导读
大模型在研发效能领域代码生成方面发挥了越来越大的作用
而大模型的预训练依赖大量的精标代码,这些精标数据必须是比较好的工程实践代码
这些比较好的工程实践代码,需要大量的技术沉淀,包括工程架构,代码架构等多纬度,涉及性能、可用性、扩展性、安全等方向
百度网盘有不少比较好的工程实践,本文主要是介绍百度网盘工程架构中的防雪崩架构
抛砖引玉,与大家一起探讨什么才是优秀的工程实践,为大模型的落地提供坚实的数据基础
01 背景
1.1 百度网盘业务背景介绍
简要介绍一下百度网盘的业务背景
外部视角:用户规模超过10亿,单纯外部用户请求日pv过千亿;
内部视角:实例数超过60w+个,模块数规模过千,单个功能最多涉及100+个模块节点。
在复杂的链路+高并发情况下,短暂的异常就会使得整个系统出现雪崩,即使异常消失也无法自愈,对用户产生不好的用户体验。
于是百度网盘服务端工程方向设计了一套防雪崩的机制,本文先介绍雪崩的技术背景,再介绍相关的解决方案。
1.2 雪崩发生的背景介绍
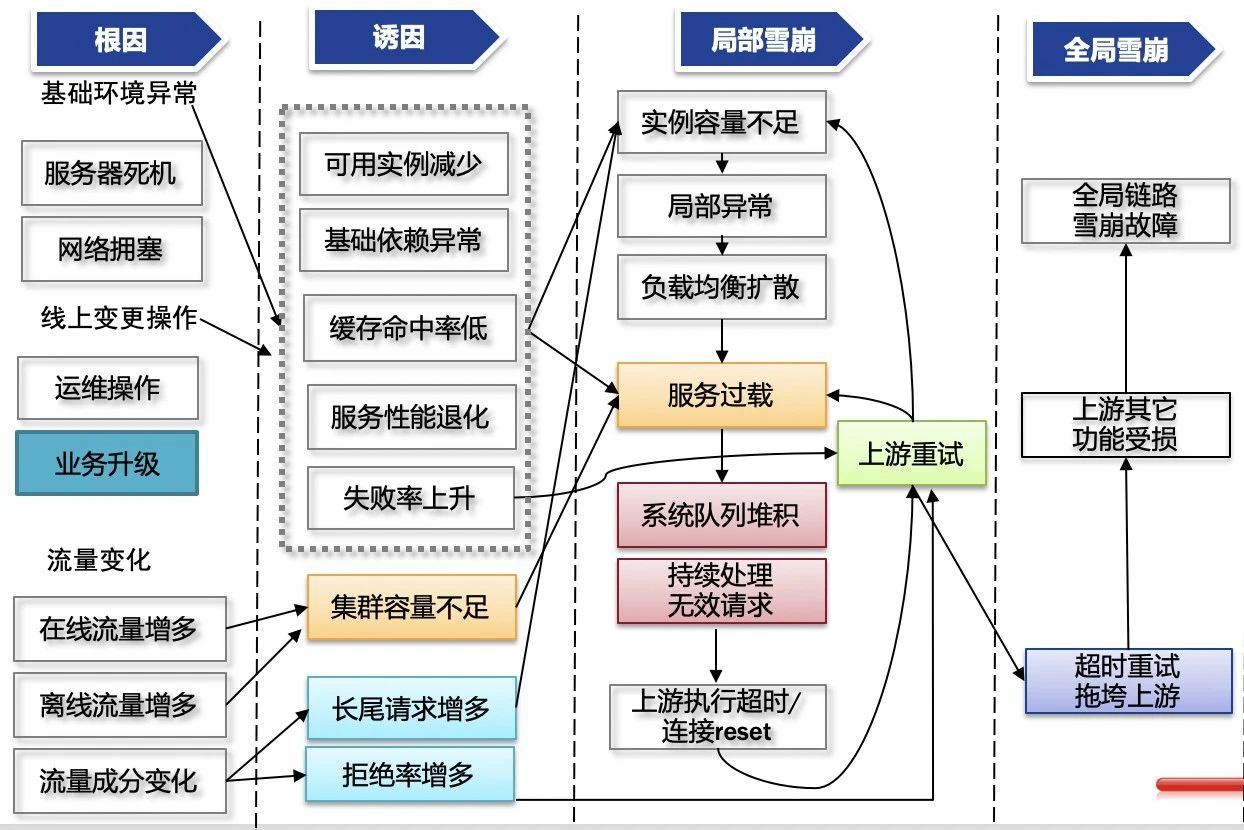
雪崩是如何发生的?简单的说,某种场景下,触发一个服务的处理能力(容量)不足而拒绝导致请求失败,而它的上游因为请求失败而重试,加剧服务持续处理无效请求,无法处理有效请求,从而形成雪崩死循环,服务无法恢复。
如下图所示,某个变动(根因) –> 服务异常(诱因) –> 链路异常(局部雪崩) –> 全局异常(全局雪崩)
简单来说,雪崩分成两个阶段:
初始阶段:各种根因 + 诱因 –> 服务过载;
循环阶段:上游重试 —> 服务持续处理无效请求 —> 上游重试 ……
下面将按系统视角介绍:雪崩是咋发生的?
