腾讯云数据库伍鑫:MPP数据库HTAP技术探索
本文根据伍鑫在【第十三届中国数据库技术大会(DTCC2022)】线上演讲内容整理而成。
讲师介绍:

伍鑫,腾讯云数据库专家工程师,在数据库内核、数据复制、大数据计算等领域有丰富经验,曾发表多篇相关论文、专利。加入腾讯前曾在IBM DB2团队工作多年,后加入Hashdata云数仓公司。加入腾讯后,负责TDSQL PG系数据库研发工作。
本文摘要:
腾讯云TDSQL分布式关系型数据库是一款面向海量在线实时数据的MPP数据库系统。在面对实际业务HTAP混合负载时,不管是高并发的交易还是海量的实时数据分析,TDSQL都有足够能力处理。
本次分享为大家介绍TDSQL提升HTAP混合负载处理能力时在存储、计算、资源隔离等方面的探索优化历程。
演讲正文:
一、HTAP概述
早在上个世纪九十年代,大家就在讨论存储模型到底是用行存还是列存,因为针对交易系统每列数据是紧耦合,按行组织数据效果在OLTP场景更好。但OLAP性能分析在DSM列存格式上效果更好,因此从业务角度的特点来说就会分成两个方向:
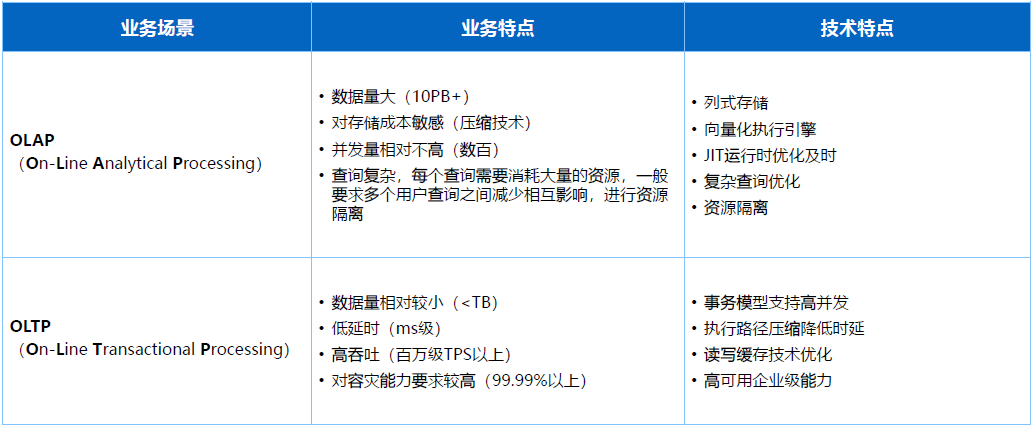
早期OLTP领域数据量相对较小,一般小于TB级别,要求低延迟,用户交易请求需要在毫秒级甚至更快的情况下完成,达到一个高吞吐,交易请求可能会有非常高的并发请求数量,同时对数据高可用和容灾能力要求非常高。
OLAP场景更多的是面向海量数据分析,最近几十年数据整个规模的膨胀发展,数据量基本上会超过PB级别甚至达到EB级别,对存储成本要求会比较高,因为海量的数据情况下,有些存储场景成本会超过总体的50%甚至70%,随之带来针对数据压缩技术要求会比较高。
OLAP场景大部分情况并发相对不高,但近几年来并发要求也开始上升,所以在弹性计算和相关Serverless无状态的构架下也有一些演进,整体来说相对OLAP场景并发度不高。
