一、引入缓存后给业务带来的问题
业务系统引入缓存之后,架构由原来的两层架构变成了三层架构:
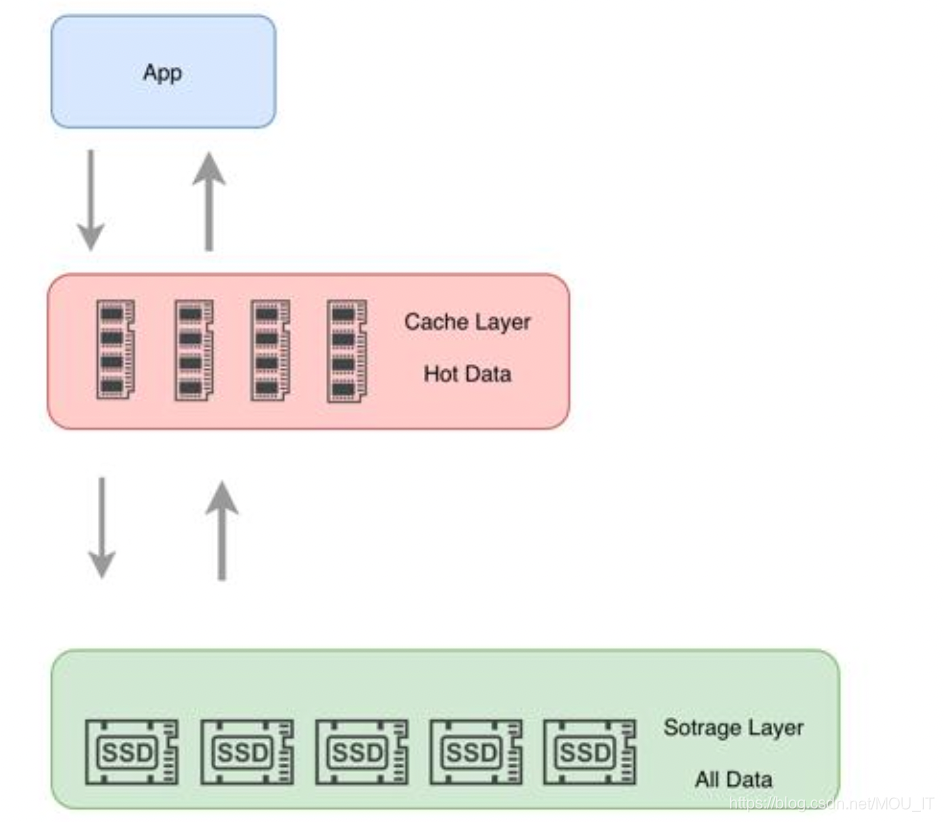
由此,带来了三个问题需要解决,分别是缓存读取、缓存更新和缓存淘汰。
1.缓存读取
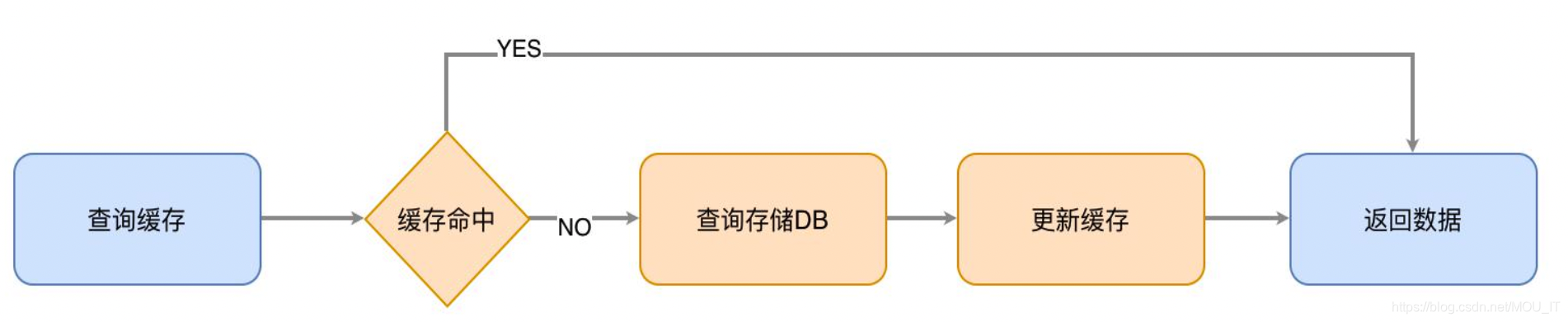
缓存读取比较简单,查询数据时首先查询缓存,如果缓存命中,则从缓存中读取数据。如果缓存不命中,则查询数据库,并且更新缓存。
2.缓存更新
缓存更新时,在更新存储和更新缓存的先后关系上,有以下几种策略:
1)先更新数据库再更新缓存
首先,这种方案会有线程安全的问题:
例如,同时有线程A和线程B对数据进行更新操作,可能会出现下面的执行顺序。
①线程A更新了数据库
②线程B更新了数据库
③线程B更新了缓存
④线程A更新了缓存
此时就会出现数据库中的数据与缓存的数据不一致的情况,这是因为线程A先更新了数据库,可能因为网络等异常情况,线程B更新完数据库进而更新了缓存,当线程B更新完缓存后,线程A才更新缓存,这就导致了数据库数据与缓存数据的不一致。
其次,这种方案也有其不适用的业务场景:
首先一个业务场景就是数据库写多读少的场景,这种场景下采用先更新数据库再更新缓存的策略,就会导致缓存并未被读取就会被频繁的更新,极大的浪费了服务器的性能。
再一个业务场景就是数据库中的数据不是直接写入缓存的,而是需要大量的复杂运算,将运算结果写入缓存。如果这种场景下使用先更新数据库再更新缓存的策略,也会造成服务器资源的浪费。
