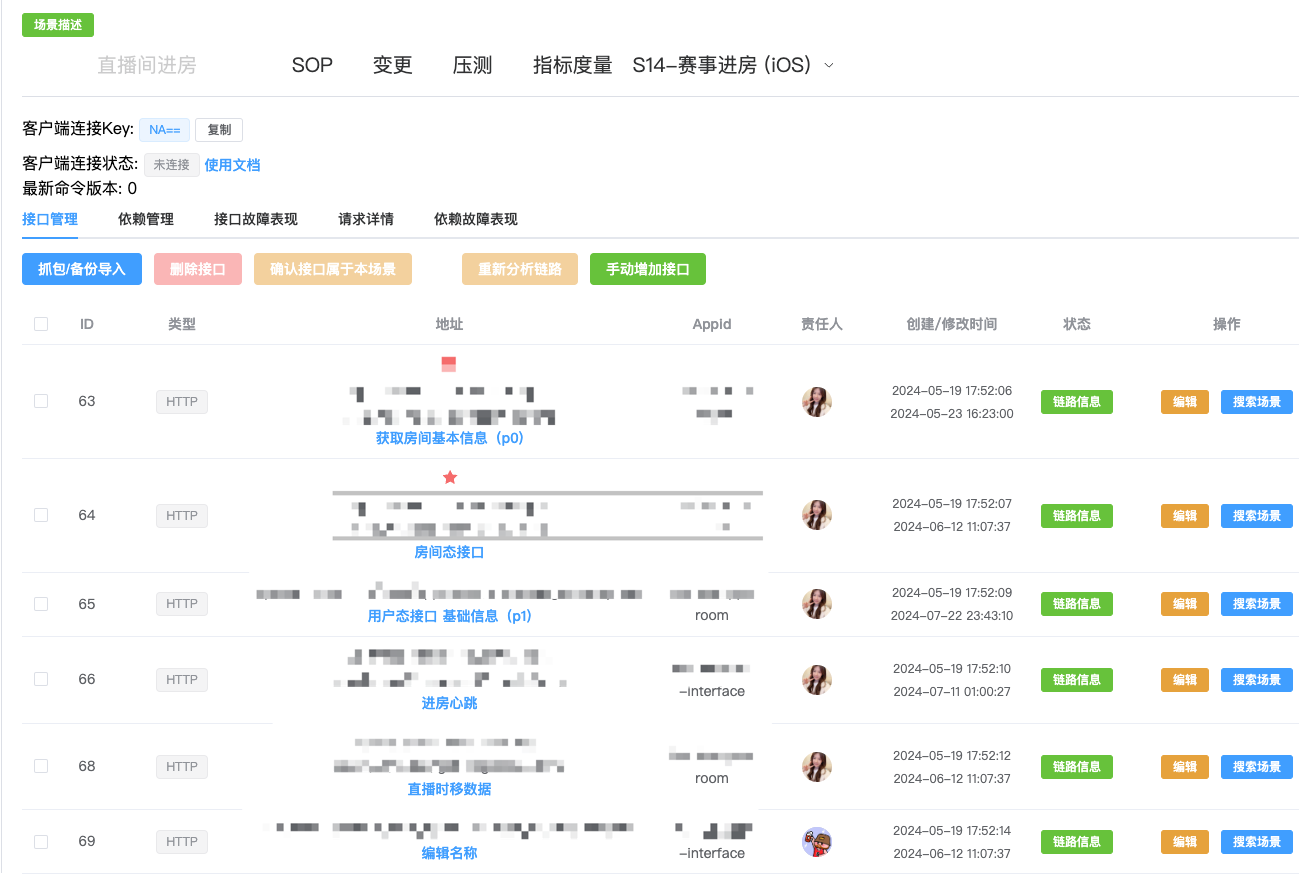
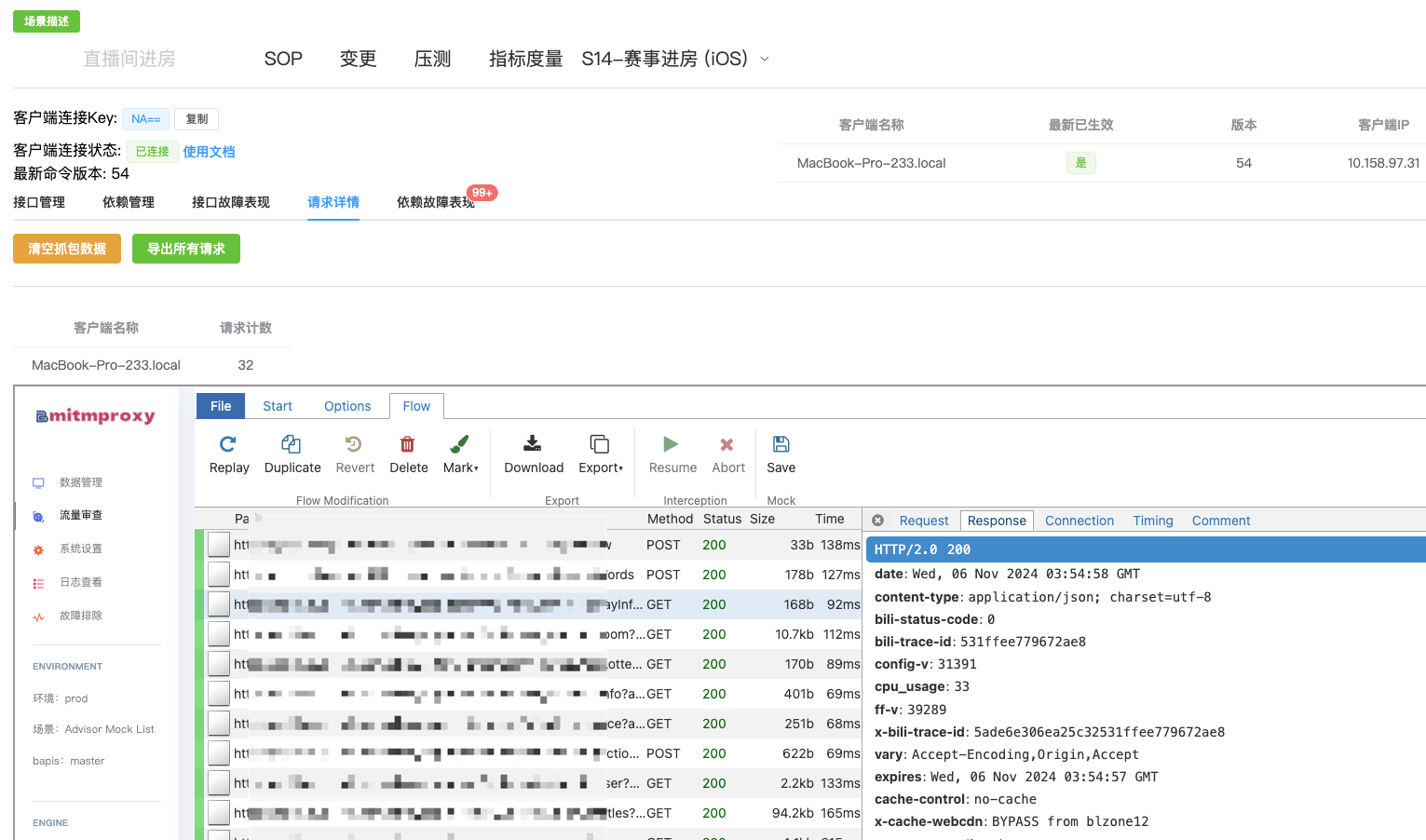

通过以上措施,我们提升了链路信息的准确性,降低了梳理成本,这也为后续的保障打下了坚实的基础。
资源预估
在准备大型活动保障时,我们通常会设置一个保障的业务目标。对于直播业务来说,通常采用PCU(Peak Concurrent Users,直播间峰值在线人数)来衡量。基于PCU目标,在保障阶段需要将其拆解为技术目标,通常拆解成每个接口的调用QPS。
在去年的S13,我们采用的是基于曝光转化率的流量预估模型,目标QPS = 曝光量 × 转化率1 × … × 转化率n / 分摊时长 = PCU × 转化率1 × … × 转化率n / 分摊时长。但这种方式因为人工参与的地方较多,梳理、统计的成本比较高,往往只能用于少量的重要接口上。
过去的预估方式:
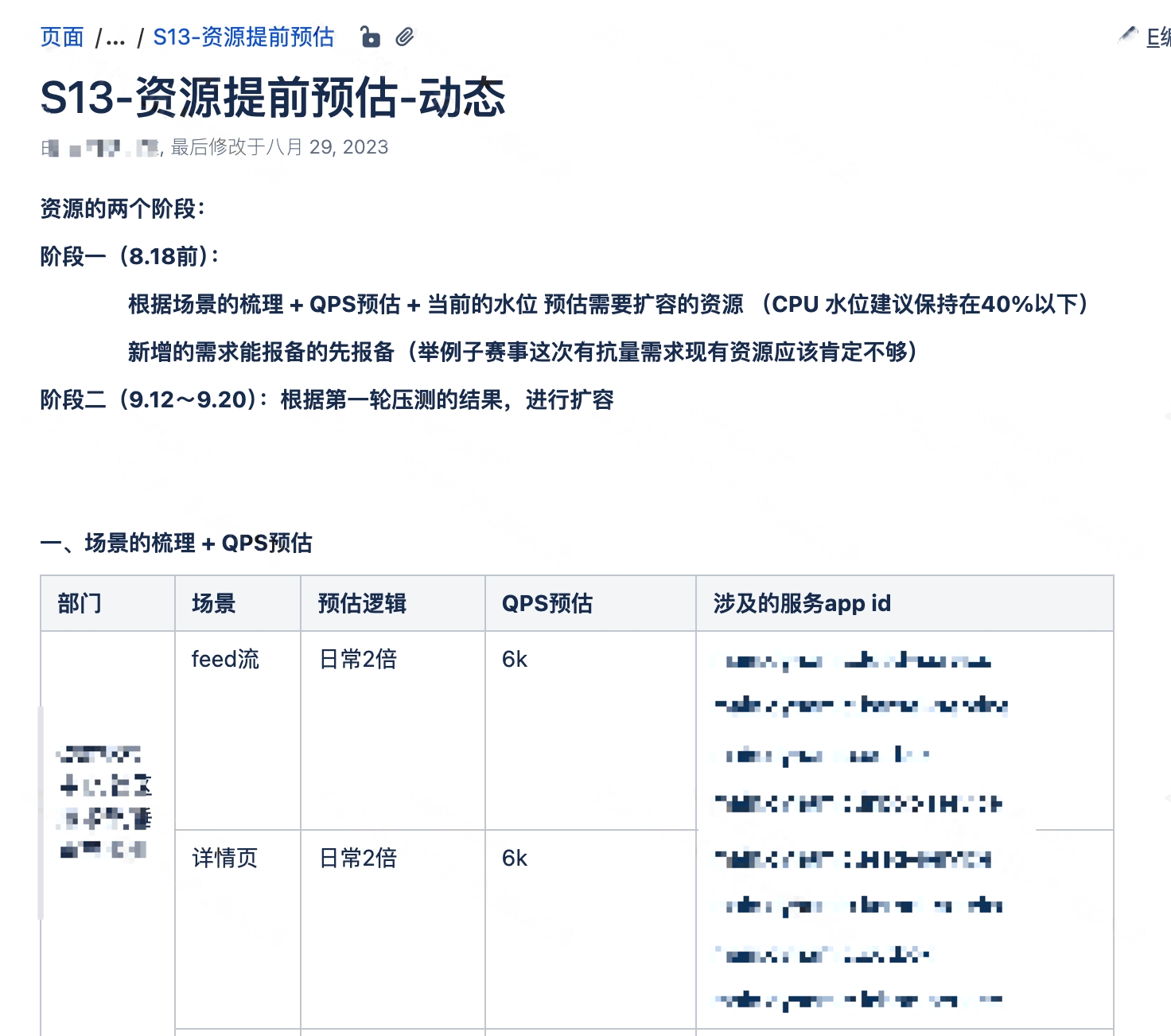

