引言
这篇文章由三个部分构成,希望可以从看自己、看行业、看世界三个视角,讲一讲我的思考,以及在这巨变的时代,不变的本质是什么。
第一部分,我会从一名 AI 产品 Agent 工程师的视角,聊聊我亲身经历的一些变化,以及在这些变化里我越来越确信的一件事:有些东西一直在变,但也有些东西几乎没怎么变过。我觉得这一点,对任何行业的人都可能有点用。
第二部分,是一些关于行业与 AI 结合的思考。我这些年换过几个行业,接触过教育、营销、金融。因为最近九年都在阿里巴巴,所以会重点聊聊营销、人群运营和金融领域,我看到AI改变了它们什么。教育那段以后有机会再慢慢聊。
第三部分,是我对最近一些很火的 AI 产品(ClaudeCode、OpenClaw 等)的看法:这类产品是由什么技术构建的、最核心的是什么,以及我认为不变的部分是什么。
一、看自己,一名工程师在这三年经历了什么
先从几个数据开始看工程师经历了什么变化,最近自己参与的公司产品,我个人的AI代码生成率已经至少在99%以上,1个人可以短时间,造一整个系统。效率的提升我认为至少20倍起步,因无法准确评估和衡量,说50倍其实也不夸张。看整个行业,今天GitHub上4%的公开代码提交都是由AI Agent生成的,预估26年底可以达到20%以上。
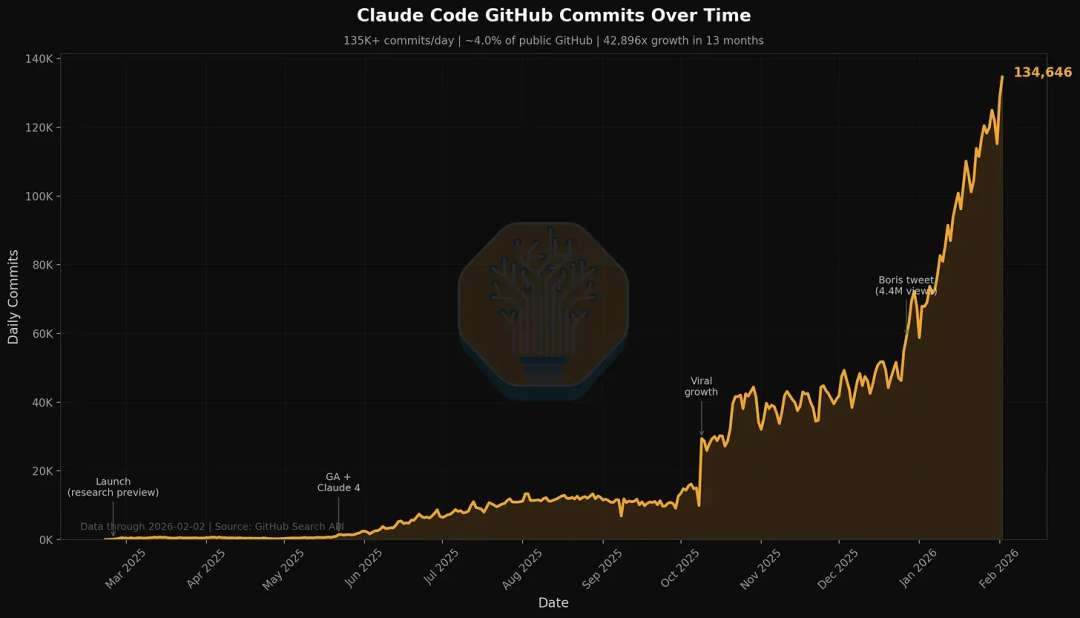
图片来自:
https://newsletter.semianalysis.com/p/claude-code-is-the-inflection-point
推动软件行业发生如此巨大变化的转折点,我认为是ClaudeCode,这是一个AI智能体发展的转折点,当然,不止软件行业,今天所有的领域都会因ClaudeCode产生的影响,发生巨大的变化,而我们今天正一起见证着这个新时代。引用知名分析师前几天硅谷归来的感受讲,“AI不是风口,是海啸。“
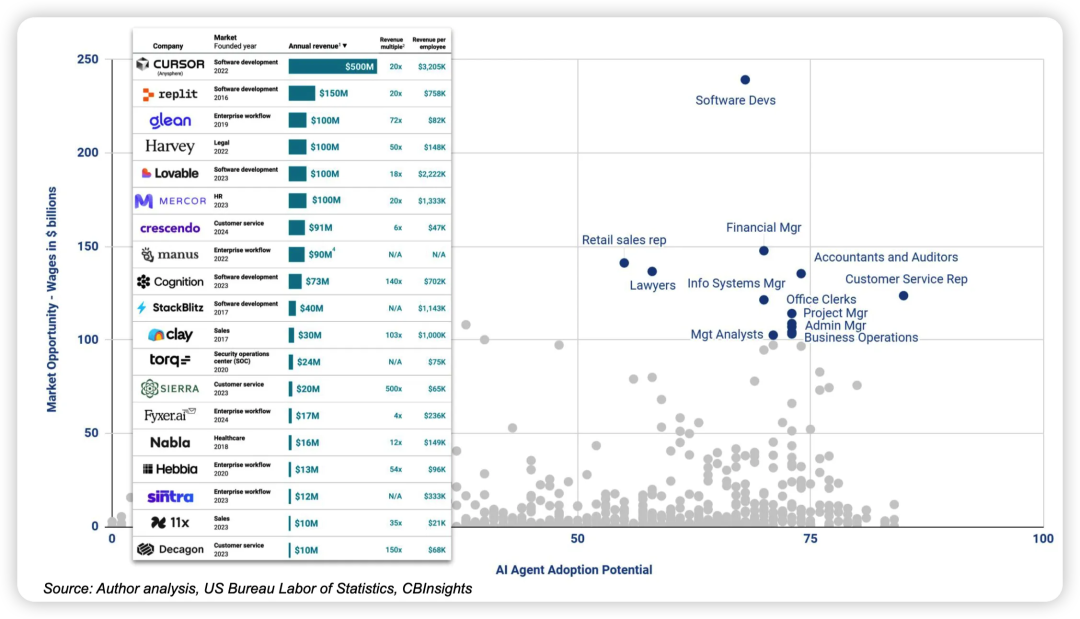
图片中不同职业工资市场规模绘制分布图
软件工程师这样年收入高达2300亿美元的职位是最具吸引力的机会
代码写了十年,这三年自从ChatGPT火爆之后,对我的编码主业带来的极大的影响和变化。这期间主要经历了四个阶段:
「第一阶段:把模型当作“搜索引擎”」
早期,我更多是把大模型当作一种更聪明的搜索引擎来用:遇到问题直接提问,写代码卡住了就把报错和上下文丢给它,往往能很快得到一个可行的解法。在这个阶段,Stack Overflow 首当其冲地受到了冲击。2023 年时,它新问题发布量已经出现断崖式下滑(30%+)。
