导读:随着大数据技术的不断发展,数据治理和自治能力的提升变得尤为重要。本次分享题目为“天穹数仓自治能力新实践”。
01 大数据自治的背景
1. 大数据自治涵盖的范畴
大数据自治是一个广义的概念,涵盖从数据采集到数据接入、计算、存储、应用等一系列问题。它不仅包括数据治理,还涉及数据研发和业务发生问题的解决。大数据自治的目的是管理数据的整个生命周期,从数据产生到数据使用,再到数据销毁。
2. 业务、技术的快速发展
在过去的三十年中,数仓的发展历程经历了从传统数仓到大数据数仓,再到数字数仓的三个阶段。传统数仓如 Oracle、DB2 等,架构单一,主要处理结构化数据,数据规模较小,实时性较低。
随着 Google 三篇论文的发表,开始进入大数据时代,Hive、Hadoop/MR、Spark 等大数据数仓先后问世,产生了 Lambda、Kappa 等较为复杂的架构,处理的数据规模呈爆炸性增长,结构化、半结构化和异构化数据并存,实时性要求更高,计算也变得更为复杂。
从 2020 年至今,处于数智数仓时代,实时性和计算复杂性进一步提升,架构也更加复杂,包括流批一体、湖仓一体等,大模型也逐渐应用到数仓之中。
随着数仓技术的发展,数据处理的流程从传统的 ETL,变为大数据时代的 ELT,当前又提出了 EtLT 的概念。
3. 数仓模式演进:EtLT 崛起
EtLT 是 ELT 的扩展,其中 Extract、Load、Transform 的含义并没有改变,在此基础上提出了小 t 和大 T 的区别。针对当前数智数仓的技术生态,小 t 更紧密地结合湖仓技术,偏数据底层的工程架构,而大 T 阶段则更贴合业务,结合大模型的能力,完成偏数据上层应用的工作。
02 天穹大数据自治能力建设和落地:双引擎策略
天穹大数据自治平台采用双引擎策略,结合 SQL 智能体和传统机器学习,推动平台自治。通过构建感知力、观测力、诊断力和优化力,实现对数据相关进程的细粒度感知和智能优化。能力范围包括从数据采集、数据接入,到数据计算、存储,再到应用的全流程,从资源、计算、研效等各方面进行了优化。
最终实现了包括算子粒度的回放和诊断能力的产品化:支持 40 多个算子粒度问题的诊断,并优化了 SQL 粒度算子实现了自动 map join 功能,在 Presto 上测试效果显著,CPU 和内存节省显著。SQL 引擎自动选择方面,提升了计算性能,减少了资源浪费。作业任务资源优化方面,大幅降低了天穹上运行作业的内存和 CPU 成本。除此之外还有 SQL 智能体的优化改写等功能,这些功能在实际应用中取得了显著效果。

1. 感知力
感知力是数据系统的重要部分,决定着上层观测力、诊断力、优化力等能力体系建设的深度。天穹平台通过 JVM 级别的数据感知,已基本覆盖所有物理机和容器,每天感知的数据量达到了万亿规模。
2. 观测力
通过对采集数据进行指标的聚合和抽象,建立以健康分为核心的数据体系,实现任务进程粒度的数据上卷和下钻操作,使大数据生态的“黑盒”更加透明化,发现底层指标或异常问题。
3. 诊断力
(1)全链路诊断能力的构建
针对内部经常遇到的作业链路较长,问题定位和诊断工作繁琐低效的问题,天穹平台基于组件粒度构建了全链路诊断能力,使得用户能够清晰地了解当前问题发生在哪个组件,并在此基础上进行深入挖掘和对比。例如,如果问题发生在计算引擎侧,能够清晰地告知用户作业在计算引擎层是由于资源抢占被 kill,或任务本身数据膨胀、数据倾斜等原因导致的异常,并提供细粒度的判断。
(2)算子粒度的异常识别
同时,针对 SQL 任务,推出了算子粒度的诊断,可以将实际物理执行过程中发生的异常点与 SQL 逻辑片段对应起来,从而帮助用户在繁杂的计算过程中快速准确地定位到问题的具体原因。