先从服务接收&处理请求来说,根据网络TCP三次握手准则,客户端的请求会被放入半连接/全连接队列中,而服务端从队列中取出请求进行处理。由于队列是先进先出的,处理的请求都是之前的请求(即使client已经断开了连接,但是accept队列也不会剔除这些断开连接的请求)。如下图,client 向serve发了5个请求,r0/r1/r2/r3/r4,这些请求会被放入server的accept队列里,但是由于server处理逻辑比较慢,导致client请求超时,断开了连接r0/r1/r2的连接,但是server这边还会从accept队列里取出r0/r1/r2的连接,进行请求request数据的读取(即使client已经断开连接,server还是能够读到之前client发送的请求数据),进行无效的处理,于是client不停的重试,而server不停的在处理失效的请求。
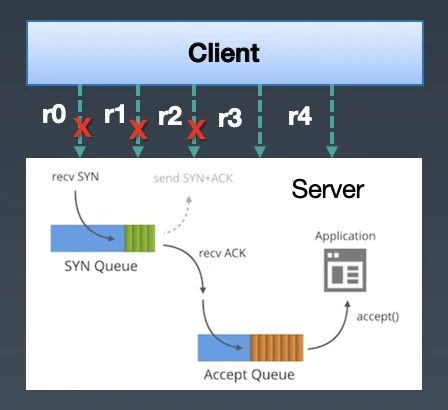
△server读到已经断开连接的socket连接
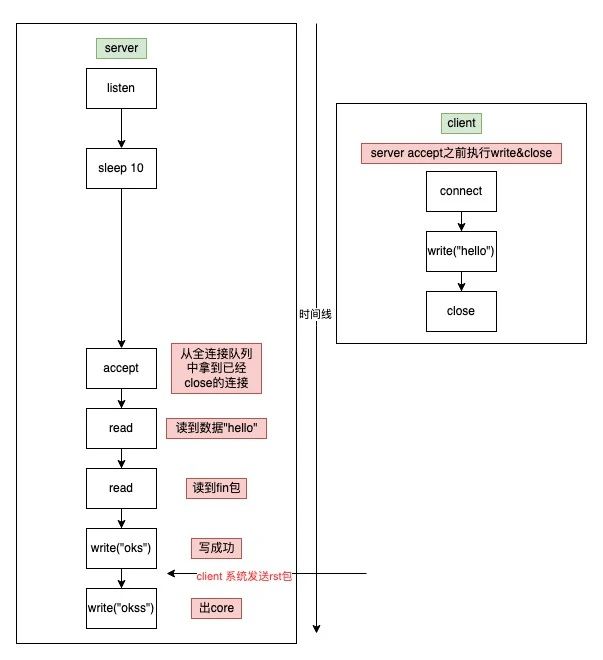
△ server读到已经断开连接的socket请求数据
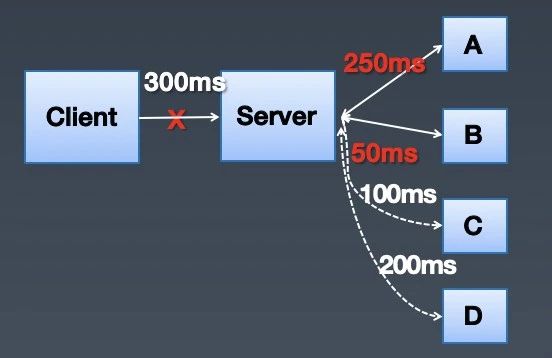
从上下游处理视角来说,雪崩并不是局部行为,它会随着链路漫延到整个系统链路上。如下图,client以300ms的超时时间访问server,server在访问A和B之后,已经用掉了300ms,这个时候client已经断开了和server的连接,但是server却继续访问C和D,进行无效的请求。当这种无效请求在整个链路蔓延开,client又在大量的重试的时候,就是整个系统崩溃的时候。
02 传统解决方案
从预防/阻止/止损雪崩三个子方向介绍相关实战经验,以及分析它们的优缺点。
2.1 预防
通过各种手段,规避雪崩初始阶段的出现,例如热点治理、长尾治理、分级操作、容量保障等。
2.2 阻止
处于雪崩初始阶段,有发生雪崩的可能性,需要阻止雪崩进入循环阶段。
【重试率控制】
基本思路:当重试请求数占当前请求数的X%, 就不会再进行重试;