这个阶段,程序员获取答案的路径,开始从“搜索 + 筛选”,转向“直接对话”。
「第二阶段:Copilot,让 AI 开始“陪我写代码”」
随后,Copilot 这一类产品形态出现了。以 GitHub Copilot 为代表的代码补全工具迅速流行起来。我记得很清楚,自己几乎是上线第一时间就花了 100 美元订阅了一年。在当时,这已经是一种非常新鲜、也足够令人兴奋的体验:AI 会陪你一起写代码,而且很多补全的猜测都相当准确。对经验相对丰富的工程师来说,这一阶段通常能带来 20–30% 的效率提升。直到今天,恐怕仍然有相当多的工程师,停留在这个阶段。据了解我公司的很多团队仍是如此,让人转变思想相信新物种,需要一个过程。
「第三阶段:Cursor,把 AI 从“补全”推向“参与修改”」
在前两个阶段之后,“AI 能写代码”以及“程序员愿意为此付费”,已经成为共识。在这样的背景下,Cursor 顺势出现,并迅速爆火。它的关键不在于模型多强,而在于 AI-first 的设计理念:AI 不再只是补全你正在写的那几行,而是可以主动参与到整个项目的修改和重构中。这一阶段的产品形态非常激进,对开发者的心理门槛也极高——但一旦真正跨过去,几乎就回不去了。
「第四阶段:Claude,带来真正的“质变”」
随着模型能力的快速提升,事情开始发生更深层次的变化。Anthropic的Claude 系列模型,早期就把重心放在长上下文理解和编程能力上。再结合其在工程架构上的创新,这一组合带来了明显的质变:AI 不只是“更会写代码”,而是开始具备处理更长任务链、更复杂工程代码重构的能力。这一步,实际上为后续的 Agent 化、自己干活,打下了基础。
这个阶段观念转变最难的,因为你要真正把ClaudeCode这种智能体当成是真人,像管理团队一样去驾驭AI,比如你要有意识教AI怎么做个好工程师,比如:1)敢于质疑老板;2)做事有章法;3)凡事有交代;更高级一点的思维你甚至要调教和驱动智能体从Coder升级为CTO,不仅写代码,还负责技术决策和怼老板(当然指的是作为使用者的你)。
这几个阶段,让我对“软件工程师”这个角色的理解发生了根本变化:工程师不再只是一个写代码的人,而是变成一个定义软件,并对结果负责的人。
当然,在今天,我和 AI 的协作方式还谈不上成熟。我仍然需要为它定义架构和模块边界,并持续检查代码质量,这部分判断工作依然消耗着大量精力。但是我深刻相信,随着更成熟的产品形态出现——尤其是更可靠的流程和测试机制——这部分判断成本本身,也很可能会被系统性地消化掉。
