背景
随着B站大数据业务的高速发展,各类业务资源需求也随之快速增长。与此同时,大数据集群有效的资源利用率低于预期,究其原因主要有以下两点,
业务出于性能、稳定性考量会向平台申请过量的系统资源,导致平台不会调度更多任务上来运行。
对于高低优任务资源隔离能力不足导致有竞争时,高优任务受影响甚至被误杀。
为了解决业务资源过量,大数据团队在hadoop架构中加入了自研超配组件Amiya。Amiya依据用户申请的资源量一般大于用户真实使用的资源量的基本推论,根据当前机器的实际负载情况,向调度组件虚报一定的资源量,使得更多的任务能够被调度到服务器上。同时,在大部分任务申请量接近其真实使用量时,Amiya需要及时驱逐一定量的任务以保证服务器整体稳定运行,关于Amiya细节信息可参考B站大数据集群混部实践(上)- 资源超配篇。
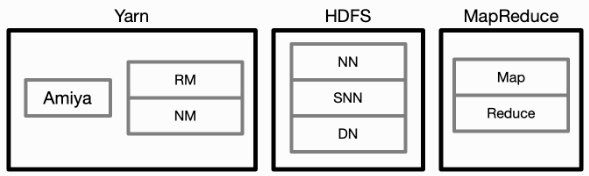
随着Amiya正式上线,更多的任务有机会被调度运行,提升了整机任务密度,日均资源利用率提升幅度约15%。但是利用率的提升也使得任务间资源隔离问题日益凸显,多次出现资源竞争导致高优任务被杀。需使用OS提供底层资源隔离能力才能根治。
需求分析
为了解决大数据业务资源竞争问题,通过数据监控观察了从CPU、磁盘IO、网络、内存四个维度分析业务资源瓶颈。
CPU,CPU idle均值在30%以上,且CPU使用率打满时段占比在4%以内,故CPU并非整机资源瓶颈。
网络,带宽资源也较富裕,并未达到带宽上限,且交换机侧没有网络反压相关报文出现,同样非资源瓶颈。
磁盘IO,监控使用了ioutil%作为监控信息,可以看到在一定时段内磁盘确实十分繁忙,但由于磁盘IO的复杂性,单凭ioutil%指标不足以说明磁盘达到瓶颈,需要更加完善观测指标才能下定论。
内存,整机内存资源使用已达较高水位,系统日志显示触发oom-killer频率较高,同时还存在以下几个问题,
