01 实践背景
自从ChatGPT问世以来,大模型凭借其强大的语义理解和生成能力开始在多个领域引领技术变革。但大模型在房产推荐场景的应用上仍存在一些瓶颈:
其一,数据形态的适配难题。房产推荐依赖房源价格、户型、地理位置等强结构化数据,而大模型则更适配自然语言文本,这要求构建起推荐特征与大模型输入之间的有效转换。
其二,大模型响应的时效挑战。算法需要根据用户的线上行为实时调整推荐方向,大模型由于其计算速度影响很难在用户兴趣变化时快速响应。
其三,参与模式的边界定义。大模型有多种参与推荐的形式,可以是直接生成推荐或辅助特征提取,需要讨论哪种更适合房产场景。基于以上背景,58同城房产事业群(HBG)推荐算法团队和58同城AI Lab进行深度的项目合作,以多业务、多场景、多模式的方式开展算法落地实践,尤其是在大模型画像推理和大模型Embedding上,取得了一些阶段性成果,本文将分享我们的实践案例及经验。
02 实践案例
2.1 大模型画像推理项目案例
应用策略
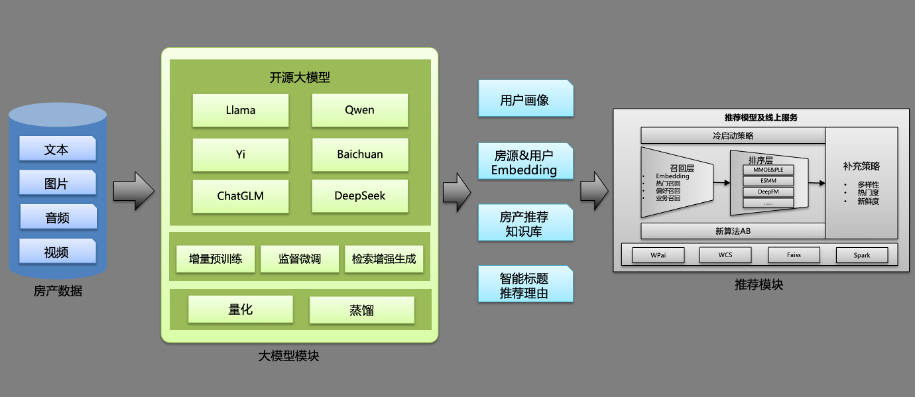
图1:大模型应用流程架构图
在二手房推荐系统中,用户画像的构建是提升推荐效果的关键。本项目通过融合用户的行为数据(如搜索、筛选、点击、收藏、电话、微聊等)和房源内容特征,构建出用户找房路径的文本作为Prompt提示词输入大模型中。经过大模型的推理,获取用户画像偏好的房源信息文本,并将文本解析为推荐系统可用的画像数据,应用于召回、精排、重排等过程中。
首先,用户行为数据的收集和分析是构建用户画像的基础。通过对用户在平台上的各种行为进行跟踪和记录,可以了解用户的兴趣偏好、购房需求以及决策路径。例如,用户频繁搜索某一特定区域的房源,或者对某一价格段的房源表现出较高的点击率,这些行为数据都可以作为构建用户画像的重要依据。
其次,房源内容特征的提取和融合也是关键步骤。房源的特征不仅包括地理位置、价格、面积、户型、装修情况等结构化特征,还包括房源描述、小区点评等非结构化特征,以及图片、视频等多模态特征。通过将这些特征与用户行为数据相结合,可以更准确地描绘出用户的购房需求。例如,用户可能更倾向于选择某一商圈内的房源,或者对某一特定小区的房源表现出较高的收藏率。
最后,将大模型构建好的用户画像数据应用于推荐系统的各个环节。在召回阶段,根据用户的偏好筛选出符合条件的房源;在精排阶段,根据用户的详细需求对房源进行排序;在重排阶段,根据用户的实时反馈和业务数据效果进行调整。通过这种方式,可以显著提升推荐的精准度和用户满意度。
优化技巧
在二手房画像推理项目中,优化技巧的应用对于提升模型效果至关重要。以下是几种关键的优化技巧
Prompt优化:
使用角色扮演、思维链等常规方法,帮助大模型理解自己需要承担的推理任务。
在画像推理过程中,期望返回固定个数的偏好实体,比如5个小区,但由于大模型对个数不敏感,经常会返回Prompt中的全部小区。通过调整Prompt,使用填空方式限定数量,有效解决个数问题。具体格式如下:{区域1:Q1 ,商圈1:S1 ,商圈2:S2 ,商圈3:S3 ,小区1:C1 ,小区2:C2 ,小区3:C3 ,小区4:C4 ,小区5:C5 ,相似小区1:SC1 ,相似小区2:SC2 ,相似小区3:SC3 ,价格段:xx-xx 万元,面积段:xx-xx 平方米}。这种方式不仅限定了返回的数量,还使得返回结果更加结构化和易于解析。
参数优化:根据应用场景对温度系数进行调整。温度系数越大,模型更倾向于从较多样且不同的词汇中选择,这使得生成的文本风险性更高、创意性更强,但也可能产生更多的错误和不连贯之处。在画像推理中,通过不断的尝试,最终选设置temperature=0.08进行推理,取得了较好的效果。
画像推理:将大模型构建的特征数据接入二手房默认列表页推荐位后,对比之前使用规则提取的特征数据,人均连接数提升2.37%,其中北上广深一线城市效果比较明显,人均连接数提升5.33%。这表明,通过优化画像推理过程,可以显著提升推荐系统的效果,尤其是在一线城市中,用户的需求更加多样化和复杂化,优化后的推荐系统能够更好地满足用户的需求。