优点:可以避免大量重试导致雪崩死循环;
不足:设置重试率多少才是合理的?另外,这个还需要持续更新,因为下游的容量是在变化的,可能连正常的流量都无法处理(比如实例被缩容了)。
【队列控制】
基本思路:不再基于系统层面的内核队列,应用层自己维护队列(比如用一个线程从系统读取连接数据到队列中),记录请求在队列中等待的时间。如下图,队列中有8个请求,代表他们在队列中等待的时间(单位ms),假设上游的执行是200ms,处理一个请求需要100ms,那么第1个到第4个请求明显是失效请求(最大等待时间( = 上游执行超时 - 服务处理时间) < 当前等待时间),等处理完上游都已经断开连接了,就不需要处理了,可以直接从第5个请求进行处理;

优点:通过维护应用层的队列,加上等待时间,快速抛弃无效请求,避免雪崩的发生;
不足:依赖假设上游的访问超时时间以及自己的执行时间,才能准确判断出请求是否已经失效。但是有可能不同的上游的超时时间不一样,自身的执行时间也不稳定性。同在服务在极端负载下,包括读取系统队列的线程也会受限资源,无法及时从系统队列中读取请求,导致读到了无效请求。
【限流】
基本思路:在服务接入层设置一个静态阈值,表示后端服务最大的请求qps,超过这个qps的流量就丢弃请求;
优点:可以避免瞬间突增的流量打垮服务,导致服务不可恢复,可以解决一部分场景问题;
不足:提前设置限流一个静态阈值,和重试率控制一样,不是所有场景都有效果。另外也有运维维护成本,具体如下:
阈值合理性:需要频繁压测才能知道当前系统的瓶颈qps阈值是多少,设置大了,达不到阻止过多流量的效果,设置小了,又有误伤;
故障期间服务处理能力退化:当花费了很多时间压测出来一个系统的qps阈值是100,但是故障期间服务承载的qps可能会退化成80。会有很多原因会导致,比如一部分实例oom导致不可用,上线导致实例启动失败、长尾流量导致部分实例处理能力不足(比如某些视频转码需要更长的时间,同时还是热门视频,负载均衡重试到不同实例上),最常见的是下游请求执行时间变长了。这样导致每秒都需要承载多余的qps请求,累计下来,这个系统迟早被打垮。本质问题还是静态阈值导致的。