业务侧
不同的任务之间没有优先级,竞争情况下无法区分哪些任务优先给予资源。
由于内存资源竞争触发OOM-killer杀死data-node,存在数据丢失的风险。
系统侧
内存资源紧张时,由于内存使用达到cgroup设定上限,会在任务上下文频繁内存直接回收,导致任务内存分配出现高延迟。
由于内存资源瓶颈,超配组件出于稳定性考虑没有继续调高超配比,限制了资源利用率进一步提升。
解决方案
如前文所述,大数据业务的资源瓶颈主要是内存,需要使用系统底层的内存隔离能力来解决。根据当前场景中的问题解决方案如下。
制定任务优先级
为解决优先级缺失问题,先和业务确认了各个组件的重要程度。
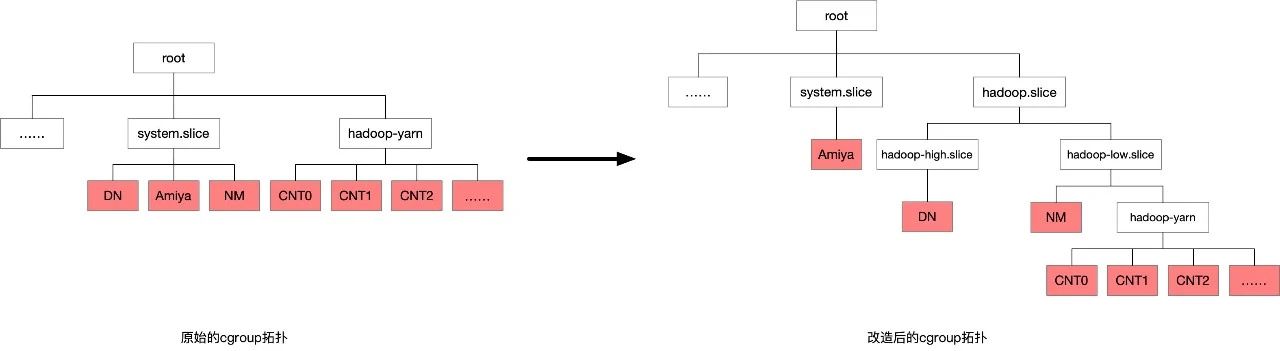
在大数据场景中,DN负责数据存储,如果DN受影响可能会导致丢数据,影响面较大,故该场景中将DN定义为高优先级任务;NM负责执行任务容器,单个NM如果被杀,对集群影响并不大,且NM负责的全部计算任务可以通过重试机制,继续运行,故将NM定义为次优先级;而大数据计算任务如果被杀死,单个任务也可通过重试机制继续运行,影响程度最小,故将任务容器定义为低优先级。
memory cgroup可以通过不同的cgroup层级设定不同参数的方式来区分不同的任务优先级,故需对hadoop各个组件cgroup拓扑做改造,如下图所示。遵循两个原则,1. 层级越高优先级越高;2. 同样层级通过之后的cgroup参数区分优先级。
OOM杀DN问题
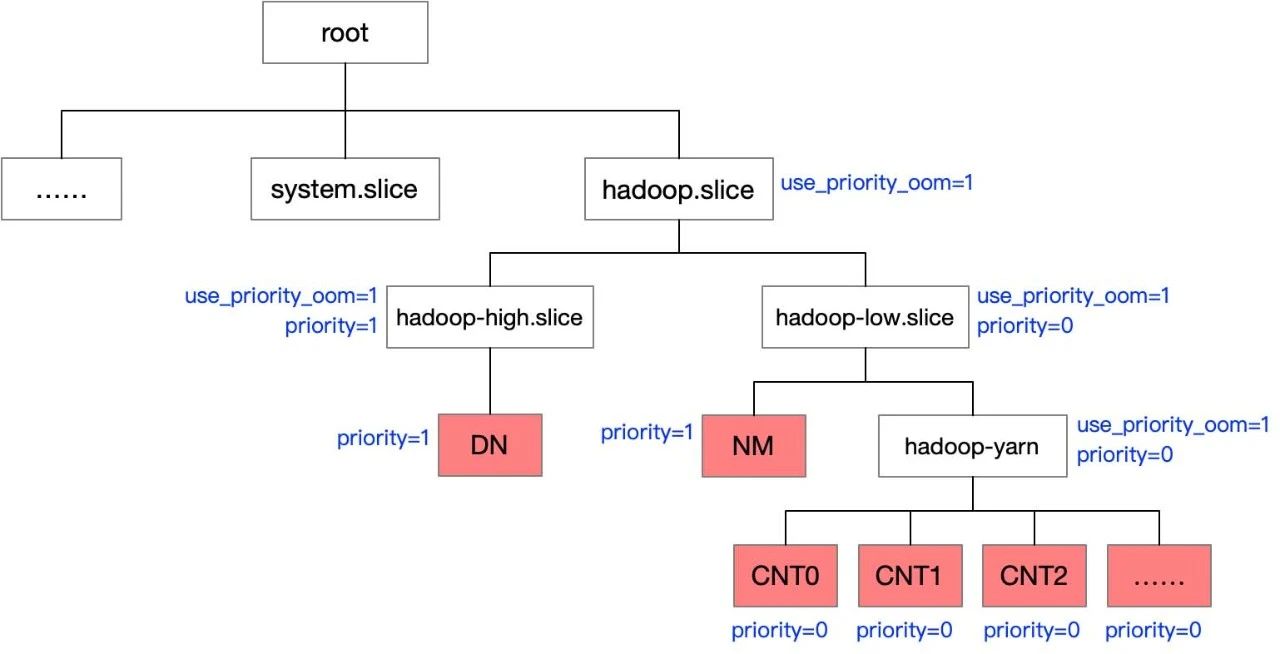
为解决业务侧遇到的内存资源竞争相关问题,OS团队使能了内核OOM优先级特性,细节参考资源隔离技术之内存隔离。对不同的cgroup做优先级区分,在进行oom kill操作时,会首先判定cgroup的优先级,选择低优先级的cgroup进行oom kill操作,从而保证高优先级任务可以稳定运行。
