Apache Hudi 在京东的最新架构演进
导读:本文基于京东&HudiMeetup亚洲站的分享内容,详细介绍京东数据湖现状、最新自研技术特性、业务实践、社区贡献与未来规划,展示京东如何通过数据湖技术推动数据资产准实时化,提升数据资产的价值。
01 京东数据湖现状
京东数据湖团队近年一直在利用数据湖能力推进整个集团数据的准实时化,帮助京东零售、京东科技、京东物流等子集团的核心数据资产提升数据时效,入湖的数据规模已达到500PB以上,支撑这些的是强大的底层技术架构和平台产品能力。
京东数据湖能力全景图
京东数据湖构建于HDFS等分布式存储系统之上,利用Hudi高性能的读写能力和文件组织来支撑准实时化加工链路,承接消息队列、Binlog、Hive、Hudi等数据源,支持高性能的流、批及OLAP查询。在底层技术之上,京东大数据平台提供全生命周期的产品能力,从表的创建、集成入湖、数据开发、任务调度,到数据查询、数据质量,到湖表替换Hive表的切换工具,通过提供相应的产品能力,来支持各个BGBU的数据团队进行准实时化改进。
京东Hudi基于社区0.13.1版本进行研发,旨在满足京东业务的特定需求。为此,我们在Hudi内核的组织协议层、IO传输层等多个关键模块,实施一系列自主研发的优化措施。
组织协议层
1. 索引方面,社区提供Bucket、BloomFilter等索引,京东自研分区级Bucket索引,差异化控制分区的Bucket数量,有效解决分区倾斜问题;此外创新性的自研外键索引,并基于外键索引实现流式的外键关联能力;
2. Merge Engine方面,在0.13.1中以PayLoad为主,社区提供了OverwriteWithLatest、EventTimeBased、PartialUpdate等,京东自研Multiple Ts支持多字段的合并逻辑,也对Partial Update做了增强。现在社区主推RecordMerger,后续京东也会补齐相关的实现。
3. 表格式方面,社区CoW与MoR已在京东实现生产实践。社区版MoR采用Base文件与Log文件相结合的组织模式,其中Log文件以Avro格式进行行存储。京东在实际应用中发现,社区版MoR在性能方面存在一定瓶颈。为此,京东自主研发基于LSM-Tree组织协议的MoR,采用分层管理机制,所有Log文件均以Parquet格式存储,其读写性能相较社区版提升了2至10倍。
4. 并发控制方面,社区提供了OCC和MVCC两种并发控制的模式, 京东自研的LSM-Tree组织协议实现了无锁并发更新的效果。
5. 文件布局方面,京东自主研发混合存储的布局方案,支持将一张表的数据分布于多个存储位置。其中一部分被称为缓冲层,用于存储如deltacommit等高频写入的数据,通常选择低延迟的高性能存储系统,如HDFS或ChubaoFS;另一部分则称为持久层,缓冲层中的数据通过表服务迁移至持久层。在读取时,系统会将缓冲层与持久层的数据进行联合,生成统一的文件视图。
6. 表服务方面,京东在社区版基础上实现增量式的表服务机制,有效避免因分区数量持续增长而导致的表服务耗时增加问题,从而显著降低对写入端的阻塞时间。
IO传输层
