从Kafka到AutoMQ:爱奇艺实时流数据架构演进
本文详细介绍了爱奇艺在处理大规模实时流数据时,从传统Kafka架构向AutoMQ演进的技术历程。为了解决私有云环境下集群扩缩容难、资源利用率低以及运维成本高等挑战,爱奇艺开发了Stream平台与Stream-SDK,实现了业务与底层存储的彻底解耦。随后,公司引入公有云服务并最终切换至基于存算分离架构的AutoMQ,利用其单副本存储和秒级弹性的特性,显著提升了系统的灵活性。这一系列的架构升级不仅优化了数据治理体系,还成功将运营成本降低了70%以上。目前,爱奇艺正持续扩大AutoMQ的应用规模,以进一步实现降本增效的长期目标。
01# 背景
Kafka因其高吞吐、低延时、可扩展的特性,在出现之后迅速成为流数据存储的标准组件,广泛应用于实时大数据场景。爱奇艺的流数据服务也主要基于Kafka构建,随着实时大数据应用越来越广泛,Kafka集群数量、规模越来越大,面临扩缩容繁琐、成本高、难治理等诸多问题与挑战。为解决这些问题,我们进行了Kafka服务化、上云、迁移AutoMQ等一系列探索。
本文将介绍爱奇艺Kafka从私有云迈向公有云、从Kafka到AutoMQ的探索与实践。
02# 流数据在爱奇艺的应用
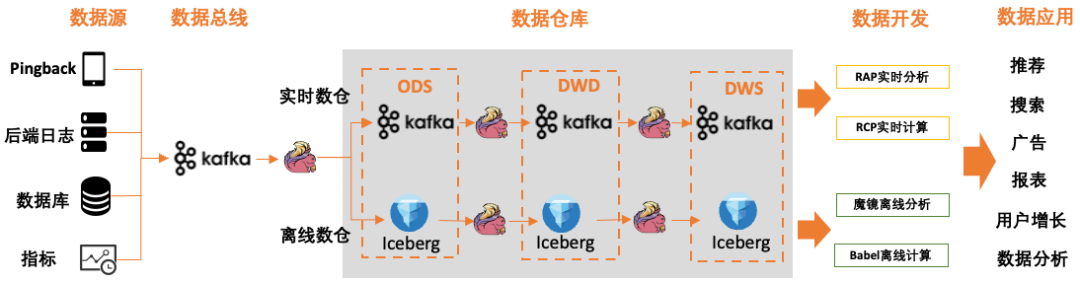
图1 数据通路
在爱奇艺,流数据的存储组件使用的是Kafka,计算组件主要使用的是Flink,流数据相关的典型数据通路如图1所示,主要包括如下环节:
数据集成:Pingback(端上投递日志)、后端日志、数据库binlog、指标等持续产生的流数据,实时写入数据总线Kafka。
数据仓库:由Flink程序将数据引入到实时(流式)、离线(批式)数仓。在实时数仓中,数据仍然以流数据形态存储在Kafka中,并通过Flink构建实时数仓各层数据。在离线数仓中,流数据将会聚集成批数据存储在Iceberg中,再由 Flink增量消费Iceberg构建离线数仓各层数据。实时数仓具备秒级延时,离线数仓具备分钟级以上延时。
数据开发:数仓的数据通过数据开发平台应用到各业务场景。在实时计算中Kafka也会作为中间流数据的存储用于任务之间的解耦。
数据应用:数据广泛应用到爱奇艺的推荐、搜索、广告、报表等等场景中。数据的价值随着延时增大快速衰减,为了数据价值最大化,近几年主要应用场景都已切换到流数据。
Kafka作为流数据的存储承担数据集成到大数据体系的数据总线、实时数仓存储、实时任务之间解耦等角色。
