随着短视频兴起,每天有海量的短视频上传到各大视频平台,面对海量的短视频,如何提升这些短视频的智能分发效率是各大短视频平台面临的重要课题。视频的标签技术是内容理解的一种重要手段,可以对不同兴趣的用户分发属于他们感兴趣的视频,从而提升平台的用户时长和ctr。
视频标签技术难点
由于视频内容是包含文本、视觉、语音等信息的多模态表现形式,如何提取多模态特征的表征能力并进行模态之间的融合互补,综合应用在模型中并取得较好的结果是至关重要的,该领域存在以下几个技术难点。
标签量级大
由于标签的粗细力度对内容推荐和下游分发的精准性有很大的影响,所以标签的量级越大、覆盖范围越广,越能精细表示视频内容和用户习惯。网易新闻站内标签是以几十万量级计数,并且每个视频有多个标签所属,同时标签长尾分布现象严重,常规的多标签分类方式解决已不再适用。
标签覆盖率低
比如一个视频的标题为“这才是百姓小馆,特别接地气”,视频内容是在餐馆用餐,标注同学标注结果是探店美食,但是同样日常美食、美食测评也同样满足这个视频内容。但是这些可用标签没有被数据标注的情况给模型学习带来了挑战。
多模态信息理解差异化
视频是一种多模态的内容形式,包括文本、图像、音频等多种模态的信息。对于不同的视频,不同模态的重要程度也不同,因此需要对多模态的信息进行综合全面的向量表征。
技术解决方案
针对以上对视频内容标签流程的难点和挑战,我们设计了基于召回-排序的两段式算法流程,如图1所示,召回是视频和标签粗粒度匹配的过程,排序是视频和标签细粒度匹配的过程,用来做精细化标签适用性的排序。此算法可以很好地解决视频标注过程中的难点。

图1 视频标签解决方案
召回阶段
召回阶段核心目标在于召回尽可能多、尽可能全的候选标签。我们采用video-video-tag的方式召回,通过query视频向量召回相关视频,从而相关视频的原始标签可以被query视频获取。为保证召回标签尽可能全面,我们按照以下五个维度进行召回:
文本语义相似
对视频的文本采用sentence-bert[1]模型获取embedding进行相似召回。
视频语义相似
对视频进行抽帧后经过clip[2]提取图像特征后进行mean pooling得到embedding进行相似召回。
音频语义相似
对视频中背景音乐截取经过vggish[3]提取音频特征后进行mean pooling得到embedding进行相似召回。
多标签分类结果:
建模视频多模态多标签分类模型,将输出结果作为召回标签。具体结构如图2所示。因为该模型的目的是训练通用视频表征能力的embedding,所以模型的分类类别较多。与传统分类模型相比,我们添加了标签embedding和视频融合embedding的相似学习分支,增强视频向量在语义空间的鲁棒性,也取得了预期的效果。

图2 多模态多标签分类模型
多模态语义相似
对视频,文本,音频三路特征进行多模态融合后得到embedding进行相似召回。
基于以上五种召回方法,对比召回结果和原始标签标注结果计算召回率,如表1所示。其中,应用于多模态相似召回和多标签分类召回的网络模型为我们原创模型。
表1 多种召回方式召回率

排序阶段
排序阶段核心目标在于精准排序所有召回的标签,排序模型的结构如图3所示。
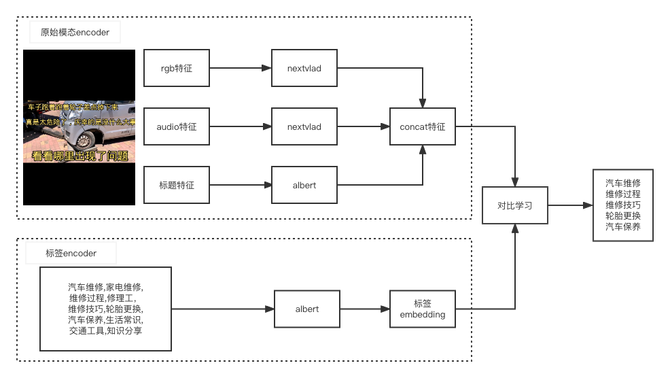
图3 对比学习排序模型模型
排序模型中,我们采用了nextvlad[4]的进行视频帧特征和音频特征的聚合降维,使得视频,音频和文本特征可以进行模态对齐。文本特征提取我们采取了轻量化的tiny-albert[5]模型,便于线上快速推理。
排序模型是基于向量对比学习,目的是拉近视频的相关标签和推远无关标签。我们实验发现在对比学习中,负样本标签的构建尤为重要。我们尝试了纯简单样本,加大负样本的negative_num,困难样本等多种思路,得到以下结论:
1、当只用简单样本时,并且负样本采样个数为10个时,排序模型可以将无关召回标签排在后面,高相关性标签排前,但相近的标签区分度不大。并且当召回源较多时候,排序准确性会降低。
2、加大负样本的negative_num到400时,极大解决了召回源多时,排序不准确的问题。但还会存在一定程度相近标签难以区分。
3、尝试进行"2跳"方法构建困难负样本进行训练,即与video1有相同标签的videok的其他标签,当做video1的困难负样本。很大程度相近标签解决精准排序问题。
以上三种尝试的排序样例如表2所示(未进行相似标签去重和个数限制)。以第二个视频为例,我们可以明显观察到视频的的ground_true 是篮球比赛,在负样本较少的情况下(negative_num=10)排序top5会出现足球运动,拳击运动等体育相关的运动,但跟篮球无关,细粒度排序效果差。当增加负样本 (negative_num=400)后,排序top5的结果有所改善,拳击运动排在靠后位置,当(negative_num=400)并且增加困难样本后,排序top5出现前四个全部描述篮球运动的,后一个体育资讯也是与篮球运动有相关性的。可以得出训练时增加负样本比例,增加困难样本,可以得到更好的排序结果。
表2 排序结果对比

效果评估
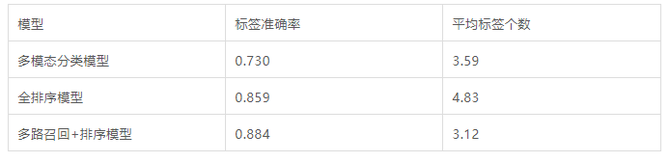
综合以上方案设计,我们在网易新闻客户端落地机器标签预测模型。后续通过扩展标签的embedding,无需模型训练可以直接扩充标签覆盖数目。同时,我们对比了多模态分类结果,多路召回+排序结果,和全排序的结果(即无召回阶段,在全部的标签上直接做排序)。如表3所示。多种方案的人工评测数据效果可供参考。
表3 多种标签方案指标对比
总结展望
本文提出了一种多模态视频多标签的建模方法,旨在通过引入召回排序的方式,去提升标签预测的准确性。同时落地在视频新闻场景,在下游推荐算法中取得了不错的业务效果。未来希望融入图谱知识到模型中,提升模型的泛化能力。