其次,对各个层级配置如下图所示。配置完成后,优先级分为前文所述三层,DN优先级最高,NM优先级次之,任务容器(CNTx)优先级最低。当hadoop.slice层级触发memcgroup OOM时按优先级从低到高选择任务杀掉;当hadoop-low以及hadoop-yarn层级触发了memcgroup oom也只会杀NM或任务容器,保障了DN受影响程度最低。
内存分配延迟
为避免业务内存分配延迟过大、降低cgroup级别内存直接回收频率,OS团队使能memcg后台异步回收特性,细节参考资源隔离技术之内存隔离。该特性基于cgroup内存上限又设定了一条水位线,在cgroup内存使用量达到该水位时启动后台线程对memcg做内存回收。
这里我们将水位线如下图设为95%,当对应cgroup内存使用达到memory.limit_in_bytes的95%时触发后台回收,拉起一个异步线程提前开始内存回收的工作。

收益预估
为了测试内核特性效果OS团队抽取了一批线上机器开启了相关内核混部特性,开始预估混部特性收益。从DN被杀死的频率、内存直接回收延迟两个维度来评估收益。
DN被kill频率
根据大数据团队反馈更换混部内核之前,DN被杀死的频率约为1周1次,评估时长为期两周。
使能内核oom优先级特性后,通过扫描系统dmesg日志信息来查看是否存在OOM杀死高优任务的情况。
观察结果符合预期,两周内没有高优任务DN被杀死情况出现,但因DN被杀本身出现频率不高还需要扩大一些部署规模进一步验证效果。
$ dmesg | grep constraint= | grep /hadoop-low | wc -l45$ dmesg | grep constraint= | grep /hadoop-high | wc -l0
memcg直接回收延迟
