导读:58招聘业务商业化流量主要集中在推荐场景,招聘业务面向的C端求职者群体广泛,B端企业招聘职位类型丰富,由于蓝领招聘具备门槛低的特点,求职者求职意向普遍跨度较大,如何基于有限的商业候选职位做好BC双边匹配,并不断提升商业流量变现效率是商业推荐系统要解决的核心问题。本次分享将结合58招聘业务特点,介绍商业推荐系统设计与实现,以及召回、粗排和精排各环节算法的选型与实践。
今天的分享主要包括以下几大方面:
58APP端招聘商业化推荐场景概要及特点
58商业推荐系统架构总览
58召回
58排序
总结与展望
0158APP端招聘商业化推荐场景概要及特点
1. 推荐场景
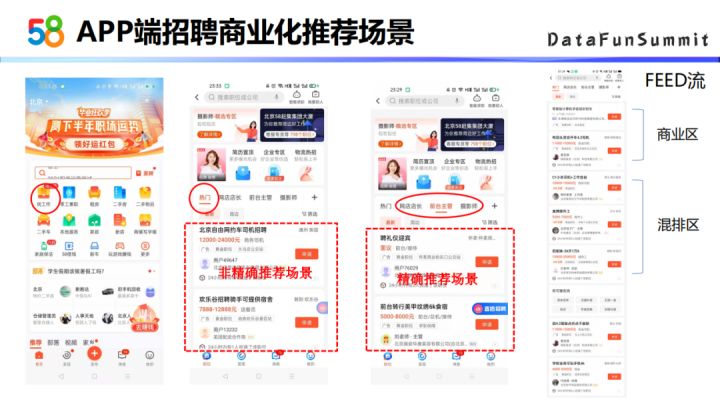
58APP首页的左上角有个找工作,这是招聘场景的主入口,在招聘场景下70%的流量属于推荐,推荐又分为非精确场景和精确场景:
非精确场景主要指热门、附近位置等,基于用户行为进行推荐;
精确场景推荐如热门旁边的这几个标签,推荐的内容需要跟标签有一定相关性。所有推荐位置的架构都是基于Feed流形式,top几页是商业区,紧接着是混排区,在混排区中有一定比例的商业位置。
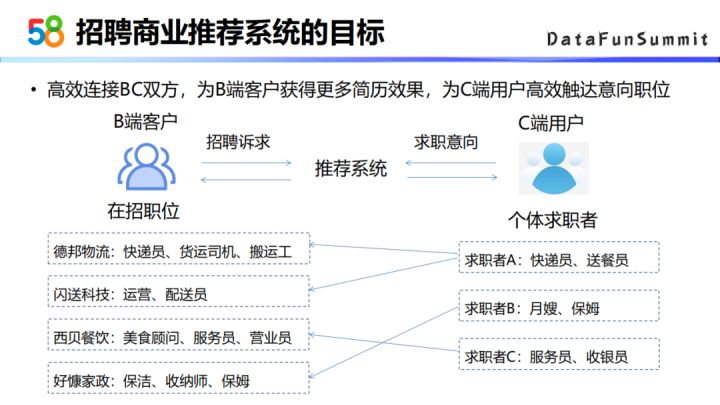
2. 推荐系统的目标
商业推荐系统的目标主要是高效的连接BC双方。为B端客户获得更多简历效果,为C端用户高效触达意向职位。高效就体现在推荐的结果上,比如如果一个求职者的求职意向是快递员送餐员,如果平台给他推荐的东西都是一些营业员服务员保洁类的帖子,这一部分流量相对于平台来说是浪费掉了。
3. 58平台上求职者特性
平台上的求职者有以下两个比较重要的特点:
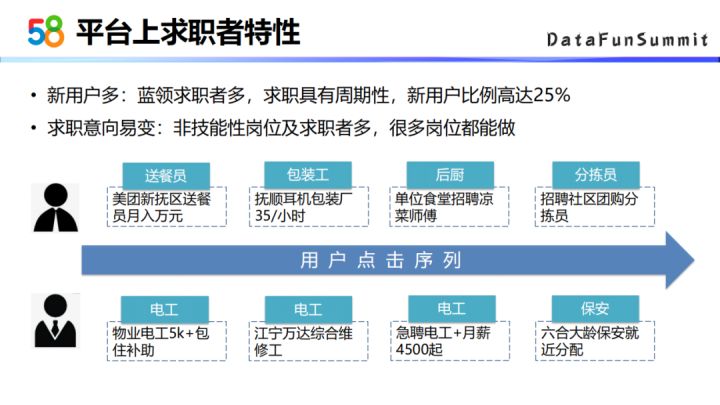
第一个特点是新用户比较多,蓝领的求职者比较多,他们的求职具有周期性,新用户的比例可以高达25%;
第二个特点是求职者的求职意向会比较容易发生转变,因为非技能性的岗位比较多,求职者会想要尝试多种非职业性岗位。
比如上图中的两个例子:
第一个用户的意向关注点在送餐员,包装工,后厨,分拣员这四个职位上。虽然这几个职位之间其实没有多大的联系,但是从深层次的考虑的话,这几个职位对技能的要求并没有那么高,求职者可以灵活的在岗位间切换,所以会同时关注这几个职位。