本次S14,有70+场景共300+接口需要预估,我们针对S赛事的流量特性使用了新的预估模式,对于S赛来说,分入围赛、小组赛、淘汰赛、半决赛、决赛等多个赛程,流量也是由少到多逐步递增的,因此这给我们提供了天然的预估方向,我们会记录历史每场比赛的赛中情况,分析PCU与各个技术指标的对应关系,利用小赛程的数据来预估大赛程的数据,从而得出更加真实准确的预估数据。
以如图应用为例,每增加1万 PCU,应用CPU则增加xx C,从而得出在预期PCU下需要消耗多少CPU资源。
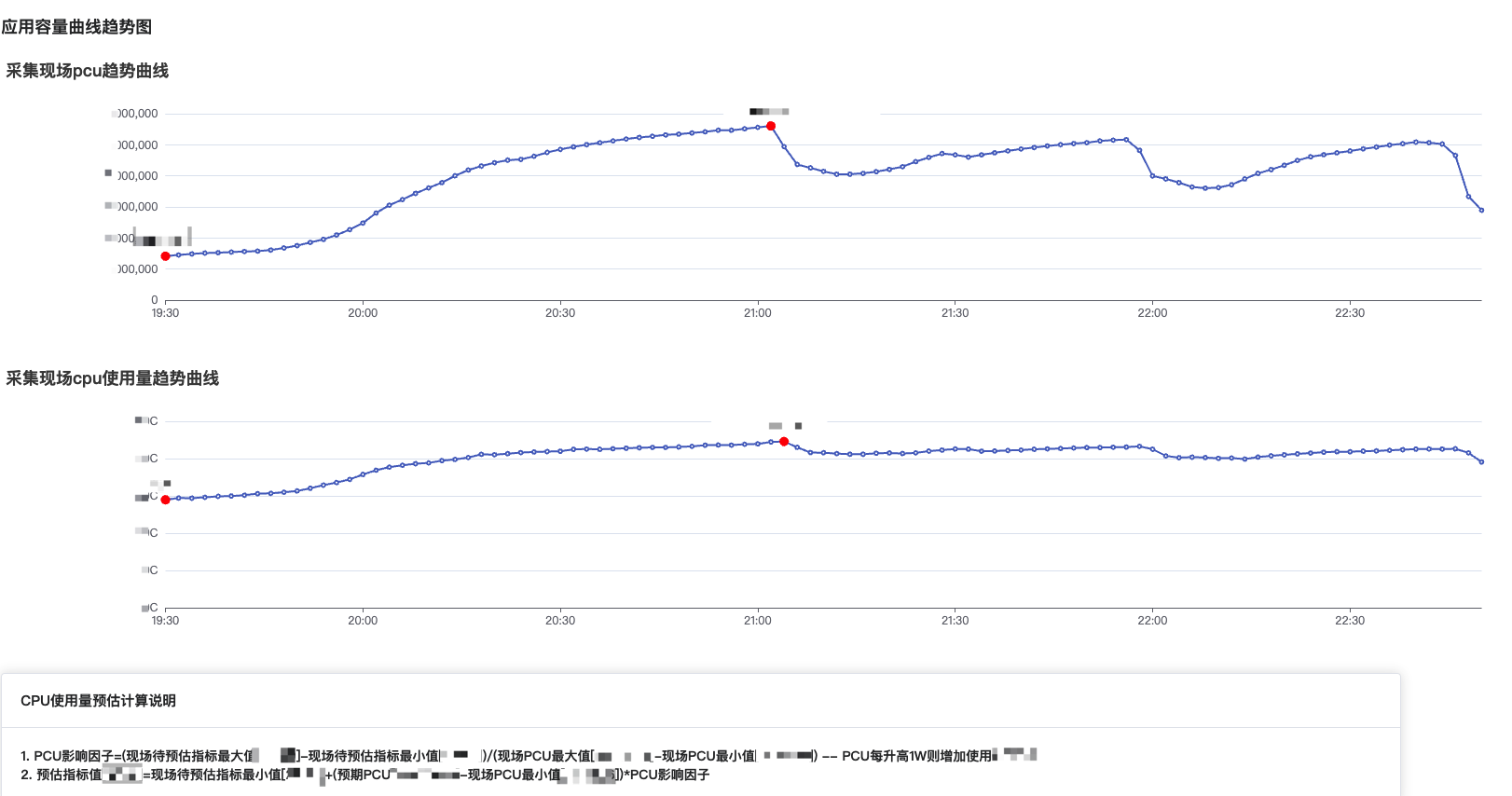
对于技术资源,我们分成了以下几类:
容器类型:CPU、内存
应用内部资源:接口容量、限流额度、MQ事件处理容量
基础资源:应用相关的数据库、缓存、带宽等
以上资源我们均使用类似的方式进行预估,有效的解决了不同资源、不同业务扩容比例不一致、成本高、难估算的问题。
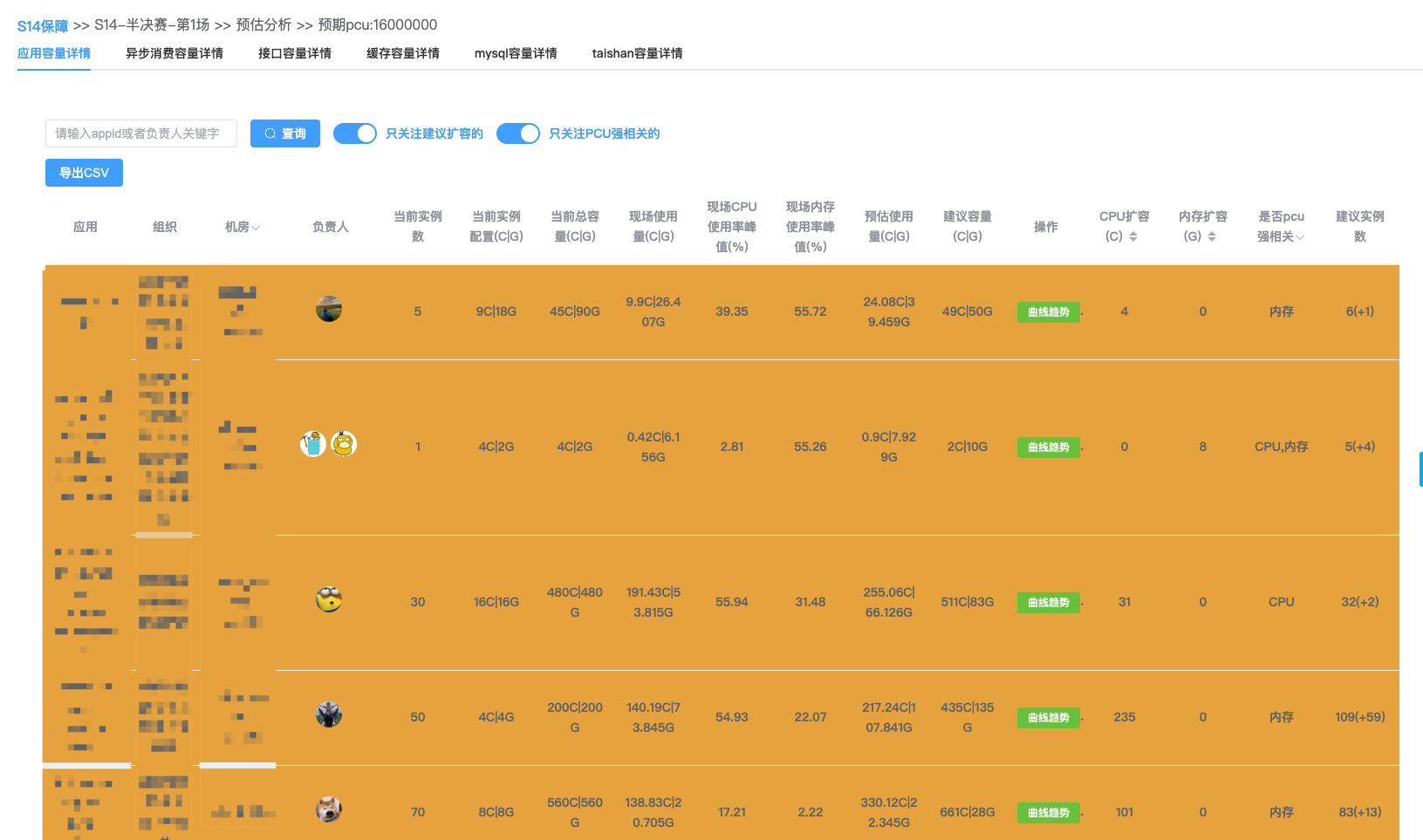

资源申请