OS团队抽取了两台线上机器,评估时长为期6天。6天时间内,每隔一天开启/关闭memcg后台异步回收,同时观察hadoop.slice cgroup内核统计信息。对比的统计指标为一天内内存直接回收次数、一天内内存直接回收延迟时间总数。
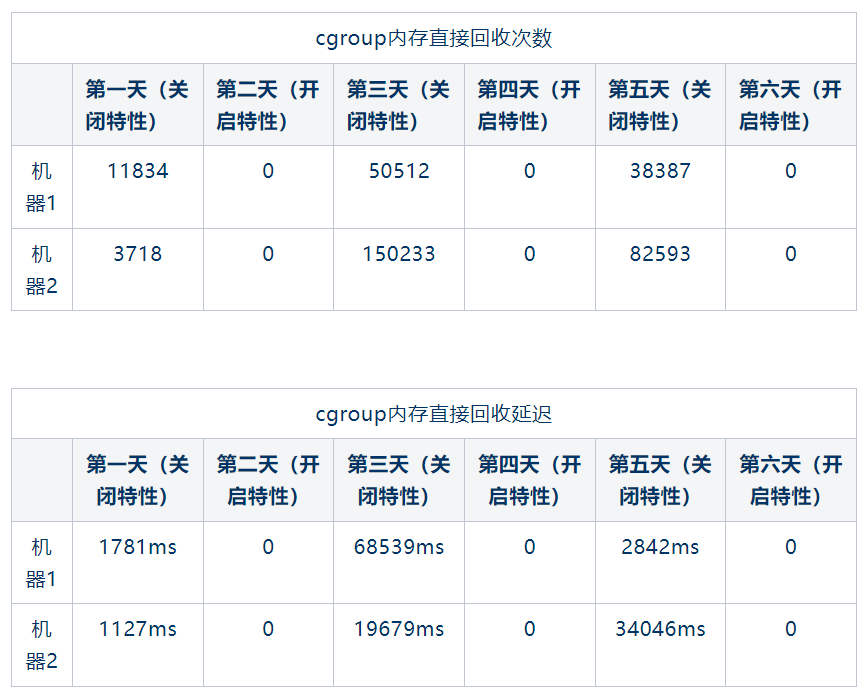
可以看到,同样机器在开启memcg异步回收的时间段内可以有效降低内存直接回收频率,从而改善因内存直接回收带来的任务延迟,符合预期效果。
CPU调度延迟
除了上述测试外,OS团队还验证了CPU调度特性Group Identity(GI)。GI可以保障高优先级任务的CPU唤醒延迟最小化,从而避免低优任务影响高优任务的调度延迟。同时,统计hadoop.slice cgroup的CPU内核调度延迟分布情况。
测试三天的平均值如下表所示,
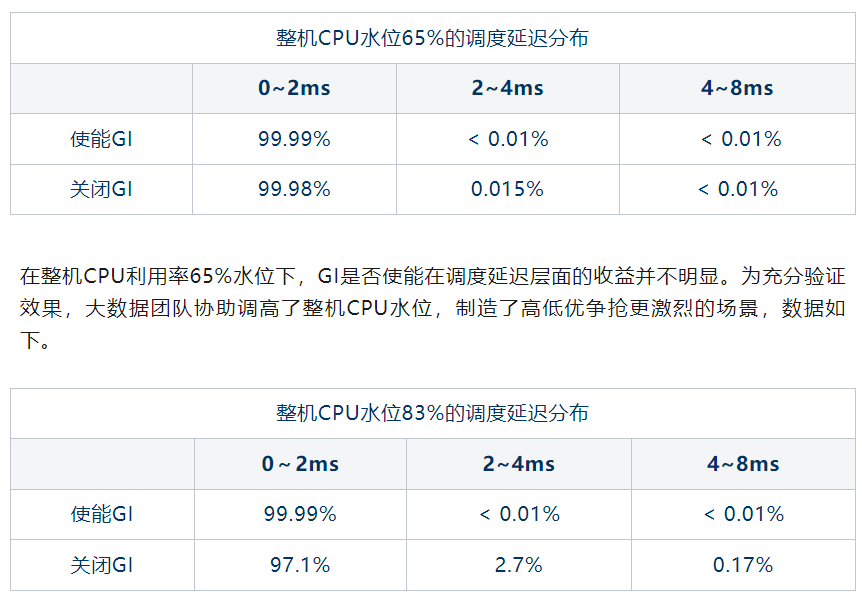
可以看到在CPU争抢较为激烈情况下,GI能够保证99.99% QOS在0~2ms之内。但目前场景中还达不到这么高的CPU水位,所以该特性收效在当前场景中并不明显,符合最初“CPU并非整机资源瓶颈”的推断。
至此,对各个特性收益有了基本预期,开始推进灰度测试。
灰度排障
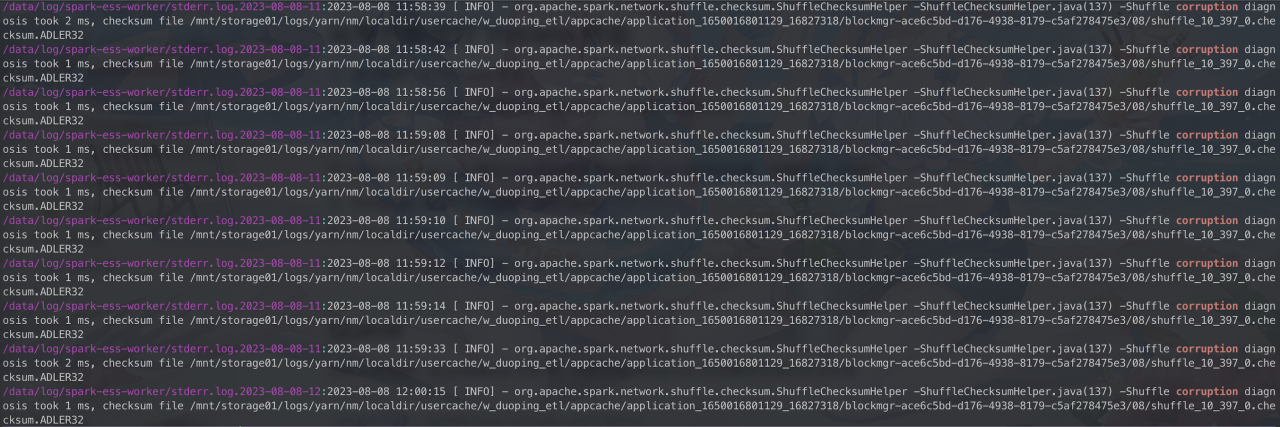
混部内核功能灰度测试发现,spark ess组件频繁触发shuffle corruption导致上层业务受影响,错误日志如下图。
问题分析
大数据团队以内核版本、hadoop组件是否使能混部特性、触发data corruption次数几个维度拉取了线上集群的情况,如下图所示,
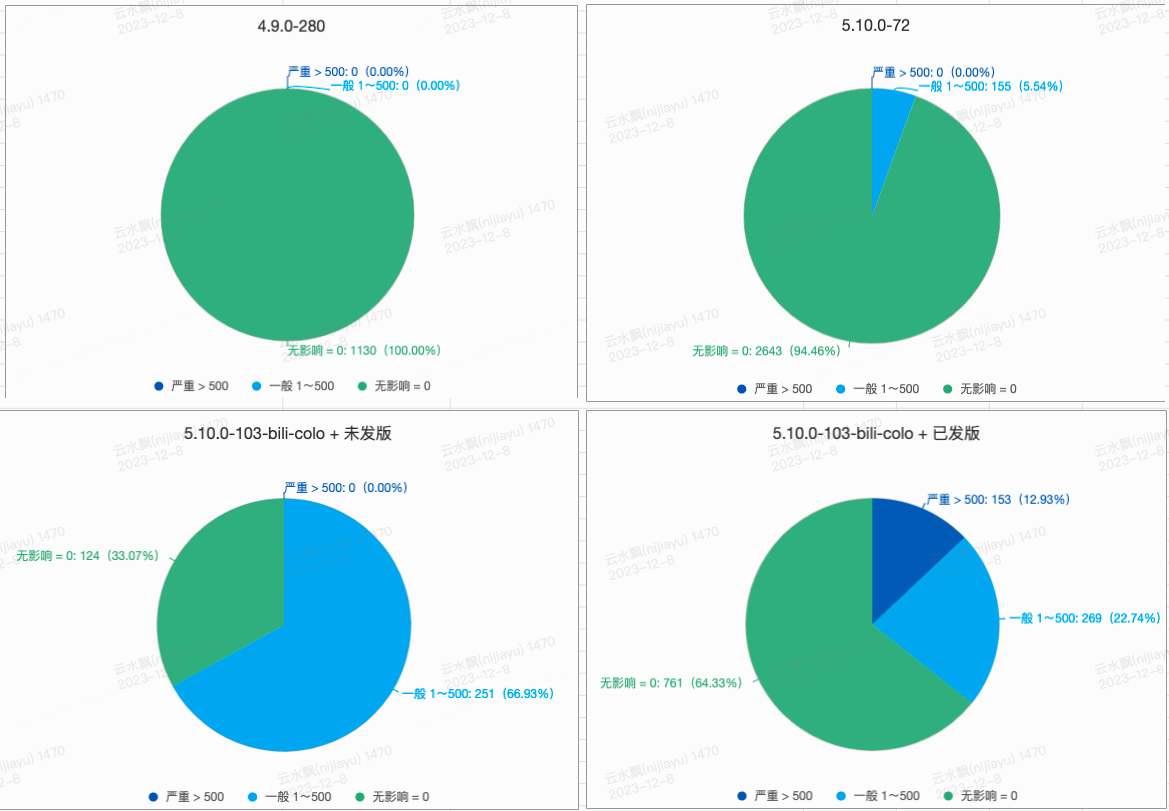
上图三个内核版本中,5.10.0-103-bili-colo内核为混部特性内核,基于该组线上数据的观察,可以得到以下结论:
搭载混部内核的机器在线上出现data corruption频率较高,且使能混部特性后严重程度激增。
在非混部内核(5.10.0-72)机器上也存在data corruption现象,但是数量不多。
综上,初步判断data corruption问题与新引入的混部特性无关,但因使能了混部特性增大了整机负载从而放大了data corruption问题出现的概率。
spark根据下列逻辑来诊断shuffle是否发生data corruption,根据大数据团队的反馈,错误日志原因为本地文件两次checksum不一致(下面逻辑中 c2 != c3的情况),属于disk issue,故从IO作为切入点进行下一步排查。
shuffle数据错误诊断逻辑:
The shuffler reader would calculate the checksum (c1) for the corrupted shuffle block and send it to theserver where the block is stored. At the server, it would read back the checksum (c2) that is stored inthe checksum file and recalculate the checksum (c3) for the corresponding shuffle block. Then, if c2 != c3,we suspect the corruption is caused by the disk issue. Otherwise, if c1 != c3, we suspect the corruption iscaused by the network issue. Otherwise, the checksum verifies pass. In any case of the error, the cause remains unknown.