2)先删除缓存,再更新数据库
先删除缓存再更新数据库的方案也存在着线程安全的问题,例如,线程A更新缓存,同时,线程B读取缓存的数据。可能会出现下面的执行顺序:
①线程A删除缓存
②线程B查询缓存,发现缓存中没有想要的数据
③线程B查询数据库中的旧数据
④线程B将查询到的旧数据写入缓存
⑤线程A将新数据写入数据库
此时,就出现了数据库中的数据和缓存中的数据不一致的情况。如果删除缓存失败,也会出现数据库数据和缓存数据不一致的现象。
3)先更新数据库,再删除缓存
首先,这种方式也有极小的概率发生数据库数据和缓存数据不一致的情况,例如,线程A做查询操作,线程B执行更新操作,其执行的顺序如下所示:
①缓存刚好失效
②请求A查询数据库,获取到数据库中的旧值
③请求B将新值写入数据库
④请求B删除缓存
⑤请求A将查到的旧值写入缓存
如果上述顺序一旦发生,就会造成数据库中的数据和缓存中的数据不一致的情况发生。但是,先更新数据库再删除缓存的策略发生数据库和缓存数据不一致的概率很低,原因就是:③的写数据库操作比步骤②的读数据库操作耗时更短,才有可能使得步骤④先于步骤⑤执行。
但是,往往数据库的读操作的速度远快于写操作,因此步骤③耗时比步骤②更短这一场景很难出现。因此,先更新数据库,再删除缓存是一种值得推荐的做法。
4)异常情况
上面的讨论与对比都是在删除缓存和更新数据库这两步操作都成功的情况下叙述的。当然系统正常运行时的操作基本上都是成功的,那么如果两步操作有其中一步操作失败了呢?以先更新数据库再删除缓存举例:
更新数据库失败:这种情况很简单,不会影响第二步操作,也不会影响数据一致性,直接抛异常出去就好了;
更新缓存失败:这种情况需要继续尝试删除缓存,直到缓存删除成功,可以用一个消息队列完成,如下图所示:
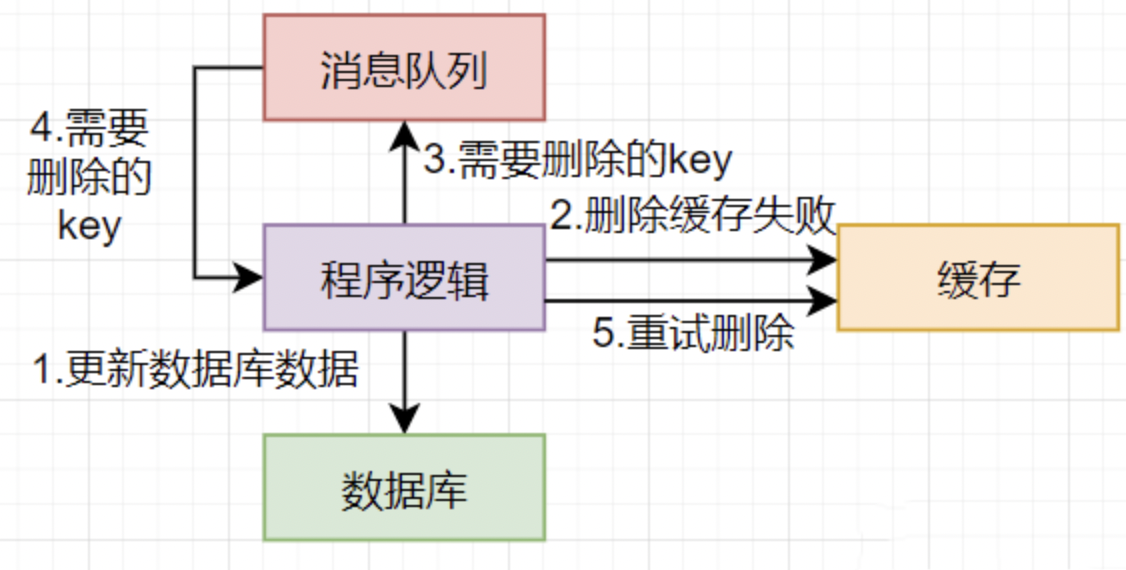
①更新数据库数据;
②删除缓存数据失败;
③将需要删除的key发送至消息队列;
④自己消费消息,获得需要删除的key;
⑤继续重试删除操作,直到成功。
3.缓存淘汰
主要有两种策略,分别是主动淘汰和被动淘汰:
主动淘汰:给键值对设置TTL时间,到期自动淘汰(推荐),这种方式可以达到缓存热数据的目的;
被动淘汰:内存达到最大限制时,通过LRU、LFU算法淘汰(不推荐),这种方式影响缓存性能,缓存质量不可控。
二、缓存的三座大山
1.一致性
一致性主要解决以下几个问题:
1)并行更新如何解决隔离性问题
串行更新:单个Key更新序列需要串行更新,保证时序
并行更新:不同的key可以放到不同的Slot中,在Slot维度可以进行并行更新,提升性能
2)原子性更新时如何解决部分更新的问题
系统联动:缓存&存储实时同步更新状态,通过revision同步状态
部分成功:缓存更新成功,存储更新失败,触发HA,保障写入成功(日志幂等)
3)如何解决读一致的问题
revision:每个Key都带有一个revision,通过revision识别数据新旧
淘汰控制:Redis不淘汰存储未更新的数据(Redis不淘汰revision < 4的数据),保证Redis不缓存旧版本数据
2.缓存击穿