在实际应用中,我们已经将算子粒度的回放和诊断能力产品化。这使得用户能够回放 SQL 计算的过程,诊断每一个算子的数据规模和资源占用情况。目前,我们已经支持了 40 多个算子粒度问题的诊断。

4. 优化力
针对在大数据计算过程中面临的挑战,如任务运行缓慢、数据处理速度不理想以及任务资源启动困难等问题,构建了优化力能力体系。在资源方面,针对 Spark 和 Flink 进行了深入优化。在性能方面,引入了 SQL 引擎选择、智能 SQL Hint 和智能 RSS 等技术。此外,通过 SQL 智能体的构建,实现了 SQL 优化改写、语法纠错和诊断等功能。
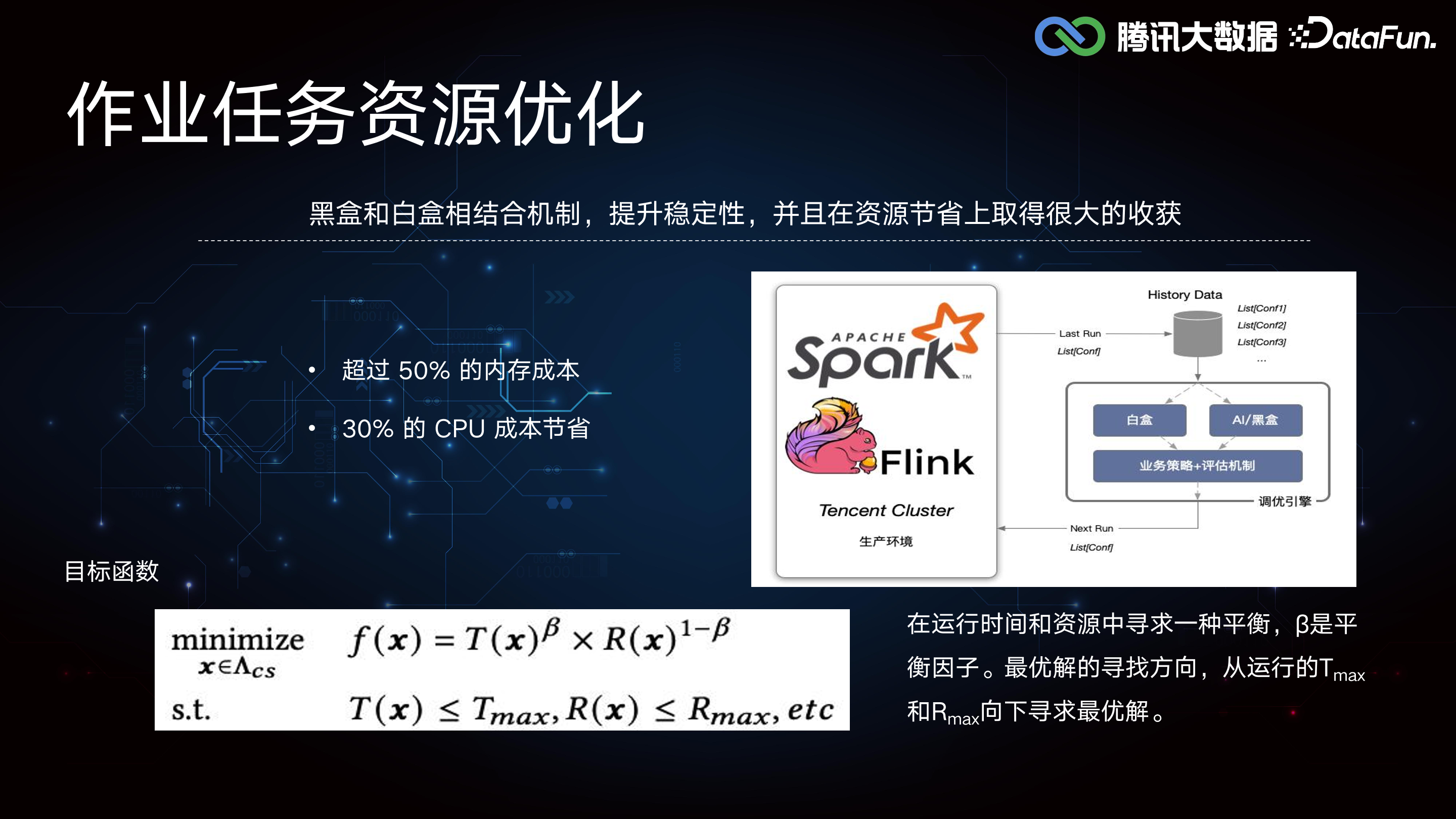
(1)数据驱动的资源优化
针对 Spark 的资源优化,主要构建了基于 Spark 历史运行数据的方法,采用白盒和黑盒两种方式进行调整。白盒方法通过分析历史运行过程中资源的实际进程粒度占用情况,拟合出适合作业正确运行的资源参数。我们根据历史运行曲线自定义计算弹性因子,并每天为作业推荐资源参数。而黑盒方法则无需用户感知,算法基于时间和性能两个维度自动调整参数,并每天定时进行迭代。通过前一周期的运行结果,调整下一周期的参数,并提交到集群中运行。
最终针对一些应用组显著节省了超过 50% 的内存成本和 30% 的 CPU成本,在资源优化方面取得了显著的成果,降低了资源的使用。
(2)SQL 引擎选择,让 SQL 计算更加高效
在 SQL 计算引擎选择方面,根据 SQL 计算逻辑的复杂度判断其是 IO 密集型还是 CPU 密集型,并将不同的 SQL 分发到不同的计算引擎上以提高性能。同时从历史运行的 SQL 中提取特征,利用 XGBoost 模型进行训练,以优化底层的建模过程。
最终通过特征化和模型训练,引擎 failover 规避率有了显著提升,进一步降低了资源浪费。