IO传输层的核心优化思路是减少序列化/反序列化的开销,京东自研二进制流拷贝Clustering,跳过计算引擎与Parquet文件间的行列转换,直接进行二进制流复制实现文件聚合;利用Engine-Native优化使用计算引擎的数据格式,避免行格式间的互转;利用ZSTD降低文件压缩过程中的CPU损耗。
02 最新自研技术特性
01. Hudi MoR LSM-Tree
在京东的业务实践中,随着数据规模的持续扩大与实时性要求的不断提升,Hudi MoR表在面对高并发、高吞吐的实时数据处理时,逐渐显现出多项性能与稳定性瓶颈,具体表现为:
1. 写入性能瓶颈:高流量数据写入时,MoR表执行更新需将增量数据与基础文件合并写回,难以兼顾低延迟与大吞吐量的并发写入,成为实时数据接入的关键制约。
2. 索引效率低下:当采用Bucket索引且分桶数量较多时,每次写入Log文件均需频繁执行耗时的List操作,严重影响写入性能。
3. 查询效率不足:底层使用的Avro行式存储格式无法有效下推查询,即使仅访问少数列也需读取整行数据,产生大量无效IO,导致查询效率低下。
4. 资源竞争与运维复杂:流式任务中写操作与Compaction共享资源,相互抢占常引发作业失败,往往需独立部署Compaction作业,增加了运维复杂性与成本。
5. 架构并发能力受限:缺乏并发更新能力,进行数据回溯或故障修复时必须暂停实时任务,影响业务连续性;同时受表级并发写入能力限制,同一张表的多个加工任务只能串行执行,导致数据产出延迟累积,难以满足高时效性要求。
为应对京东实时数据业务,特别是流量洪峰下的实时数仓、多流融合等场景对性能、稳定性与并发处理能力提出的更高要求,京东数据湖团队基于LSM-Tree思想对Hudi进行架构升级,旨在突破现有瓶颈,更高效地支撑日益增长的实时数据业务需求。
基本设计原则
LSM-Tree是一种通过顺序写入和分层合并来优化读写性能的存储结构。在Hudi底层改造中,以Bucket索引为基础,将每个FileGroup内的文件组织成一棵两层LSM-Tree。新写入的数据首先进入L0层,通过两类合并(Compaction)机制提升查询效率、减轻读时合并压力:
Minor Compaction:用于将L0层的小文件合并为更大的L0文件,高效控制小文件数量,执行频率高且速度快。
Major Compaction:周期性将所有文件合并至唯一的L1层文件中,从而在保持数据全局一致性的同时,降低合并操作的执行频率。
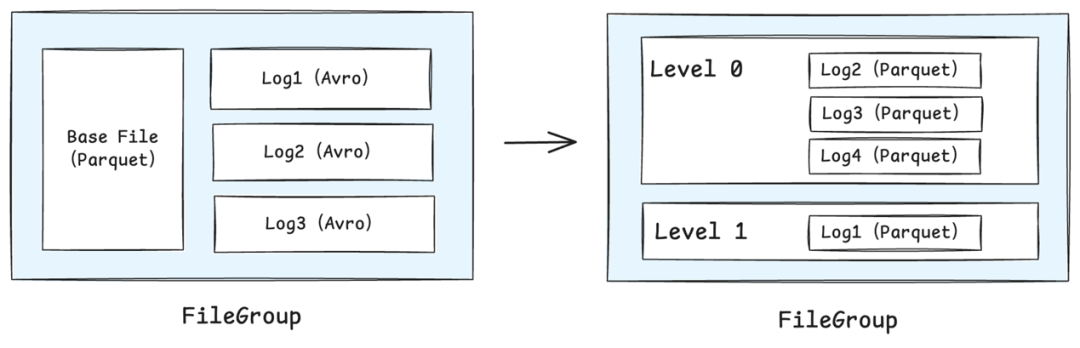
在数据流转过程中,JD-Hudi采用计算引擎原生的行格式(如Spark InternalRow、Flink RowData),避免此前由于Avro序列化和反序列化操作而带来的额外开销。此外,增量更新数据以创建(Create)新Parquet文件的方式,替代原先的Log文件追加(Append),从而避免数据写入前繁重的File List操作,同时支持多任务并发更新。
FileSystemView构建逻辑
FileSystemView(以下简称FSView)是Hudi的元数据抽象层,通过提供统一的查询接口,屏蔽底层文件组织细节,使引擎能够基于逻辑视图高效构建查询分片,为快照隔离和数据一致性提供关键支撑。改造后的FSView构建逻辑可以通过以下公式表示:
𝐹𝑆𝑉𝑖𝑒𝑤 at 𝑇=𝐶𝑜𝑚𝑚𝑖𝑡𝑒𝑑𝐿𝑜𝑔𝑠−(𝐿𝑜𝑔.
