当算力遇见科学:一场刷新世界纪录的“微观破界”
在科学研究的长河中,人类对物质世界的认知始终遵循着某种“尺度逻辑”。从肉眼观察的宏观现象,到显微镜下的细胞结构,再到原子尺度的量子行为,每深入一个量级,都意味着对自然规律理解的跨越。
然而,长久以来,科学界面临一个尴尬的现实:最精确的第一性原理计算,能模拟的原子规模往往只有几百上千个;而真实世界中,一个半导体器件的局部接触面就包含数亿原子,一块电池界面的复杂结构则达到百纳米量级。计算能力与现实之间的差距,如同横亘在科学家面前的一道“认知天堑”。
如何突破这一瓶颈?答案指向算力。那种能将量子力学精度与工业级尺度无缝衔接的超级算力。
近日,一场由中科曙光、龙讯旷腾与超算互联网联合举办的沟通会,向外界披露了一个令人振奋的答案:在三方协同努力下,基于曙光scaleX万卡超集群与龙讯旷腾MatPL软件,成功完成了414.7亿原子规模的液态水分子动力学模拟,所有原子间相互作用均达到第一性原理级精度,一举刷新该领域的世界纪录。
这不仅是一次数字上的超越,更是一场关于国产科研范式变革的深度叙事。
“四百亿”:一场没有硝烟的算力竞速
“414.7亿原子”,这个数字意味着什么?
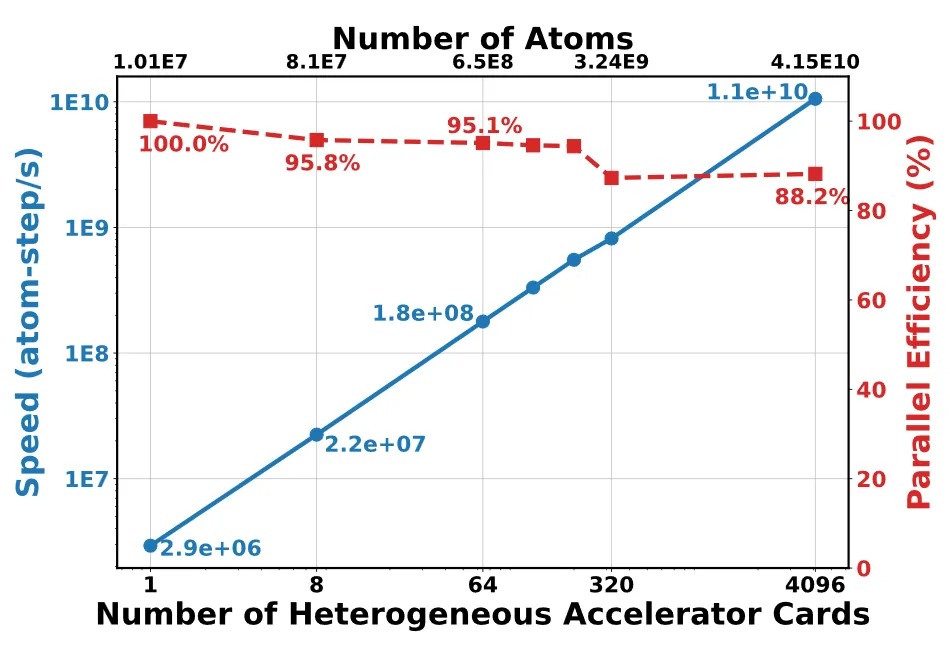
如果我们做一个直观的对比:此前公开报道中,机器学习力场分子动力学模拟的世界纪录是290亿原子。此次成果将其提升了1.43倍。更重要的是,模拟的体系边长达到了700多纳米。这在微观世界已是接近微米级的“庞然大物”,第一次将第一性原理精度的原子尺度模拟,推向了介观尺度。
“以前从来没有这样的模拟解决方案,能够以第一性原理精度真实复现这种场景。”北京龙讯旷腾科技有限公司高级研究员、机器学习研发总监索鹏飞表示,无论是多晶材料百纳米级的晶粒尺寸,还是7纳米、5纳米工艺的半导体器件,乃至固态电池中电极与电解质界面处复杂的结构,“现在都有了从0到1的突破可能”。
