滴普科技冯森:FastData DLink实时湖仓引擎架构设计与落地实践
本文根据冯森在【第十三届中国数据库技术大会(DTCC2022)】线上演讲内容整理而成。
讲师介绍

冯森,滴普科技FastData产品线DLink产品研发负责人,目前负责FastData DLink实时湖仓引擎产品研发工作。曾就职于网易MySQL数据库内核研发团队,有近10年数据库内核研发经验。
本文摘要:湖仓一体是目前比较火热的方向,主要解决成本问题和减少ETL,同时可以提升数据端到端可见性。本次演讲主要介绍DLink实时湖仓引擎的架构设计和核心功能实现介绍以及DLink在客户侧的落地实践案例和未来规划。
演讲正文:
DLink架构介绍
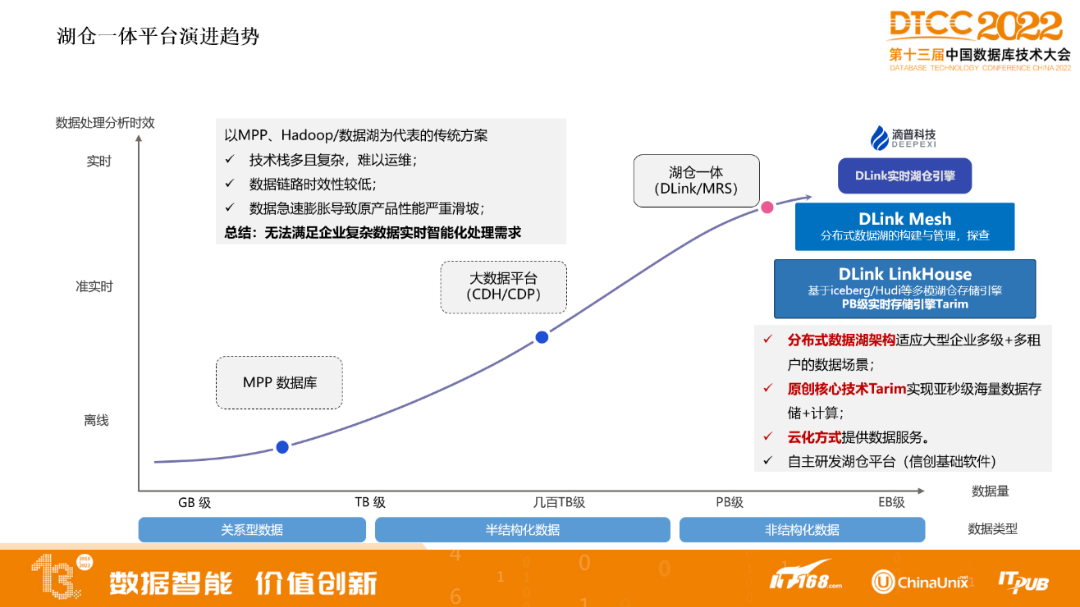
湖仓一体平台演进趋势
以MPP、Hadoop/数据湖为代表的传统方案,存在技术栈多且复杂,难以运维;数据链路时效性低;数据急速膨胀导致原产品性能严重滑坡等难题,无法满足企业复杂数据实时智能化处理需求。
随着数据量增加以及对时效性要求更高,来到新的架构湖仓一体,湖仓一体能带来什么样的效果?可以从原来T+1增加到T+0,因为湖仓一体基本可以达到分钟级别的时效性。
DLink还有企业级特性,像多级+多租户的数据场景,内置了自研的引擎,可以实现亚秒级海量数据的存储和计算,可以提供云上服务方式。
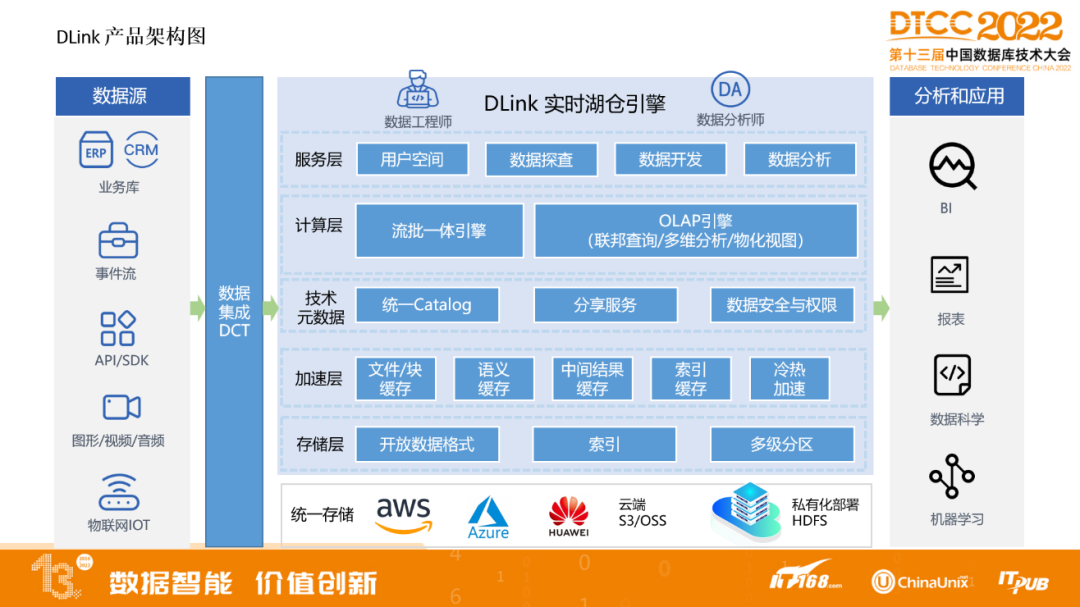
▲DLink产品架构图
对接不同数据源,如业务库、Kafka、API、SDK,还有非结构化数据图形、视频、音频,包括IoT物联网数据,都可以通过我们公司自研产品DCT数据集成工具来把这些抽取到实时湖仓引擎。
DLink支持私有化部署,存储层支持开放数据表格式,加速层支持数据在内存和本地SSD缓存,不只有文件缓存,还有中间结果,包括索引、冷热数据、语义的缓存,技术元数据开发统一Catalog,可以对湖内数据提供统一视图,对接上层不同引擎,基于技术元数据可以对湖内数据做数据分享,包括控制一些数据的安全和访问权限。再上一层是计算层,基于Flink做的流批一体的引擎,不但借助于Flink在流处理强大的性能,也同时开发了基于Flink做批处理的SDK,可以被调度引擎做批调度。OLAP引擎支持联邦查询,同时因为支持多湖多租户,可以支持多个数据湖之间的联邦查询,包括多维分析、物化视图功能。再上一层是服务层,支持不同用户空间,主要可以对不同用户、租户做资源隔离,同时支持在产品上进行数据探查、数据开发、数据分析等。这套实时湖仓引擎可以对接不同应用,包括BI、报表、数据科学、机器学习等。

▲DLink实时湖仓架构图