就像Anthropic团队在2月5日进行的实验,让 Opus 4.6 利用智能体团队来构建一个 C 语言编译器,然后(基本上)就放手不管了。如果在结合上Happy Coder这样的移动端软件,即使不在电脑前,也能监控和控制正在运行的开发任务。

图片基于Manus对
https://www.anthropic.com/engineering/building-c-compiler 的理解自动生成
更重要的是,这个过程发生的异常之快,远超我的预期——至少对我而言,很难想象仅仅三年时间,自己的工作方式就已经发生了如此剧烈的变化。程序员用自己的双手构建了开源世界,而这个”世界“后来成了大语言模型最重要的养料,并最终参与了对程序员这一职业的重塑。某种意义上,我们也算是被自己提交的代码教育了一遍。但我并不焦虑,反而感到兴奋。工作方式的变化,让我从过去那种被调侃为“搬砖工、码字员”的高强度执行劳动中解放出来,使我在创造产品时,更多时间处在灵感持续涌现的状态。也正因为如此,我开始真正期待接下来的三年世界会变成什么样。在这样的时代里,路径依赖是最大的风险。面对持续发生的变化,最重要的,是始终保持乔布斯所说的那种“初学者心态”,不断地去重新理解,并不断尝试与 AI 的新协作方式。
今天再去提埃隆·马斯克一直强调的“第一性原理思维”,确实显得有些老套,但它对我的帮助依然非常直接。正是借助这种思维方式,在生产力被彻底重塑的过程中,我反而愈发确信,有些东西其实一直都不会变。
首先,是人与人之间的沟通与协作能力——清晰表达、建立共识、管理团队的经验与技巧,这些能力不仅没有被削弱,反而成为AI时代更重要的底层能力。
其次,是做选择的“品味”,以及把结果认真、负责地做稳的工程思维。所谓品味,并不只是审美,而是长期积累下来的判断标准、直觉和对复杂系统的理解。过去来自于互联网复杂系统架构、优秀实践和失败经验的沉淀,同样可以用来指导AI提高质量。
最为重要的,还有敢于决策、敢于承担结果责任,并与他人建立长期信任的能力。在 AI 参与执行的情况下,“谁对结果负责”反而变得更加清晰,也更加重要。
这些在没有AI的时代就极其关键的能力,在今天依然是最硬的实力,也是让 AI 真正成为你杠杆的核心积累。
这部分的结尾,我想补充一个最近才深刻意识到的体会。一次和老朋友的聊天中让我意识到,长期保持运动习惯,真的很重要,多年未见,他看上去比之前还年轻了几岁,说完全是因为坚持打网球。除了工作,更要去”感受自己“。
在 AI 时代,生产力在很大程度上取决于你能够调用的算力;而当你所能掌控的算力达到你的带宽(你的打字速度和精力)极限时,真正稀缺的,反而是你的身体健康,以及持续保持高能状态的能力。
二、看行业,AI为营销、金融,带来了哪些变化?