𝑏𝑎𝑠𝑒𝐼𝑛𝑠𝑡𝑎𝑛𝑡>𝑇)−(𝑅𝑒𝑝𝑙𝑎𝑐𝑒𝑑𝐿𝑜𝑔.𝑏𝑎𝑠𝑒𝐼𝑛𝑠𝑡𝑎𝑛𝑡≤𝑇 )
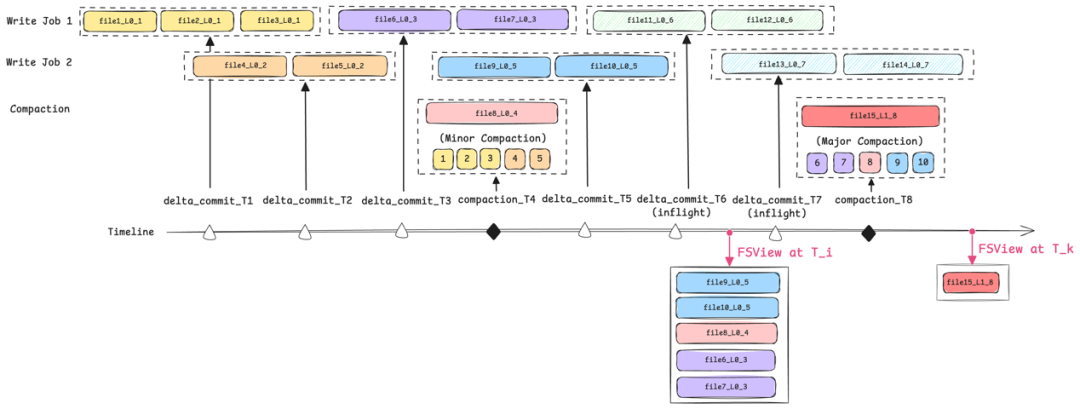
以图中所示的多任务并发更新场景为例,所有已提交的文件包括 File 1 ~ 10 以及 File 15。在 T_i 时刻,提交时间晚于该时刻的文件为 File 15,而提交时间早于或等于该时刻且因 Compaction 操作被替代的文件为 File 1 至 File 5。因此,可根据相关公式计算得出 T_i 时刻所对应的逻辑快照视图,该视图由文件 File 6 ~ 10 构成。
写流程设计
以Flink流式写入为例,写流程主要包含重分区、排序、去重、IO四个核心阶段。
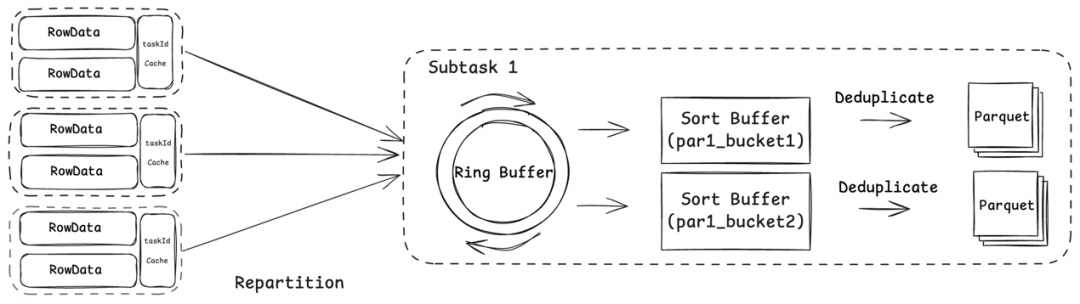
1. 统一数据表示:全流程数据流转均采用Flink原生RowData格式,减轻序列化及格式转换开销。
2. 均衡数据分布:针对Bucket分布不均问题,提出基于全局视角的Remote Partitioner机制,实现写入负载的动态均衡。
3. 异步处理架构:在Sink算子中引入Disruptor环形队列,解耦数据生产与消费,显著提升处理性能,有效应对生产速率高于消费的场景。
4. 高效内存管理:集成Flink内置MemorySegmentPool与BinaryInMemorySortBuffer,实现内存精细化管控与高效排序,大幅降低GC压力与排序开销。
读流程设计
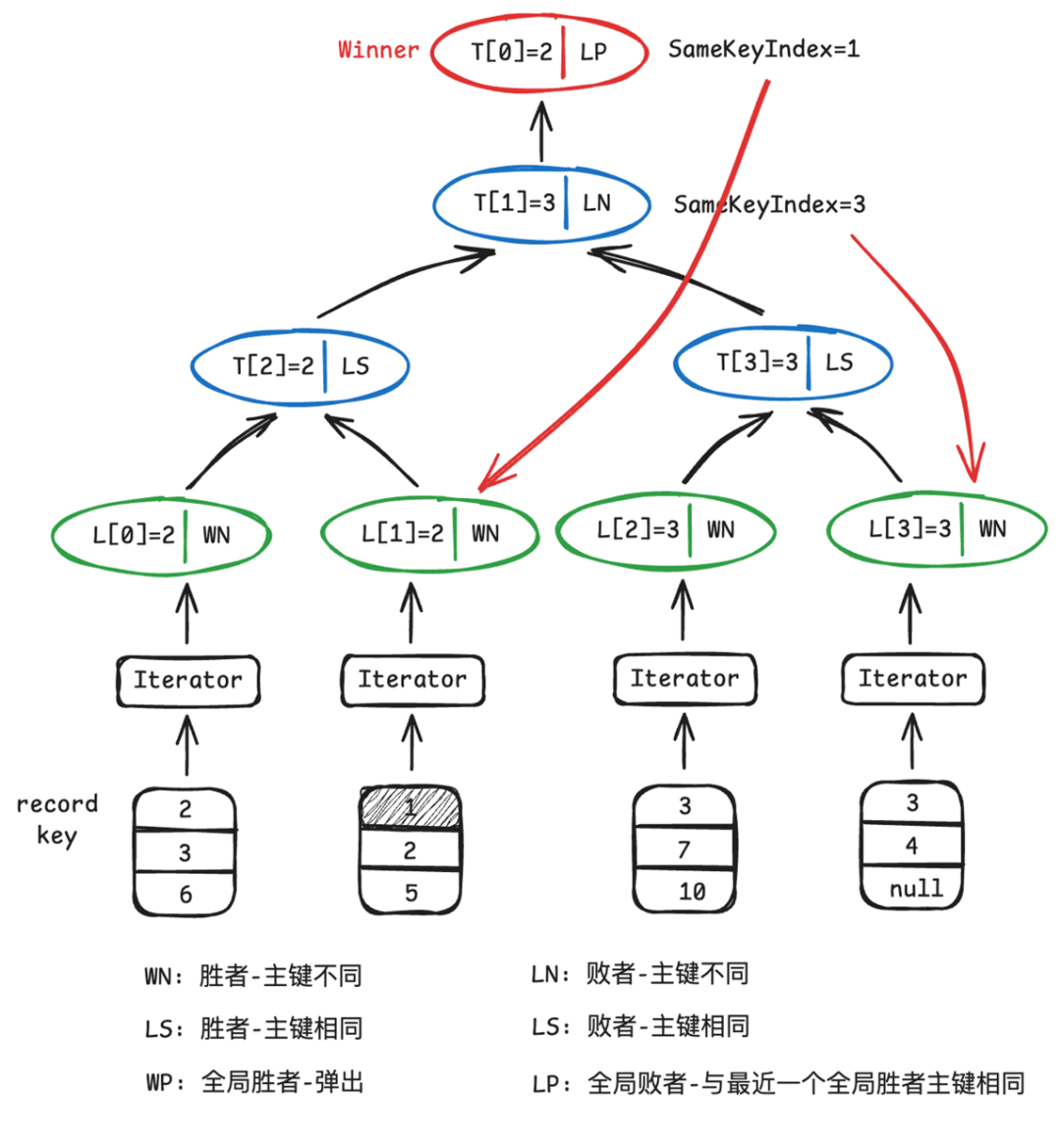
在LSM-Tree结构中,底层文件内部的数据记录都是有序的,因此高效的多路归并排序算法是提升查询性能的关键。最小堆和败者树是用于归并排序最为常用的数据结构。当合并路数(K)较大时,败者树每次调整仅需约log₂K次比较,而最小堆需要约2log₂K次,理论比较次数减少近一半,在数据流规模较大时优势明显。