第二个用户他的求职意向是电工,可以看出他是有技能特长的,但是他也会关注保安这种通用技能的职位。
4. 58招聘商业场景特点
招聘商业场景有它独特的特点,其中最明显的特点就是招聘的商业候选帖较少,职位粒度较细,种类较多。普通贴的库存在6000万的量级,商业贴的量级在30万。

如果把这商业帖分散在几百个城市的上千个职位下,实际上每个类目下的商业候选量更加不足。商家为了触达更多的C端用户,会把相同的帖子投放在多个不同的类目下。商家不了解推荐系统的推荐逻辑,直觉认为投放的类目多,曝光的机会就多,这就导致了很严重的跨界发帖的问题。
0258商业推荐系统架构总览
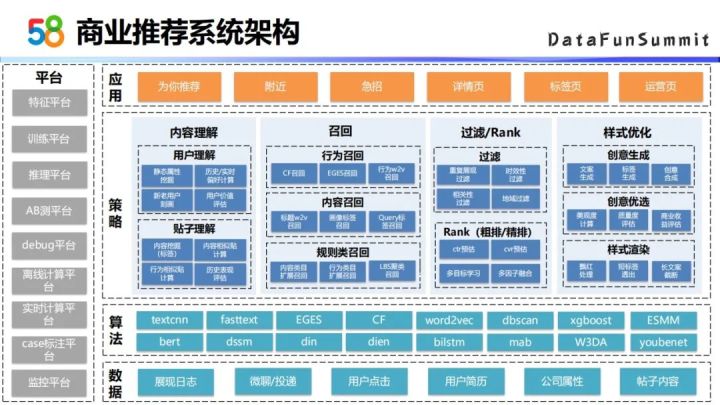
基于上述求职特性以及商业场景特点,我们通过对内容理解,建立了从多路召回到过滤排序的商业推荐系统。整个商业推荐系统的架构是基于B端和C端的用户的数据,以及前沿的机器学习算法。在策略层主要基于对内容的理解,建立了召回过滤排序的机制,并在最后展现前做了一个样式优化的策略,最后应用在不同的推荐场景上。
下面主要从召回和排序这两个模块,介绍一下我们使用的方法,以及对这些方法的改进。
0358召回
58商业招聘在召回阶段主要使用了两种召回方式,基于地域的召回方式(基于LBS聚类冷启动)和基于用户行为的召回方式。
1. 基于地域的召回方式
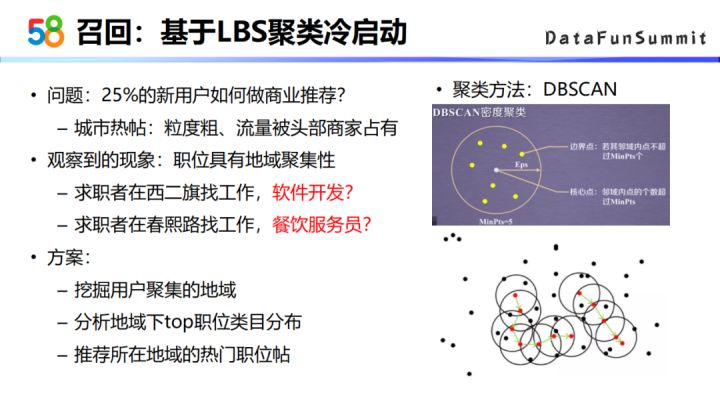
前面有提到平台上25%的新用户,对这一部分新用户,我们商业是怎么做推荐的?最开始是基于城市的热贴来推荐,但是这种推荐方式的粒度比较粗,大部分流量会给到城市下的头部客户。我们观察到职位是具有地域聚集性的,比如一个求职者在西二旗找工作,很有可能找软件开发相关的工作;如果求职者在春熙路找工作,很有可能找餐饮服务员相关的工作。
基于这种现象,如果能挖掘出用户聚集的地域,再挖掘该地域下比较热门的职位,一个新用户来到平台时,就可以用所处地域的热门贴来进行推荐了。