OLAP场景下复杂场景会比较多,存储过程要求也比较高,复杂场景情况下资源就会消耗比较多,CPU网络和内存等层面,所以需要对用户和资源做一些隔离,也是在不同业务特点下对产品形态的要求。
那么在这样的特点下就催生了不同产品的技术特点和技术路线:
OLTP场景更多要求是在事务模型支持高并发,执行路径达到降低时延,读写缓存技术优化以及企业级高可用要求比较高,包括容灾场景针对性要求非常高。
OLAP场景跟随业务特点会更深入地Focus在列式存储、向量化执行引擎、JIT运行时优化、复杂查询优化、资源隔离等场景会有比较多的要求。
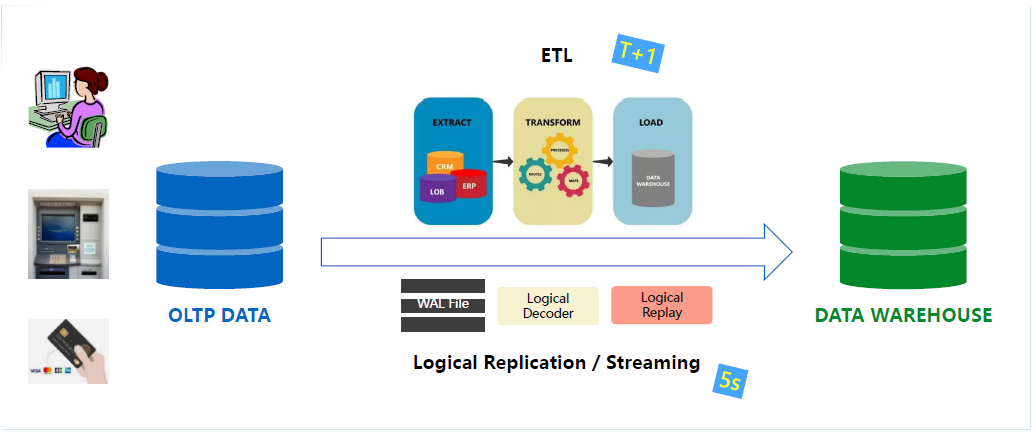
其实在比较早期的OLTP、OLAP产品形态比较独立的情况下,大部分用户其实也是有这样的一个混合方案的需求。
产品独立的情况下,早期需要向ETL工具去做一个定期的Extract Transform或者Load的操作,流程上就会比较烦琐,用户也需要在ETL工具进行选择和消费,可能会买相应的产品。那么在这样的构架下,时效性相对比较低,一般需要在T1+的层面才能达到分析型的数仓,拿到准实时的数据。
过去的十年更多推进的是基于Logical Decoder和Logical Replay去做基于流式复制更高时效的复制层面设计,通过CDC从远端TP场景抓取增量日志、逻辑日志,传输到端的数仓,再做一个日志回放,这样的话时效可以达到5秒内,目前国内的主流混合场景其实都可以通过流复制达到准实时或者基本近实时的效果。
这些是过去很长一段时间以来的融合方案,其实就会对产品、成本、构架有比较高的要求,如何降低成本,如何在产品选型做到更简单,同一个数据库同时实现OLTP和OLAP,业务开发和相关的成本也会下降得比较明显。
在这样新时代的需求下,我们前面也在强调产品是随着用户需求的形态转变的,新时代的用户需求可能会有这样的一些场景:
1.日间交易和夜间批量业务复用。银行业或者金融行业日间有很高的OLTP场景需求,夜里交易量闲时可以利用这样一个很大的OLTP资源场景去做分析,包括每晚业务的汇总或者银行的月度结息都可以把OLTP资源进行复用,这是一个典型的OLTP和OLAP混合的场景。