写这段内容的此刻,Seedance模型正在国内爆火破圈,叠加元旦期间在海外走红的快手可灵,它们正在深刻重塑内容创作的生态。其关键在于:把影视级短片的制作从过去那套依赖大量人力、分工繁琐的流程,逐步变成“AI 辅助、甚至由 AI 主导”的新方式。结果是,专业视频制作的门槛被明显拉低,“人人皆可导演”不再只是口号;创意、叙事与表达的价值,反而被前所未有地凸显。
这股由 AI 推动的浪潮,与我所在的软件工程行业正在发生的变化,在底层逻辑上是同一件事。视频制作工具之所以越来越“傻瓜化”,本质上是软件本身正在变得更智能,或者说更像“人”,还是很专业的人——从写代码到做视频,很多原本需要经验和时间堆出来的环节正在被重塑。
在很多垂直细分的领域,可能有非常多的变化正在发生,只是还掌握在少数从业者的认知里, 没有形成足够强的共识。我在阿里9年,从营销到金融,看到哪些变化,简单的向大家分享一下。
「营销和消费者运营」
我在阿里的第一段旅程,是做商家端的产品。在阿里巴巴的电商生态中,商家运营的核心逻辑从早期的”流量运营“(以货为中心,找便宜流量)逐步在转向”人群运营”(以人为中心,管理全生命周期的价值),生意参谋和品牌数据银行就是两个阶段最具代表性的产品。它们虽然都为商家提供数据支持,但在业务维度、数据深度及战略目标上有着本质区别。
核心业务价值和应用场景,比较易于理解和成熟的就是发现市场机会(比如发现某个细分类目搜索激增),然后找到对应的目标人群,到达摩盘或者阿里妈妈进行广告投放,形成从发现机会到精准收割的闭环。当然会有非常多的看板和分析能力,帮助你去看流量的变化,属于你自己品牌人群的变化,比如当时我们主推的AIPL模型,将消费者划分为四个阶段:
A (Awareness) 认知:看过品牌广告、搜索过品牌词的人群。
I (Interest) 兴趣:产生过加购、收藏、关注或点击行为的人群。
P (Purchase) 购买:发生过购买行为的人群。
L (Loyalty) 忠诚:多次复购、入会或主动分享的人群。
在技术侧,我们之所以能做出消费者运营模型、提供各种分析能力,本质上是把阿里电商生态里沉淀下来的海量行为数据“用起来”。比如搜索、浏览、加购、收藏、购买、评论等基础行为,都会成为计算人群与标签的原材料,再结合不同的标签体系,把消费者刻画成可分析、可运营的人群资产。
到了 AI 时代,上面提到的两个典型场景(广告投放、新品预测),即便我已经离开这个领域一段时间,仍然能明显看到一些与之相关、而且方向很一致的变化:
1)广告与投放:从“标签匹配”走向“生成式推荐”。
Meta 的 GEM(Generative Ads Recommendation Model)在业务上已经拿到不错的结果了,比如 Instagram 广告转化率因此提升 5%,Facebook Feed 广告转化率提升 3%。它不再只依赖传统的“标签—人群—投放”匹配逻辑,而是能够捕捉更多隐式关联。很多年前我们解这种问题时,更多还是用购买路径定义等相对传统的产品与技术范式;现在的解法已经明显更“生成式”了。
2)新品预测/意向判断:用 LLM 做具备足够多样性且“永不疲惫的人”。