2.3 止损
通过各种手段,加速雪崩止损恢复,例如:
限流:通过多次人工调整限流阈值,使后端请求减少,逐渐恢复;
重启服务:通过重启服务,快速丢弃系统队列中的无效请求。
属于兜底的机制,缺点是整个恢复周期会比较长。
03 解决方案
传统解决方案里,包括预防、阻止、止损三个子方向。
一旦处于雪崩状态,是不可逆的,需要比较长的时间去恢复。
所以重点在于预防和阻止,因为预防会有遗漏,更多的精力在于阻止,即处于雪崩初始阶段,有发生雪崩的可能性,需要阻止雪崩进入循环阶段。
业界的做法,其实可以分成两种做法:
减少过载流量:比如限流和重试率控制,剔除服务不能够承载的流量;
减少无效请求:比如队列控制,使得服务处理有效的流量。
这两种做法需要结合,单个做法是会有问题的。
比如减少过载流量,由于下游的处理能力是动态变化的,实际上还是会出现过载,下游会长期处于处理无效请求,无法处理有效的请求。
减少无效请求,大部分场景下是能搞定的,但是如果瞬间的请求量特别大,请求都是属于有效的,内存可能会先达到瓶颈,导致oom了。
下面介绍一下百度网盘的防雪崩架构实践。
3.1 减少过载流量-基于动态熔断
【基本思路】
业界对减少过载流量,除了上面说的静态限流之外,还有一种熔断做法,具体流程如下:
流程说明1 开始请求: 系统接收到一个外部请求。2 熔断器状态判断:- 闭合状态(Closed): 熔断器允许请求通过,继续执行。- 打开状态(Open): 熔断器阻止请求,直接失败或返回预定义的响应。- 半开状态(Half-Open): 熔断器允许部分请求通过,以测试服务是否恢复。3 执行请求:- 请求成功:- 如果处于闭合状态,则重置失败计数。- 如果处于半开状态,则关闭熔断器,恢复正常。- 请求失败:- 增加失败计数。- 如果失败计数超过预设阈值,则打开熔断器,跳闸。4 冷却时间: 熔断器在打开状态后,会等待一段冷却时间,然后进入半开状态。5 半开状态测试:- 请求成功: 关闭熔断器,恢复正常。- 请求失败: 重新打开熔断器,继续等待冷却时间。
这个熔断机制和限流一样的,都是存在静态的缺陷问题。