2.实时分析型要求。刚才也有讲到虽然最近用到逻辑复制和流复制的场景达到5秒内的数据延迟,但其实还不是一个完全实时的业务分析,面向现在更多要求实时性更严格,甚至是完全实时的分析场景就需要有一个挑战,一体式的HTAP产品是否能够完全实时的数据分析要求也是一个挑战。
3.全量数据精度分析。因为大部分场景分析OLTP会有全量用户的数据,OLAP场景可能会去复制或者加工后面的一些数据集,提供用户数据价值的提炼,但实际上在现在这样一个时代,我们需要对实时有一个要求,也是需要对全量实时数据进行分析。
OLTP和OLAP业务混合负载。在同一套系统下,能够降低整个用户的选型成本以及资源利用率的提升,都是有这样的一个效果。在新时代下,这四个场景是对产品整个形态的演进有一定的挑战。
在这样的需求下,我们怎样构建我们的产品,其实我们也是持续通过多年的探索和演进去做规整,今天主要做这样一个分享。
Gartner对HTAP的整个趋势判断也是比较早地提出这样的概念,现在的IT构架师需要在HTAP层面思考更多,是否是通过HTAP构架下为公司和业务部署提供低成本和更实时高效分析的状态,我们在这种趋势判断下进行多年的探索。
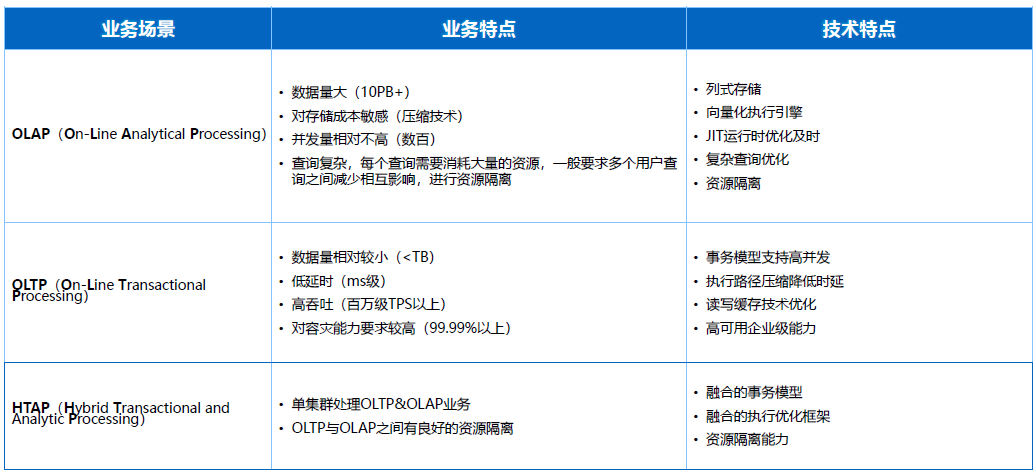
刚才讲到OLTP和OLAP分别的特征,混合场景下我们更关注融合场景下的事务模型,是否可以同时支持TP和AP的事务请求,混合场景下的执行和优化是否在同一套构架下可以完成TP和AP计算或者查询优化的分析,混合场景下是否可以为用户在OLTP和OLAP资源进行隔离,保证互相不受干扰。OLTP场景的实时性要求更高,需要保证更好的网络和缓存的机制,保证基本的TP场景的低时延和高吞吐,AP场景其实也要分配足够的CPU和内存自来带来高效的内存计算。
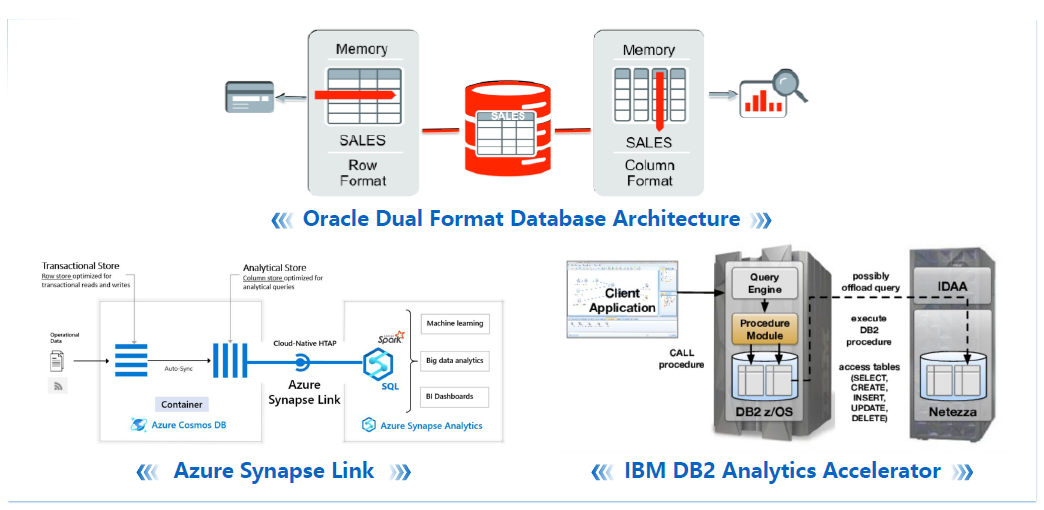