在赛事开始前,研发后端通常需要提交资源申请进行采购扩容。往常我们采用的方法是沟通上下游数百研发,各自根据PCU去计算需要扩充的资源,再一一汇总计算,耗时耗力,沟通协调的成本巨大。本次赛事,我们基于基于资源预估的能力直接计算得出需要使用的资源总量,再减去当前业务的现有存量直接就能得出需要申请的资源总和。以此为模板,再由有特殊需求的业务方进行微调就可以完成资源申请的计算,这也大大节省了我们的梳理成本。
故障演练
故障演练是为了模拟在特定故障场景下,查看系统的表现,找出以下问题:
代码问题:是否有不合理的代码实现,将可降级的弱依赖实现成了强依赖
超时问题:是否有不合理的超时时间设置
端上体验问题:可降级的情况下,是否正确降级,端上用户体验是否能做到容错和友好提示。
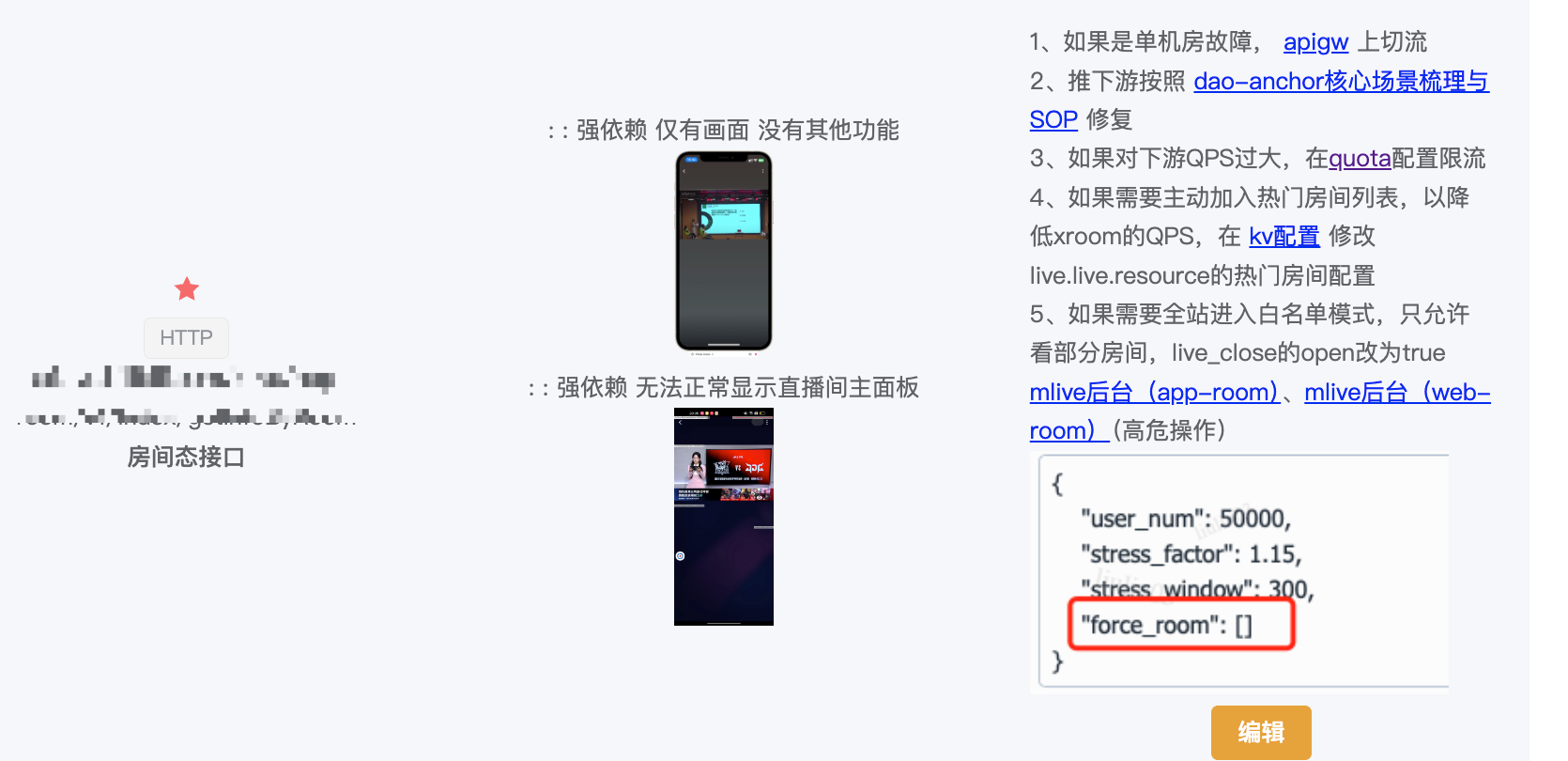
我们将故障注入分成两类,一类是端上直接访问接口的报错,另一类是内部请求或者链路依赖中的错误。
对于端上接口的故障注入:
在过去,接口故障的模拟需要去故障注入平台操作,选择应用、增加对应故障点,进行错误注入。每个接口需要耗时十多分钟才能完成一次演练。本次我们通过流量代理的能力,在保障平台上对接口直接进行拦截返回注入相关错误,并提供查看和管理故障表现的能力。通过一站式的平台集成,做到了30秒内即可完成一次演练。