我们支持这些数据源导入到湖内,支持从端到端,也就是从原端数据源一直到数据可以查到,支持分钟级延迟。数据入湖之后可以通过Flink做CDC的功能,在湖内构建实时数仓,之后可以通过分析引擎做实时数仓查询分析。
DLink产品关键特性
云原生架构:云中立,对接不同云平台,支持弹性扩缩容。
支持流批一体:计算上通过Flink做流和批的计算。
多模数据存储和管理:结构化、半结构化和非结构化数据存储和管理。
存算分离:计算和存储资源可以单独进行扩缩容。
安全和隐私:可以对数据文件进行加密,像Parquet/ORC等文件进行加密处理。查询,查询时进行掩码。
统一元数据管理:通过它来对接湖内不同引擎,也可以对接湖外不同的引擎,比如可以对接湖外的Hive、Spark等引擎,也可以对接湖外元数据,不同版本可以通过注册形式连到我们元数据上。
支持统一数据接口:包括基于分析引擎做分析,在项目空间级别进行数据开发,包括机器学习等。
支持租户管理:支持不同租户进行管理,包括空间概览,目前在湖内有哪些数据,有哪些任务,有哪些异常监控状态,都可以看到。
数据探查:支持SQL编辑器,可以直接在开发界面上进行查询、分析。
湖仓管理:因为数据入湖之后可能会产生一些小文件,我们提供统一后台服务来自动对这些小文件进行合并。
实时计算:提供了DLink SQL作业和任务管理能力,包括任务运维监控功能。
数据分析:我们做了一些优化,像物化视图、计算下推,提供更多统计信息,来提升它的查询性能。
机器学习:因为底层支持非结构化数据存储,对外可以对接不同的AI平台来提供机器学习的能力。同时支持Python对湖内数据的访问,也支持机器学习的场景。
作业管理:支持多种不同类型作业管理。
DLink核心功能
DLink是基于最核心的三大开源组件做的,比开源社区做了一些优势功能,也提供给了开源社区。
优于开源Iceberg
BloomFilter索引:在等值查询和范围查询场景下性能大幅提升。
Z-Odrer数据排序:在多维数据分析场景下性能大幅提升。
Hive存量数据快速迁移:支持生成Iceberg元数据的方式对Hive历史数据快速迁移,避免数据搬迁。
Iceberg CDC功能:Iceberg通过流读变更数据构建实时数仓的重要能力。
小文件自动合并:通过内置合并策略,可以自动进行后台小文件合并,快照清理等。
隐藏分区/计算列:支持Flink在Iceberg上创建带有计算列/隐藏分区的表。
支持Iceberg维表:支持通过Iceberg存储维表功能。
优于开源Trino
Catalog热加载:支持动态加载Catalog能力。
支持Local cache:对IO密集型query进行性能优化。
支持多租户:基于ranger支持多租户能力。
