大家风范 DELL PE R805机架服务器评测
ScienceMark v2.0 Membench
ScienceMark v2.0是一款用于测试系统特别是处理器在科学计算应用中的性能的软件,MemBenchmark是其中针对处理器缓存、系统内存而设计的功能模块,它可以测试系统内存带宽、L1 Cache延迟、L2 Cache延迟和系统内存延迟,另外还可以测试不同指令集的性能差异。
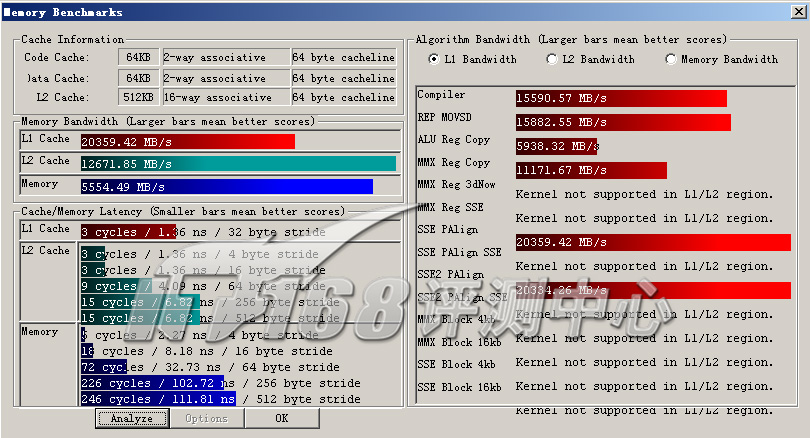
ScienceMark v2.0 Membench L1测试成绩

ScienceMark v2.0 Membench L2测试成绩

ScienceMark v2.0 Membench 内存测试成绩
首先我们进行的是ScienceMark的测试,主要考察系统的缓存和内存子系统情况。L1/L2 Cache的成绩主要是跟处理器频率相关,因为目前的处理器当中L1 Cache都是和处理器核心同频率的,而L2 Cache基本上也是——当前的处理器L2都是全速的(放置在处理器内但不在同一个芯片上的Pentium II为半速L2,而Pentium之前的处理器L2则和处理器分离,速度更低)。越快的频率,L1/L2性能就越好。而内存带宽主要由两部分相关:比较大的部分是内存架构,小部分是内存操作指令(集),例如使用最新的SSE指令集比通常的ALU指令集会得到更大的吞吐量,而不同的SSE版本性能也有不同。
ScienceMark Membench | |||
| 厂商 | DELL | DELL | |
| 产品型号 | PowerEdge R805 AMD Barcelona Opteron 2354 2.2GHz | PowerEdge 2900 III Intel Harptown Xeon E5430 2.66GHz | |
| 内存技术参数 | 2GB R-ECC DDR2-667 SDRAM x8 | 2GB FBD-ECC DDR2-667 SDRAM x4 | |
| L1带宽(MB/s) | 20359.42 | 55376.16 | |
| L2带宽(MB/s) | 12671.85 | 16757.55 | |
| 内存带宽(MB/s) | 5554.49 | 4485.09 | |
| L1 Cache Latency(ns) | |||
| 32 Bytes Stride | 1.36 | 1.13 | |
| L1 Algorithm Bandwidth(MB/s) | |||
| Compiler | 15590.57 | 25201.968 | |
| REP MOVSD | 15882.55 | 25467.15 | |
| ALU Reg Copy | 5938.32 | 13093.65 | |
| MMX Reg Copy | 11171.67 | 25242.19 | |
| SSE PAlign | 20359.42 | 52826.21 | |
| SSE2 PAlign | 20334.26 | 55376.16 | |
| L2 Cache Latency(ns) | |||
| 4 Bytes Stride | 1.36 | 1.13 | |
| 16 Bytes Stride | 1.36 | 1.50 | |
| 64 Bytes Stride | 4.09 | 4.51 | |
| 256 Bytes Stride | 6.82 | 4.51 | |
| 512 Bytes Stride | 6.82 | 4.89 | |
| L2 Algorithm Bandwidth(MB/s) | |||
| Compiler | 5093.55 | 118800.48 | |
| REP MOVSD | 5463.29 | 12536.88 | |
| ALU Reg Copy | 4200.95 | 8577.86 | |
| MMX Reg Copy | 7532.08 | 13408.31 | |
| SSE PAlign | 12552.76 | 16719.97 | |
| SSE2 PAlign | 12671.85 | 16757.55 | |
| Memory Latency(ns) | |||
| 4 Bytes Stride | 2.27 | 1.13 | |
| 16 Bytes Stride | 8.18 | 4.89 | |
| 64 Bytes Stride | 32.73 | 19.17 | |
| 256 Bytes Stride | 102.72 | 59.77 | |
| 512 Bytes Stride | 111.81 | 68.04 | |
| Memory Algorithm Bandwidth(MB/s) | |||
| Compiler | 1877.70 | 3178.45 | |
| REP MOVSD | 1901.81 | 3220.23 | |
| ALU Reg Copy | 1609.94 | 2789.34 | |
| MMX Reg Copy | 1917.39 | 2972.91 | |
| MMX Reg 3dNow | 5374.10 | - | |
| MMX Reg SSE | 5478.60 | 3978.53 | |
| SSE PAlign | 4894.52 | 4128.59 | |
| SSE PAlign SSE | 5554.49 | 4390.48 | |
| SSE2 PAlign | 4895.07 | 4326.42 | |
| SSE2 PAlign SSE | 5554.14 | 4441.71 | |
| MMX Block 4kb | 3034.72 | 4063.30 | |
| MMX Block 16kb | 3355.63 | 4479.88 | |
| SSE Block 4kb | 3176.99 | 4074.79 | |
| SSE Block 16kb | 3395.19 | 4485.09 | |

AMD 45nm Shanghai Opteron 2350的缓存架构,L3基于32路集合关联,并且容量只有2MB
Intel 45nm Harptertown Xeon E5430的缓存架构,L3基于24路集合关联
不得不说,直联架构的内存带宽是要高一些,而基本上,与处理器结合最紧密的L1,或L2(在有L3的情况下)的延迟总是跟处理器频率密集相关的,因此频率较高的Xeon平台在缓存方面就强一些。大容量的缓存在进行多任务处理器的时候会具有更高的效率。
0
第1页:DELL PowerEdge R805服务器评测第2页:DELL PowerEdge R805服务器外观介绍第3页:DELL PowerEdge R805服务器内部组件解析第4页:DELL PowerEdge R805服务器内部组件解析第5页:DELL PowerEdge R805服务器内部组件解析第6页:测试环境与测试平台介绍第7页:测试方法介绍第8页:软件测试信息、系统部件简介第9页:SiSoftware Sandra 2009综合性能测试第10页:ScienceMark - 缓存内存子系统测试第11页:CineBench R10性能测试第12页:SPEC CPU 2006-处理器子系统性能测试第13页:IOmeter-磁盘子系统性能测试第14页:NetBench-文件服务器测试第15页:Benchmark Factory-数据库性能测试第16页:服务器功耗测试第17页:IT168评测中心观点
相关文章
关注我们

