DeepSeek-V4炸场:百万上下文成“水电煤”,携手昇腾打破算力霸权
日前,AI圈又迎来了一场久违的“周五惊喜”。
没有预告、没有直播、没有路线图,DeepSeek在这一天悄然发布了全新系列模型——DeepSeek-V4。不仅同步上线官网与App,更毫无意外地再次开源。
相比半年来各种传闻的喧嚣,DeepSeek只用一篇发布稿回应了一切。而这篇稿子的结尾,引用了一句古语:“不诱于誉,不恐于诽,率道而行,端然正己。”
这不仅是态度,更是实力宣言。
V4到底有多强?两个版本,两种打法
DeepSeek-V4本次一口气推出两个版本:

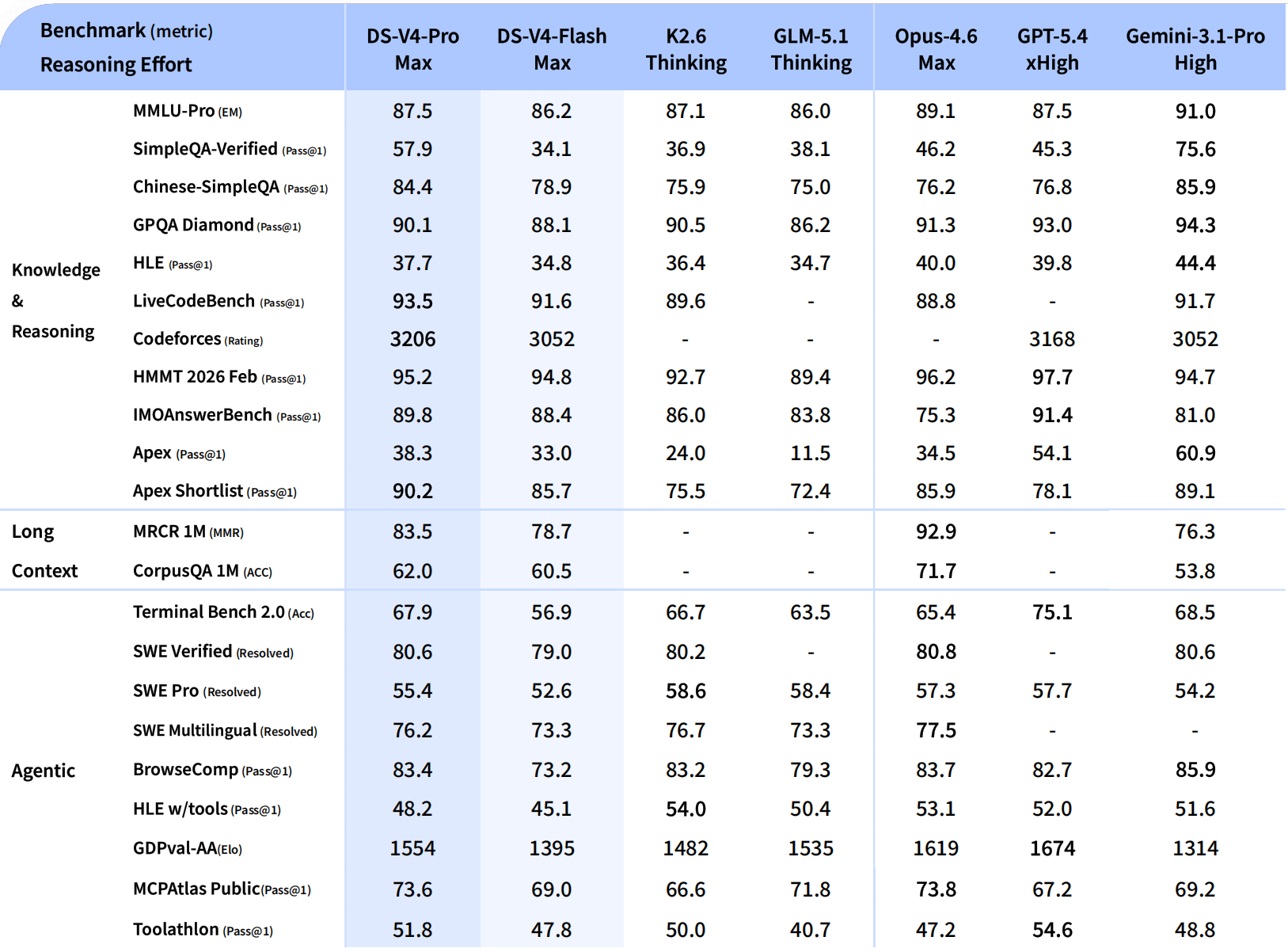
DeepSeek-V4-Pro:总参数1.6T,激活49B,对标顶 级闭源模型。
DeepSeek-V4-Flash:总参数284B,激活13B,主打性价比。
二者均支持1M上下文长度,这不是“高端功能”,而是所有官方服务的标配。一年前,1M上下文还是Gemini独家的王牌;今天,DeepSeek把它变成了“水电煤”。
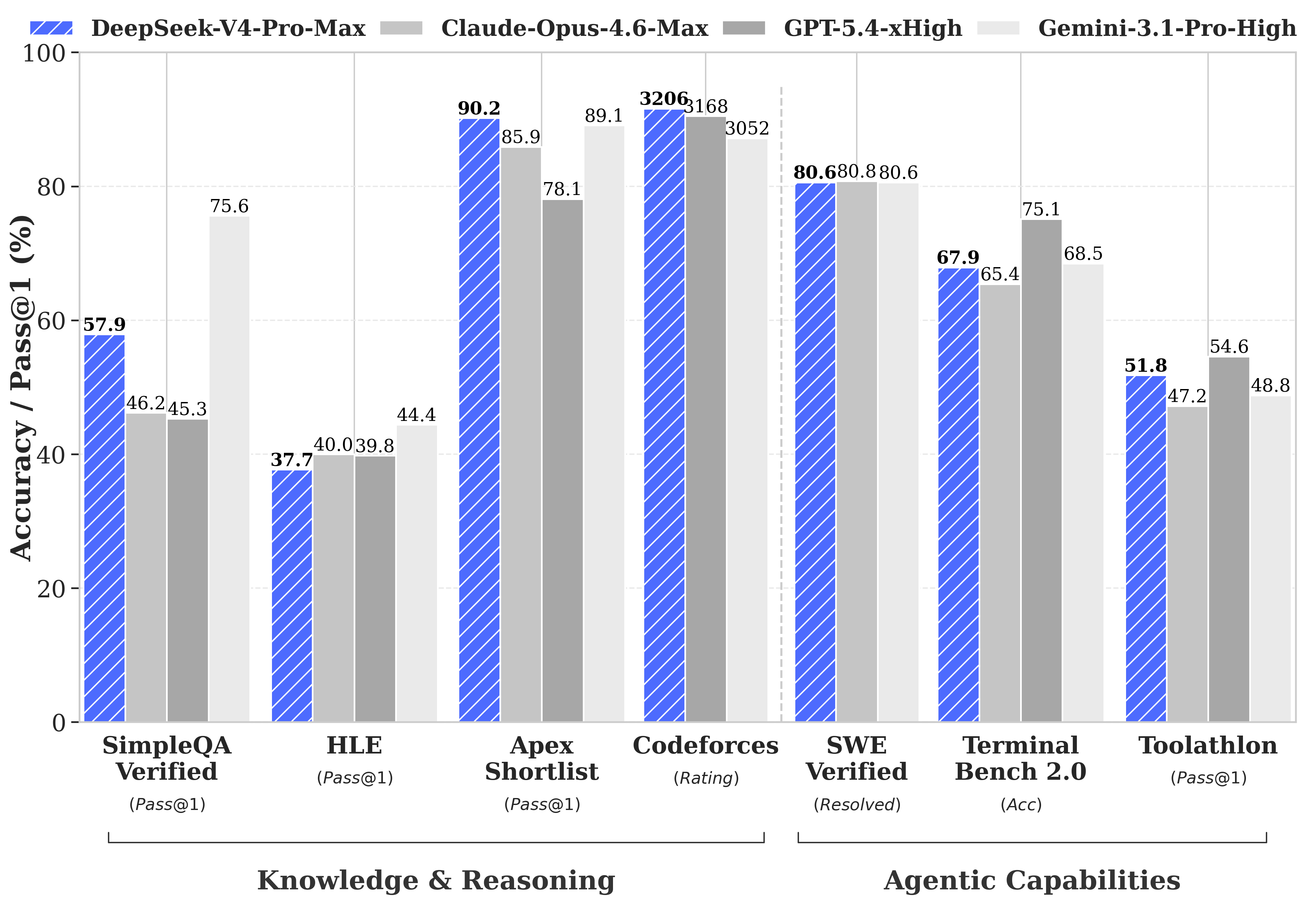
在性能上,官方给出了三个判断:
