64位对决32位 SPEC CPU运算效能测试
【IT168评测中心】我们已经有并且已经运行64位计算多年了,从桌面级别到服务器级别,除去比较偏门的原生IA64架构,我们已经对x64并不陌生。

Why towards 64?
和彻头彻尾的64位RISC架构不同,也异于Intel从头打造的IA64,我们经常接触的64位计算基于两种技术:AMD的x86-64和Intel的EM64T。从名字上可以看出,对AMD而言,64位计算是x86架构的一种扩展,而已。而对于Intel来说更为简单,仅仅是一种内存支持技术的提升。
x86-64的根本变化:更强大的寄存器
虽然如此,凭借着GPR通用寄存器方面的变化,x86-64和EM64T——统称为x64——仍然带来了计算性能上的提升,我们已经在《突破4GB内存屏障 64位平台解析(下)》里面分析了这方面的原因,接下来我们会通过SPEC CPU 2006这套测试软件,来更精细地察看这个问题,并进行解答:为什么一部分人会拒绝64位?
*VIA的Nano处理器现在也能进行64位计算
为了避免枯燥的架构资料影响结论党的情绪,我们在分析之前我们先来直接看测试结果,按照规定,我们必须先给出测试平台,不感兴趣的同学可以直接看下一页~
测试平台、测试环境 | |||||
测试分组 | |||||
类别 | 双路Xeon E5430基准平台 DELL PE2900 III服务器 | ||||
处理器子系统 | |||||
处理器 | 双路Intel Xeon E5430 | ||||
处理器架构 | Intel 45nm Penryn | ||||
处理器代号 | Harpertown | ||||
处理器封装 | Socke 771 LGA | ||||
处理器规格 | 四核 | ||||
处理器指令集 | MMX,SSE,SSE2,SSE3,SSSE3, SSE4.1,EM64T,VT | ||||
| 主频 | 2.66GHz | ||||
| 处理器外部总线 | FSB:1333MHz | ||||
L1 D-Cache | 4x 32KB 8路集合关联 | ||||
L1 I-Cache | 4x 32KB 8路集合关联 | ||||
L2 Cache | 2x 6144KB 16路集合关联 | ||||
L3 Cache | |||||
主板 | |||||
主板型号 | DELL PE2900 III | ||||
北桥芯片组(MCH) | Intel 5000X | ||||
| 北桥芯片特性 | 12MB Snoop Filter | ||||
内存控制器 | 北桥集成四通道FBD DDR2 | ||||
内存 | 2GB FBD DDR2 667 SDRAM x8 | ||||
系统磁盘子系统 | |||||
磁盘控制器 | DELL Perc 5/i RAID Controller | ||||
磁盘控制器规格 | SAS 3Gbps | ||||
磁盘控制器设置 | RAID 5 | ||||
磁盘控制器驱动 | LSI SAS 3.8.0.32/3.8.0.64 | ||||
| 磁盘 | Seagate Cheetah 15K.5 ST314655SS x3 | ||||
磁盘规格 | 15000RPM 146GB SAS 3Gbps 16MB Cache | ||||
磁盘设置 | SAS 3Gbps 20GB系统分区 | ||||
软件环境 | |||||
| 操作系统 | Microsoft Windows Server 2008 Enterprise x64 Edition SP1 Microsoft WIndows Server 2003 R2 Enterprise Edition SP2 | ||||
Harpertown架构Xeon基于Core微架构,支持SSE4.1和EM64T扩展指令集。SPEC CPU 2006测试要求每一个测试进程都搭配1.5GB以上的内存,每个内核一个测试进程,总共就需要12GB以上的内存,因此我们将DELL测试平台的内存增加到16GB。以往的测试表明,12GB以上的内存对SPEC性能没有什么影响。