很多场景和产品在过去也有进行很多HTAP尝试,Oracle是大家了解比较多的,大家经常对Oracle做混合场景,OLTP和OLAP性能都是相对比较好。
这里有些混合方案,比如行存和列存的构建格式,通过实时双模存储格式达到HTAP的整体要求,Azure Synapse和IBM DB2 Analytics Accelerator也是融合不同的TP和AP产品,无论是外部还是内部达到实时的数据复制,为用户提供一个基本透明的HTAP体验,这些都是传统厂商做的探索。
我们也会提出更进一步的挑战,是否真的可以在同一套系统里面完全融合实现存储、计算以及优化,包括用户接口的融合。
二、TDSQL-PG探索
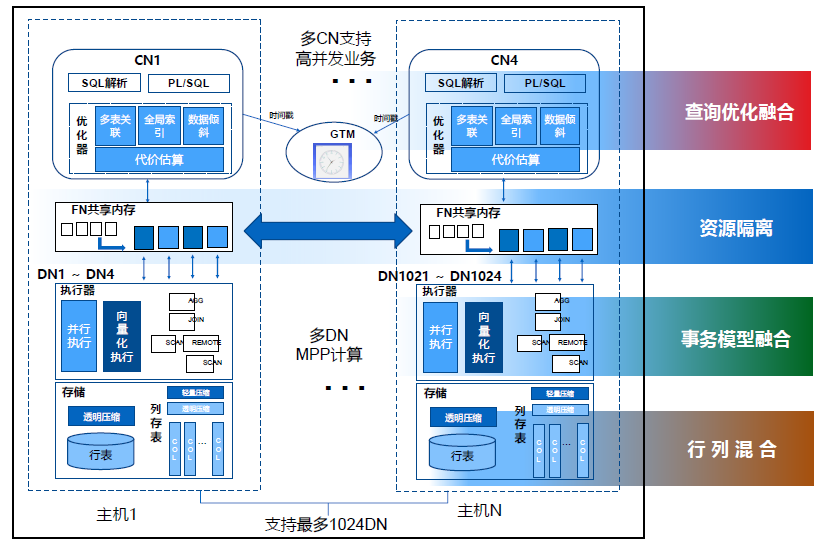
TDSQL做了很多探索,MPP引擎其实是TDSQL整体构架图,这里有几个模块:入口模块是Coordinator Node,我们支持多CN协调节点,可以为用户提供高并发的业务请求,同时支持TP和AP场景下的高并发需求。
DN就是存储和计算节点,这里是MPP Sharing构架,最多可以支持超千台DN节点,达到MPP并行计算效果。中间层面是做了一个数据转发的优化,解决MPP在高并发、海量并发复杂查询场景下的连接问题。
刚才讲的多CN需要在事务层面有一个协调节点,我们叫做Global Transaction Manager,通过这样的一个构架,可以在几个层面帮助客户实现数据融合和HTAP构架下的最低成本和最高效的部署模式。
后面会具体讲如何在同一个事务层面达到完全实时一致的数据存储请求和服务,行列混合是如何做到同一套事务模型如何做到行存和列存,资源隔离如何做到TP和AP资源隔离和查询优化,如何同时做到,就是刚才讲的HTAP架构。
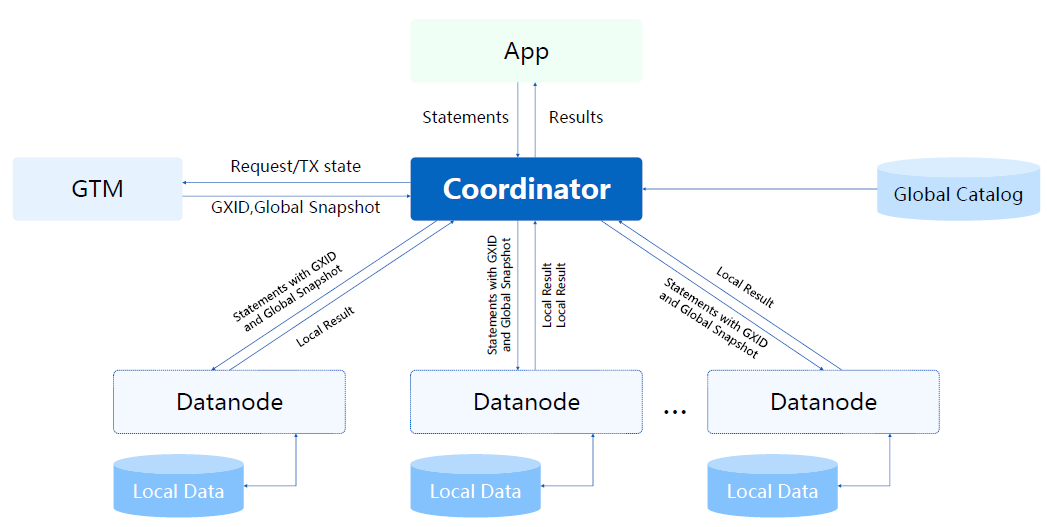
刚才讲到我们是多CN节点,其实是需要GTM全局事务管理模块剥离出来,因为需要对CN和DN提供统一的事务请求。最开始我们是通过全局事务快照机制在GTM维护活跃事务链表,相当于统一处理CN节点请求的快照,但在这种情况下包括GTM节点的单点瓶颈和快照网络传输消耗是比较大的。