为进一步提升合并效率,京东数据湖团队采用基于状态机的败者树实现。通过为每个节点定义明确状态(如“就绪”、“已选出”等),并在每次比较时驱动状态转换,同时动态记录相同主键对应的叶子节点索引,其好处是:
避免重复调整:当识别到相同主键时,可直接基于索引复用比较过的路径,无需重新遍历树结构。
批量合并输出:在一次调整中,可定位并输出当前树中所有相同主键的记录,支持合并函数一次性完成聚合。
消除深拷贝:通过索引直接引用数据位置,无需进行对象复制,大幅降低内存与CPU开销。
该方案在实际测试中带来约15%的读取性能提升,有效支撑LSM-Tree架构下高吞吐、低延迟的查询需求。
Compaction优化
Hudi Compaction 是面向 MoR 表设计的一项核心后台服务,其主要功能是将行式增量日志文件与列式基础文件进行合并,以生成新版、更高效的基础文件。在 Hudi-LSM Tree 的研发过程中,针对其排期阶段目前存在的性能及稳定性瓶颈,做出如下两项主要优化:
1. 增量排期
排期阶段主要工作是划定哪些分区的哪些File Slices将参与Compaction,然后生成一个计划(Compaction Plan)保存到Timeline。实际在这个过程中,仅需针对有新增数据的分区执行即可。然而,原有Compaction策略无论分区是否存在新数据,都会全盘扫描所有分区,导致不必要的资源消耗,且随着分区数量增加,还可能引发任务失败。为此,在LSM版本中引入了Incremental Compaction策略, 其核心工作流程如下:
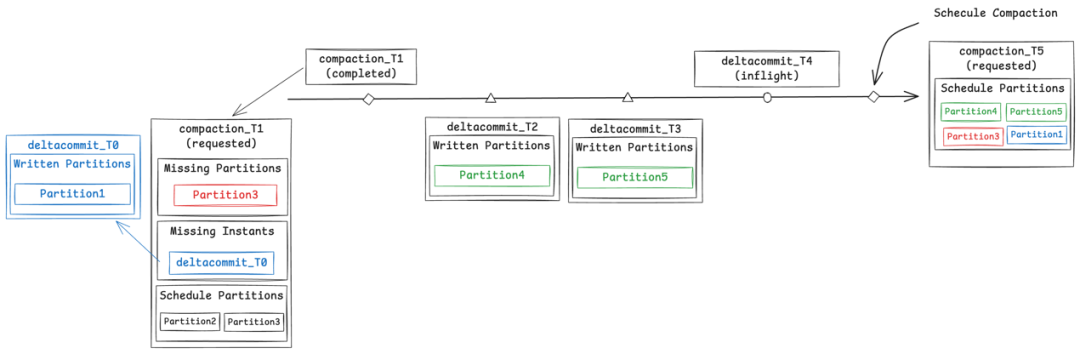
首先,将从上一次完成Compaction到当前时刻的这段时间视为一个增量窗口,在此期间通过deltacommit提交的分区,即为写入了增量数据的分区。如图中所示,若在T5时刻进行调度,则(T1, T5)即为增量窗口,其中在T2、T3时刻写入的Partition4与Partition5需纳入本次合并计划。