缓存击穿指的是访问数据时直接绕过缓存,访问数据库。可能会有两种原因造成这种现象:
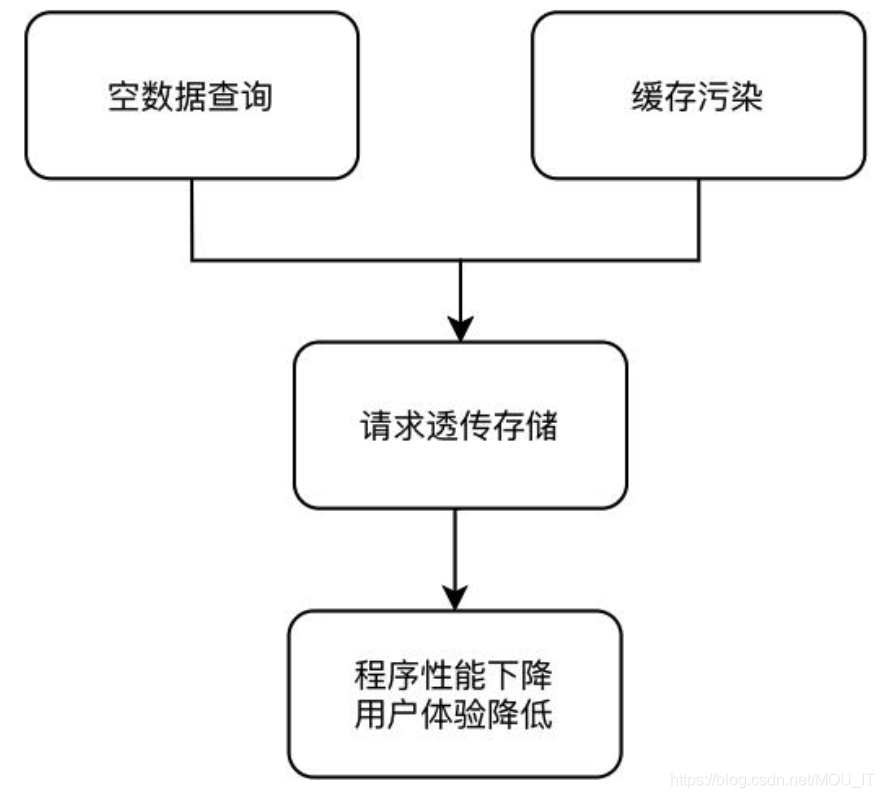
一种是大量的空查询,比如黑客攻击;另外一种是缓存污染,比如大量的网络爬虫造成的。
1)为了解决空查询带来的缓存击穿,主要有两种方案:
第一种是在缓存层前面再加一层布隆过滤器,布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。布隆过滤器是一个 bit 向量或者说 bit 数组,长这样:

如果我们要映射一个值到布隆过滤器中,我们需要使用多个不同的哈希函数生成多个哈希值,并对每个生成的哈希值指向的 bit 位置 1,例如针对值 “baidu” 和三个不同的哈希函数分别生成了哈希值 1、4、7,则上图转变为:

我们现在再存一个值 “tencent”,如果哈希函数返回 3、4、8 的话,图继续变为:
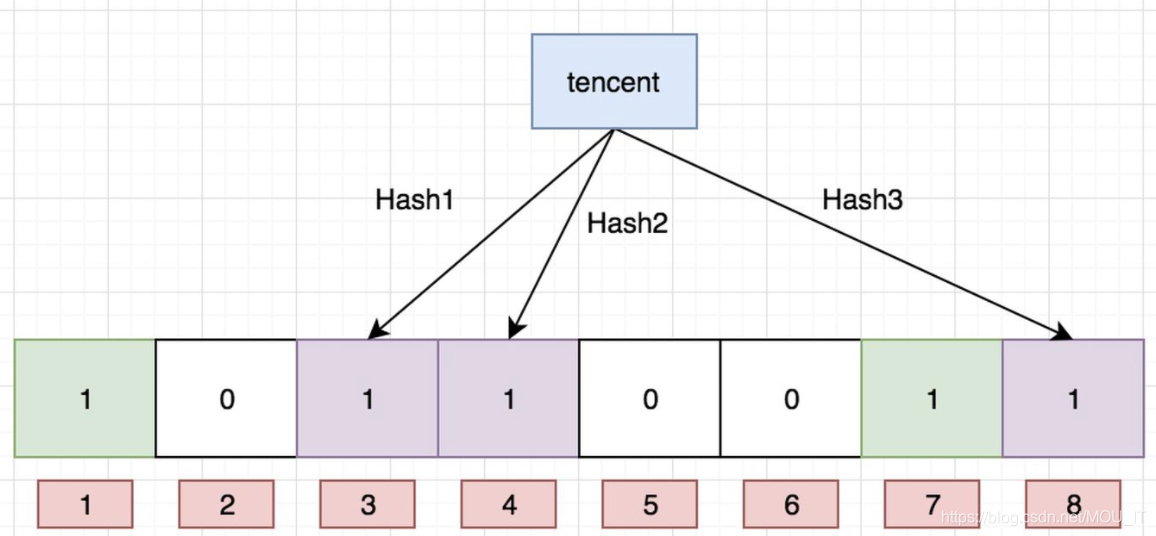
值得注意的是,4 这个 bit 位由于两个值的哈希函数都返回了这个 bit 位,因此它被覆盖了。现在我们如果想查询 “dianping” 这个值是否存在,哈希函数返回了 1、5、8三个值,结果我们发现 5 这个 bit 位上的值为 0,说明没有任何一个值映射到这个 bit 位上,因此我们可以很确定地说 “dianping” 这个值不存在。