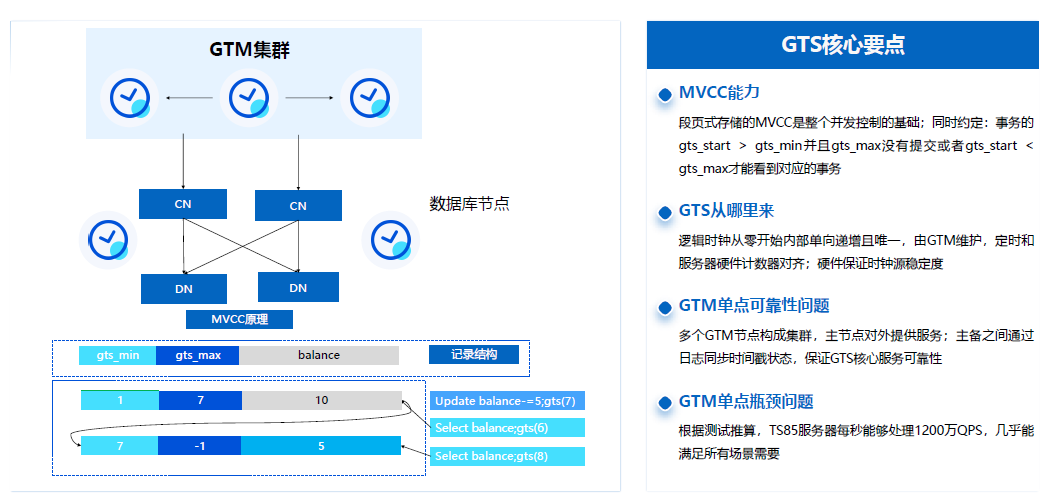
我们2016年就开始做一些探索,结合Spanner和Percolator相关思想做了一些创新和专利发表,然后基于中止提交协议把GTM节点的单点瓶颈解除,相当于把单点事务协调的状态推到CN或者DN节点去做分布式的协调。
这里主要是通过基于一个单调递增的逻辑时间戳,以及基于时间戳的可能性判断的逻辑调整,GTS也是在GTM节点能做了很多并行生成优化,保证单台TS85服务器达到1200万QPS的请求服务标准,然后在这样的GTM底座下支持集群多节点的行列混合的事务模型基础。
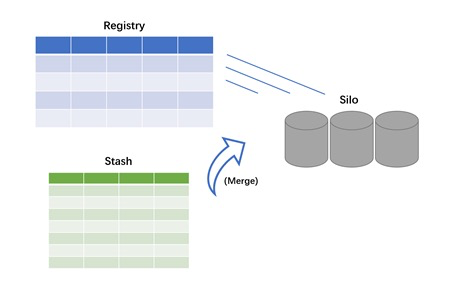
讲完事务模型,我们再简单介绍一下行列混合存储情况下的事务模型是如何体现的。可能大家对PG行存表相对熟悉一些,简单介绍一下列存表。为了达到事务层面和行存表一致,其实列存表分为元数据和用户数据存储模块。

元数据是复用行存表的一些机制,相当于每个列都是按照紧凑排列,每个列存块相当于一个Silo,就是数据筒仓的概念,元数据会有一个行表明数据状态。DML的操作都会根据元数据表去做一个相应的体现,我们还有一张辅助表把TP场景下短事务的DML操作缓存在一张行存表,通过元数据的行存表和Stash行存表为列存表做元数据管理和偏TP场景的优化。
行列存在很多系统里面其实是相对割裂的存在,用户需要在建表的时候了解数据模型,然后针对用户数据模型去建行存表和列存表,选择偏OLTP场景还是偏OLAP场景。我们这里需要去做一个透明的优化,就是尽量让用户体验更好,不用去选择我是要用行存表还是列存表。
我们的做法是列存表格式下,用户可以选择一个开关建对应的行列混合的表,行存表部分其实就是内嵌一张辅助的行存表,存储相关的一些OLTP场景的数据,我们会自动地为用户进行区分,比如用户业务场景进来,就是小数据量的插入更新,可能会有一个阈值进行设置,会走入行存表Stash表里面,如果是批量导入和批量更新,这些数据会直接组织成列存格式,然后以最优的面向查询请求的方式去做数据编排。