在对用户具体的地域做挖掘的时候,采用了DBSCAN的聚类算法。这个算法主要有两个参数,一个是域的半径,一个是域内点的个数,根据密度可达的概念完成最后的聚类。我们以城市为单位,不同城市的聚类参数是不一样的,大家可以去结合自己的业务场景来选择适合的参数,在该参数下划分出的范围比较有区分度。
以下是58商业招聘业务场景下,对地域进行聚类的可视化结果。由图可以看出用户是具有地域聚集性的,拿到有聚集性的区域之后,对这个区域下所有用户点击的帖子进行汇总统计,计算出该区域下top点击的热门职位。最后得到的结论也比较符合我们的直观认知,比如成都的春熙路,它的热招职位就是服务员店员营业员;广州地区的热招些职位是普工文员。

2. 基于行为的召回方式
另一个比较重要的召回方式是基于用户行为的召回。这里主要介绍下采用EGES模型进行召回。前面提到在58平台上,蓝领求职者比较多,他们的求职意向比较容易发生转变,然而商家候选又少,如何能够根据基于有限的商家候选来去给求职者做推荐呢?
由于蓝领求职者比较多且多数没有专业特长,所以来到平台上很大一部分用户其实自己也不确定具体要找什么样的工作。另一部分求职者会关注一些相似的工种,比如说如果他比较关注分拣员工这个职位,同时会关注仓库管理员的相关的职位。
基于这样的现象,在推荐时可以考虑给商业候选帖做相似/相关性的扩展。我们对商业帖子做embedding,这个embedding要实现的效果是,对某用户点击过的一批帖子embedding结果进行计算,得到的结果会更加的相似。所以这里基于用户行为建立了以帖子内容为结点的图结构,然后采用EGES的算法对帖子进行embedding,最后在线上通过向量检索的形式召回帖子进行推荐。
EGES算法流程:
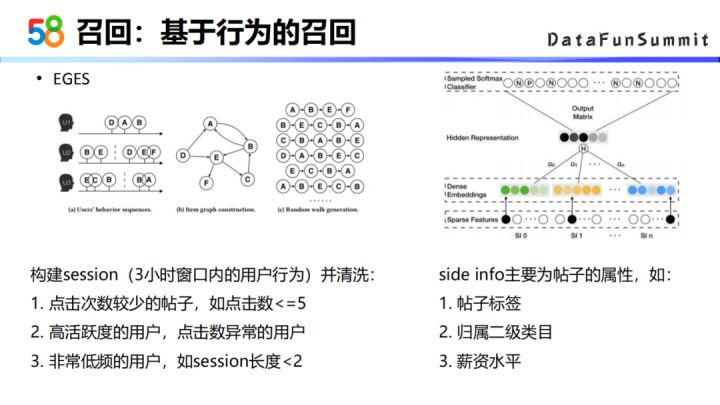
先构建一个session,这里我们选择的是三小时窗口内用户的行为,然后对这个session会做一些比较细的一些清洗,去掉一些质量较差的数据。
其次是建立图结构,建立有了session数据之后,以session内有行为的帖子做一个图的连接结构,同一个session内有点击的帖子之间设置边的关系。
然后用随机游走的方式采样一批序列,有了这些序列之后,就可以参考训练word2vector的方式来训练一个帖子的embedding。训练帖子embedding的时候,在表达帖子的结点时还可以加入side info的信息,比如说帖子的标签,归属的二级类以及薪资水平等等。