举个例子,当前流量的qps为100,后端只能承载10的qps。
当后端失败率超过阈值之后,触发打开状态,然后等待一段时间之后,进行半开状态,用一部分流量进行测试。
本质上是不能动态根据后端的处理能力进行流量限制转发,所以需要实现动态熔断限流。
【具体实践】
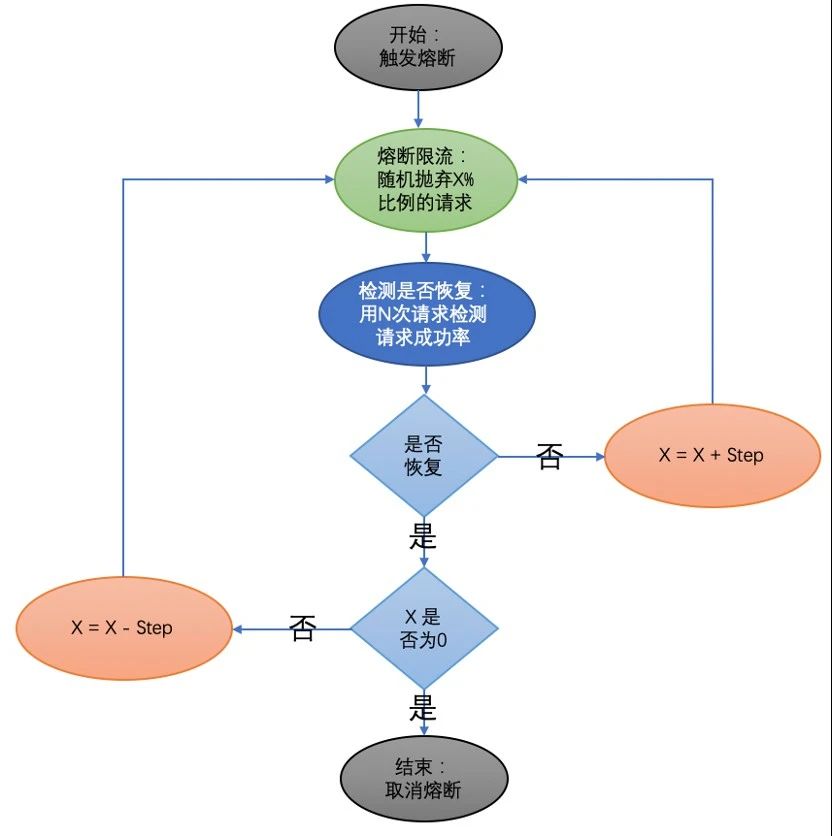
其核心思路是根据下游的请求成功率动态限制转发到下游的请求数。具体如下图所示,先随机丢弃X%比例的请求,然后进行检测,判断服务是否恢复,如果还未恢复,说明需要继续降低转发到下游的请求数,设置X = X + Step,增大丢弃请求的比例,继续熔断限流。如果已经恢复了,则判断丢弃请求的比例是否已经降低到0(即X是否为0),如果X不为0,则还需要继续减少丢弃请求的比例,设置X = X – Step,继续熔断限流,如果X为0则说明整体已经恢复,则结束动态熔断限流。
动态熔断的思想是借鉴了网络,当雪崩过载的时候,相当于发生了请求的拥塞,和网络拥塞是一样的特征行为,网络链路都带宽相当于服务的容量。
这里面其实还有一种问题没法解决,即ddos攻击。
这种一般需要有一个统一的接入层来解决,设置一个相对大的限流阈值,然后通过动态熔断来转给后端的业务。
3.2 减少过载流量-基于流量隔离
动态熔断策略相对复杂,还有一种简单粗暴的方式,即流量隔离。
适用于流量来源存在不同级别的,而且高优流量常态下比较稳定,低优流量有突增的情况。
【基本思路】
将流量进行分级,通过部署隔离解决高低优流量相互影响的问题,即使低优流量再怎么增加也不影响高优流量。
高优流量:比如用户感知明显流量等;
低优流量:比如后台流量、离线计算流量等。
【具体实践】
首先是client需要打上流量标签,其次是gateway or service mesh基于这些流量标签进行相关的流量转发。
3.3 减少无效请求-基于请求有效性
【基本思路】
上游服务A访问下游服务B的请求时间可以由以下部分组成:
请求耗时 = 上游发送请求 + 网络传输 + 下游tcp建连队列等待时间 + 下游处理时间
上游服务A发送请求:基本可以忽略,机器负载问题不再这里考虑;