支持物化视图:支持物化视图动态刷新。
数据加密:支持通过masking的方式对数据进行加密。
数据权限:支持库、表和字段级数据权限。
支持CBO优化:支持基于Iceberg统计信息进行优化执行计划。
优于开源Flink
UI界面:DLink在UI界面集成了作业提交、管理运维、数据视图Metrics等能力。
Flink引擎支持多版本:支持Flink1.12-1.14版本。如果客户正在使用1.15~1.16的话,我们也可以快速进行支持。
流批一体:Flink支持SDK的方式提供被批调度能力。
整库入湖:支持整库数据入湖,提升入湖效率。
算子调优:支持Flink算子自动调优、算子拆分、算子并发。
数据连接:支持丰富的connector。
支持yarn/K8S:Flink支持on yarn和on K8S资源调度。
DLink在开源社区的贡献
Iceberg社区:PR总数:31个;Contributor总人数:9位;
Hudi社区:PR总数:13个;Contributor总人数:3位;
Trino社区:PR总数:4个;Contributor总人数:2位。
DLink核心功能包括带来新的效果
Z-Order是一种特殊的将多维数据映射到一维的方法,对于一个二维的查询条件来说,无论对A还是对B进行范围查询,都能至少过滤掉50%的数据量。在多维分析场景性能会有大幅提升。
DLink BloomFilter索引
是基于文件block级别的索引进行过滤,在10亿规模点查产品下进行测试,如果开启BloomFilterF的话,大概有8倍左右性能的提升。
DLink支持Iceberg CDC流读Insert/Update/Delete
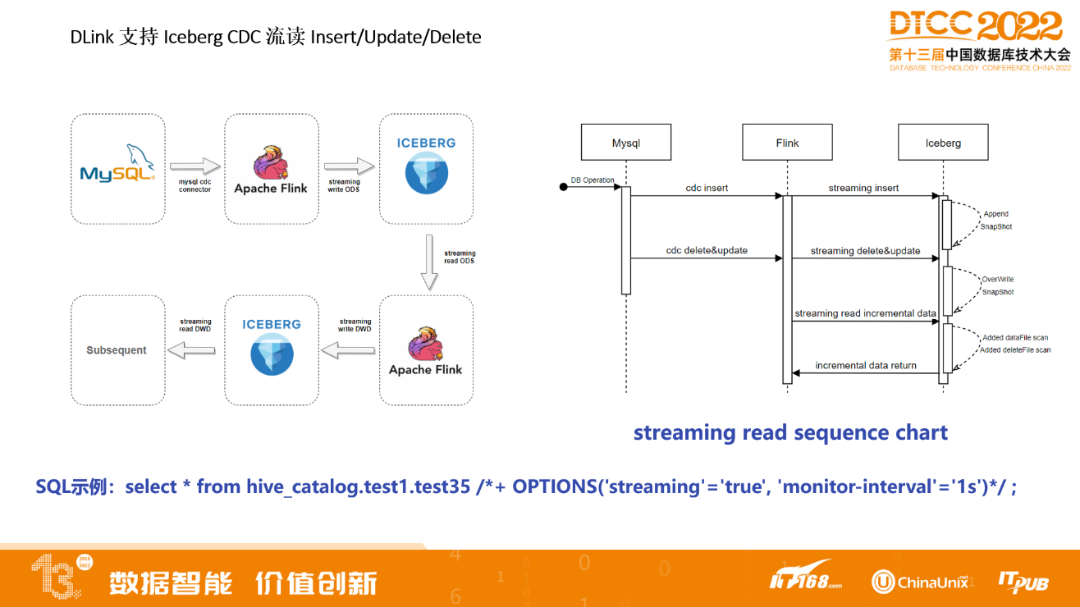
这是一个Flink任务,流读间隔可以设置1秒或几分钟都可以。如果ODS层上数据变更的话,通过流读在每层数仓进行实时变化,每层1秒,通过4秒,在ADS层就可以查到,性能比较快。如果没有这样的方式,每层数仓还要重新跑一遍批。
DLink自动化合并Iceberg小文件
做了独立的后台服务,可以自动对文件进行合并。Iceberg社区本身也提供了对应的合并接口,通过写程序方式对应接口进行合并小文件。把这块做得更加智能,让Iceberg包括DLink可以达到开箱即用目的,就像数据库一样,不需要手动或定时触发合并,客户无感知,根据他的规则,如快照数量、小文件数量,来进行自动触发文件合并。同时也做了资源隔离和多种任务调度策略。客户对每张表想马上触发,在界面上可以配置,触发之后,这个策略就会跑到队列前面,下一个任务马上可以执行。
DLink Hive历史数据快速入Iceberg
