B站基于大模型的大数据智能诊断助手实践
01 背景介绍
1. 整体架构和规模

B 站是一个视频分享平台,拥有海量数据。大数据平台要支撑公司的众多业务,包括 AI、商业等重要应用。
大数据平台整体是一个“五层一体”+“存算分离”的架构,底层是分布式文件系统;中间有智能调度层,以及不同的计算引擎如 Spark、Flink 等,还包括各种客户端,以及实时数据流 Kafka、OLAP 引擎 ClickHouse 等,还有一些自建的工具和 CI/CD 平台。

平台任务量非常大,每天有 27 万个离线任务计算,2 万左右的 Ad-hoc 查询,7000 个左右重要的实时业务。团队的咨询量也非常大,每周有上千条咨询,每个小团队每周要处理 3 人天的咨询量,需要安排一个人专门处理业务上的咨询,回答用户关于任务失败、任务变慢等问题。
2. 用户的问题
关于离线计算,用户主要有两个问题,一个是为什么任务失败,另一个是为什么任务变慢。
(1)任务为什么会失败
系统内核的缺陷。有些时候系统内核升级了,但任务并没有做充分的测试,导致大规模的任务失败。
依赖组件的问题。平台数据量大,资源组件也很多,有很多任务彼此之间存在依赖,依赖的组件升级或者有 bug 就会导致任务的失败。
数据质量问题。本身有些数据有问题,也会造成任务失败。
当然,可能还会有其它一些原因造成任务失败,比如内存相关的问题等等。
(2)任务为什么会变慢
硬件老化引起。如果计存达到一定规模就会发现这个问题,我们的视频网站,硬盘的数量非常大,数据磁盘是有寿命的,过一段时间读写速度容易变得很慢。
资源调度问题。用户量非常大之后,资源调度压力会非常大的,加上公司的混合部署机制,资源会在不同的部门之间进行调转,在一些潮汐时可能有任务会受到影响。
数据分布问题。数据倾斜或数据本身存在问题也会造成任务变慢。
任务失败或变慢的原因非常繁杂,需要逐一排查,耗时耗力,因此我们需要探索利用智能手段来协助解决问题。
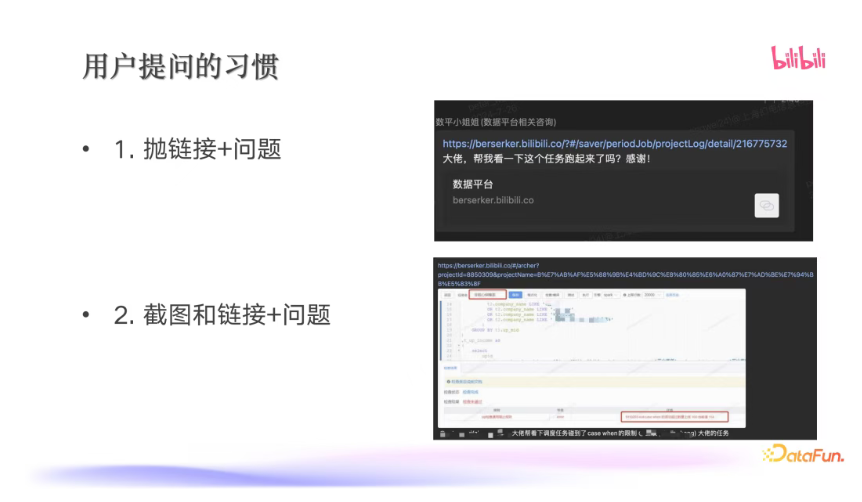
用户的提问通常是比较工程化的,没有很多描述,往往就是一个问题+一个链接,或者比较友好一点的会再加上一个截图。