有了帖子的embedding的结果之后,在线上通过向量检索的环节拉取帖子。

上述环节会拉取到大量的异地帖子,这并不符合产品诉求,因为58招聘的场景需要给用户推荐当前城市下的帖子,这里我们对帖子的向量做了如下处理:先对帖子的向量单位化,再拼接上地域的向量得到最终向量,再去采用余弦距离的方式进行召回。
地域向量编码的方式采用了硬编码,用一个16位的二进制来表示一个城市,这样全国的几百个城市肯定是能够完全表达得过来。然后把二进制里面的所有的0都替换成-1,就得到了地域的最终向量表示。这么做的一个理由是最终的向量地域相乘的结果肯定是在整数部分,进行单位化的向量相似度在小数部分,同地域的向量计算结果肯定会比异地帖子向量计算的结果大。同地域的结果之间又是根据向量相关性进行倒排,即相关性越大,乘积值越大,排名越靠前。
3. 其他召回方式
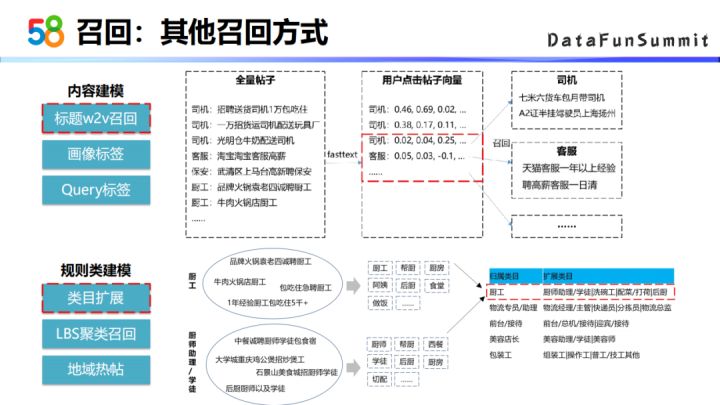
① 基于内容的召回方式
除了前面提到的一些召回方式,我们还有一些基于内容的召回方式比如说基于标题word2vec的召回方式,首先是拿全量帖子的标题训练word2vec模型。这样我们就能算出来每一个帖子的向量表示,然后根据用户点击过的帖子召回相关内容的帖子。
比如说用户点了司机客服,系统会给他推司机相关的帖子,也会推客服相关的帖子。在实际应用过程中,还会加入一些时间衰减的因素,来控制每一个类型的召回比例。
② 基于规则的召回方式
基于规则类的建模,比如说基于类目扩展的召回方式。由于58平台的分类体系比较细,约有上千种的三级类,这些类别之间很多类目非常相关的,比如说厨工和厨工助理类目下的帖子就比较相似,都可以推荐给相同的一批用户。类目扩展的方法是把某个类目下的所有的帖子放在一起,然后去挖掘这个类目的关键词,挖掘出类目的关键词后,通过这些关键词对比找到类目之间的相似程度,再去判断这个类目是否具有可扩展性。
0458排序
接下来介绍一下排序方面的一些算法,以及我们做的一些算法上的优化改进。排序主要分成两个阶段,粗排和精排阶段。
1. 粗排
① 粗排模型化