请求在网络中的耗时:基本可以忽略,网络故障问题不再这里考虑;
请求在下游服务B系统队列中的等待时间:堆积太多请求会导致请求失效;
下游服务B的处理耗时:处理的慢导致请求长期阻塞在系统队列中。
不再基于单独维护一个队列的思想去解决问题。单独队列一方面是需要支持不同语言,以及准确性不足,在虚拟化的环境里,资源受限之后,队列的等待时间就不准确了,还有上游不同的超时时间,没法简单判断是否已经超时了。
这里面的关键点是上游传递一个截止时间给下游,但是如何表示该请求截止时间呢,具体有绝对时间和相关时间两种方式,相关缺点如下:
绝对时间:用绝对时间戳表示(比如1577681783),但是不同设备上的时钟不一致,如下图A和B两台机器的时钟差了2分钟,A访问B的超时时间是5s,于是请求发到机器B上就直接超时失败了,不符合预期 ;
相对时间:用相对时间表示(比如5s),但是这个时间是从业务接收到请求开始计时的,没有包括在系统队列中的时间,有可能已经等待了很久的时间了,上游已经断开了连接,不符合预期;
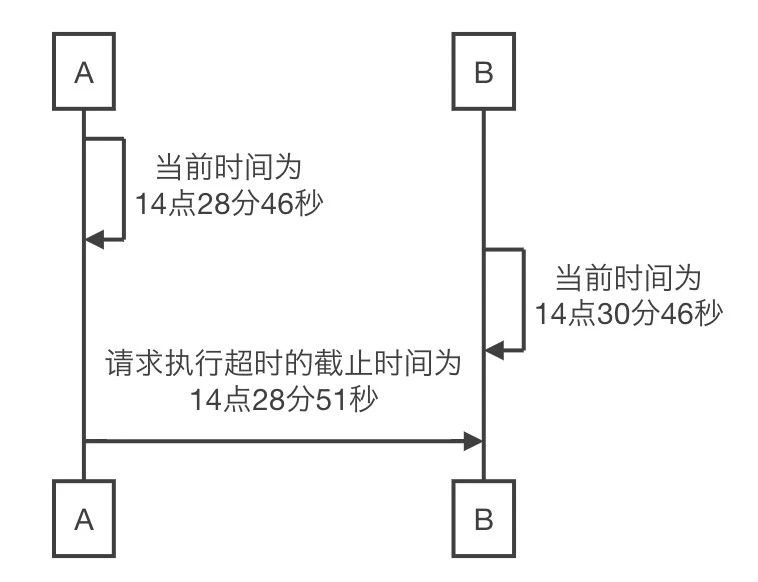
△绝对时间的问题
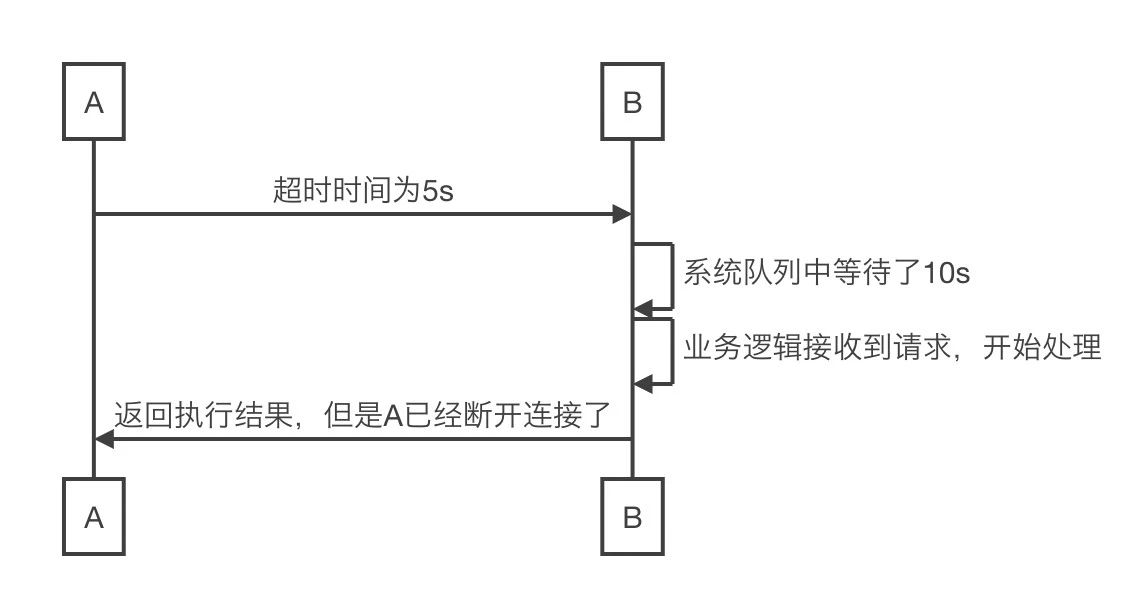
△相对时间的问题
【具体实践】
从上文可知有这么两个问题,绝对时间和相对时间解决其中之一:
机器之间的系统时钟不一致
需要关注在系统队列中的等待时间
于是可以将绝对时间和相对时间结合在一起,借助UFC(百度网盘的Service Mesh,详见之前的一些分享Service Mesh在百度网盘数万后端的实践落地)来解决问题,以下图流程为例子说明:
Host1机器上的服务A访问Host2机器上的服务B;
服务A先访问本地的UFC-agent,传递相对超时时间为5S;
Host1机器上UFC-agent 访问Host2机器上的UFC-agent,传递相对超时时间为5S;
Host2机器上的UFC-agent 把相对超时时间转成绝对超时时间;
Host2机器上的UFC-agent 访问本地的服务B。