(3)SQL 算子粒度优化,反哺计算引擎
除了资源优化和 SQL 引擎选择外,还关注算子粒度的优化。从历史运行数据中挖掘包含算子粒度信息的数据记录,经过规划处理后形成 SQL 算子粒度的数据体系。这有助于支持 SQL 的 CBO 代价模型优化。例如,如果提前知道计算过程的数据量,可以自动添加 map join 等提示以提升效率。此外,对于每天定时调度的数据计算任务,由于 SQL 逻辑和数据量相似,可以通过历史数据进行预测和优化。

最终通过算子粒度的数据挖掘,将运行过程中的数据量大小和数据记录数喂给 SQL 代价模型,实现了自动 map join 的功能,显著提高了 SQL 计算的性能。在 TPC-DS 测试集中,自动 map join 的占比达到了 57%,显著提升了 CPU 和内存的使用效率。

5. SQL 智能体
由于日常机器计算类型中 SQL 任务占比很高,且标准化程度较高,天穹结合大语言模型对于 SQL 的理解力,以优化 SQL 性能提升作业效率为目标,进行了 SQL 智能体的构建。
腾讯内部基于混元大语言模型,设计了多轮对话、问诊模式的 SQL 智能体,涵盖了 prompt 知识库、function call 等环节。

下面介绍一下 SQL 智能体的构建过程。首先,通过现网收集 SQL 优化和错误 SQL,以及 SQL 工单语料库,在此基础上建立 SQL 指令集,基于基座模型进行指令微调,并结合 prompt 强化用户意图。