如何做到行存表和列存表同步,而且数据完全一致,我们其实是会有一个背景进程,自动为用户把行存表里的数据Stash Merge列存格式,这个动作是透明的,自动为用户做的。需要强调的一点是,我们的数据是只有一份,不会产生冗余的数据存储带来的成本开销,所以我们会通过这样的一个设计,更加面向企业级用户。因为是完全实时的、没有数据冗余存储的设计,透明的方案就是这样设计,带来这样一个构架的好处就是面向未来可能更高要求的实时要求和存储成本要求,我们做到最优。
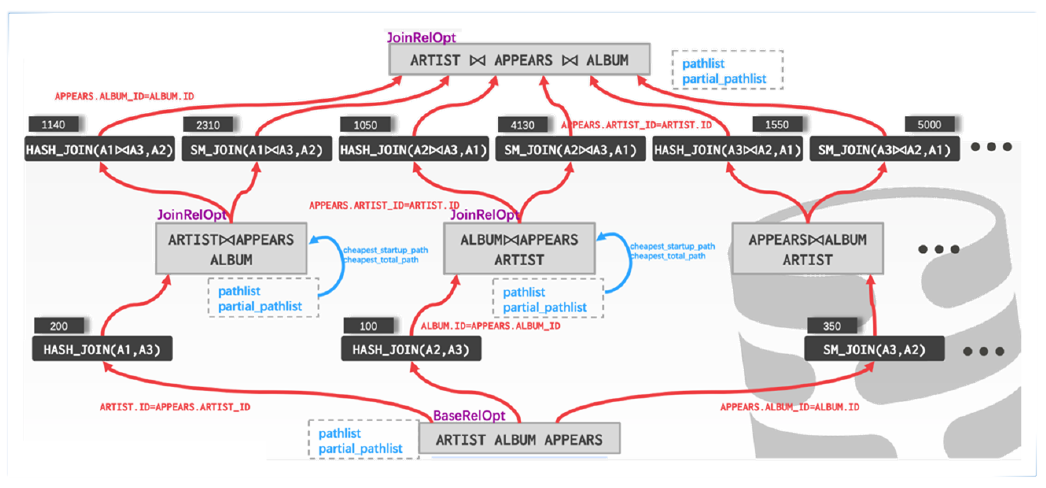
刚才讲的是存储和事务层面,产品优化也是做了统一的基于CBO和RBO的优化器,典型的动态规划算法。多表关联,每个Level开始规划单表的执行路径,可能的Table Scan还是Index Scan,尝试所有可能的多表关联、两表关联,生成相对应的路径,然后判断这一层的Cost,形成状态转一函数,完善多层的动态规划,寻找最优执行计划的方法。
这个相对比较简单,要是有并行场景的话就会有更复杂的执行路径,不同Level去做执行路径对比的时候其实还需要对并行场景甚至去做一些延迟物化场景做更复杂的转移判断,所以整个算法是相对比较复杂的,我们也是沉淀了比较久,分布式场景、并行场景都有进行很多细致优化。这里对行存表和列存表都有不同的Cost估算,索引层面列存在多值反复查询,没有缓存的情况下其实效果会比较差,所以我们也是针对Bitmap Index Scan去做很多性能优化,包括Cost Model的调整保证我们在同一套优化器里面可以支持行存表查询和列存表查询,或者混合行列存的查询。
后续我们已经做到向量化的处理层面,也是在同一套优化其判断哪些算子可以走向量化,哪些算子是走偏行级别的,这些都是有场景的,不是所有场景都是向量化更好,这些都是我们很多复杂场景下同一套优化其做的优化。

