AI Agent竞争下半场:决胜关键不在模型,而在系统架构
过去半年,“智能体(AI Agent)”这个词几乎成了大模型应用的代名词。
很多企业都在讨论:
“我们要不要做自己的智能体系统?”“LangChain、LangGraph、MCP 这些到底该怎么配合?”
我发现,大家最容易陷入的误区就是只盯着模型,而忽略了背后的系统架构。
事实上,一个能真正跑起来、能协作、能执行任务的智能体系统,绝不只是“接个大模型”这么简单。
今天,我们就借助这张完整的智能体架构图,一步步拆解出每个模块的作用、逻辑和落地方法。
如果你是开发者、AI 产品经理、或者在企业内推动智能体项目,这篇文章能让你彻底理清楚思路。
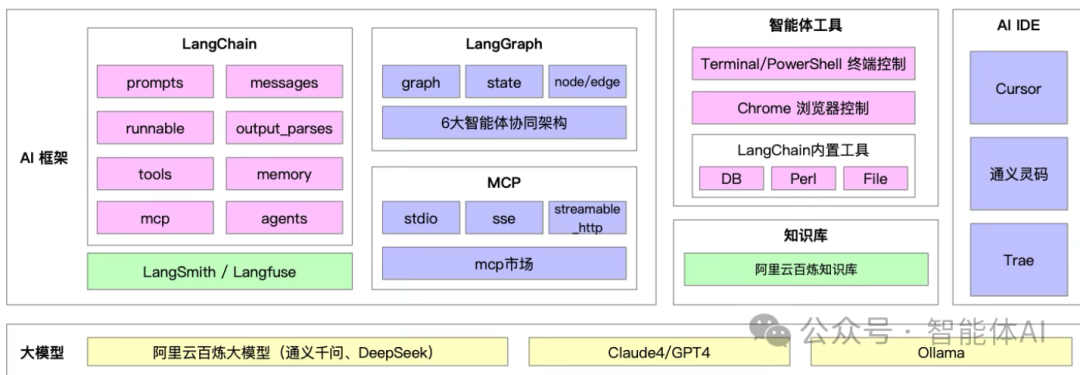
一、从全局看:智能体生态的三层逻辑
从整体上看,这张架构图分为三层:
1)大模型层 —— 提供智能的“底座”;
2)AI 框架层 —— 负责结构化管理智能体的逻辑;
3)工具与生态层 —— 让智能体能真正“动手”和“落地”。
这三层并不是孤立的,而是像一台机器的三个关键部件:
模型是发动机,框架是传动系统,工具与知识库是车轮与导航。
任何一环缺失,都跑不稳。
二、AI 框架层:智能体系统的“大脑中枢”
这一层包括三个核心框架:LangChain、LangGraph 和 MCP。
它们构成了智能体运行的基本逻辑,是整个系统最重要的部分。
1、LangChain:让智能体“会思考”
LangChain 是智能体的基石。它把大模型那种模糊的自然语言能力,转化为可控、可复用的工程结构。
LangChain 的几个关键模块如下:
1)prompts / messages: 用来定义提示词逻辑和上下文结构。 例如你要让模型“像一个税务专家回答问题”,那就得通过系统 prompt 明确语气、口径、引用方式等。 Messages 则负责把对话历史串联起来,让模型记住之前的内容,形成连贯的对话。
2)runnable: 把整个智能体的行为逻辑变成“可执行单元”。 这让你可以像编排代码一样,去控制模型执行的步骤,比如“先检索 → 再分析 → 最后总结”。
3)output_parsers: 很多模型输出结果不规范(比如漏引号、格式混乱),这个模块能自动解析和清洗输出,保证结构化一致。
4)tools / memory / agents: 三个模块是 LangChain 的核心。
tools 让智能体能调用外部工具,比如数据库、搜索引擎或浏览器;
memory 让它能记住历史状态;
agents 则负责决策——根据上下文选择使用哪个工具。
LangChain之所以重要,在于它把“智能体”从一个单纯的聊天机器人,变成了一个可编排、可控制的决策执行系统。
落地建议:
在企业项目中,LangChain 应当被当成“业务智能中间层”来设计——
所有 prompt 模板、工具定义、决策逻辑都要模块化、可版本化管理。
不要把提示词写在脚本里,这会让维护变成噩梦。
2、LangGraph:让智能体“能协作”
当你的系统里不止一个智能体时(例如有“数据获取 Agent”、“分析 Agent”、“汇报 Agent”),它们之间就需要协作机制。
这正是 LangGraph 的用武之地。
LangGraph 的核心概念包括:
1)graph(图结构):整个系统的任务流程。
2)node / edge(节点与边):每个节点代表一个智能体或工具调用,边代表它们之间的数据流向。
3)state(状态):用于记录当前任务进展和上下文信息。
LangGraph让开发者可以“画”出整个智能体网络的执行图,实现任务流转、状态监控、容错回退等高级功能。
它特别适合多步骤、长链路任务,比如自动报告生成、流程审批、或多角色协作。
落地建议:
LangGraph 最好的实践方式是“先定义流程,再接入模型”。
不要让模型逻辑主导整个流程,否则容易失控。
先设计好节点职责、输入输出,再用模型填补智能部分。
3、MCP:让智能体“能互通”
MCP,全称 Model Context Protocol,是智能体世界的“数据总线”。
它负责模型与外部环境之间的数据通信。
主要包括三种模式:
1)stdio:最传统的输入输出方式,适合命令行环境;
2)sse(Server-Sent Events)与 streamable_http:支持实时流式输出,比如网页端显示模型思考过程;
3)MCP 市场(Marketplace):未来可让开发者像安装插件一样接入新的工具或知识源。
它的价值在于统一通信标准。
以前每个 AI 工具、知识库、服务都要写一套独立接口,有了 MCP,这些模块都能通过同一协议连接。
落地建议:
企业在构建智能体平台时,一定要预留 MCP 接口层。
无论未来换模型、加新工具,系统都不需要重写主逻辑。
三、智能体工具层:让智能体“能动手”
这一层是真正让智能体“干活”的关键部分。
模型再聪明,如果不能操作系统、读写文件、调用数据库,就永远停留在“嘴上智能”。
这一层主要包括:
1)Terminal / PowerShell 终端控制: 让智能体能执行系统命令,比如运行脚本、拉取日志、部署代码。
2)Chrome 浏览器控制: 实现网页自动化操作,比如登录系统、爬取网页内容、填写表单。
3)LangChain 内置工具(DB、Perl、File): 支持数据库查询、文件读写、代码执行等场景。
有了这些工具,智能体就能从“回答问题”走向“执行任务”,例如:
自动生成报表;
查询库存;
下载发票并归档;
定期监控网站内容。
落地建议:
一开始一定要限制权限。