最终通过 SQL 智能体的构建,从多方面实现了 SQL 的优化改写和诊断,显著提升了 SQL 性能。
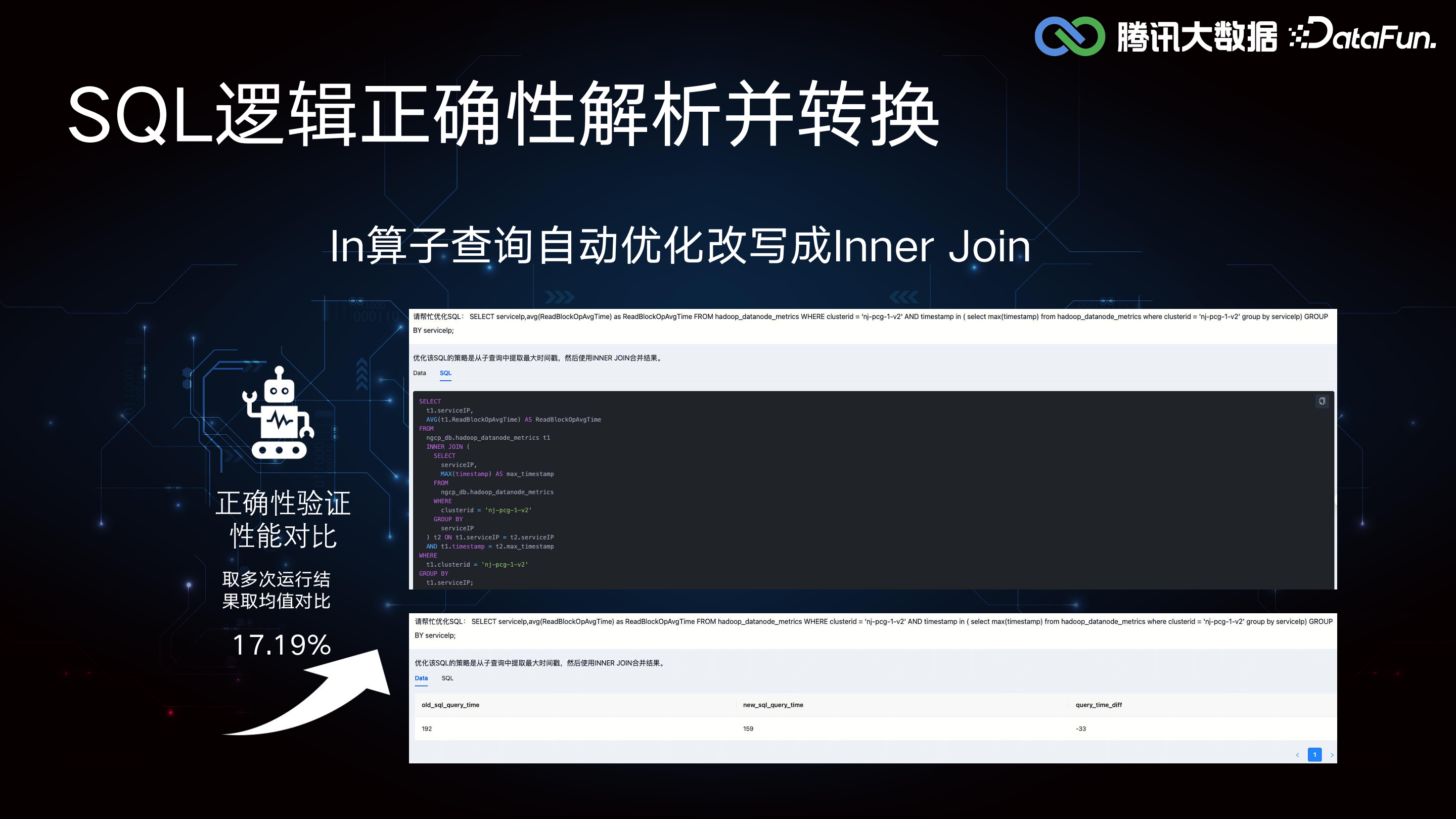
(1)正确性解析和转换
它能自动将硬查询中的 SQL 翻译为为 inner join,并实时对比优化前后的 SQL。
SQL 智能体在优化改写方面也取得了显著的成果。通过底层的 OLAP 引擎测试发现,性能提升了 17.19%。这表明 SQL 智能体能够有效地优化 SQL 计算,提高系统性能。
(2)SQL 长度优化
大模型能够理解长 SQL 内容,自动去除不必要的如 order by 的逻辑片段,提高计算效率。