我看到一款产品思路非常好:他们用 LLM 去模拟真实个体的认知与决策。它会基于个人的详细数据(基本信息、社交媒体语料、消费行为,甚至引入一些社会科学的建模思路),构建出对应的 AI Persona,让它在一个虚拟环境里“看广告、做选择”,甚至直接给出购买意向判断。据说模拟结果与真人对比的一致性大约能达到 81%。并且为了进一步提高一致性,这家公司还在持续引入更前沿的智能体技术,让 Persona 的行为更稳定、更接近真实世界。
像第二种“为模型注入多样、真实的人格与行为方式”的思路,其实不只适用于营销领域,也很容易外溢到更多行业。我看到他们的客户已经覆盖快消、美妆、科技、咨询等多个行业的头部企业了。这家初创公司的估值很可能已经在 10 亿美金量级。某种程度上,这类高速、低成本的虚拟试验场,正在成为传统调研与决策支持的重要补充。

「金融」
投研、包括围绕基本面的量化策略,都因为AI的进步产生了巨大的变化,某种程度上来说正在走向技术平权,普通投资者一定也会被未来诞生或者已经诞生的AI产品强化,这会为二级市场带来新的变量。从本质上看,这和 AICoding、AIGC 视频生成带来的结构性变化是同一类事情——生产方式被重写,门槛被拉低,效率与边界被重新定义。
这部分也是我近几年工作的重心,我的很多认知和市场判断都与正在做的事情高度相关。受限于业务敏感性,细节不便展开,但我可以明确给出一个判断:像金融行业这样的复杂业务深水区,并不是今天一些“通用形态”的热门智能体就能真正做好的。所以面向垂直领域、能把数据、方法论、流程与合规风控、可管控性等一起打通的“领域智能体”,机会很大,但门槛也极高。当然做好了Moat很深,不是模型公司能随便轻易进入的。关于这个部分技术方面的一些思考和趋势判断,会在第三个部分详细展开。
如果你对这个方向及其中的挑战更感兴趣,欢迎投递简历,或私信这个公众号。简历可以发到我的工作邮箱:yipengfei.ypf@alibaba-inc.com
三、看世界,ClaudeCode与Openclaw
这种“纯血智能体”到底带来了哪些变与不变
「1.0 时代:用“人类理解”的经验流程设计软件」
过去三年里,各类 B 端产品可能有 80% 的时间。都在用 RAG、编排工作流等偏“传统软件思维”的技术路径,去探索大模型能力,并试图把它落地到各自的业务领域。这条路确实跑出了不少成熟产品:以 Perplexity 为代表的搜索问答(后来演进出 Deep Research 这类新形态),国内以 Coze、DifyAI 为代表的工作流式智能体搭建平台,还有更早以 ChatBot 形态跑出来的 ChatGPT,以及国内的豆包、千问等。
这些产品在过去三年的阶段性发展中,的确提供了价值。但问题在于:再过五年、十年,“软件”本身是否还以今天的形态存在、会变成什么样,都很难讲。

就拿“XX点外卖”的交互体验来说,它仍然是在迎合人类过去的使用习惯:你需要主动输入一堆字、或者发语音告诉它“我想吃什么”。可如果类似 Openclaw🦞 这类个人助理型智能体未来人手一个,你真的还需要这样做吗?有没有可能一定是:它基于对你最近状态的理解——兴趣、行为、注意力,甚至通过终端连接到你的健康数据——形成对你的独特记忆(本质上类似人类对家人、朋友偏好的理解;技术上我们称为“记忆”)。然后在你需要吃饭的时间点,直接推送几个最合适的选择,你甚至不需要明确地 “yes or no”。