【如图:不符合预期的故障表现】
在演练后,产品同学也可以复查端上表现,及时发现不符合预期的情况进行产品调整。
对于内部链路的故障演练,我们经常遇到的问题有两点:
复用困难:每次故障注入都要从头开始,历史的故障注入经验都散落在各个文档中,没有结构化的沉淀,后续难以复用
容易遗漏:难以衡量做的完整程度,仅通过做了哪些难以准确地衡量整体的覆盖程度和百分比,检查是否存在遗漏。
在本次,我们在链路信息梳理后,直接在其之上标记每个链路节点是否进行了故障注入、故障表现和强弱依赖信息。
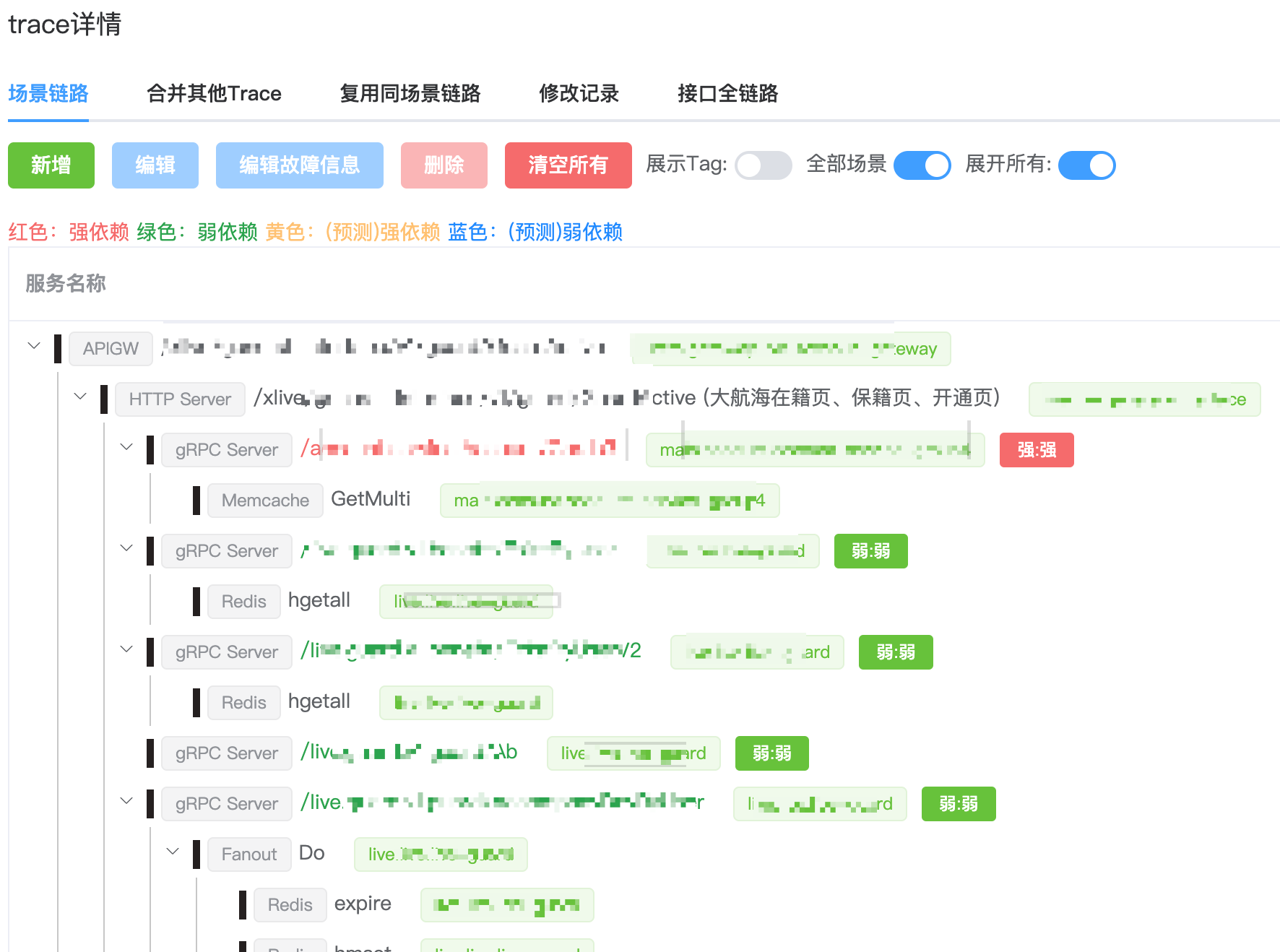
通过这种方式,可以非常直观地看到链路中有哪些还未进行故障演练,便于了解进度。而且后续链路变更可以只针对新增的链路进行补充,有效解决了之前遇到的问题。
应急预案SOP
在保障大型活动时,遇到问题只靠临场发挥是远远不够的,需要预先制定好应急响应预案,在这方面,我们遇到过以下问题:
由于项目交接或者人员变动,预案信息丢失
出问题后,SRE和其他的研发同学也难以找到预案