Agent能力大幅提高:在Agentic Coding评测中达到开源更优水平。内部员工已全面使用V4替代Claude,评测反馈使用体验优于Sonnet 4.5,交付质量接近Opus 4.6非思考模式。
世界知识领先:大幅领先其他开源模型,仅稍逊于Gemini-Pro-3.1。
推理性能顶 级:在数学、STEM、竞赛型代码测评中,超越所有开源模型,比肩世界顶 级闭源模型。
更值得关注的是,V4-Flash以极低成本实现了接近Pro版本的推理能力,这对中小开发者和企业来说,是真正意义上的“平权”。
技术突破:DSA稀疏注意力+1M上下文
V4最核心的创新,是一套全新的注意力机制。它在token维度进行压缩,结合DSA稀疏注意力(DeepSeek Sparse Attention),大幅降低了对计算和显存的需求。
其实,DSA并不是今天才出现的新词。半年前V3.2-Exp那次“没什么亮点”的更新,外界关注度不高,因为跑分几乎没有变化。现在回头看,那是V4的地基。
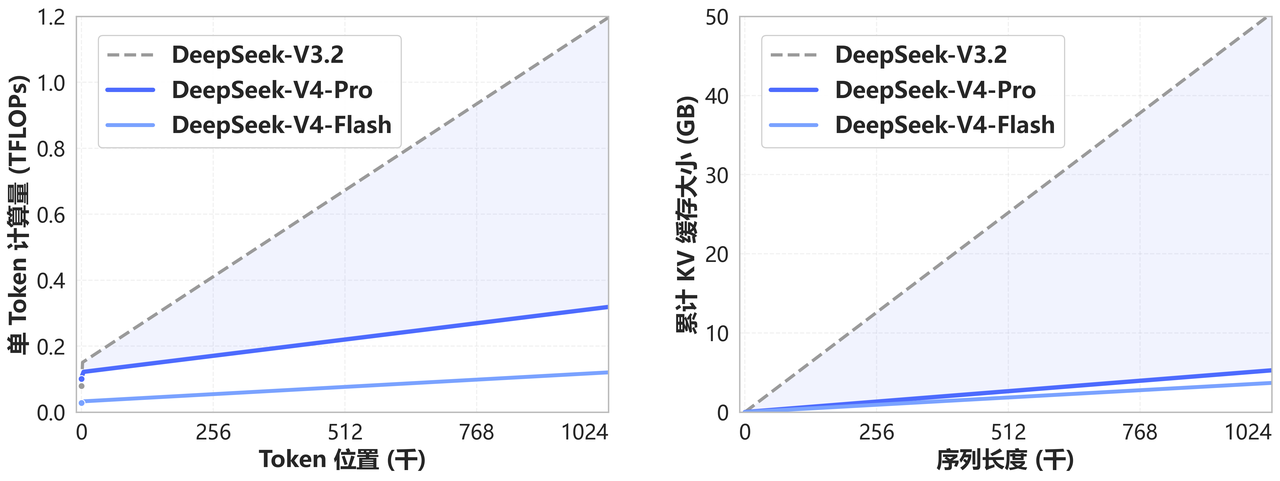
DeepSeek用半年时间默默铺路,然后在某个周五的上午,把一切都端了出来。
最大看点:下半年批量上华为昇腾算力
在这次发布中,有一个被很多人忽略、但极其关键的信息——