之前讲的是通用的查询优化,这里对OLTP场景也有一些针对性的优化。图中就是分布式场景下的两种层面:PLAN Shipping就是Query在CN节点进行统一场景分片规划,针对子的场景计划推到对应的计算节点进行执行计划,这样的好处就是对复杂SQL会有一个统一的CN节点去做评估、搜集和判断,多分片情况下,不同分片计划同时可以启动多个进程进行并行计算,不需要有些等待。
这里有一个问题就是PLAN在复杂场景下本身的数据量传输相对比较大,描述场景计划需要占用的网络带宽比较大,整个过程中也做了一些针对性的优化,就是有些SQL可以直接下推到单个DN,可以避免这样的场景,提高事物高吞吐的场景的要求。要是把Query提前判断,SQL能够直接下到DN节点,中间的网络传输也是会有比较大的减轻。
如果是一个简单的单点查询就是Select ID From Table,传输的数据量远比下推一个场景计划小很多。通过这种方式,可以大大减轻高并发情况下的网络带宽的压力,很好地在同一套系统又支持复杂场景的PLAN Shipping也支持OLTP场景的SQL Shipping,这些是两个层面维度去做优化和执行层面的融合。
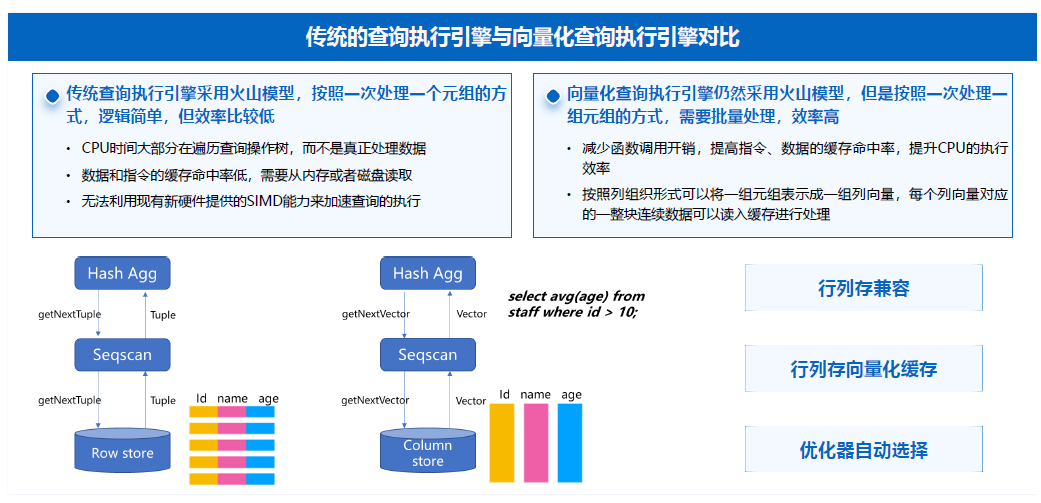
向量化计算就是OLAP场景下如何进行深入优化,这个Topic比较大,我们不深入展开,简单来讲就是在OLAP场景下,已经对执行引擎进行深入改造,Scan、网络传输和全链路的复杂程度更高的语句都可以完全走向量化引擎,优化器层面也是自动去做规划,甚至一个Query里面有一部分查询走向更优,数据量减少的情况下要求更快的数据,后面的算子不走向量化,这些都会有自动的判断。
向量化引擎也会对行存表和列存表去做向量化执行:行存表会有一个算子做数据类型的转换,转换成内存格式计算,列存表本身是原生,就是向量化扫描的,内存执行效率会因为有向量化执行去做进一步的性能优化。
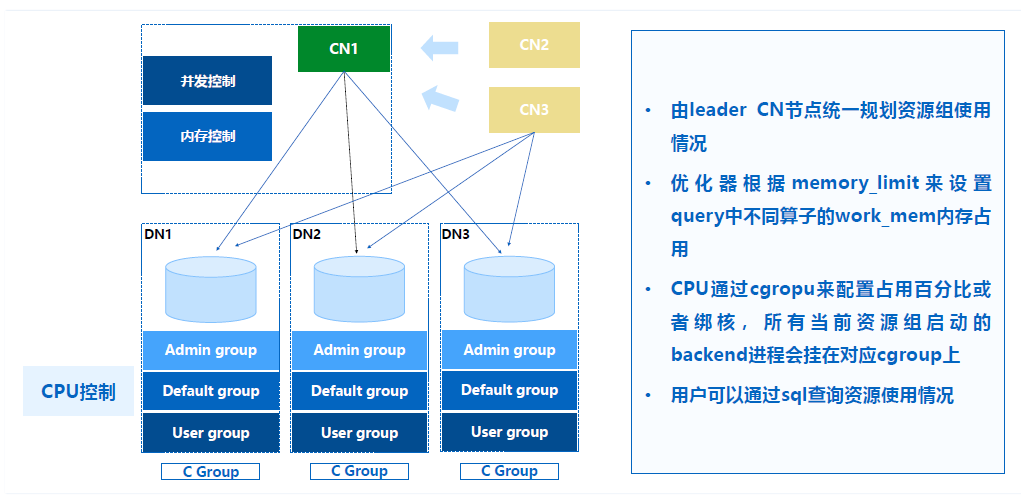