在本次,我们将SOP信息跟场景元信息两者进行关联,直接在场景中填写,统一格式和放置位置。
我们将其分成两种类型的预案:
场景整体的故障预案
场景关联的接口预案
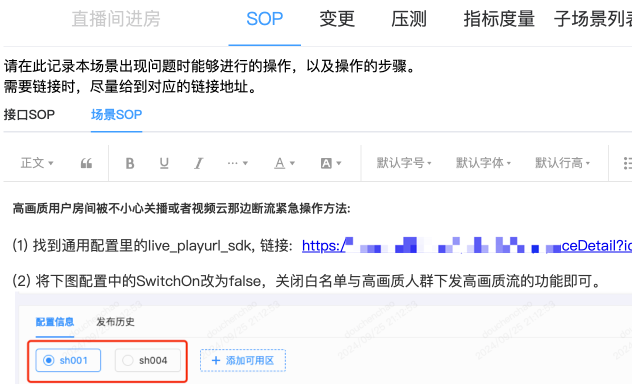
通过这种方式解决了数据散落的问题,便于信息共享。
压测
压测是为了验证系统是否能支持活动预期的流量,发现高并发下的性能隐患,是活动保障重要的一环。在执行压测保障时,主要分以下几个阶段:
压测目标制定以及压测脚本准备
压测执行和压测后的数据回收
发现的问题改进
在本次赛事,我们做了以下的优化:
1.压测目标制定:有别于往常凭经验得出的粗糙数据,这次我们结合容量预估相关的能力,通过平台基于历史数据分析自动化给出在预期PCU下每个接口的预估QPS值。
2.压测脚本准备:为了避免同一个接口重复构造压测数据,我们开发了自动查询是否存在同类压测脚本的能力,提升脚本复用程度,避免重复实现。
3.压测执行:联合基础架构部门对压测平台进行了多项易用性的优化。