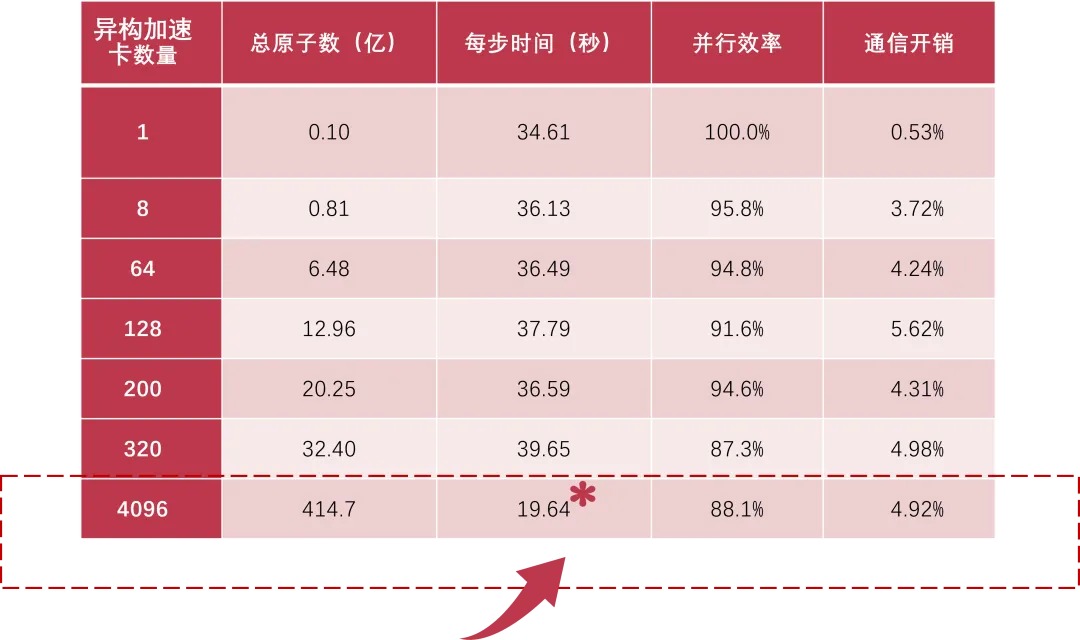
而支撑这一突破的底层力量,是基于scaleX万卡超集群4096张异构加速卡的高效并行运行。这意味着,每增加一张卡,算力几乎线性增长,通信开销被压缩到极致,4096卡并行时,通信占比仅为4.92%,计算占比始终超过90%。
“这套系统证明了,我们不仅造得大,更跑得顺。”中科曙光解决方案与创新业务总经理张磊如是评价。
软硬协同:一场“双向奔赴”的技术攻坚
如果说算力是舞台,那么软件就是那位真正的舞者。
本次模拟所使用的核心软件,是龙讯旷腾最新发布的MatPL-2026.3版本。与传统的机器学习力场软件相比,MatPL实现了五大技术创新:从跨节点多卡并行训练,到单卡性能比肩国际主流软件,再到内存占用优化20%,以及最重要的是支持大规模并行,打破了以往力场软件无法跨节点模拟的限制。
“机器学习力场的模型不同于大语言模型。大模型一次问答可能只需要几十到几百步计算,但我们的应用场景,大部分任务需要百万步。”索鹏飞强调,“效率是决定性的。”
正是基于对效率的极致追求,龙讯旷腾团队与中科曙光团队走到了一起。双方的技术人员在底层展开了深度协同:从针对核心矩阵运算创新应用TensorFloat-32算力,到将AI的Tensor核心能力赋能科学计算,再到利用GPU架构对传统数据计算单元的完整保留——每一个优化点,都是软硬件工程师反复碰撞的结果。
“以往大家做算力的只管做算力,做软件的只管做软件。”张磊回顾合作历程时感慨,“这次我们真正实现了面对面的协同。两支团队都有材料和物理的核心背景,沟通成本极低,能快速把算法优化的方向和硬件的优势拿到台面上。”
这种协同机制,或许比破纪录本身更具示范意义。
国产替代的“无感”跨越
在当前的国际环境下,国产算力的发展始终绕不开一个核心命题:能否真正替代,能否好用?