“下半年批量上华为算力。”
据多家媒体报道,DeepSeek-V4已经在华为昇腾NPU上完成了细粒度专家并行(EP)方案的验证。这意味着,DeepSeek的推理路径已经具备跨算力平台的适配能力。
当然,当前开源的版本仍主要基于CUDA工具链,深度绑定英伟达生态。但官方明确表示:受限于高端算力,目前V4-Pro的服务吞吐有限,预计下半年昇腾950超节点批量上市后,Pro价格会大幅下调。
这释放了一个清晰的信号:DeepSeek一边在现有CUDA生态内做极致优化,一边在为华为昇腾等多算力环境预留空间,开始尝试把模型运行时从单一硬件依赖中解耦出来。
而昇腾方面也迅速回应,宣布昇腾950超节点可实现DeepSeek V4-Pro 20ms、V4-Flash10ms的低时延推理,A3超节点系列产品全面适配,同时开源了PyPTO编程范式与TileLang方案。
这是中国AI产业链“芯模协同”的一次标志性落地。
API更新与旧模型下架:开发者请留意
API方面,V4-Pro和V4-Flash均已上线,支持OpenAI ChatCompletions和Anthropic两套接口。base_url不变,model参数改为deepseek-v4-pro或deepseek-v4-flash即可调用。