房源推荐知识库:主要通过离线汇总一些相似小区、相似商圈等关系数据,用于线上推荐使用。这种知识库的建立,可以为推荐系统提供更多的参考信息,使得推荐结果更加精准和全面。例如,通过分析相似小区的房源特征,可以为用户推荐更多符合其需求的房源。
通过以上优化技巧的应用,二手房画像推理项目在提升推荐系统效果方面取得了显著的成果。不仅提高了用户的人均连接数,还在一线城市中取得了更为明显的效果。
2.2 大模型Embedding推荐案例
应用策略
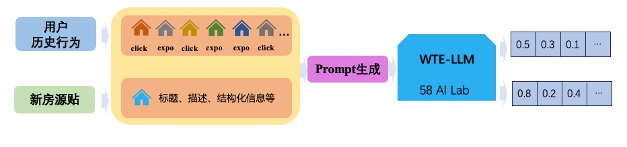
图2: Embedding生成流程图
在推荐系统中,用户和房源的Embedding生成是提升推荐效果的核心技术之一。与传统的画像策略不同,Embedding策略通过将用户、房源、小区等对象的文本描述作为Prompt输入大模型,输出为高维向量(Embedding),并将这些向量直接用于推荐的召回和精排过程中。这种方法不仅能够捕捉用户和房源的深层次特征,还能通过向量之间的相似度计算实现精准匹配。
首先,用户和房源的特征文本描述是生成Embedding的基础。用户特征包括用户的筛选搜索行为、点击偏好、收藏记录、对话消息等,而房源特征则包括地理位置、价格、面积、商圈信息等。通过将这些特征转化为结构化的文本描述,可以构建出高质量的Prompt输入。例如,用户的文本描述可能包括“频繁搜索CBD商圈,偏好面积在100-200平方米的办公空间”,而房源的文本描述可能包括“位于CBD商圈,面积150平方米,价格500万元”。
其次,大模型的选择和优化是生成高质量Embedding的关键。在本项目中,HBG算法团队与58同城AI Lab深度合作,采用了AI Lab自研的文本向量化模型族Wuba Text Embedding(WTE)。其中,WTE-chatling-7b是基于灵犀大模型chatling-turbo为基座的首个WTE模型。该模型通过整合双向注意机制,增强了情境理解能力,并在涵盖房产、招聘、生活服务等场景的庞大文本语料库中进行了全面训练。预训练阶段使用了弱监督数据,确保模型适用于广泛的下游任务;微调阶段通过改进的对比损失函数,结合双向对比和扩展负样本,进一步提升了训练效率和模型性能。
最后,将生成的Embedding向量应用于推荐系统的召回和精排过程。在召回阶段,通过计算用户Embedding与房源Embedding之间的相似度,筛选出最匹配的房源;在精排阶段,结合用户的详细需求和房源的详细特征,对房源进行排序。通过这种方式,可以显著提升推荐的精准度和用户满意度。
优化技巧

图3: Embedding可视化图
在大模型Embedding推荐项目中,优化技巧的应用对于提升模型效果至关重要,以下是几种关键的优化技巧:
Prompt优化:在实际使用中,我们对大模型自身的Prompt范式进行调整,只需要对Query进行prompt优化,即可提升模型性能。例如,在构建Prompt文本时,多保留数字ID,灵活调节各个特征文本的位置,对数字进行取整从而提升出现频率。通过以上方法可以构建出高效的Prompt来让大模型抽取Embedding。具体来说,用户和房源的文本描述中应包含详细的数字信息(如价格、面积等),并通过调整文本顺序和格式,使得模型能够更好地捕捉关键特征。
模型加速:在部署阶段,我们紧跟前沿技术,完成了模型在基于Rust推理的Text Embedding Inference框架和基于Python的SGLang框架两种框架下的推理加速。经过加速后,模型的推理速度相较于原始的sentence-transformer推理方式提升了10倍,有效应对了大流量场景下的推理耗时要求。这种加速技术的应用,不仅提高了系统的响应速度,还降低了计算资源的消耗。