北京龙讯旷腾科技有限公司总经理田洪镇给出了回答:“曙光这边最大的优势,对于我们开发人员来讲,可以说就是两个字——无感。”
“我不需要专门针对这个硬件去写专门的适配代码,也不需要为通信做专门的调整。这是最大的优势。”田洪镇进一步解释,曙光提供了成熟的转换工具,能够将原本基于英伟达架构的软件,直接编译到基于国产X86和国产AI加速卡的架构上,“适配成本没那么高”。
这种“无感”的背后,是曙光多年来在底层技术栈上的深耕。从芯片微架构到编译器,从数据库到驱动层,曙光构建了完整的技术闭环。而本次scaleX万卡超集群所展现的高密度算力集成、高速互联网络、以及相变浸没式液冷等技术,共同构成了国产算力从“可用”到“好用”再到“领先”的三级跳。
“这套集群的冷却、供电技术和硬件架构,均可比肩2027年NVL-576水平。”张磊的这句话,无疑为国产算力注入了一剂强心针。
科研普惠:让“大算力”走进“小课题组”
如果说破纪录代表着技术的高度,那么如何让这种能力惠及更广泛的科研群体,则决定着技术的广度。
本次模拟的另一个重要信号是:在4096卡上实现414.7亿原子模拟的同时,单卡性能同样惊人。据透露,单张加速卡即可模拟千万级原子体系,一台8卡服务器则可达到上亿原子规模。
“这意味着,一个更小的科研课题组,就可以用少量的资源,模拟世界级的超大规模体系。”张磊解读道,“我们把更大、更宏观的东西,通过算力的价值,带到了小课题组面前。”
而超算互联网平台在其中扮演了“连接器”的角色。据超算互联网平台龙讯旷腾项目负责人介绍,目前平台注册用户已接近120万,通过弹性算力调度、预安装预优化的软件生态、以及7×24小时的技术支持,大幅降低了科研人员使用国产仿真软件的门槛。
“将来随着大语言模型的发展,我们还在跟曙光探讨打造材料模拟的智能体。”负责人透露,“让材料计算软件变成可以用自然语言驱动调用。用户不关心软件怎么起作用,只关心我要设计一个新的电池,底层自动调软件、自动算、自动出结果。”
这或许才是“AI for Science”的终极愿景:让科学家回归科学本身,而非被工具所困。
笔者观察:一次破界,三重启示
回顾本次414.7亿原子模拟的突破,至少带来三重启示。
第一,软硬协同是国产科研生态的必由之路。长期以来,国内科研软件与硬件的发展相对割裂,导致“有算力无软件、有软件无优化”的尴尬。曙光与龙讯旷腾的深度绑定,证明了当两个懂行的团队真正坐在一起,能够产生的化学反应远超预期。
第二,国产替代不应止步于“能用”,更要追求“好用”与“领先”。本次模拟不仅在规模上刷新纪录,更在扩展效率、通信优化等关键指标上展现出世界级水平。这证明,国产算力与国产软件的融合,完全有能力与国际巨头同台竞技。
第三,算力的终极价值在于普惠。破纪录固然振奋人心,但如何让顶尖算力走出“象牙塔”,服务于更广泛的科研与工业场景,才是决定国家整体创新能级的关键。超算互联网的实践表明,平台化、服务化、智能化是算力普惠的可行路径。
414.7亿原子,是一个数字,更是一个起点。当微观世界的边界被不断推远,中国科研的想象力,也将随之抵达更遥远的星辰大海。