问题定位
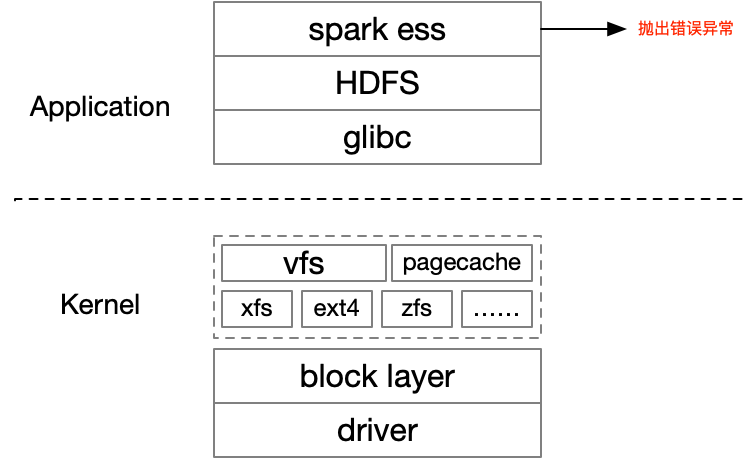
由于IO链路较长如下图,首先在大数据团队协助下,完成了应用层排查,但并未发现可疑点。开始排查内核IO栈。
通过日志分析以及监控信息确认,在出现corruption问题时必然有内存回收行为存在。同时,将xfs文件系统替换成ext4之后该问题消失。基于这些信息进一步推测,是否当前内核的xfs文件系统的脏页管理相关逻辑有bug?之后,尝试替换了一个最新的6.4 LTS版本内核,替换内核后的xfs未出现存corruption问题,看来该问题在新版本内核中已被修复。最终通过bisect方式,定位到了xfs关键的修复补丁集。
git repo: linux-stable,commit id: d7b64041164ca177170191d2ad775da074ab2926。在commit log中,xfs的核心开发者Dave Chinner也给出了问题产生的原因,同时在社区讨论邮件中Dave也表示这个问题早就已经存在,
Dave's mail:
we do indeed have a pre-existing problem with partial writes, iomap, unwritten extents, writeback and memory reclaim.
简单来说,问题的触发有必要三个条件,写IO、页缓存脏页回写、内存回收。当这三者频繁触发时,Dave指出xfs buffer IO可能会存在以下情况。
一个应用App1写一个新文件某个偏移,内核申请内存页文件位置映射到内存页面的后半段。内核把内存页面前面的部分清零,填入数据后将该页面挂入pagecache并将页面标记为dirty。
触发后台脏页回写,将页面刷回磁盘,回写提交完IO。
另一个应用App2将要开始对该文件偏移处写数据,将对App1清零部分填入数据(红框区域)。与此同时,后台回写正在做IO。
App2朝内存页面中填数据过程中,磁盘回写完成,并将该页面标记为clean。
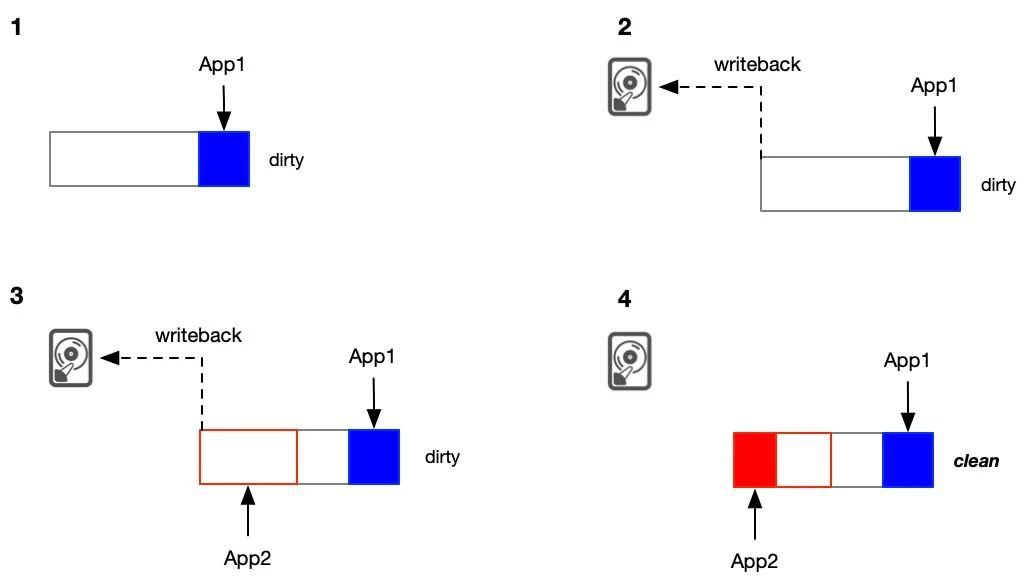
当该页面被标记为clean状态,那么这个页面在内存紧张时会被内核回收并将该页面从pagecache中移除。
更进一步,App2会接着写入该文件,但pagecache中已不存在该页面,内核会重新分配一个新的内存页供App2继续写入,由于App2的IO上下文中维护了旧的文件磁盘映射关系(内核中称之为iomap),内核会将蓝色区域清空,继续写入红色数据,最终可能结果如下图。

这个补丁在buffer IO上下文中加入了iomap有效性检查的API,并在之后的补丁里基于XFS实现了该接口,避免了因为iomap失效导致蓝色区域被清的情况出现。
问题修复
为了方便业务在线修复该问题,开始将构建内核修复热补丁。
该问题的原始补丁原理是在buffer write上下文中嵌入iomap有效性的检查,具体实现为在iomap创建时给其赋予一个XFS文件系统维护的一个序号每一次对iomap区域修改都会改变该序号,如果检查到iomap序号与xfs维护的不匹配就可以知道iomap已经失效。原始补丁中有如下代码改动。