核心价值:Hive数据可以在不迁移数据文件的情况下,直接构建Iceberg元数据,转换为Iceberg表,并在此基础上做了性能优化,降低了迁移成本。
测试结果:经过多次对比测试,说明数据轻量级迁移任务的执行还是很快速、稳定的。
DLink整库数据入湖
支持Oracle、MySQL、TiDB等。同时支持整库多张表和部分表,也支持历史数据和增量数据一体化入湖,这个任务建好之后,可以对存量和增量数据一起入湖。
支持在入湖过程中如果原库数据DDL发生变更,增加列或新增表,都可以自动识别、自动同步。
支持并行化入湖。
支持时间戳回溯。
DLink统一元数据服务

可以兼容不同HMS多实例,内置把不同的HMS版本做了大量兼容工作。可以通过统一元数据来控制上面引擎DDL权限操作,比如哪些用户不能建表/删表等。支持基于统一元数据做租户和不同Catalog级别的隔离,支持兼容不同引擎,对湖内引擎,像Flink、Trino等,都可以对接,Hive/Spark 的话,都可以对接到统一元数据上,通过外部引擎也可以访问到湖内数据。好处是客户基于CDH/CDP做业务处理的话,基于Hive、Spark业务,这些就不需要改了,直接可以非常顺滑迁到DLink上。
DLink数据权限控制
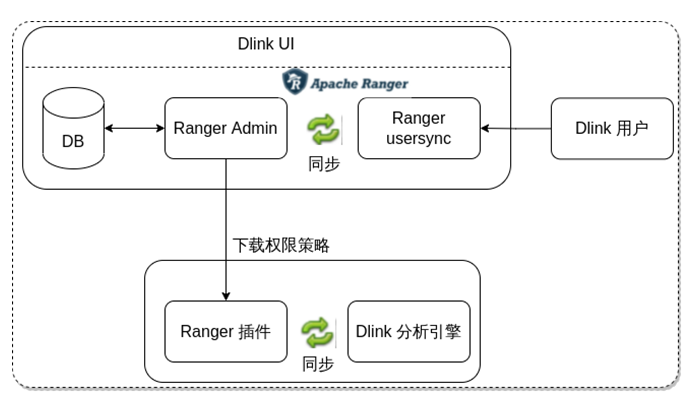
目前做到分析引擎查询时,可以设置权限,比如库表列,设置好策略之后,存到Ranger,通过策略下载,直接可以控制对应元数据的查询能力,能控制到查询哪些数据。也可以跟目前大数据体系做权限打通,如果客户原来也是基于Ranger来做的话,可以通过DLink进行统一管理。
DLink Trino支持批处理和容错机制
容错执行是Trino中的一种机制,它使集群能够通过在发生故障时重试查询或其组件任务来减轻查询故障。支持Query和Task级别重试,同时基于Tardigrade 实现了强大的批处理能力。
DLink支持物化视图
物化视图的全量刷新很慢,其次当我们对物化视图关联的表进行dml操作的时候,数据会进行变化,但是物化视图无感知,导致物化视图查询的结果可能不是最新数据。定时刷新的好处在于我们刷新之后,把表的数据同步到了物化视图,使查询的数据不是旧的数据。
DLink支持数据缓存

Alluxio Local data cache,轻量级仅本地节点访问的缓存,将数据缓存在计算Node的本地SSD中,不考虑集群节点间数据共享,依赖于soft affinity schedule,增加缓存命中率,尽量本地node处理本地的数据。
DLink Trino Catalog热加载
主要做法是通过产品层面提供restAPI方式,新增注册Catalog接口。每个节点都可以加载到Catalog,达到集群Catalog热加载,包括删除、更新操作。