「1.5 时代:面向模型设计软件的开端,给模型一个虚拟电脑」
ClaudeCode、Openclaw 这两个产品最近影响力实在太大了,但在讲他们之前,我最想先提的其实是 Manus——一个被质疑“为什么能卖 20 亿美金”的产品和团队。这里不讨论它到底值多少钱,我想聊一聊:从我看到的角度,他们究竟厉害在哪。
可以毫不夸张地说,在 ClaudeCode 和 Openclaw 爆火之前,这绝对是这个世界上最会利用模型的团队之一。他们不仅产出了一套相对成熟的产品,还获得了很好的订阅收入,跑通了基本的 PMF。我也是付费一员,每年为 Manus 贡献至少 400 美金。
过去我们基于人类的使用习惯,面向用户去设计和定义产品,发明了各种基于 GUI 交互的、今天人类仍在使用的工具和产品。但他们是最早坚定相信可以像造“人”一样去造产品的团队之一,并做出了交互体验非常好的产品,并推向海量用户。在去年大家都还在玩编排智能体和多智能体的时候,他们就坚定把模型当成“人”,像教人一样教模型使用各种工具,比如浏览器、搜索、命令行终端,给它一个完全可以自主操控的计算环境。
这种认知,相信用过大模型做产品的人一定知道有多难。我们很容易为了某个场景的效果去 hack 流程,陷入“希望快速通过工程手段达到很好演示目的”的陷阱里。因为当模型的智能上限不断突破时,这些预设好的流程和代码很快就会一文不值:模型会自主决策和规划,找到可能比人更优的路径去完成任务。正是这种坚定,让他们在模型技术达到一个阶段时,发现产品可以完成很多连他们自己都意想不到的任务。
他们也是最早公开分享智能体长程任务优化经验的团队,甚至是第一个“自己没有模型,但 Google 愿意长期为他们驻场解决问题”的团队;Google 甚至会根据他们的用法和任务表现,去调整模型训练方向。他们也很早就分享过一些面向智能体的开发经验和调优方法,比如面向 KVCache 去调优。我觉得他们对我们、甚至对整个行业开发智能体,都做出了很大的贡献。应该也算是第一个在“直接面向用户的使用方式”上,跑通“大规模模型使用虚拟计算机跑任务”的模型产品团队。
所以他们在我心中有很多的“第一”,为这个行业后面的一些进化和发展奠定了基础。看到被收购的新闻时,我也非常为他们感到开心。
当然,同年 5–7 月,CludeCode 在程序员圈子里迅速蹿红,它晚于 Manus 的发布。ClaudeCode 和 Manus 在技术上的原理我认为是相似的:他们都是完全面向模型设计的通用智能体产品。区别是 Manus 在云端操作虚拟电脑中的各种工具,而 ClaudeCode 是跑在你的电脑上;并且它的提示词定义会稍微偏向编程方向,因为在这个阶段,Anthropic 这家公司的专注点——甚至直到今天——也都是在让模型写代码的能力不断变强,因为目前看来,编程是解决所有任务的更优底层基础能力。
技术小圈子里也有一些通用智能体理论概念的讨论,包括 Anthropic 团队的人也在提及的一种新的技术架构,并把这种概念称为 “Agent Harness”。这种技术架构我认为可以准确概括这种通用智能体产品技术。当然 Manus、还有 OpenAI Cloud Codex 这种云端的产品,会有一些更复杂的系统工程技术。