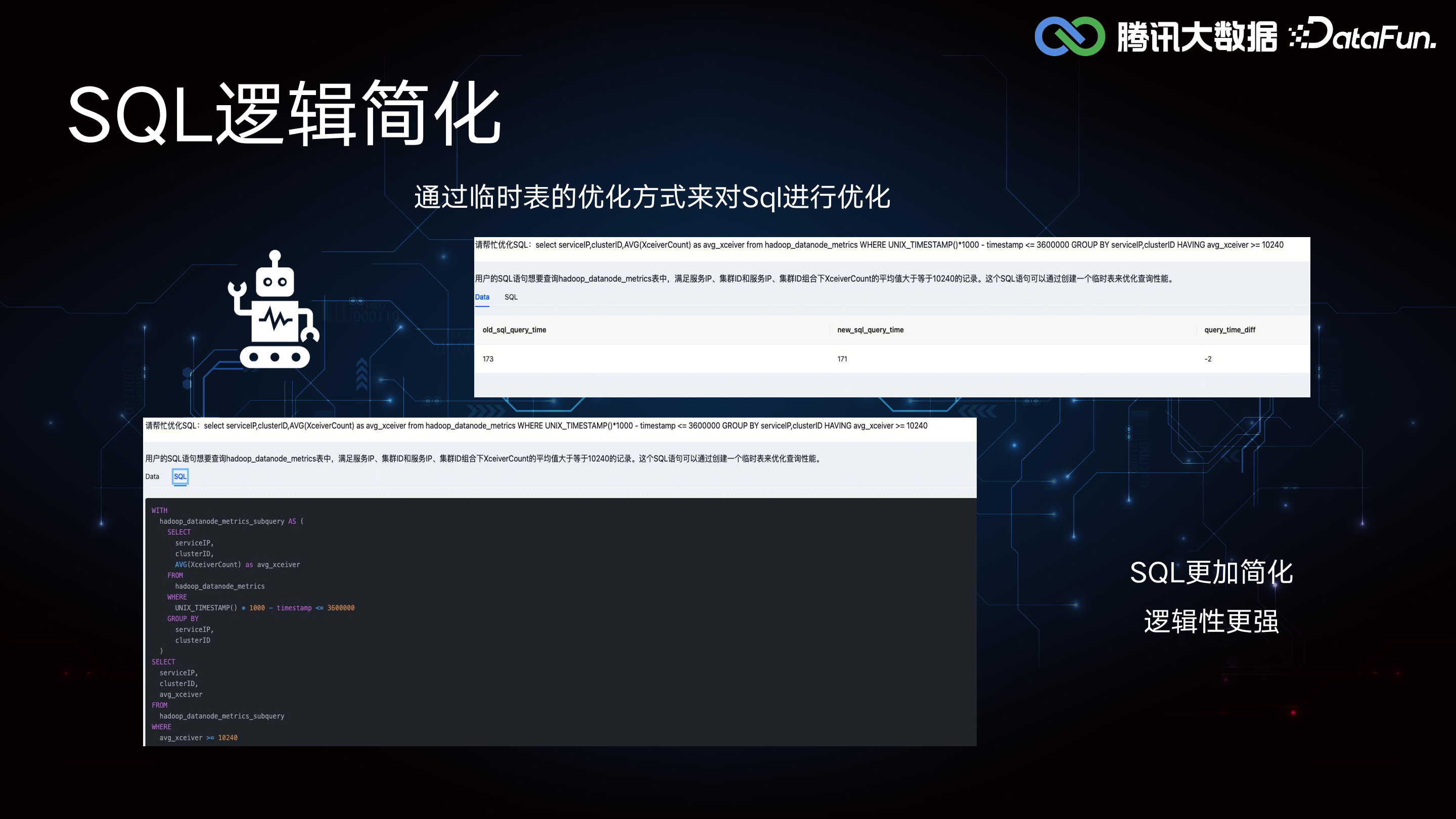
(3)SQL 逻辑简化
此外,SQL 智能体还能够简化 SQL 逻辑,借助临时表等技术,使得 SQL 计算逻辑更加简洁和高效。
03 未来规划和展望
在未来的规划中,我们将继续优化数据存储和研发能力,不断丰富和提升大数据自治的能力。最终,我们计划打造一个湖仓智能自治的解决方案,支撑大数据平台的智能化应用,推动大数据自治向更高层次发展。