粗排的目标是从上千的候选集中选出200到300个候选集,然后再吐给精排,所以说粗排模型对性能的要求会比较高。线上的性能要求一般是要求在15毫秒以内,所以粗排不太适合使用特别复杂的模型来做。另外,粗排的目标也需要是尽可能的与精排目标保持一致的。随着前面召回通道的增加、召回候选集的增加,粗排策略也经历了一系列的演进,主要包括以下这么几个阶段。
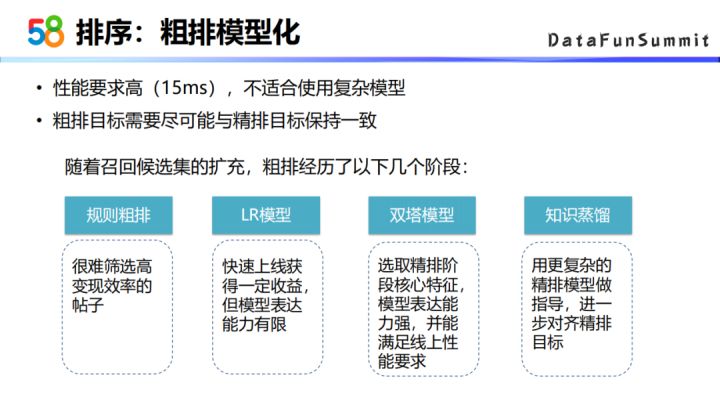
最开始的粗排是基于规则的方式,因为候选集比较少,基于规则的这种方式会比较便捷有效。之后随着候选级的增加,为了快速上线获得一些收益,我们上线了一个LR的模型,后来又为了能够提高模型表达能力,采用了双塔的双层模型的方式。双塔模型结构相对来说还没有特别复杂,可以满足线上项目的要求。后来我们调研了知识蒸馏的方法,主要是用更复杂的精排模型做指导,进一步的对齐精排的目标。
② 粗排特征
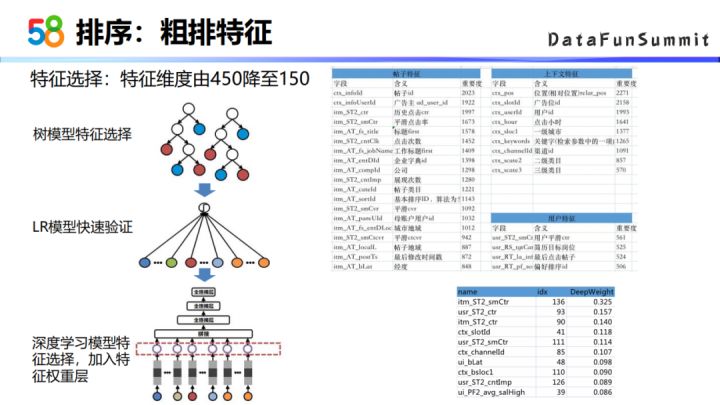
由于粗排阶段有性能的要求,所以我们在做粗排之前对特征做了特征选择,最开始采用的方式是用树模型和LR模型的方式来去做特征选择,后来是用深度学习模型的方式去做特征选择。这里主要是加入了一个特征权重层,然后选取训练结果中特征权重比较大的一些特征,最终特征维度由450维降为降成了150维。
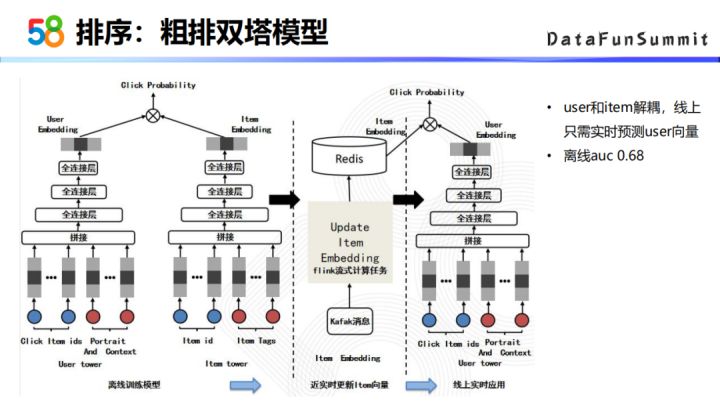
③ 粗排双塔模型
粗模型我们采用的是双塔模型的结构。双塔模型的一个好处就是user的塔和item的塔是解耦的,在线上预测的时候只需要进行用户侧向量的实时推断,item这一侧的向量可以近实时的更新在Redis中,然后在线上读取这些候选集item的向量,再跟实时计算好的用户向量去算相关性,算一个最终的点击率预估的结果。这个模型的离线AUC能达到0.68。
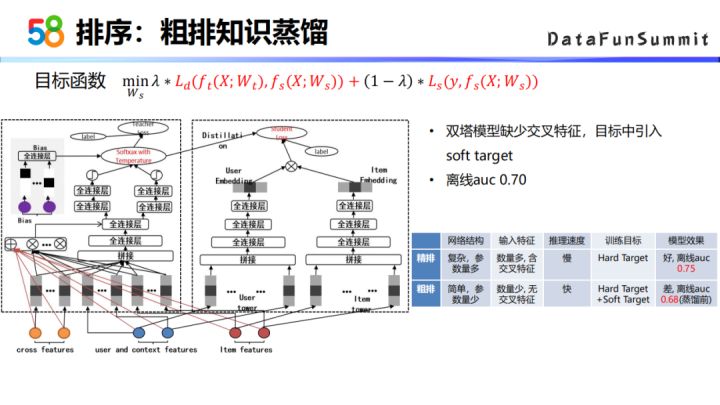
④ 粗排知识蒸馏
粗排模型的网络结构相对来说没有很复杂,参数较少。精排阶段包含了交叉特征等复杂特征,且特征量较多。因此在粗排阶段,可以用精排的模型来去指导我粗排的目标。