Embedding特点的利用:在实验过程中,我们发现大模型Embedding具有以下特点:对数字ID敏感,对文本内容的位置敏感,对高频文本敏感。因此,在构建 Prompt文本时,我们特别注重保留数字 ID,灵活调节各个特征文本的位置,并对数字进行取整以提升出现频率。例如,将“房屋总价是 500万元”调整为“价格 500万元”,将“面积 75.86平方米”调整为“面积 75平”。通过这些方法,可以显著提升 Embedding 的质量和推荐效果。
实验结果:通过以上优化技巧的应用,相关推荐场景都取得了不错的效果,譬如商业地产大类页推荐系统在上线后,人均连接数提升了6.61%。这一显著的效果提升,证明了Embedding策略在推荐中的有效性和优越性。尤其是在大流量场景下,优化后的系统能够快速响应用户需求,提供精准的房源推荐。
2.3 大模型对话式推荐案例
在新房智能微聊助手中,我们也尝试应用大模型进行推荐和问答,由于在微聊界面中,用户的输入数据形态不固定,存在文本,语音,图像等数据的输入,因此我们需要针对这类数据进行解析从而进行房源的推荐。
具体实施方案如下:在助手与用户的实时对话过程中,我们的系统能够动态解析用户的意图,有效区分问答、闲聊及推荐等不同场景。同时,系统会实时捕捉并分析用户的购房偏好。例如,在一个典型的交互场景中,用户首先询问了房源的价格,随后进一步询问了三房户型的信息。基于这些连续的意图,系统能够推断出用户实际上是在询问三室户型的价格。紧接着,当用户通过语音输入提出房源推荐需求时,系统会根据之前记录的上下文信息,优先推荐符合用户偏好的三室房源。这种基于上下文理解的推荐策略,不仅提高了推荐的准确性,也极大地提升了用户体验。
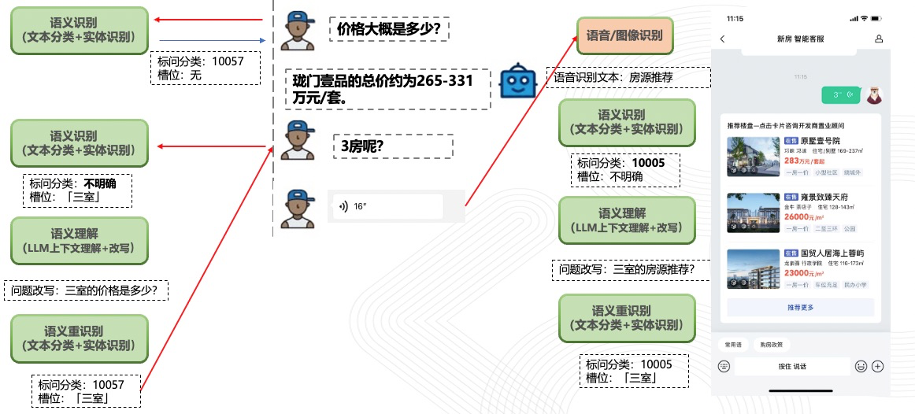
图4: 大模型对话式推荐案例图
03 展望
在58同城&安居客的房产推荐场景中,HBG算法团队始终以业务需求为中心,深度融合技术探索与场景落地,通过与58同城AI Lab的深度协作,成功将大模型技术在推荐场景中转化为实际业务价值。在工程方面,基于Rust推理的Text Embedding Inference框架和基于Python的SCLang框架使得模型响应速度提升10倍,成功支撑起推荐这个大流量场景的实时需求。
未来,HBG算法团队将围绕三大方向持续突破,深化与AI Lab的技术协同,构建更智能的大模型推荐生态:
1. 多模态融合:从文本到全域感知
当前大模型推荐落地已实现对房源文本的高效理解,但找房用户决策往往依赖图片、视频等非结构化数据,如户型图和小区实景。后续加强与58同城AI Lab的技术合作,探索跨模态对齐技术,优化算力资源调度,推动多模态大模型在房源推荐场景落地。
2. 生成式推荐新范式:从匹配到创造
传统推荐系统依赖历史行为匹配,而生成式大模型可以主动创造用户潜在需求。基于房产领域专属的生成式推荐模型,实现三大突破:其一,根据用户画像生成个性化房源描述,提炼其核心需求,做到更懂用户。其二,提升虚拟顾问能力,通过对话式交互引导用户明确需求。此类推荐新范式将改变用户体验,提升用户粘性并创造更多房产服务需求。其三,使用 itemId 序列作为训练语料,通过学习用户行为序列(如点击、购买等)中的模式,预测用户可能感兴趣的下一个itemId或一组推荐itemId,生成个性化推荐。
3. 生态共建:技术开放与价值共享
HBG算法团队始终秉持开放共赢理念,在大模型技术落地的过程中积累了一套覆盖数据处理、模型优化、高性能推理的标准化技术方案。未来,将会推动大模型能力在更多业务和场景上应用起来,推动房产服务的智能化升级。
04 结语
大模型技术的迭代为房产推荐打开了全新想象空间,而业务场景的复杂性也要求技术团队兼具行业洞察与工程攻坚能力。HBG算法团队凭借对房产业务的深刻理解、与AI Lab的紧密协同,以及持续创新的技术魄力,在推荐系统升级中积极引入大模型能力,取得多个业务和场景阶段性的成果。我们坚信,继续深入多模态融合、探索生成式推荐新范式、共建开放生态,大模型将成为连接用户需求与房产服务的智能中枢。以场景驱动技术突破,以合作加速价值创造,共同定义下一代房产推荐的新范式。