其次,需关注在上一次调度时因IO限制而未完全处理的分区,这些分区信息会被记录在Compaction plan的MissingPartitions中。如图所示,在T5时刻进行调度时,需考虑T1时刻plan中记录的Partition3。
此外,在并发场景下,还需考虑那些在调度时刻之前已生成但尚未完成提交的数据,相关信息保存在Compaction plan的MissingInstants中,也应在调度时予以纳入。例如,T1时刻plan中记录的T0时刻未提交的Partition1,以及在T5时刻调度时,将未完成提交的T4时刻记录至本次计划。
最终,在T5时刻调度中,所有需参与合并的分区包括:Partition1、Partition3、Partition4、Partition5。
2. Flink 流式排期
原有排期机制的执行时序设定于 Commit 操作完成后、新 Instant 生成前,且全流程均在 JobManager(JM)节点上执行。该模式存在两项突出弊端:其一,会阻塞新 Instant 的正常生成流程,进而导致数据消费链路中断;其二,若排期环节发生异常故障,将直接造成整个任务执行失败。
针对上述痛点问题,新采用的流式排期方案进行关键性优化调整:方案将排期核心逻辑单独抽离,封装为独立算子并部署至 TaskManager(TM)节点执行。通过架构层面的根本性优化,彻底攻克原有模式的两大核心痛点。如下图所示,为 Flink 流式排期的拓扑结构示意图。其中,获取排期分区、列出待合并文件、生成 compaction plan 等排期核心操作,均由独立算子负责执行完成。

Benchmark
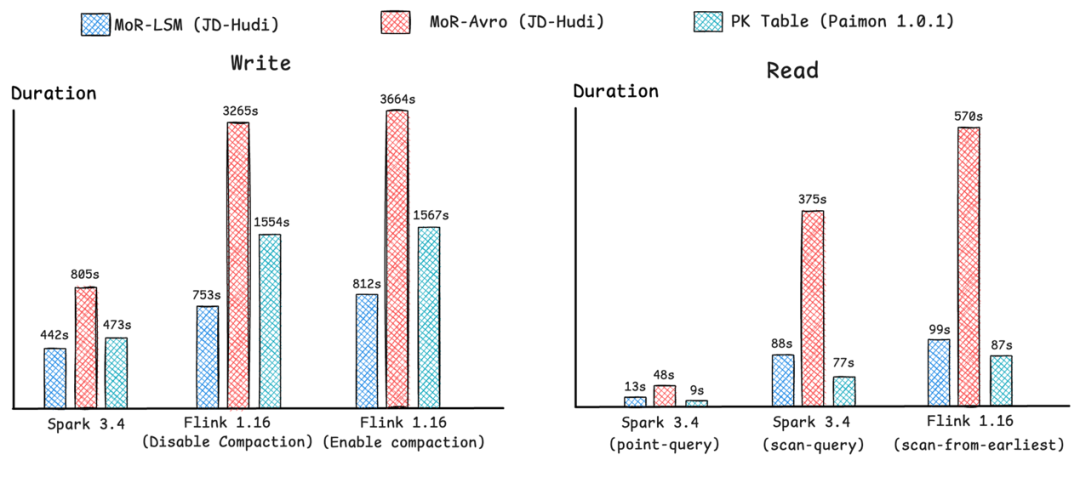
基于TPCDS与Nexmark标准数据集,在统一测试环境下对以下三种表格式进行benchmark评测:MoR-LSM(JD-Hudi优化版本)、MoR-Avro(JD-Hudi原生版本)与PK Table(Paimon 1.0.1),以任务执行时间或数据消费时间为评估指标,结果如下:
02. Partial Update Foreign-Key Join
业务背景
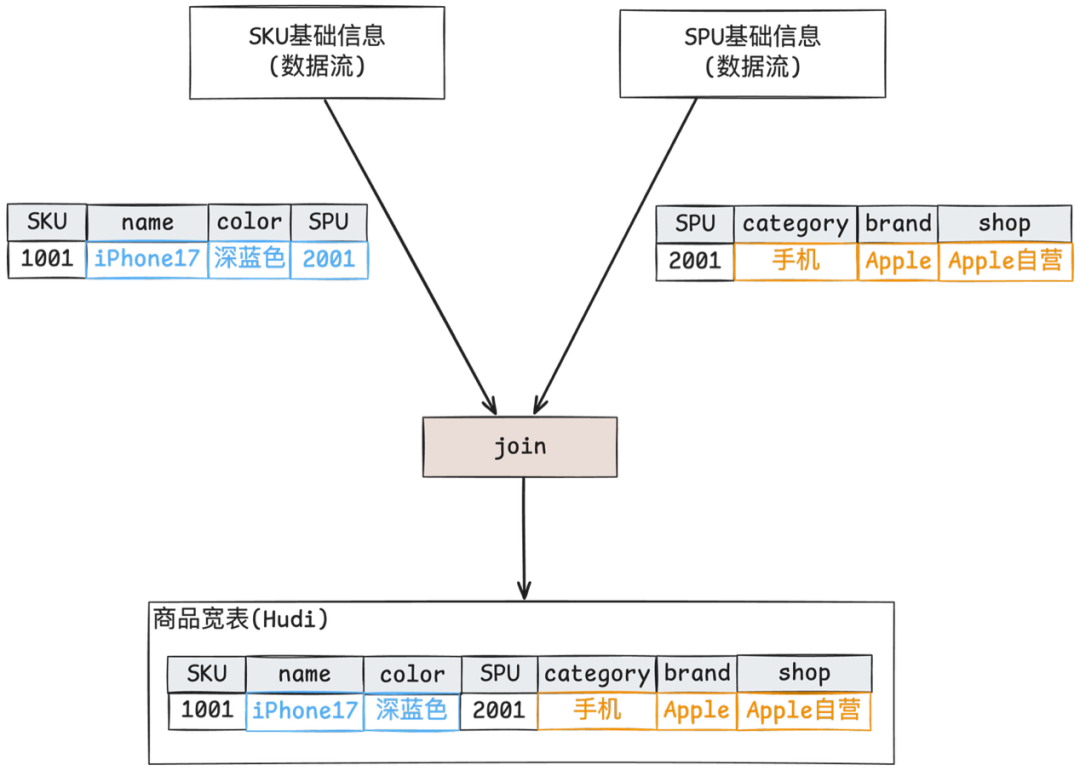
基于前期数据资产准实时化改造,上游链路商品基础明细目前已具备准实时时效。当前需持续推进下游链路中商品宽表的准实时化改造工作。商品宽表以SKU信息为核心基础,需通过流式处理方式扩展相关维度信息,涉及非主键关联更新的场景。
常规方案
实时:使用Flink流式Join,海量数据场景下状态存储巨大,维护成本高、运维复杂
离线:定期执行Spark Join,数据时效退化为调度周期+执行时间
上述两种方案难以在海量数据 Join 的场景下同时保障链路的稳定性与数据的时效性。为此,京东内部设计并引入外键索引方案。
外键索引方案
在 Hudi 中,Partial Update 在流式主键关联场景下,能够大状态下推至存储层,从而保障实时任务的稳定性。只要具备外键索引能力,即可通过外键值高效地查询对应的主键,从而满足业务需求。
京东内部设计一种外键索引:具备通过外键值快速定位主键值的能力,支持并发更新操作,具备高效的点查性能,并具有可扩展性与可插拔的索引存储机制。最终的整体链路流程如下:
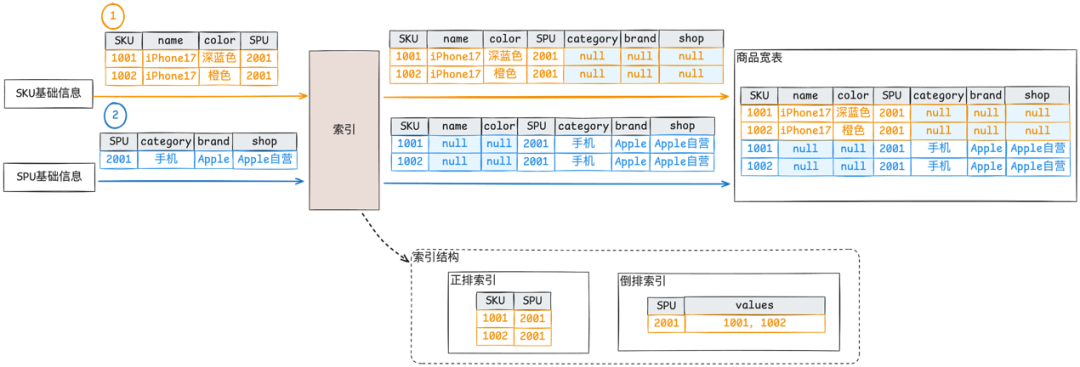
SKU 数据流实时更新维护外键索引,并 Partial Update 下发到 Hudi 商品宽表
SPU 数据流实时查询外键索引,获取所有相关主键,展开后 Partial Update 下发到 Hudi 商品宽表
最终满足业务分钟级时效
03. 数据湖 + AI 探索:Hudi NativeIO SDK
当前训练引擎的 IO 层尚未具备面向数据湖的原生适配能力(即“NativeIO”能力),致使在数据读取过程中出现 IO 放大现象,序列化与反序列化的开销较高,从而进一步限制训练效率的提升。