我们调研了粗排的知识蒸馏模型。主要的想法是把粗排环节的优化目标分成两部分,一部分是精排模型作为teacher网络去指导粗排模型的soft target目标;另一部分就是原始的优化目标hard target,把这两部分加起来作为整个粗排的最终的优化目标。经过知识蒸馏的做法后,离线的AUC达到0.7。
2. 精排
① 精排面临的问题
精排阶段我们面临的第一个主要问题就是点击率与展现位置是强相关的,即展现位置越靠前,它的点击率也就越高。
这种positionbias的问题,业界有一些常见的建模方式。如把position的信息作为一个特征,在离线训练的时候是加入这个位置信息的,但这个位置信息跟其他的特征是没有交叉关系的,因为如果有交叉的话,线上拿不着这个位置信息对模型的效果是有影响的。在线上预测的时候,位置信息会设置为默认值或者缺省值。另外一种做法是YouTube一篇论文里面提到的,它把位置信息做成一个子网络,然后把位置子网络最终的logit值与前面的CTR预估的东西的值加在一块,然后再过sigmoid。第三种做法是华为的一篇论文,它的做法也是把位置的特征做成一个子网络的形式,但是它的建模方式是子网络出来的结果与CTR出来的结果是相乘关系。之所以是相乘,因为论文假设用户如果已经关注到这些帖子,那么它的点击率跟它的位置之间没有太大关系。但是这个位置又跟我是否关注是强相关,所以说是它表达形式的是我基于这个位置有多大的概率去关注到某个帖子,我关注之后又有多大的概率去点击。
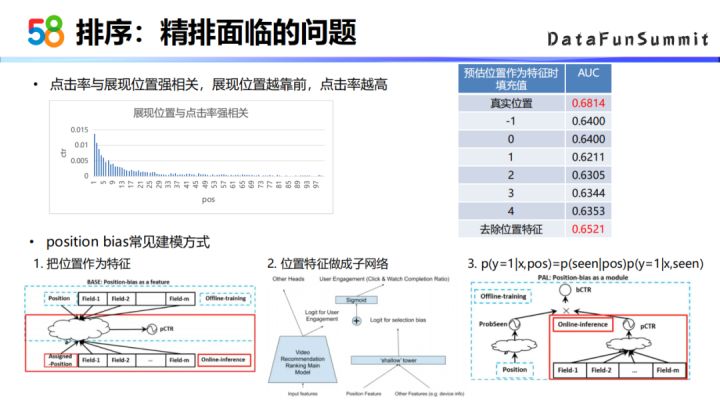
第一版的模型是把位置作为特征进行建模,上图右上角结果就是我们实验了不同填充不同位置来带来的效果。以实验结果来看不加入位置的特征效果会更好一些。
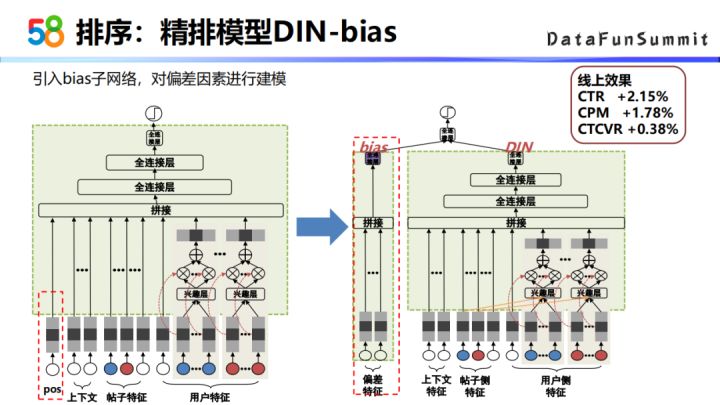
② 精排模型DIN-bias
第二版的模型参考了YouTube的做法,把位置偏差的信息作为一个子网络的形式来去单独的进行建模(下图右侧),左边时bias子网络,右边是一个DIN的网络结构。DIN这个网络结构主要是用到了上下文特征,帖子的特征,以及用户侧特征,用户侧的特征中包含用户行为的特征。DIN网络的一个主要特点是用户侧点击的帖子与当前的帖子有一层attention的网络结构。之所以这么设计,是因为用户历史的点击对当前是否点击起到的作用是不一样的。第二版模型的线上效果是CTR涨了2个点。