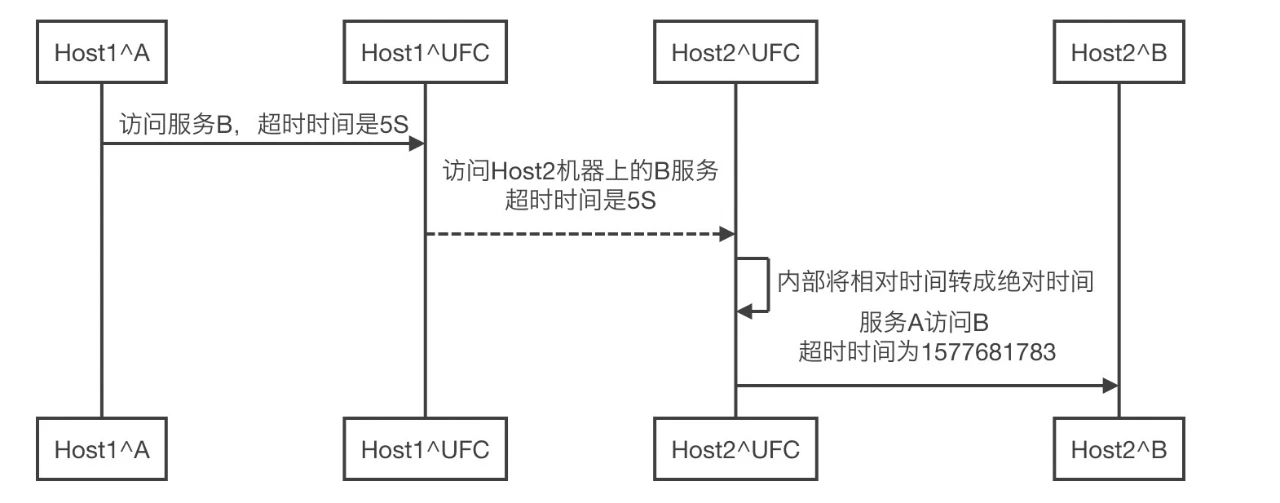
通过双端的Agent实现了相对时间到绝对时间的转换,对业务解决了上面的那2个问题,对业务也是透明的。

目前网盘的核心链路都接入了这套请求执行时间过期丢失的机制。
不过这个也是存在一些缺陷场景的,比如网络故障/ufc agent资源打满等,使用其它的解决方案来解决这些缺陷。
3.4 减少无效请求-基于socket有效性
上面是基于deadline来判断请求是否有效的,是百度网盘19年的技术方案。
当时百度网盘的技术栈还是比较多样的,编程语言包括c/c++/php/golang/ngx_lua等多种,需要从Service Mesh这种中间件来解决问题。
另外,这个依赖Service Mesh这种中间件的落地覆盖,并不是所有的业务都具备这种的前提条件。
这里提供另外一种基于socket有效性的方案来判断请求是否有效。
【基本思路】
需要有一个认知:
比如以下场景:
tcp三次握手之后,server 未accept请求,client直接调用close关闭连接;
tcp三次握手之后,server 未accept请求,client先写request请求,然后调用close关闭连接;
server accept后进行请求处理时,client调用close关闭连接。
从c语言编程视角来看,非阻塞情况下read函数返回-1表示读数据失败,返回0表示读到fin包,即client关闭了socket。
ssize_t read(int fd, void *buf, size_t count);
所以可以基于socket读到fin包事件来判断client是否已经断开连接了,如果已经断开,server则不需要处理接下来的逻辑了(异常场景收尾逻辑可能还需要)。
【具体实践】
底层socket编程这块,一般都是被编程语言/编程框架屏蔽了,这里主要是介绍一下一些常见语言/编程框架怎么判断client已经断开连接了。
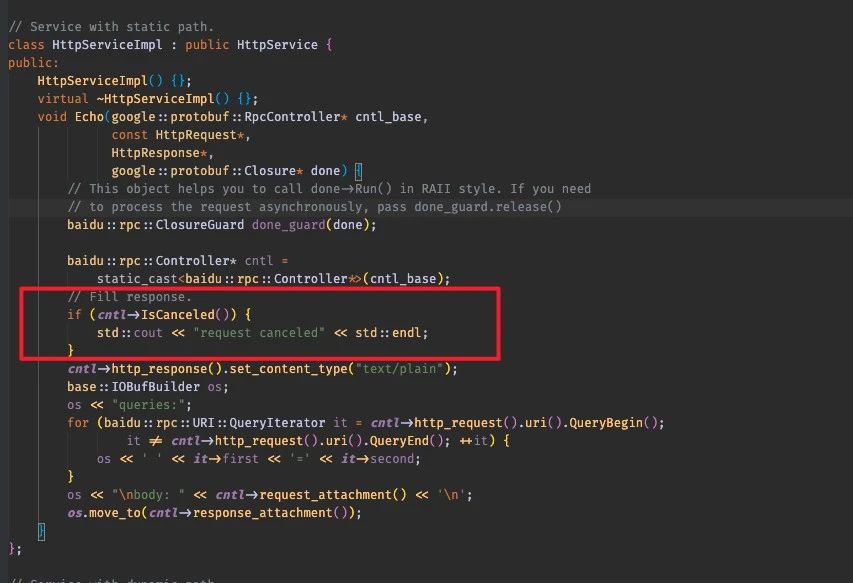
先说一下brpc框架,如下图所示,主要是调用IsCanceled函数来判断client是否已经断开了(不适用http 2.0等这样的场景)。