DLink支持Flink Job算子并发拆分和调优
主要作用是方便排查瓶颈算子,比如三个算子算一个节点,其中有一个算子OP1有瓶颈的话,如果没有拆分功能,需要对整个节点资源都要调优,对OP2/3来讲不需要调整,会有资源浪费的情况。拆分之后,就可以单独对OP1调整并发,保证整个任务可以顺利进行,也节省了资源,提升作业性能。
DLink支持在湖内构建维表和缓存加速
DLink支持多租户和多湖企业级架构,主要适合的客户,如大型央国企,大型跨国公司,集团租户不同子公司。
原来方式是每个子公司和集团公司自己都有一个湖,这个湖实际上是物理隔离的,不同的机房,如果主湖跟子湖数据想同步的话,目前通过数据拷贝的方式性能和成本会有很大的问题,我们支持多湖、多租户,通过DLink构建对外部数据源通过数据注册方式注册进来,对湖内管理,同时在湖上也可以支持多个物理湖之间跨湖的联邦查询,数据不需要两个湖之间同步,可以通过Trino联邦查询,对两个湖进行统一查询管理。
同时也可以对原有业务库,像MySQL、Oracle业务库,没有入湖的话,注册完之后,也可以支持外部数据源和每个湖之间数据的联邦查询。同时在联邦时,可以通过对租户权限的控制,如集团的湖不想让子湖全部访问到它的数据,通过对角色、用户进行权限控制,支持平台级权限,支持库表列权限,只能访问对应数据,做到数据安全。
DLink落地实践
例1,某存储客户数据能力建设现状
某某存储现有大数据平台以CDH(6.3.2)技术栈为主,基于本地IDC物理架构构建。沿用业界经典的Lambda架构,以离线采集+离线数仓为主核心技术架构。
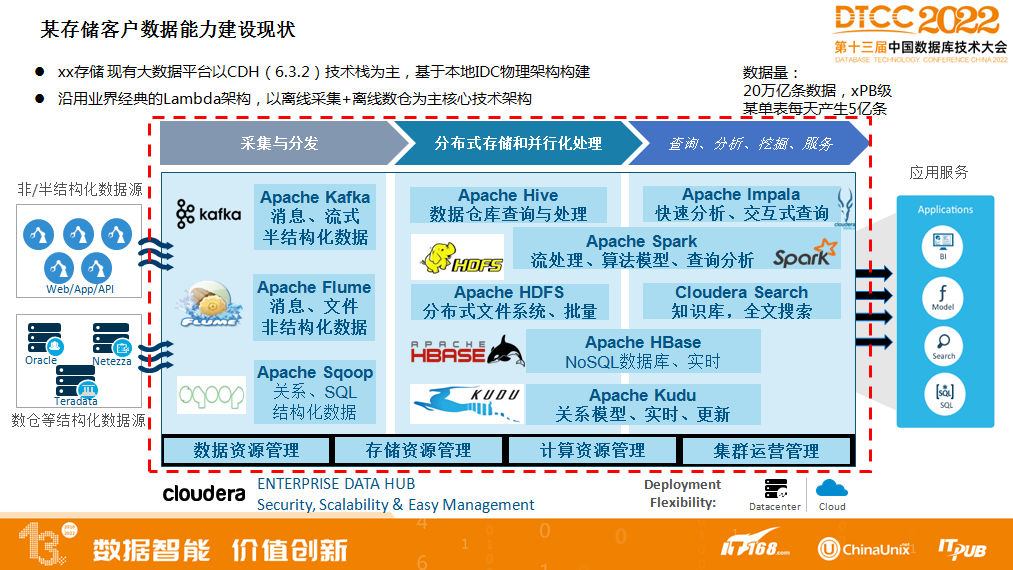
随着业务数据不断增多,还想对数据业务去从,存储和计算成本通过跑批压力也比较大,成本比较高,所以引入了我们DLink。
客户关注点:
稳定性、可用性。希望能做到大数据组件到数据本身的全链路监控。
灵活性、兼容性。各技术组件支持灵活的组合,需要与现有的CDH兼容。随着业务的发展,数据的增加,支持横向扩展。
数据准确可靠。Hive历史数据快速迁移入湖,历史数据和新增数据去重,流式任务出现异常后,需要有相应的补数方案。
解决方案:
DataOps理念。提供可靠的数据采集到上线运维的流程监控,实现数据的持续稳定交付。
湖仓一体架构。支持DLink on YARN/K8S的部署方式,兼容现有CDH,各组件之间解耦;云原生架构,支持计算和存储资源弹性扩容。
面向数据质量提升的技术架构。提供Hive历史数据生成DLink Iceberg元数据的方式快速迁移数据入湖;提供历史数据快速批式去重,新增数据流式去重;提供流式任务异常情况补数据的方案。