4.压测结果回收:在压测后,我们新开发了压测结果回收能力,自动收集压测现场每个接口和依赖的请求情况进行数据分析,得出压测是否达到目标值的结论。
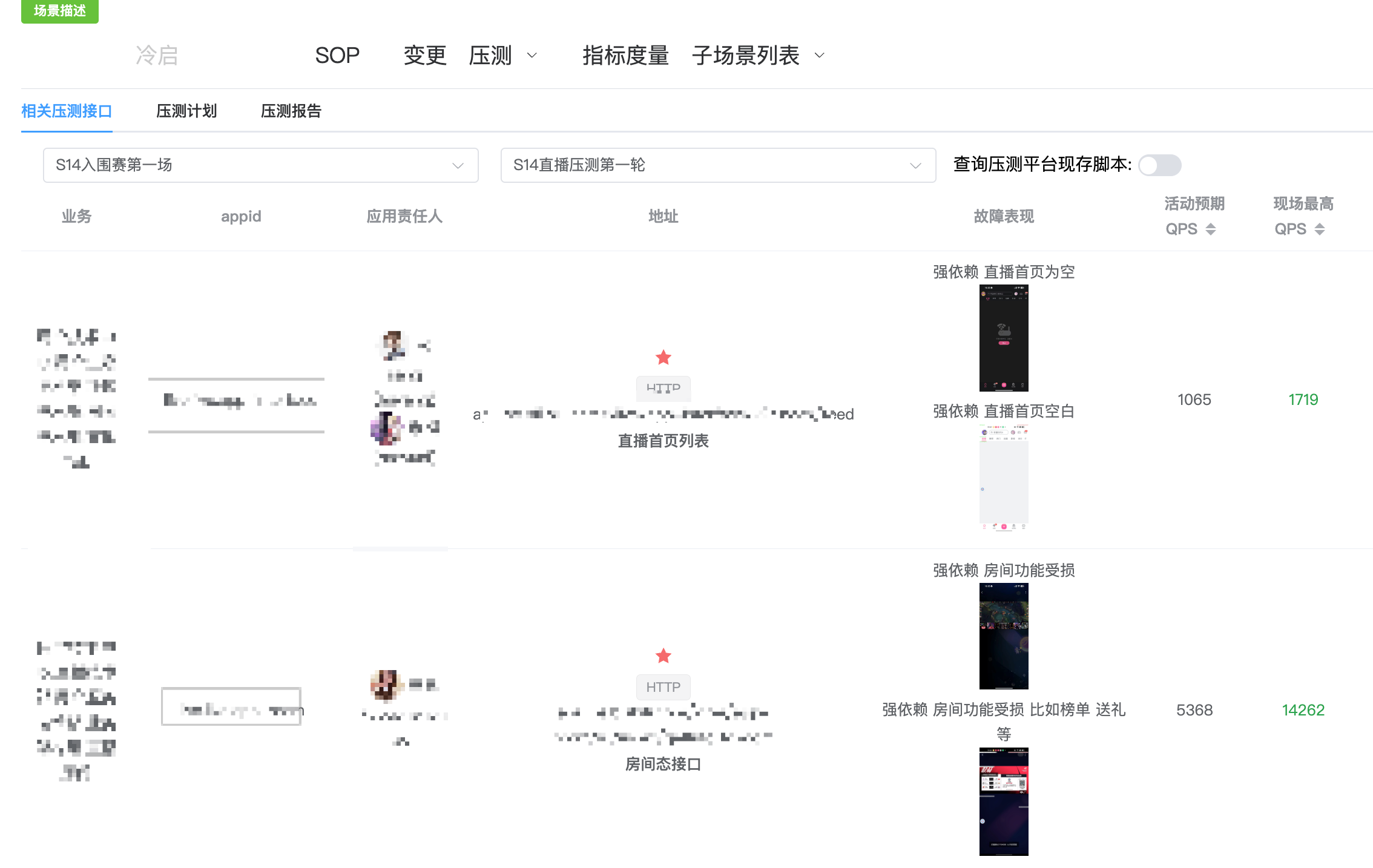
5.压测报告管理:我们支持了场景压测报告的录入和管理,便于收集和查看每个场景的压测报告信息。
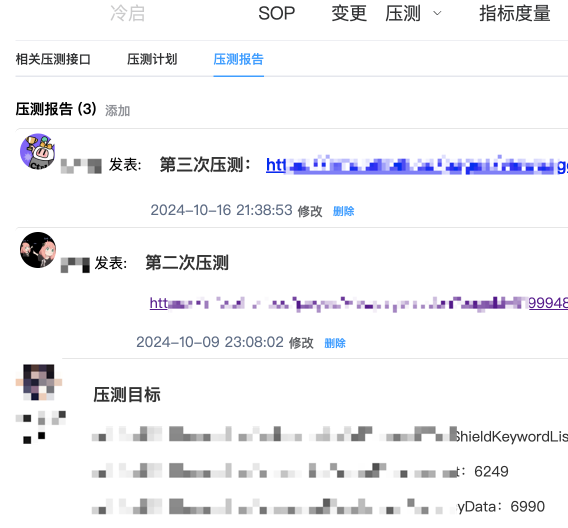
保障任务分工
S赛保障是一个横跨整个公司多个部门的大型工程,良好的协调、沟通也是必不可少的。我们采用的方式如下:
每个部门指定一个部门接口人,负责本部门相关事项的沟通协调和信息传达。在部门内部,按照内部小组拆分,每个小组指定一个熟悉业务的接口人,负责本小组内的保障事项。在具体事项执行上,尽可能利用我们本次提供的平台能力和工具,以低成本的完成保障工作。
信息同步方面,主要有以下方式:
每周进度同步会:当面同步当周保障事项的进度和风险
周报同步:各部门通过周报的形式总结汇总保障进展。
保障进度可视化
在本次保障中,受益于保障信息大多都录入到了系统,因此我们可以实现通用保障事项的进度可视化。通过保障进度看板的方式,明确地感知各个责任人的保障进展,实现统一标准、责任到人。