@@ -89,6 +98,7 @@ struct iomap { void *inline_data; void *private; /* filesystem private */ const struct iomap_page_ops *page_ops;+ u64 validity_cookie; /* used with .iomap_valid() */ };
新增的validity_cookie用于存储iomap的序号。在热修复中对结构体新增成员通常是一个敏感操作,很容易出现由于结构体大小发生改变指针引用时修改其他结构体的内存数据,虽然内核本身提供了klp_shadow_* API用于动态新增成员变量,但其实现中用到了一把全局自旋锁,高并发情况下性能影响极大,显然不是一个好的解决方案。
static void *__klp_shadow_get_or_alloc(void *obj, unsigned long id, size_t size, gfp_t gfp_flags, klp_shadow_ctor_t ctor, void *ctor_data, bool warn_on_exist){ ...... spin_lock_irqsave(&klp_shadow_lock, flags); // 获取全局锁 ...... spin_unlock_irqrestore(&klp_shadow_lock, flags); ......}
为了解决该问题,我们基于现有代码封装了一个新的iomap结构体,并在buffer write上下文中用其替换原先的iomap。同时定义一个iomap_bili结构专用的魔数赋值给magic成员,每次引用时检查一下magic是否符合预期来确保改动的结构体在iomap_bili内存范围内。基于这种方式完成了修复热补丁的构建。
struct iomap_bili { struct iomap iomap; u64 validity_cookie; u64 magic; // 用于校验的魔数}
落地效果
解决了上述问题后,从线上随机抽取了部分机器,开始评估方案的落地效果。
由于大数据任务具有一定的周期性,根据大数据团队历史监控信息抽取了使能内核混部特性前后的流量高峰时段做对比观察。考虑到不同任务的资源使用量大小差别较大,任务下发数量不适合作为衡量指标,所以选择时间段内所有任务的资源总量均值做对比。由于当前场景中的资源瓶颈是内存,我们最终选择内存使用增量作为衡量资源利用率收益的指标。
通过以上评估手段收集到的数据显示在保证高优先级任务不受影响情况下,资源利用率可提升9%。
目前状态 & 展望
目前,混部内核已开启线上灰度测试,当前规模已达千台,随着规模、压力上升预计也会遇到更多的线上问题,还需持续打磨OS稳定性。
随着超配比上限的提升,大数据平台侧发现任务驱逐率上升也较为明显,对此问题平台调度侧也需要做一定的算法或参数调整,才能在驱逐率满足要求情况下进一步使资源利用率提升幅度接近上限涨幅。
同时,OS团队在近期对大数据场景的数据分析中引入了内存热度的统计信息,信息显示目前大数据场景下约有5%的内存资源属于匿名冷内存(长期未发生数据访问的匿名内存),结合一些内存压缩技术将这部分内存压缩后存放或许能够进一步提升集群的资源使用率。