刚才讲的就是在存储和计算层面,其实在资源整合层面我们也做了产品化的能力。我们通过资源组来做资源隔离,就是用户可以配置系统集群上的资源是如何分成不同的池子,相当于可以把用户的业务请求放到不同的资源组里面去做隔离,我们是做到CPU、内存、并发度和队列等待的能力。
这里是通过CPU进行强隔离,内存是通过增强查询优化器动态规划,Query在每个算子到底需要多少内存,PLAN限定好对应算子的内存使用量,去做一个灵活的规划,保证不会超过资源组的资源限制,如果超过的话用户可以配置不同User里面的优先级去做任务调度的等待和任务插入的操作。通过这种层面,我们可以对TP、AP甚至AP场景下不同的用户组或者任务组去做隔离。
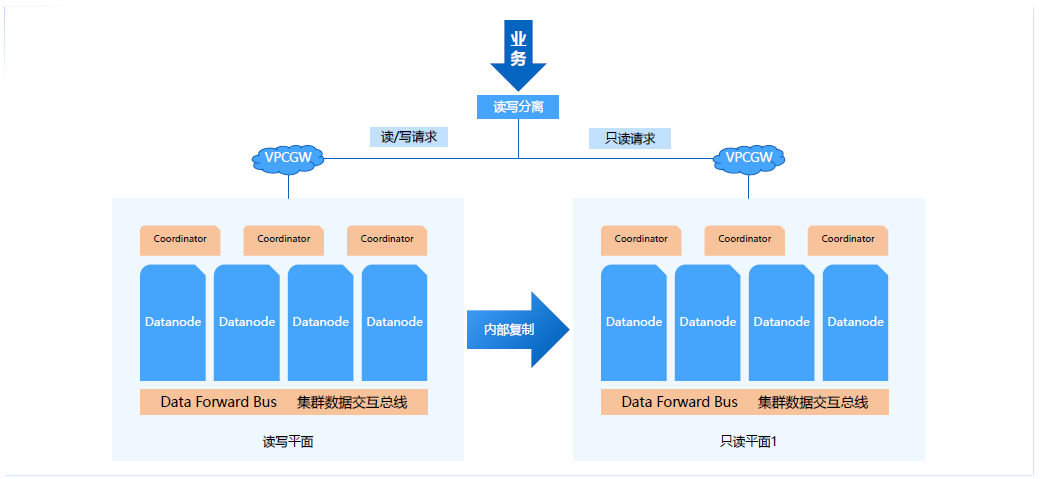
刚才讲的是同一套实例中的逻辑隔离的方式,其实这里我们也可以通过主备平面达到物理隔离,就是可以在主集群的备节点形成备平面,通过备平面支持只读请求。
这里备平面和主平面是内部的物理复制,通过物理复制效率就会比较高,用户可以配置完全实时还是只是传输日志,或者只要主平面提交就可以,这些都可以做到灵活配置,用户也可以配置一个强实时同步。
通过这样的读写请求,达到资源平面隔离的方式,通过更多的资源或者更多的物理资源去做物理隔离,逻辑和物理层面可以做到多租户、多业务的隔离。
三、后续探索
刚才讲的这些都是TDSQL本身已经实现的HTAP相关的能力,我们后面还会持续为大家在同一套系统同时达到TP和AP存储、计算以及优化层面完全一致的融合,不是两套系统做流式复制的融合方案。
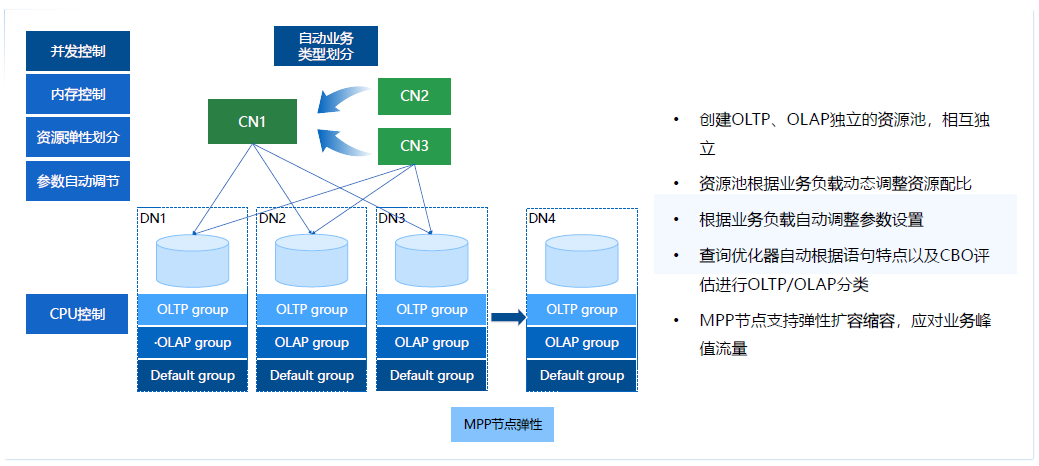
我们认为需要持续优化的是几个方向:并发控制、内存控制、资源弹性划分以及参数自动调解。白天营业的状态下TP场景可能更多,夜里AP场景可能更多,如何去做一个动态的调整,参数可以根据业务模型去做自动规划,自动和智能的业务划分其实都是我们未来持续探索的一个方向,持续为大家提供一个完全透明、单系统的HTAP方案。