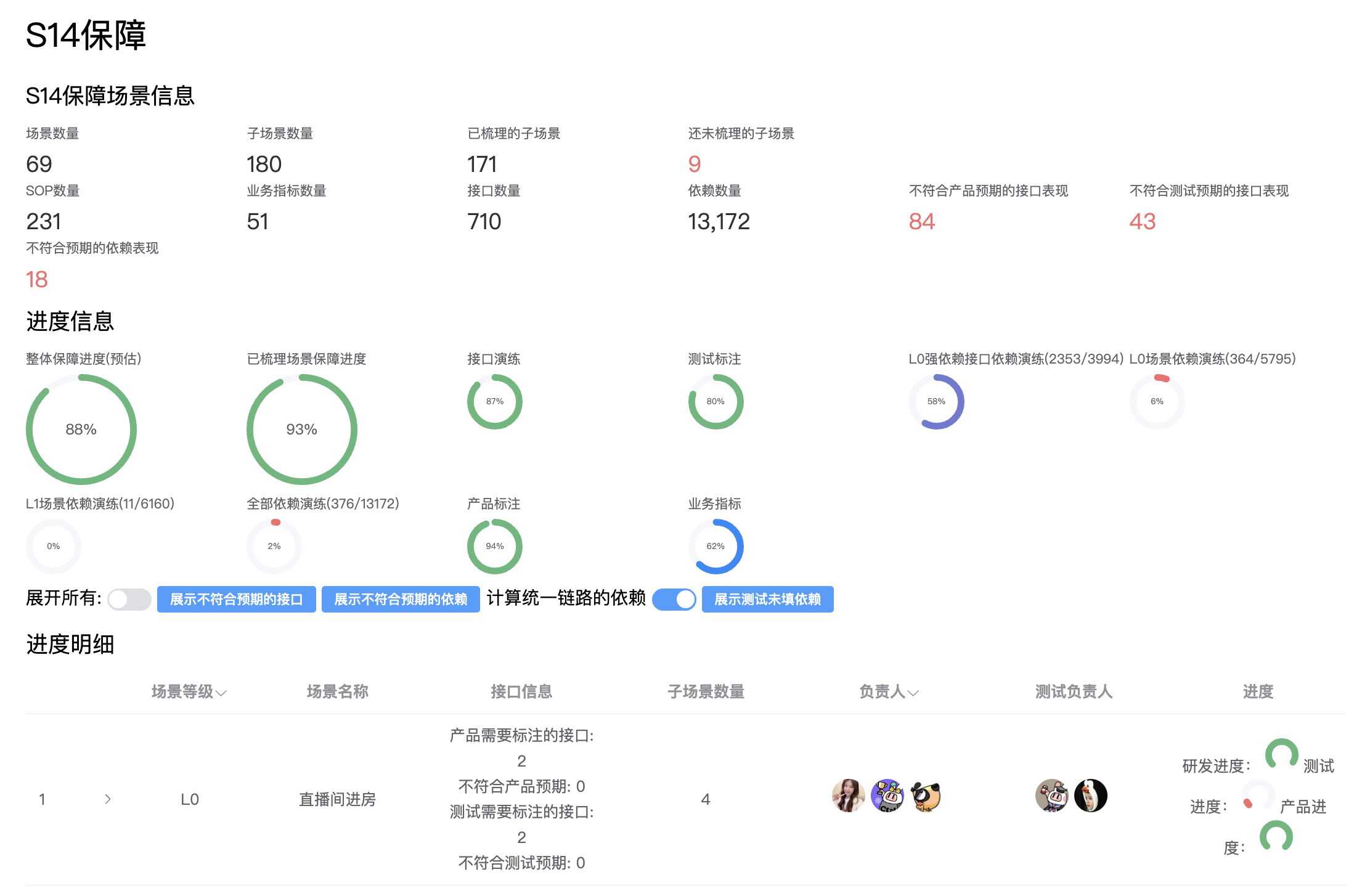

赛中变更管控
在赛事期间,为了防止非预期的变更导致线上问题,我们会开启变更管控,前置阻断发布流程,严格控制生产环境变更。
与往年不同,在今年,我们实现了按照应用维度聚合所有变更信息一站式全览的能力,将应用以及环境依赖的变更信息汇总展示,有效预防了预期外的变更问题。
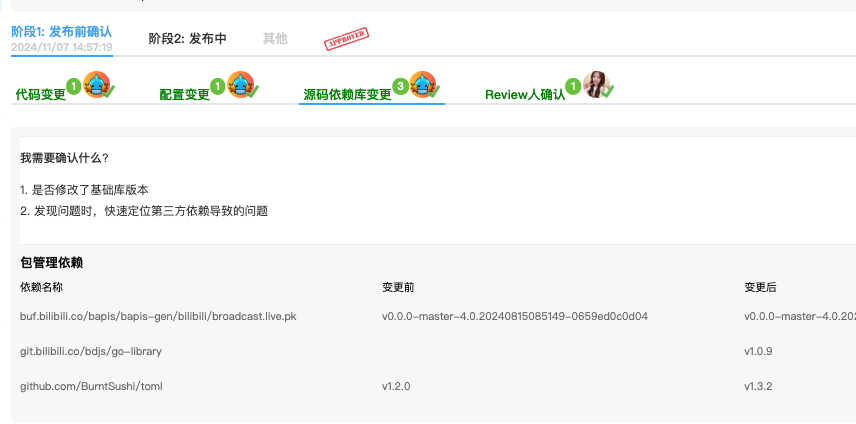
【变更流程确认】
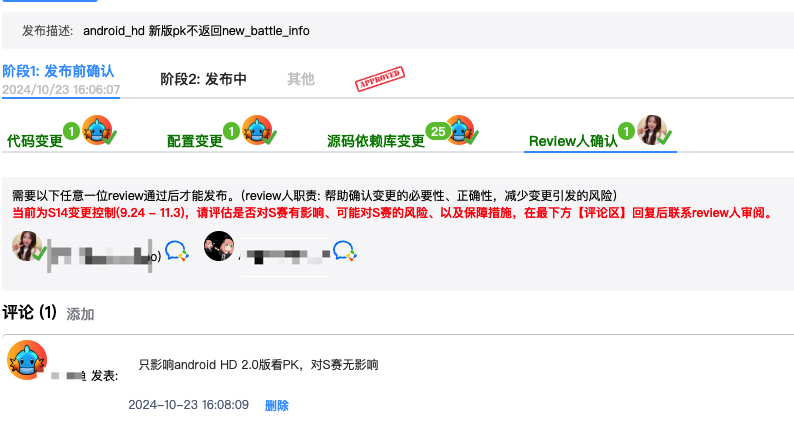
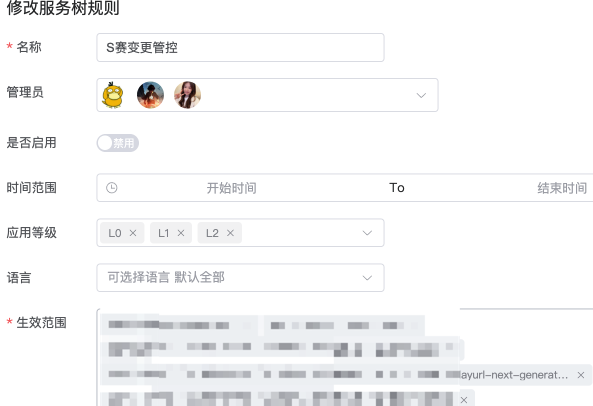
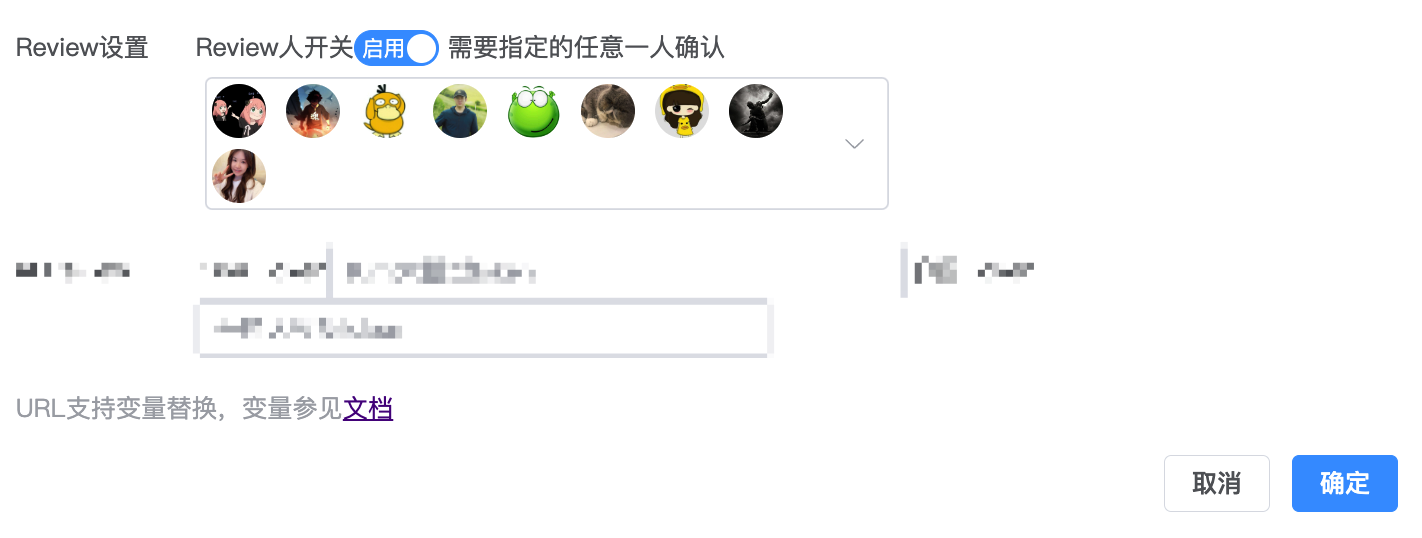
【变更管控策略创建】
本次保障我们也新实现了基于场景查看变更时间线的能力,在发生线上环境问题后,能更及时地感知到相关场景的变更内容,及时操作回滚止损。
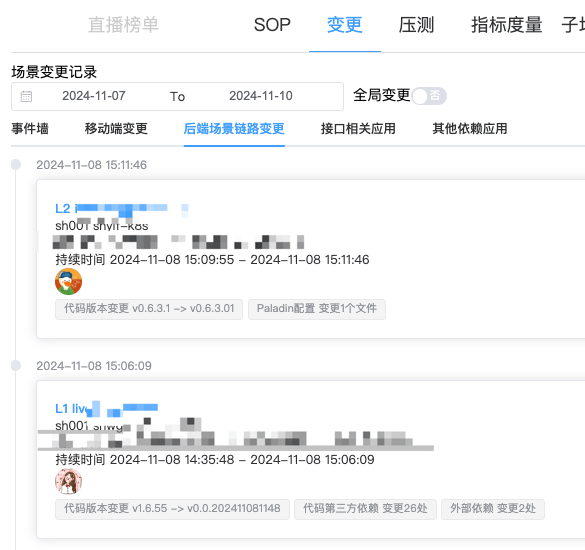