03# 流数据存储服务:从管集群到管数据
爱奇艺的流数据服务最初以Kafka集群为核心构建,提供集群生命周期管理、Topic管理、消费监控等基础能力。随着业务规模扩大、集群数量和数据量持续增长,逐渐暴露出以下问题:
业务与集群强耦合:业务代码直接依赖Kafka地址访问集群,一旦需要迁移或调整集群,必须修改业务代码并重新上线,不灵活。同时也无法从平台侧统一识别和监控各业务的读写行为。
缺乏统一的数据与schema管理:平台没有管理数据描述、schema、数据归属等元数据信息,无法提供数据查找功能,不利于跨团队的数据理解、复用与治理。
主备数据管理缺失:对重要数据,业务侧通常配置主备链路,但平台侧缺乏对主备关系的统一管理,难以做到一致性保障与故障切换治理。
为了解决上述问题,我们将流数据存储服务升级到了如图2所示的架构,由Stream平台、Stream-SDK、存储组件三部分构成。
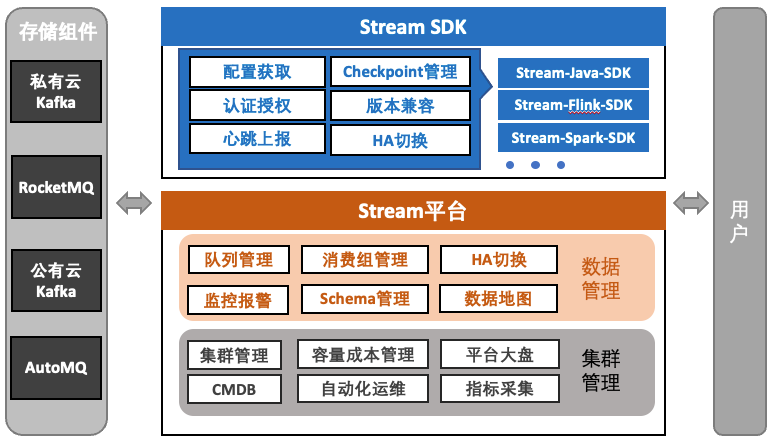
图2 流数据服务架构
先介绍下Stream平台,Stream-SDK和存储组件后面介绍。Stream平台由“集群管理”和“数据管理”两大模块组成。集群管理负责集群生命周期与底层资源的统一管理,侧重运维侧能力。数据管理是平台的核心,以“数据为中心”构建,面向数据开发人员提供统一的数据视图和管理能力,核心功能如下:
逻辑队列:原先“集群+Topic”定位数据的方式,升级为基于“项目+队列(Topic)”的逻辑命名方式,集群仅作为队列的一个属性,消除业务对具体集群的依赖。逻辑队列还支持同时绑定主备两个集群,结合Stream-SDK可实现主备链路的一键切换。
Schema管理:支持为队列配置schema,并自动同步至大数据元数据中心,使队列能够在数据开发平台中自动映射为逻辑表,使用SQL直接处理流数据。
数据地图:提供队列的多维度查询与检索能力,支持在线申请和授权使用队列,简化跨团队的数据查找和复用流程。
数据血缘:基于Stream-SDK自动上报的读写端信息,构建应用级的读写血缘链路,帮助快速定位上下游数据关系及影响范围。
04# Stream-SDK:统一的流数据读写客户端
Stream-SDK是平台提供的统一数据访问客户端,封装了底层原生客户端,兼容Kafka协议和RocketMQ。业务仅需配置“项目+队列”,即可完成数据读写,无需关注具体集群地址或认证方式,从而实现业务代码与底层集群的彻底解耦。