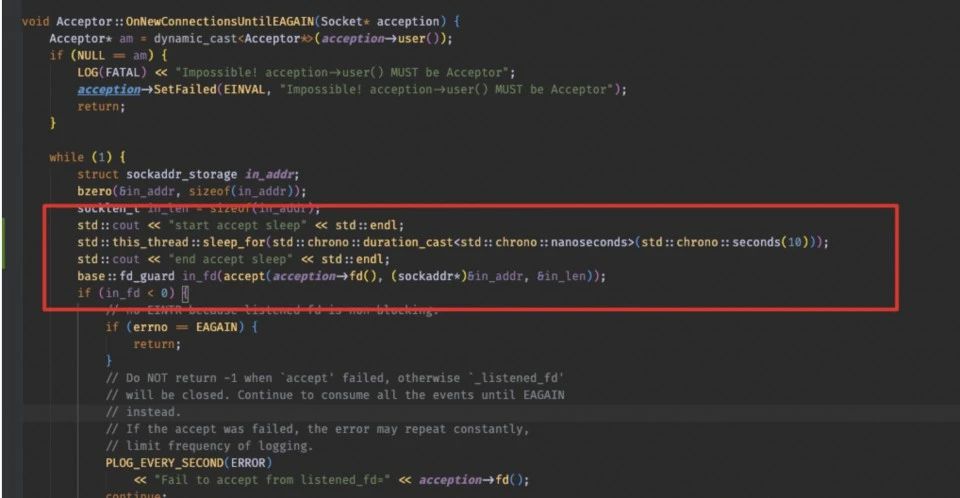
验证效果的话,可以通过在brpc框架里面的accept 逻辑前面加sleep,构造server backlog 堆积的场景进去验证。
再说一下golang语言,主要是通过http server的回调函数的参数r *http.Request进行判断的,具体是判断 r.Context().Done()。
验证效果的话,可以通过netutil.LimitListener来设置最大处理的连接数。


不过golang和brpc的内部实现还是有点不一样的,下面将举例说明:
当一个client 与server通过tcp三次握手建立连接后,进入了server的全连接队列中,client调用close关闭连接,1秒之后,server 调用accept取出该连接。
brpc通过IsCanceled是可以判断出client已经断开连接了,而golang通过r.Context().Done()却判定client还未断开连接,需要sleep若干时间之后才能判断client已经断开连接。
原因是golang在源码里是起了一个单独的协程去读socket,所以导致这个判断会出现延迟。
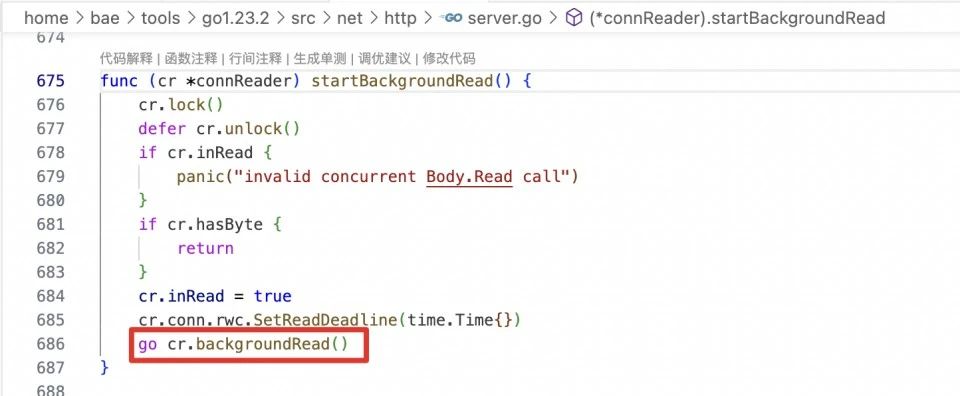
解决方案是通过ConnContext回调函数,把连接存储在context里,然后在http server的回调函数里取出连接,先读一次,这样就可以判断是否已经断开了。


04 总结
百度网盘业务形态众多,业务的高速迭代发展需要建立在可靠的架构基础之上。
在整个架构演进过程,可用性是非常重要的事情,于是设计了一套防雪崩架构,具体包括两部分:
流量限制:可以分成两部分,一个是流量接入层,解决ddos连接数攻击,另外一部分是流量转发层,通过动态熔断策略将后端能处理的请求数转发给后端;
流量处理:业务基于流量有效性进行处理,避免处理无效请求。

最终对雪崩的治理也取得了不错的效果,单个季度可以规避若干次的雪崩故障发生,保障了网盘业务的可用性。