SPEC CPU2006 v1.01
SPEC是标准性能评估公司(Standard Performance Evaluation Corporation)的简称。SPEC是由计算机厂商、系统集成商、大学、研究机构、咨询等多家公司组成的非营利性组织,这个组织的目标是建立、维护一套用于评估计算机系统的标准。
SPEC CPU 2006是SPEC组织推出的专门用来评估CPU子系统性能的测试软件,它目前版本为1.1,包括了CINT2006和CFP2006两个子项目,前者用于测量和对比整数性能,而后者则用于测量和对比浮点性能。
SPECfp测试过程中同时执行多个实例(instance),测量系统执行计算密集型浮点操作的能力,比如CAD/CAM、DCC以及科学计算等方面应用可以参考这个结果。SPECint测试过程中同时执行多个实例(instances),然后测试系统同时执行多个计算密集型整数操作的能力,可以很好的反映诸如数据库服务器、电子邮件服务器和Web服务器等基于整数应用的多处理器系统的性能。
SPEC CPU 2006总共包含了29个主要测试项目,最后两个specrand目录乃是SPEC自身的一部分
SPEC测试代表了绝大多CPU密集型的运算,包括编程语言、压缩、人工智能、基因序列搜索、视频压缩及各种力学的计算等,包含了多种科学计算,可以用来衡量系统执行这些任务的快慢。SPEC测试包括了浮点(fp)与整数运算(int)两大部分。
SPEC CPU 2006是一个发行源代码的测试,需要测试者自行进行编译,因此我们得以分别进行32位和64位的测试。在测试32位性能的时候,我们采用了Windows Server 2003 R2 Enterprise Edition SP2 + Intel C++/Fortran Compiler 10.0.025的组合,而在测试64位性能的时候,我们采用了Windows Server 2008 Enterprise x64 Edition SP1 + Intel C++/Fortran Compiler 10.1.025的组合。因为经过多次试验,10.1.025版本编译器只能工作在32位Vista下,SPEC官方网站的大部分例子也是基于这一组合。除了操作系统和编译器之外,我们还安装了Visual Studio 2005 SP1提供相应的库文件,并使用了QxS对SSE4指令集进行了优化,编译时未使用SmartHeap商业优化库。
不仅仅测试耗时,对测试组件进行编译也很花时间。这个过程其实也能体现了系统的快慢
在一个计算系统中,CPU子系统是影响最大的,而内存子系统和C/C++/Fortran语言编译器都会影响最终的测试性能,而I/O(磁盘)、网络、操作系统和图形子系统对于SPEC CPU2000的影响比较小。运行SPEC CPU 2006测试需要大量的内存和较多的磁盘空间。
整数运算主要包含编译、压缩、人工智能、视频压缩转换、XML处理等,此外,各种日常操作也主要是基于整数操作。SPEC CPU 2006的整数运算包含了400.perlbench PERL编程语言、401.bzip2 压缩、403.gcc C编译器、429.mcf 组合优化、445.gobmk 人工智能:围棋、456.hmmer 基因序列搜索、458.sjeng 人工智能:国际象棋、462.libquantum 物理:量子计算、464.h264ref 视频压缩、471.omnetpp 离散事件仿真、473.astar 寻路算法、483.xalancbmk XML处理共12项。
SPEC CPU 2006整数测试成绩