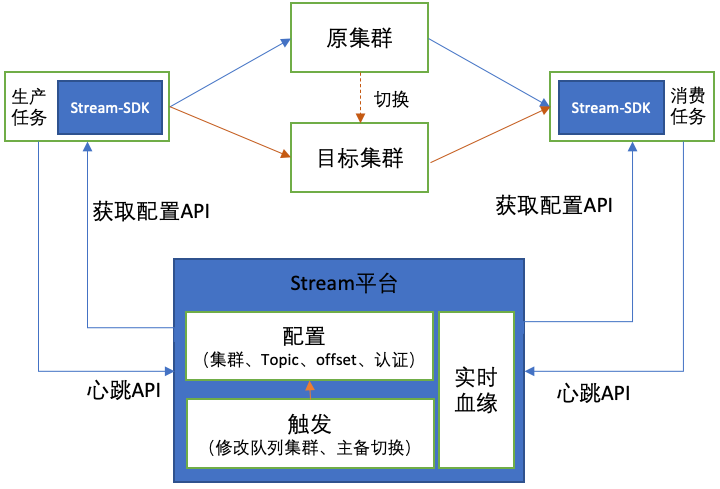
图 3 Stream SDK 读写数据过程
Stream-SDK的数据读写流程如图3所示,主要包括两个阶段:
配置获取与上报
基于业务提供的项目、队列和Token(用于鉴权),SDK调用Stream平台的配置API,获取队列对应的集群信息、Topic、认证参数等配置,并使用原生客户端执行读写。同时,SDK会通过该API上报客户端IP、消费组、应用名称等信息,平台据此实时构建读写血缘。
集群变更感知与自动切换
在运行期间,SDK每分钟与Stream平台进行心跳交互,实时感知队列关联的集群是否发生变更。一旦检测到变化,SDK会自动将读写流量切换至新集群,实现无感迁移。
借助Stream-SDK,集群的迁移成本大幅降低,也为后续从私有云迈向公有云、从Kafka切换到AutoMQ的架构演变做好了准备。
05# Kafka混合多云建设
早期爱奇艺Kafka集群部署在私有云IDC,受制于IDC资源供给模式及Kafka架构固有特性,资源利用率难以保持在合理区间。自2023年起,平台逐步引入多家公有云Kafka,形成混合云架构,在资源弹性、运维效率和成本优化方面取得了显著成效。下文将介绍下上云过程。
私有云Kafka
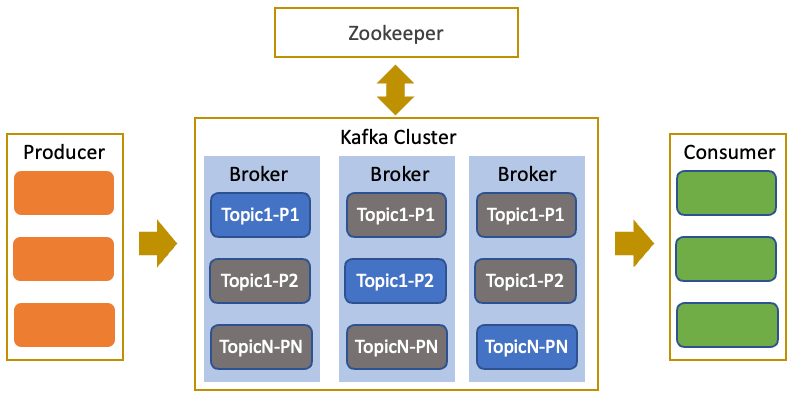
图4 Kafka 架构
Kafka架构如图4所示,是经典的多副本容错分布式架构,由Broker和Zookeeper两类角色组成:Broker负责数据存储与客户端读写,Zookeeper负责管理集群的元数据与协作状态。在私有云中,Kafka部署在爱奇艺各IDC,其中Zookeeper通常以虚机部署,Broker则根据场景选择虚机或物理机。
私有云模式支撑了公司流数据规模的快速增长,但随着业务体量持续扩大,也逐渐暴露出以下问题:
集群弹性差:Kafka的Shared Nothing架构虽然简单可靠,但每个Broker上都存储大量数据,导致扩容或缩容时必须在Broker间进行大规模数据迁移。迁移过程耗时长且会影响业务任务的读写性能,使得集群难以实现平滑弹性伸缩。
资源弹性不足:私有云的物理资源从采购到报废周期较长,难以随业务流量动态变化而快速调整,导致集群资源利用率长期处于“过高或过低”的状态。同时,对于寒暑假、重点直播等短时流量高峰,也难以做到按需扩缩,影响系统整体资源效率与成本优化。
从私有云Kafka到公有云Kafka