客户原本大数据底座是CDH6.3.2,通过Hive进行大数据量的数据去重操作,效率极低,资源占用非常高,资源库压力大。
客户最大的一张表存量数据3000亿条,日增7亿条左右。
采用DLink数据湖方案,该表历史全量数据去重时间压缩至4小时左右,入湖速度在11w条每秒,日增量数据批量merge到全量表耗时在1.0小时左右。
该方案收益:
大大降低了Oracle源库压力。
大大降低了资源消耗,只有原来的1/4。
大大提高了时效,数据从入库到Iceberg表中可查时延在2分钟以内。
例2,某能源自建云新系统架构:统一技术栈、实时湖仓、容器化
这个客户也是我们目前正在交付的客户,核心诉求是统一技术栈,也使用CDH,通过Hive构建的数仓,性能也是T+1,数据用test格式,还没有压缩,整个用起来比较浪费存储。数据源有Oracle、MySQL、SQL server、postgreSQL、mongoDB等。底层存储可以对接他们JFS,JFS可以屏蔽掉底层不同的存储方式,提供统一存储接口来进行访问,这块我们也做了对接。
在数仓建模之后,到ODS层,可以达到分钟级别,如果客户对这种数据的新鲜度要求更高的话,比如到秒级以下做业务的分析,我们业提供DLink对湖内数据进行出湖,迁移出去做数据处理。
例3,某零售行业客户案例

基于CDH做的,是6.3版本。最核心的诉求是想对图片、音视频、结构化数据和非结构化数据做统一存储,更好地对业务进行赋能,可以对图片进行搜索、检索、对接AI平台能力,我们给它提供流批一体能力,可以T+1到T+0时效性提升。存算分离,云原生架构计算存储可以弹性扩缩容,让计算资源和存储资源不再成为瓶颈。Data+AI,支持非结构化数据分析,更好挖掘非结构化数据价值。
DLink未来规划
支持亚秒级实时数仓能力,这是我们的目标,如果支持之后,在DLink上可以支持多模存储引擎。
支持企业级多租户多级数据湖,也是我们未来想继续完善和深耕的特性。
支持IMT二级索引,主要也是对重复数据合并性能带来的问题做优化。
支持自适应实时物化视图,查询时可以自动改写物化视图,改进以后,客户无感知随着业务慢慢往前演进,会越来越快。
支持数据加密和查询脱敏,主要是向金融客户、大型央国企数据加密和脱敏有严格的要求,我们也在支持这方面。
支持Hudi表格式,相当于做一个横向的扩展,因为目前DLink是构建在Iceberg表格之上的,我们也正在做Hudi表格式,进度到明年Q1DLink产品就可以上线支持Hudi表格式。
支持机器学习,我们在多个客户场景下现在已经在落地和交付DLink+AI平台服务于客户机器学习的场景,接下来会重点做这块支持和能力。