随着业务场景对模型实时性与精准性要求的不断提升,亟需打通样本训练引擎与数据湖之间的直接对接通道。通过构建适配 Hudi 的 NativeIO SDK,使训练引擎能够跳过中间同步环节,直接基于 Hudi 湖表进行样本读取,深度复用数据湖在增量更新、高效过滤等方面的能力。同时,通过 NativeIO 层面的优化手段,如列式存储适配、批量数据直读以及减少数据拷贝等,有效降低 IO 损耗,从根本上提升样本数据的时效性与获取效率,从而推动模型效果的持续优化。
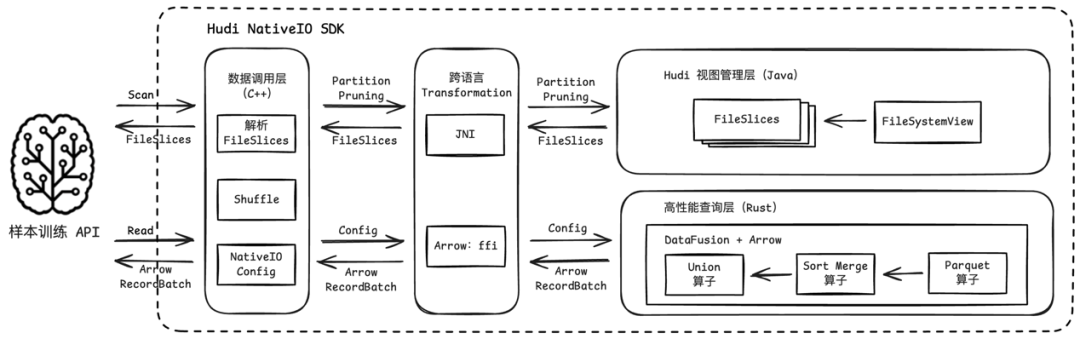
京东内部 Hudi NativeIO SDK 采用分层解耦的架构设计,整体划分为数据调用层、跨语言 Transformation 层、Hudi 视图管理层以及高性能查询层四大核心模块。各模块职责明确、边界清晰,自上而下协同运作,既确保用户操作的便捷性,又实现对湖表数据的高效读取与高时效响应,最终有效支撑样本训练引擎直接对接 Hudi 湖表,实现高效训练。
最终效果
基于 NativeIO SDK 读取 Parquet 文件,相较于 Spark 向量化读取 Parquet 文件,性能提升约 2 倍。
该性能优化有效解决 AI 场景下样本引擎在数据读取环节的关键瓶颈,从而显著提升了整体处理时效。
03 业务实践
流量数仓ADM数据湖升级
流量业务当前存在实时、离线两套开发链路,存在运维和开发成本高,口径不一致等问题; 离线链路各场域基于埋点数据自行加工存在口径不一致和数据存储冗余等问题;同时当前不具备满足准实时数据场景。流量业务存在如数据倾斜严重、数据规模超大、并发修数等挑战,基于数据湖Hudi建设统一流量公共层准实时链路,实时链路统一口径加工将实时数据入湖,提供准实时数据分析能力,在链路升级过程中做了大量的内核优化。
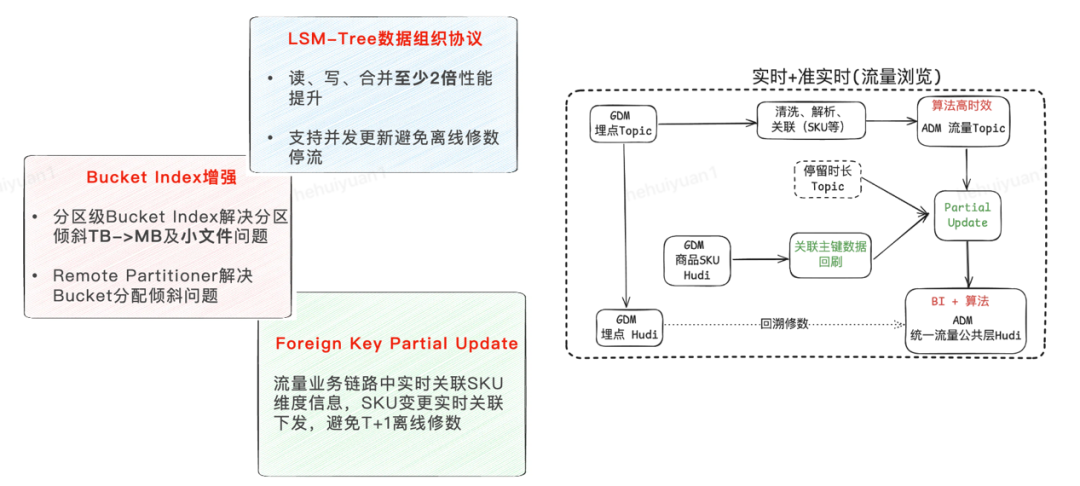
1. 基于Bucket Index的MoR表在流量数据生产链路存在将桶分配至写Write Task时不均匀导致部分Task负载高、部分Task空闲,并发资源利用低,影响流量作业的写入性能;同时流量业务分区数据倾斜TB->MB,Fix Bucket模式导致小数据量分区产生过多的小文件