而当我们需要查询 “baidu” 这个值是否存在的话,那么哈希函数必然会返回 1、4、7,然后我们检查发现这三个 bit 位上的值均为 1,那么我们可以说 “baidu” 存在了么?答案是不可以,只能是 “baidu” 这个值可能存在。
这是为什么呢?答案很简单,因为随着增加的值越来越多,被置为 1 的 bit 位也会越来越多,这样某个值 “taobao” 即使没有被存储过,但是万一哈希函数返回的三个 bit 位都被其他值置位了 1 ,那么程序还是会判断 “taobao” 这个值存在。
很显然,过小的布隆过滤器很快所有的 bit 位均为 1,那么查询任何值都会返回“可能存在”,起不到过滤的目的了。布隆过滤器的长度会直接影响误报率,布隆过滤器越长其误报率越小。另外,哈希函数的个数也需要权衡,个数越多则布隆过滤器 bit 位置位 1 的速度越快,且布隆过滤器的效率越低;但是如果太少的话,那我们的误报率会变高。
第二种是把所有的key和热数据value加入缓存,在缓存层拦截空数据查询。
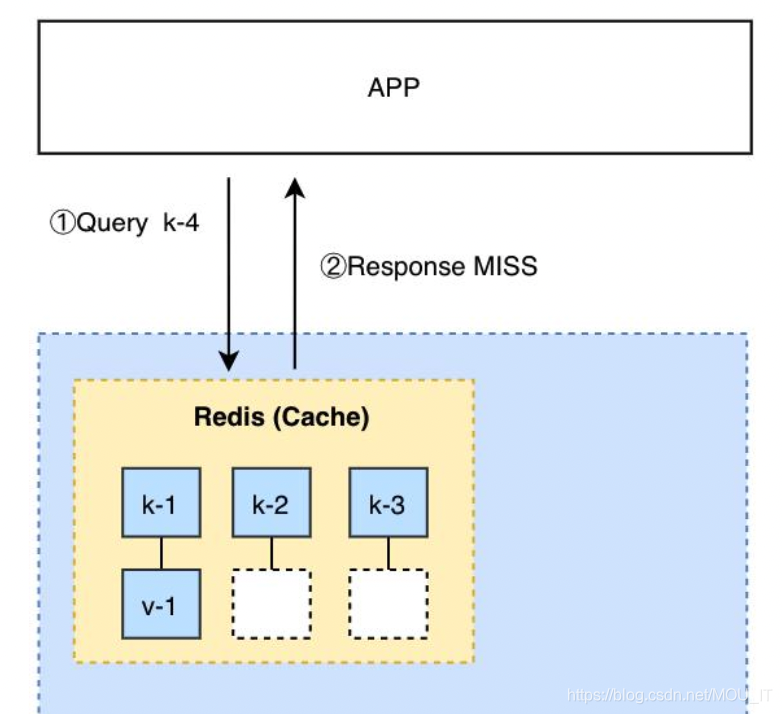
2)为了解决爬虫带来的缓存击穿问题,可以设置缓存策略:
针对更新的操作,需要立即缓存
针对读的操作,可以在设置是否立即缓冲还是延迟缓存,以及在规定的时间窗内命中的次数是否达到一定的次数才进行缓存
3.缓存雪崩
缓存雪崩指的是热数据集中淘汰,大量请求瞬间透传到存储层,导致存储层过载。

造成缓存雪崩的原因主要是TTL机制过于简单造成的,解决方案主要有以下:
设置TTL时给过期时间加上一个随机的时间值
每一次的访问都会重新更新TTL,此外业务可以更精准地指定热数据缓存时间