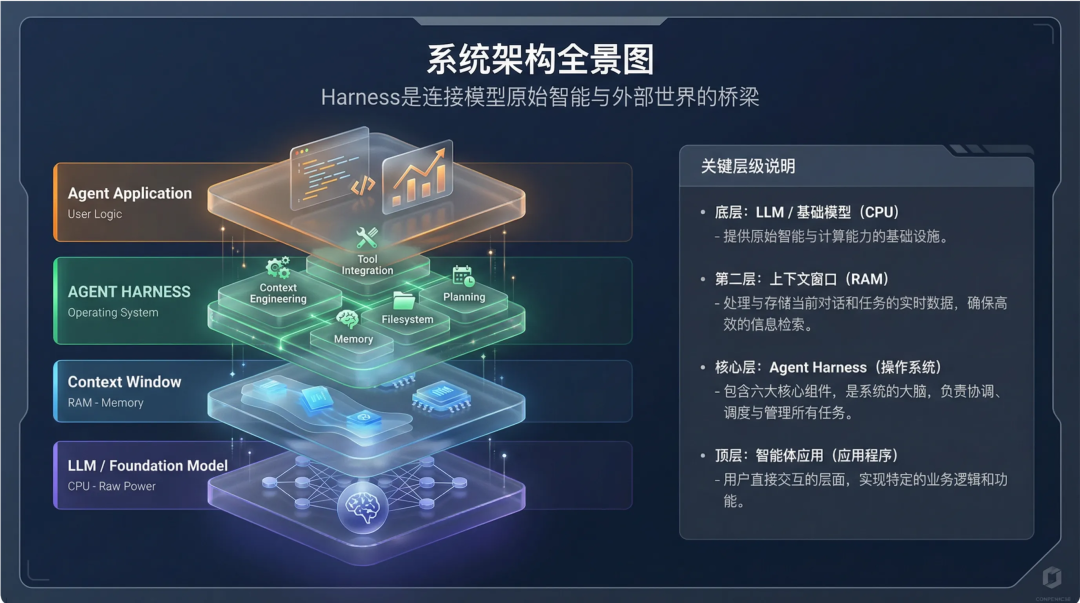
图片基于Manus对Agent Harness架构的理解绘制
「2.0 时代:面向模型设计软件,并放开所有权限给模型」
Manus、Claudecode 和 Openclaw,其实在我看来本质区别不大:它们都是“面向模型设计软件”的代表性产品。它们之所以能在最近一年集中爆发,核心原因是模型的推理能力、写代码能力持续增强——而写代码能力,本质上就是让模型能够在计算机上完成几乎一切可操作任务的基础,所以代码能力越强的模型,被套在通用智能体上,会表现出更强的效果表现。
这一点不得不说,Anthropic 对模型建设方向的战略把控确实厉害。
但 Openclaw🦞 确实通过一种更容易被大众接受的产品交互形式,外加更激进的策略——把几乎所有权限开放给它,并帮助它连接与我们相关的、在计算机上的各种软件与服务,再把这些能力集成到我们最常用的 IM 通信软件里,以一种“随时可用、顺手就能用”的方式来操作——从而在短时间里制造了大量炫酷的 aha moment,快速形成新的共识,直接打开了人们的想象力。
不过在我看来,它的底层能力依然与 Claudecode、Manus 相似。真正更进一步的,是“像造人一样去造软件”的思想在 Openclaw 的作者这里被推进到了更激进的阶段——尤其是它还引入了一种“心跳”的设计理念:就像人类的日常一样,系统可以不定时地回顾与反思我们的工作、已办与待办事项,进而产生新的想法与意识,延伸出更多规划与任务,并继续执行。
我也非常认同作者最近在播客里分享的一些思考与理念,以及他“想到就去做”的行动能力。

「快速进化的模型技术,不断变换的软件形态,不变的技术是什么?」
当一切都围绕模型被重新构建时,真正不变的核心到底是什么?在我看来,是 Context。
国内技术圈这几年创造了很多词去描述 Context,比如“提示词”“提示词工程”。从表面看,Context 似乎简单得不可思议:不就是用自然语言写几句话吗?这有什么重要、有什么难的?——这是一个非常大的误区。
你也完全可以用同样的方式去“贬低”传统软件:不就是用代码在操作内存和 CPU 吗?有什么难的?但我们都知道,软件真正的能力边界,恰恰就来自于你如何组织这些基础要素。Context 也是一样。毫不夸张地说:你对 Context 的理解深度,决定了你的产品最终能做出什么效果。甚至你作为用户,你对 Context 的理解,也会决定你在这个阶段使用智能体的效率与上限——有的人觉得“它就这样”,有的人能把它用到像拥有“无数个更好而不知疲倦自己”。
而 Context 在工程实践里还延伸出一个更“产品化”的概念:记忆。所谓记忆,本质上就是:你每次调用模型时,往 Context 里持续填入的那些信息与结构(偏好、习惯、历史、目标、约束、工具状态等)。
Context 之于 LLM,会决定它输出的一切内容。因为每一个新的 Token,都会由过去已有内容所决定概率——它是在“沿着你给的上下文继续推演”,技术一点的表达就是会改变下一个Token的概率分布。