赛中数据回收
根据场景元信息相关的数据,我们与基架共同制定了赛事保障大盘,大盘包括核心指标PCU、容量情况、核心基础资源、核心场景以及相关依赖错误率与饱和度等信息,及时感知异常情况。
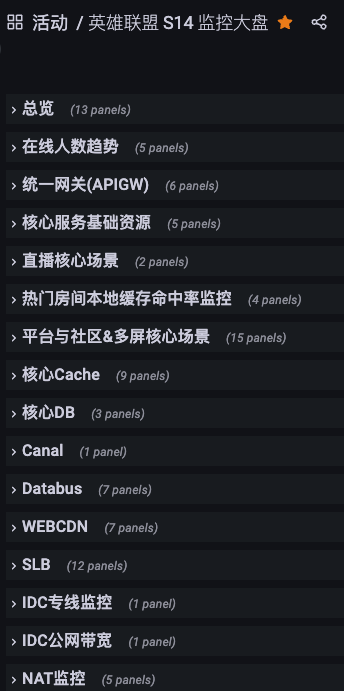
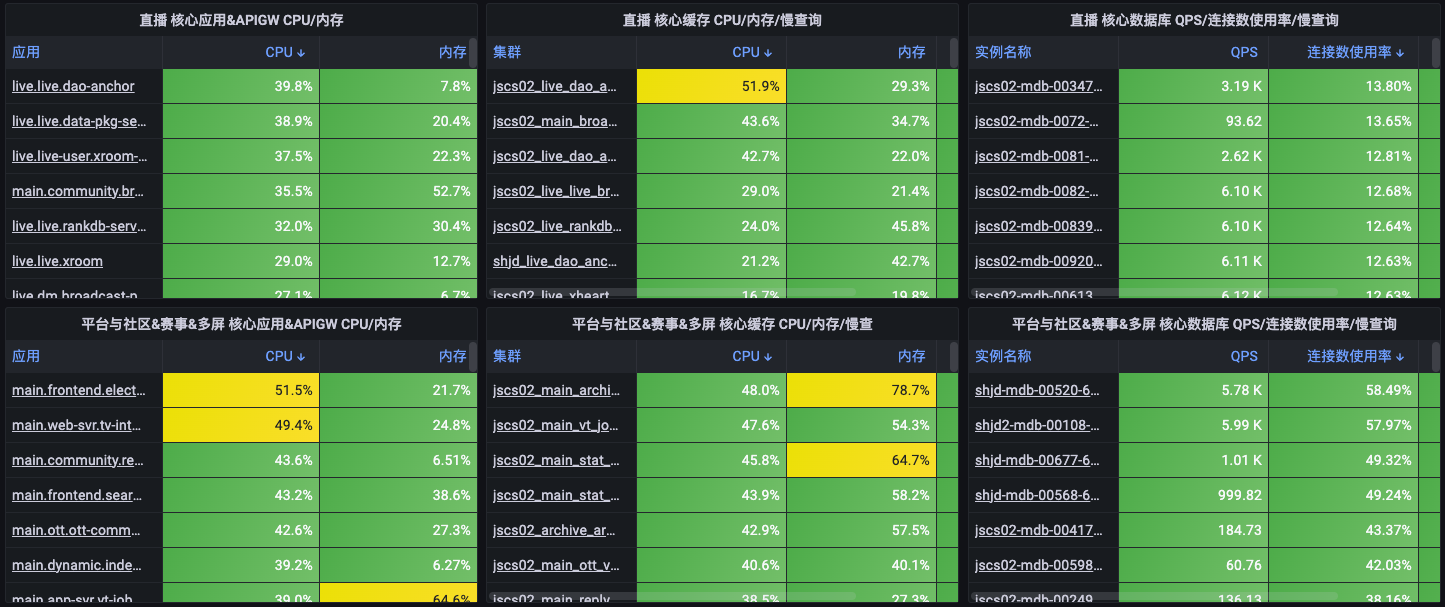
除此以外,收益与场景链路平台化,我们也实现了系统容量的自动化巡检能力。在每场比赛期间,平台会自动分析计算每个场景相关应用的容量情况, 提升了保障范围的完整度,避免遗漏应用。
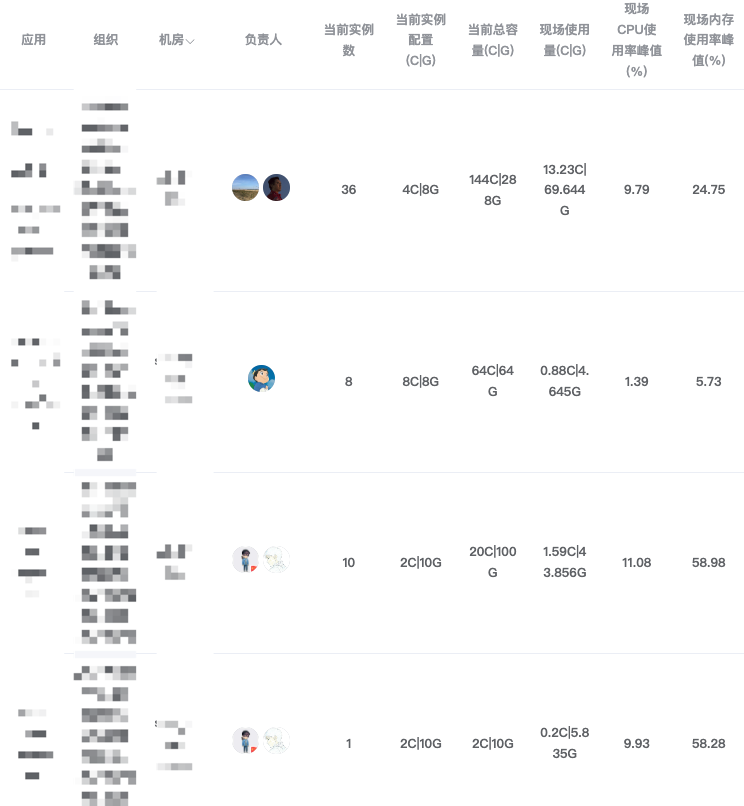
总结
通过上述各项优化,本次赛事保障直播组只用了去年的30%-40%的人员投入,扛住了比去年决赛更高的流量。赛事前后正常业务需求迭代也几乎未受到影响,为这次保障画上了圆满的句号。在此也特别感谢基础架构、测试团队、流媒体等团队的支持以及参与保障的每一位同学,S14保障能顺利进行依赖于大家的共同努力。今后我们我们也将持续提升保障的自动化程度,让直播业务走得更快更稳!