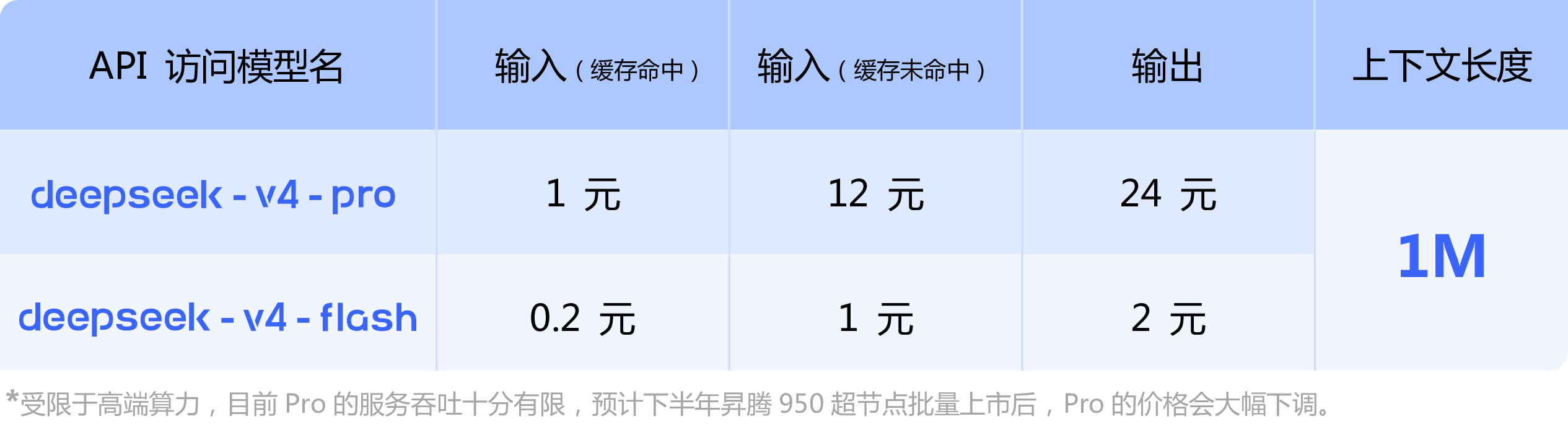
两个版本均支持非思考模式与思考模式,思考模式可通过reasoning_effort参数调强度(high/max)。复杂Agent场景建议直接上max。
重要提醒:旧模型名deepseek-chat和deepseek-reasoner将于2026年7月24日停止使用。过渡期内,它们分别指向V4-Flash的非思考模式和思考模式。对接了生产环境的公司,这三个月要去做迁移。
笔者观察:率道而行,说到做到
过去半年,关于V4什么时候发、是不是跳票、是不是已经被别家超越的传言,在中文和英文AI圈来来回回跑了好几轮。年初还有人信誓旦旦说V4会在春节前发,结果等到了四月底。
DeepSeek没有回应过一次。然后,他们在一个周五的上午,把V4放出来,同步开源,同步上线官网和App,同步更新API,顺便把内部员工已经弃用Claude的事实写进发布稿。
没有路线图,没有直播,没有访谈。当你把半年前那次“没什么亮点”的V3.2-Exp、DSA那套为V4铺了半年的稀疏注意力、1M上下文从王牌变成标配的这条路径放在一起看,DeepSeek已经做到了。
而那句“率道而行”,也终于从一句口号,变成了中国AI开源史上最硬核的注脚。