浮点运算包括的全部都是科学运算,科学运算需要用到大量的高精度浮点数据,如410.bwaves 流体力学、416.gamess 量子化学、433.milc 量子力学、434.zeusmp 物理:计算流体力学、435.gromacs 生物化学/分子力学、436.cactusADM 物理:广义相对论、437.leslie3d 流体力学、444.namd 生物/分子、447.dealII 有限元分析、450.soplex 线形编程、优化、453.povray 影像光线追踪、454.calculix 结构力学、459.GemsFDTD 计算电磁学、465.tonto 量子化学、470.lbm 流体力学、481.wrf 天气预报、482.sphinx3 语音识别共17项测试。
SPEC CPU 2006浮点运算测试成绩
整数运算的提升令人惊讶,从46.4分提升到74.8分,61.2%的提升部分要归功于操作系统的变化才对,也表明32位2003系统下成绩偏低。而浮点运算提升只有6.7%,很正常的数值。我们可以看到,在整数运算中,并不是所有的项目都得到了提升,而提升的项目中,幅度也不同,400.perlbench项目提升幅度比较过分,如401.bzip2这样的测试提升就不大。有些项目的性能还倒退了,如403.gcc、429.mcf、445.gobmk这三个项目就如此。这表明64位环境虽然很好——但非尽善尽美。
导致这种情况发生的原因是目前处理器未完全为64位计算优化。从AMD推出x86-64开始的时候就未考虑完全,到了Intel推出EM64T则是一种迫于压力的行为,先头Prescott部队内部架构甚至还没完全准备好:
支持EM64T的Prescott Pentium 4核心的ALU(算数运算单元)采用了32位/64位同时支持的设计

从电路上看,这个ALU实际上分为两个32位的部分
从实际性能来看,Prescott在执行64位整数运算的时候(整数运算使用ALU单元),延迟很高,性能也比32位情况下低多了。
当然,NetBurst架构的Pentium 4已经是明日黄花,我们再来看看现在的主流Core微架构:
Core微架构提供了一个预译码(pre-decode)功能,结合取指令缓冲和译码单元可以提供Macro Fusion(宏指令融合)功能——这是Core微架构中增加的一项新功能。从Pentium Pro处理器中,Intel便开始采用了类似RISC的做法,将所有的x86指令先解码成一条一条的内部指令:uops,基于CISC架构的x86指令集的特点是指令不等长,执行时间也不等,而类似于RISC架构的uops则不同,每一条指令长度都一样,执行时间也一样(都为一个时钟周期),这也是RISC被称为“简单指令集”的原因。
 |
| 前端单元对比:Core、yonah、P4 |
历史总是峰回路转的,从Pentium Pro乃至NetBurst Pentium 4,Intel让x86分解变成uops,到了Core微架构,Intel又想办法让uops合体:Macro Fusion宏聚合使得解码器可以将两个x86指令的uops合成为一个uop,一般做法是把x86比较或者测试指令同x86跳转指令融合为一条uop,这样最终就降低了执行指令的数量,提升了运算速度。据说macro-op fusion可以降低约10%的uops数量。
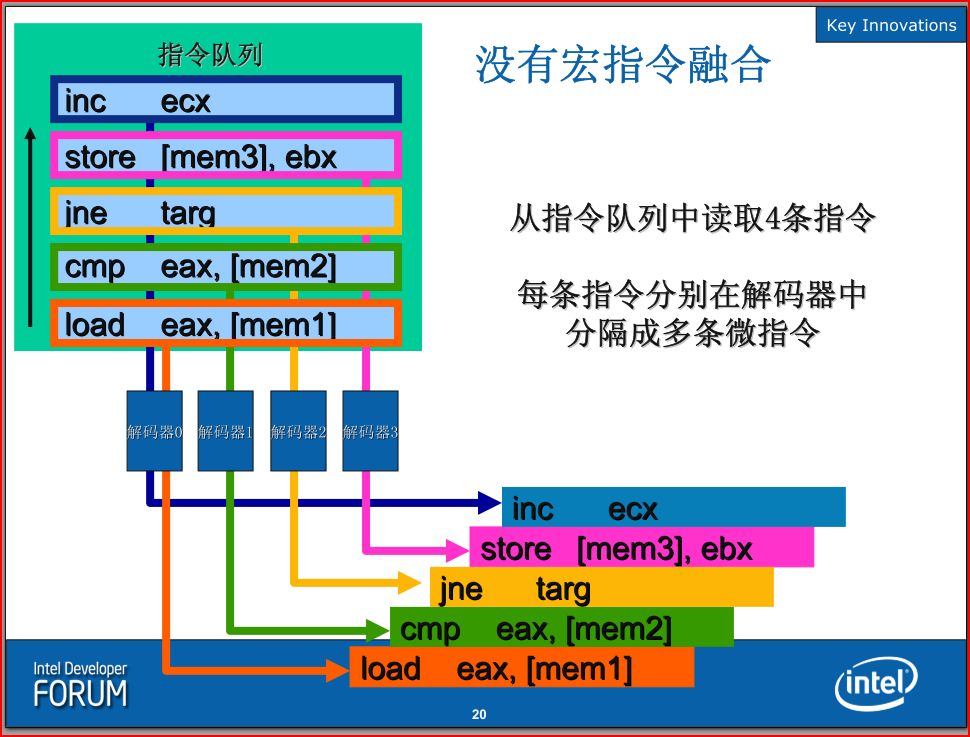
Macro Fusion功能

Macro Fusion功能
不幸的是,Core 2为止的处理器都只能提供在32位指令下的宏聚合功能,你也可以理解为:幸运的是,Intel在Nehalem上提供了64位下的宏聚合功能:

为了获得完美的64位性能,你要买Nehalem
【IT168评测中心】影响人们进入64位世界的因素还有许多,如:64位可执行文件映像总是要比32位大上一些、64位操作系统占用的空间总要多一些等,当然,如缺乏64位应用、担心32位应用无法运行,以及不是所有的64位应用性能都有提升才是最主要的。
 |
| Nehalem的SPEC CPU得分纪录都是在64位Vista下得到 |
不过世界正在逐渐变得美好,以前不坚定的64位步伐现在也一步一步走远,原生64位应用也不少见了,我们有理由相信,Nehalem将会带来更好的64位表现。