解决方案:
自研基于TimelineService的Remote Partitioner功能,采用集中式分区+桶分配策略,解决桶分配倾斜
自研分区级分桶,按照业务分区数据特性自定义分区桶数,并实现原地桶扩缩容
2. 流量曝光业务日更新数据量级千亿级,MoR(Avro) Compaction性能、读时合并、更新性能无法满足,SLA压力大;社区原生MoR不支持并发更新,回溯修数场景需停生产无法满足流量业务准实时需求
解决方案:
自研LSM-Tree数据组织格式,基于LSM顺序读写及分层合并的核心优势,提升MoR读、写、合并性能;
基于LSM-Tree文件隔离机制,解决元数据冲突、 JM与TM通信冲突、以及Hive元数据同步的冲突,实现轻量级的无锁并发Upsert
3.流量业务链路中实时关联SKU维度信息,SKU实时变更,天级别分区内不同主键相同SKU的维度信息不一致,依赖T+1离线修数
解决方案:
自研Hudi外键索引 + Partial Update,实现SKU维度信息变更时的主键回刷,保持同一个分区内SKU信息数据的一致性
04 社区贡献及未来规划
社区贡献
目前京东Hudi团队累计向社区贡献109个PR,其中包含一些重要的工作,例如RFC-83 Incremental Table Service、RFC-89 Partition Level Bucket Index、HUDI-6212 Hudi Spark 3.0.x integration等,充分体现了团队在 Hudi 项目中的重要作用及持续贡献能力。目前团队包含一名Hudi PMC,一名Hudi Committer,Hudi前100名源码贡献者中团队占6人,发展成为Hudi社区的重要力量之一。
未来规划
基于社区最新版本,推进JD内部Hudi版本演进
数据湖支持多模态能力,支持非结构化数据存储以及向量索引等能力支撑 AI 场景
基于Rust+Arrow推进NativeIO能力
探索湖流一体技术方案