把这件事类比到人类身上就更容易理解:你今天做事的方法论,其实深受你过去的学习经验、工作经验、逻辑结构与思维偏好的影响。你会基于这些经验与记忆采取行动,并进一步影响世界。换句话说,你的经验与记忆,就是你的 Context。
模型也是一样:你给它什么 Context,它就会以什么方式推理,并输出什么内容。
Anthropic 这家公司有一个很厉害的地方:他们擅长用大多数人更容易理解的方式,去“包装”使用模型的技术。过去他们推 mcp,今天他们推 skills。尤其是 skills——在我看来,它是这个阶段非常重要的定义与创新:它用一种普通用户更容易理解的方式,把“如何影响 Context”这件事产品化了,让用户可以通过编写 skills 、agent.md的方式,直接改变模型的 Context,从而改变模型做事的效果。
当然,不排除随着技术继续进化,skills 这种形态未来也会消失。比如 openclaw 已经在尝试让模型“替自己”把用户满意的习惯与经验沉淀总结成 skills。看起来是新形态,但本质仍然是在操作 Context。
所以无论三年后 skills 还在不在,Context 一定还在。就像很多程序员今天已经不需要手动管理内存,而是使用更高级的数据结构与抽象——底层的内存并没有消失,只是“操作内存的方式”在演化。
我相信,操作 Context 的方式也会不断演化,包装会变,但核心不会变。

图片来自nvdia developer-blogs
「这些变化带来的启示」
以 Anthropic 为代表,CludeCode 的迭代仍在持续:它不断拓宽可解决问题的边界,并正尝试通过更便捷的、非 CLI 的桌面端形态,去挑战更多垂直场景,为部分行业生产力赋能。与此同时,我也看到越来越多领域在用“通用智能体”的思路重构既有产品——从工具形态到交互方式,再到价值交付路径,都在被重写。
Manus 的母公司在国内叫“蝴蝶效应”。这只小蝴蝶轻轻扇动几下翅膀,所快速形成的行业共识,已经引发了数千亿、甚至上万亿市值的传统软件公司估值重估与回撤。未来关于“软件”的叙事逻辑,从这一刻起已经发生了根本性变化。
过去衡量产品成功的标准,是 DAU 有多少、用户使用时长;而这一代 AI 产品真正争夺的,是人类愿意“外包”的经济效用总量——也就是有多少真实的工作、决策与表达,人类愿意交给 AI 去完成。换句话说,关键不在于用户打开了多少次,而在于人类愿意授权给 AI 执行的任务,其经济价值到底有多大。
当然,今天通用智能体能覆盖的任务仍然有限,但它已经证明了这种形态的商业成立:已经有超过 1 亿美金的付费用户在为此买单。很多原本自己懒得做、不愿意做、也不值得专门雇个人来做的事情——以及那些频率不高、但流程固定的任务——正在被通用智能体快速替代。
但与此同时,仍然存在大量任务具备更高门槛:高失败代价、高不确定性、强情境判断,或者需要持续的人类信任与责任承担。在这些任务上,Openclaw、ClaudeCode 和 Manus 还不是更优解——而这恰恰是深度垂直领域智能体的巨大机会。
最后引用我之前看到的一句话作为结尾:
“决定这一代 AI 天花板的,是谁能进入更高价值、更高责任、更高决策密度的任务结构。这一代 AI 的终局形态,可能也不会收敛成一个单一的超级智能体,而更接近一整套分布在不同任务层级上的智能系统网络。”