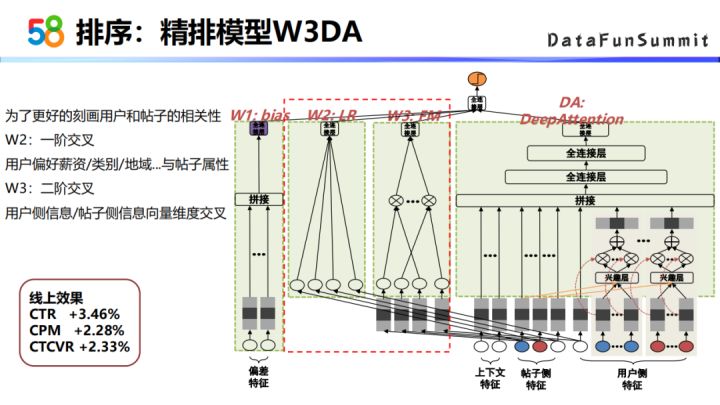
③ 精排模型W3DA
为了更好地刻画用户和帖子之间的相关性,前面是bias子网络加上DIN的网络结构,DIN网络结构可以认为是高阶特征交叉的网络模型,为了更好地刻画用户和帖子之间的相关性,我们在Wide这一部分又加入了两个Wide的子网络,就是W2和W3。W2主要是用户的特征与帖子的属性特征做了特征交叉,属于一阶的特征交叉。W3子网络,是用户侧的信息与帖子侧的信息在向量维度上做了一个特征交叉,属于一个二阶特征交叉。这个模型的线上效果是CTR涨了3.46个点。我们将这个模型称为W3DA。W3指的左侧的三个Wide部分的子网络,DA指的就是DeepAttention,这一部分就是DIN的网络结构。
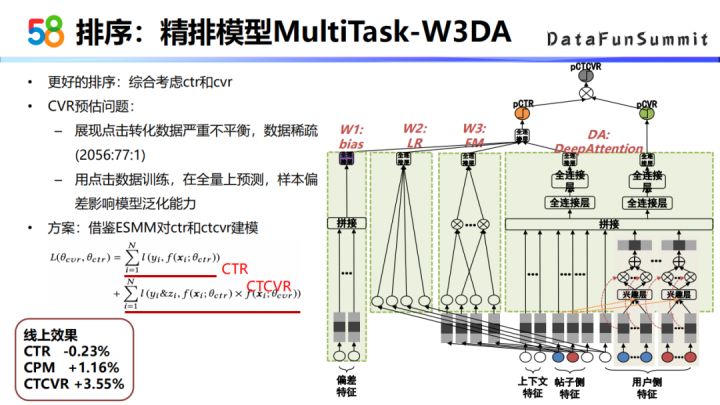
④ 精排模型MultiTask-W3DA
其实更好的一个排序结果,需要综合考虑CTR和CVR两个因素。但是CVR预估这个问题,本身天然的就有两个业界比较常见的问题,一个是数据比较稀疏,因为展现点击转化这个数据,它的比例是严重失衡的,尤其是到转化层面,转化的量是比较少的;另一个就是样本偏差的问题,在训练时如果单独训练CVR模型的话,其实是拿有点击的这些数据去进行训练,但是预测的时候是在全量数据上去进行预测的,样本偏差会影响模型的泛化能力。
这里我们借鉴了一下ESMM的模型,对CTR和CTCVR去建模,把CVR作为一个中间目标,这里的CTCVR其实就等于CTR乘上CVR。通过这种建模方式,最后的线上效果是CTR效果持平的前提下,CTCVR涨了3.55个点,也就是说最后的转化是有提升的。在最后排序的时候,不是直接用CTCVR的结果,是综合考虑CTR和CVR的结果,然后再去计算最后的排序分值。
04总结与展望
在召回阶段,我们目前的冷启动做的还相对较为简单,后面会尝试对用户的意图进行探索,动态的调整推荐给用户的结果。在排序阶段会尝试像DCNv2这种有具有更强表达能力的模型。后面会沿着加强推荐机制以及流量分配策略的方向,去打造一个更加健康的商业生态。