为实现降本增效并提升流数据存储的灵活性,我们引入并上线了公有云Kafka产品。
公有云Kafka产品遵循Kafka协议,通过在Stream平台与Stream-SDK中进行统一适配,为业务侧提供一致、无差异的使用体验,实现了私有云与公有云之间统一接入和平滑切换。
借助公有云庞大的资源池和按需创建集群的能力,解决了私有云环境下资源弹性不足的问题,取得20%以上的降本效果。
06# 从Kafka到AutoMQ
公有云Kafka虽然解决了资源弹性不足的问题,但是依然有集群弹性差的问题。新出现的AutoMQ支持秒级弹性吸引了我们的注意。
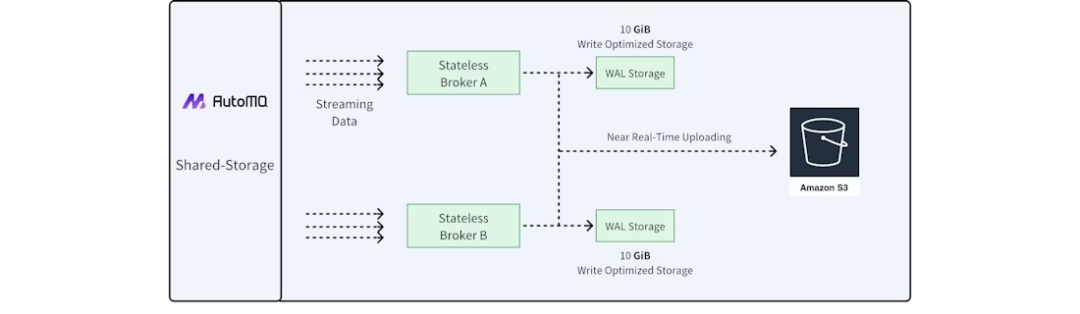
图 5 AutoMQ 架构
AutoMQ采用存算分离架构,如图5所示,具备如下特性:
共享存储:数据统一存储在对象存储中,Broker不再持有本地数据。为解决对象存储延迟高、IOPS较低的问题AutoMQ引入块存储作为WAL(Write-Ahead Log),数据先写入WAL再进行批量落盘到对象存储。
单副本存储:云端的块存储和对象存储本身具备多副本特性,已在存储层保证了高可用,因此AutoMQ内部的Topic均采用单副本策略,避免传统Kafka中Broker之间的副本同步开销,大幅降低成本与数据复制压力。
兼容Kafka协议:AutoMQ基于开源Kafka改造,保留计算层逻辑,替换底层存储实现,完全兼容Kafka协议。
快速弹性:由于Broker不再存储数据,节点可快速启动或销毁,实现分钟级弹性;同时对象存储按量计费,使资源规模能够与业务流量保持高度匹配,避免资源浪费。
在完成相关性能与稳定性验证后,我们在公有云环境部署了AutoMQ,并将其纳入流数据服务存储体系。通过Stream平台逐步将私有云Kafka、公有云Kafka迁移至AutoMQ,成本进一步降低70%以上。
07# 总结及规划
流数据因其低延时特性,已成为爱奇艺的重要数据通路。随着规模增长,传统私有云Kafka在弹性、成本与治理上逐渐遇到瓶颈,因此,流数据存储架构从“管集群”转向“管数据”,并通过Stream平台与Stream-SDK实现解耦与统一治理。随后引入公有云Kafka和AutoMQ,使系统在弹性、运维效率和成本上都实现了显著提升。
目前约40%的流量已迁移到公有云Kafka或AutoMQ,其中一半是AutoMQ,下一步将继续扩大AutoMQ的使用规模,并探索AutoMQ的自适应自动弹性机制,持续降本。

