64位对决32位 SPEC CPU运算效能测试
导致这种情况发生的原因是目前处理器未完全为64位计算优化。从AMD推出x86-64开始的时候就未考虑完全,到了Intel推出EM64T则是一种迫于压力的行为,先头Prescott部队内部架构甚至还没完全准备好:

支持EM64T的Prescott Pentium 4核心的ALU(算数运算单元)采用了32位/64位同时支持的设计

从电路上看,这个ALU实际上分为两个32位的部分
从实际性能来看,Prescott在执行64位整数运算的时候(整数运算使用ALU单元),延迟很高,性能也比32位情况下低多了。
当然,NetBurst架构的Pentium 4已经是明日黄花,我们再来看看现在的主流Core微架构:
Core微架构提供了一个预译码(pre-decode)功能,结合取指令缓冲和译码单元可以提供Macro Fusion(宏指令融合)功能——这是Core微架构中增加的一项新功能。从Pentium Pro处理器中,Intel便开始采用了类似RISC的做法,将所有的x86指令先解码成一条一条的内部指令:uops,基于CISC架构的x86指令集的特点是指令不等长,执行时间也不等,而类似于RISC架构的uops则不同,每一条指令长度都一样,执行时间也一样(都为一个时钟周期),这也是RISC被称为“简单指令集”的原因。
 |
| 前端单元对比:Core、yonah、P4 |
历史总是峰回路转的,从Pentium Pro乃至NetBurst Pentium 4,Intel让x86分解变成uops,到了Core微架构,Intel又想办法让uops合体:Macro Fusion宏聚合使得解码器可以将两个x86指令的uops合成为一个uop,一般做法是把x86比较或者测试指令同x86跳转指令融合为一条uop,这样最终就降低了执行指令的数量,提升了运算速度。据说macro-op fusion可以降低约10%的uops数量。
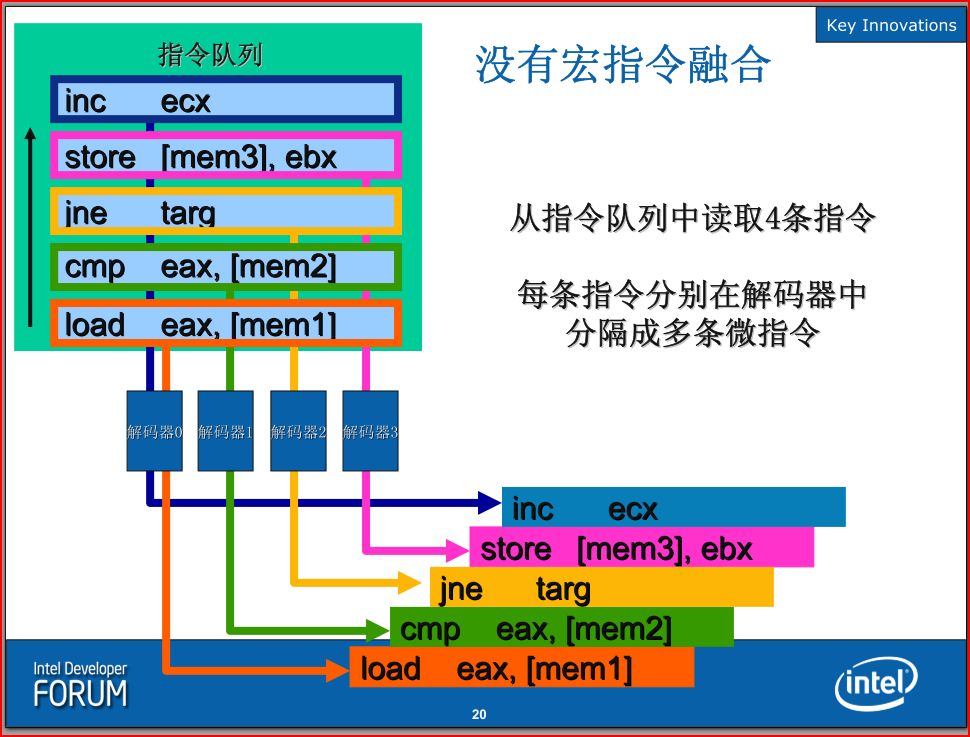
Macro Fusion功能

Macro Fusion功能
不幸的是,Core 2为止的处理器都只能提供在32位指令下的宏聚合功能,你也可以理解为:幸运的是,Intel在Nehalem上提供了64位下的宏聚合功能:

为了获得完美的64位性能,你要买Nehalem