先让智能体只具备“只读”操作(例如查询数据库),待验证稳定后再放开写入权限,并做好日志追踪与审计。
四、知识库层:智能体的“长期记忆”
知识库是智能体的记忆系统,它决定了模型是否能“懂业务”。
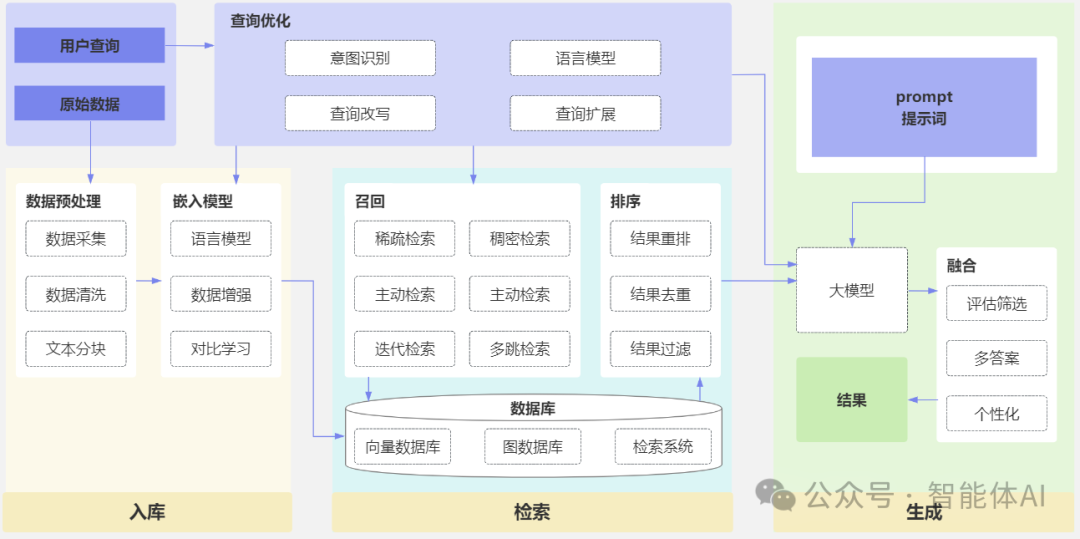
工作流程通常是这样的:
用户提问;
系统在知识库中检索相关文档片段;
拼接检索结果与问题一起发给模型;
模型根据上下文生成回答。
这就是所谓的 “RAG(Retrieval-Augmented Generation)” 技术。
落地建议:
知识库要做去噪与分片,避免长文输入造成冗余;
每条文档片段要有来源标注,让回答可追溯;
最好结合向量检索 + 精确匹配双模策略,提升命中率。
五、AI IDE 层:智能体开发的“调度台”
这一层的代表工具包括 Cursor、通义灵码、Trae。
它们为智能体开发者提供一个“可视化工作台”。
在这些 IDE 里,你可以:
调试 Prompt,快速验证输出效果;
追踪模型调用日志;
直观看到工具调用链路。
对于企业开发来说,一个成熟的 IDE 能把“调试周期”从几天缩短到几小时。
尤其在多 Agent 协作的复杂系统中,清晰的可视化界面能极大提升开发效率。
六、大模型层:智能的“底座”
最底层是智能体的“脑袋”,包括:
阿里云百炼大模型(通义千问、DeepSeek)
Claude4 / GPT4
Ollama(本地部署模型)
真正成熟的系统不会依赖单一模型,而是按任务动态选模型:
短问答用低延迟模型;
复杂推理用高精度模型;
安全场景用私有化本地模型(如 Ollama)。
落地建议:
设计一个“模型适配层”,统一管理模型调用逻辑和策略。
这样未来切换供应商(例如从 GPT 到 Claude)时,只需改一处代码。
七、落地路线:从最小智能体到企业级系统
最后,我们来看看这套架构如何一步步落地:
1)从最小可行智能体(MVA)开始——做一个能基于知识库回答问题的小助手。
2)用 LangChain 管理 prompt 与工具——把逻辑模块化,避免混乱。
3)加入 LangGraph 实现任务编排——把复杂流程拆成节点。
4)接入 MCP 协议——让模型、前端、知识库互通。
5)构建模型适配层——动态切换不同模型。
6)完善安全与审计机制——日志、权限、溯源,一个都不能少。
这就是从“架构图”到“可落地系统”的完整路径。
八、总结
智能体系统不是一蹴而就的产品,而是一种“逐步演进的工程”。
一开始你可以只做一个问答助手,但随着工具接入、状态管理、知识库丰富,它会慢慢成长为一个懂业务、会协作、能执行的智能体生态。
未来的竞争,不在于谁接了哪个大模型,而在于谁能把“智能”更好地嵌入业务流程中。
而这张架构图,正是那条通往可落地智能体系统的路线图。

