数据中心IDC基础设施运维巡检工作的6个重点
巡检是数据中心基础设施运维管理最基本的一项工作,在发现隐患和预防事故中发挥重大作用。
随着成本管控、人员缩编和智能技术的引入,巡检工作不能只是面面俱到的“走过场”,更需要专注于重点,实现最大的价值。
数据中心运行管理的主要内容
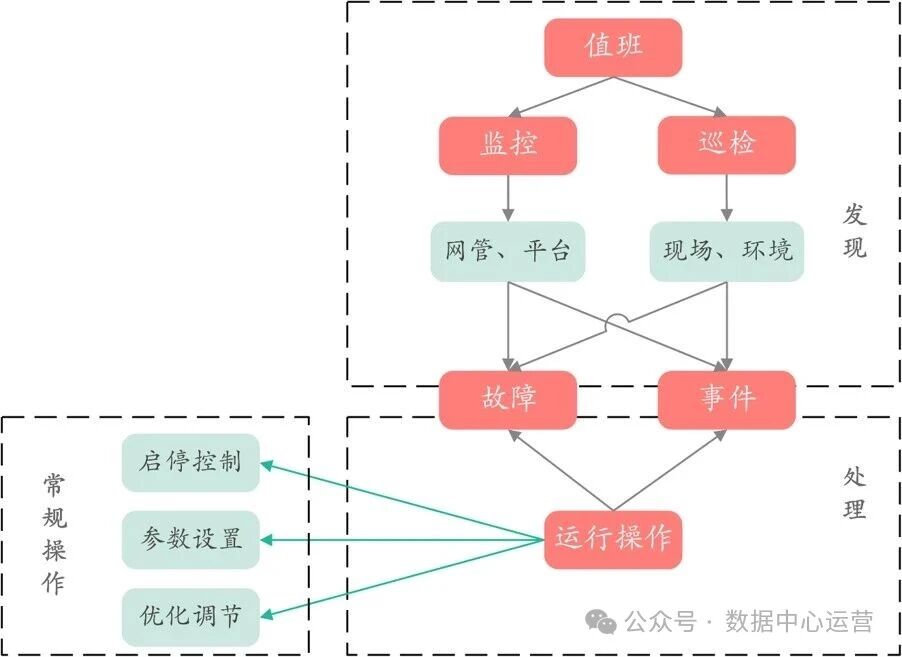
按照《数据中心基础设施运行维护标准》(GB/T 51314),数据中心运维工作分为运行和维护两个部分,运行又可分为值班、监控、日常巡检、运行操作、报警和事件处理等几个方面。
实际工作中,巡检通常归集到值班工作。值班人员通过网管监控、现场巡检和数据分析相结合的方式,及时发现隐患和事故。
各数据中心巡检机制虽然已经足够成熟,但仍存在系统巡检数据分析不足,现场巡检重点关注度不够等问题。这里先聊下现场巡检的几个重点。
重点1:运行数据的趋势
现阶段,部分数据中心依然按照传统方式执行人工“抄表”,查看运行数据是否正常。实际上,运行数据的变化趋势比单个时间点的绝对数据更能揭示系统的健康状态和潜在风险。
静态的达标只是“底线”,而动态的趋势才是“预警”。
巡检需要从“被动记录”向“主动预警”转变,通过运行数据变化趋势来识别潜在风险,而非仅仅满足于当前数值是否在阈值内。很多故障发生前,通常会存在一个缓慢劣化的过程,巡检正是捕捉这个过程的关键。
相比于网管巡查,现场巡检能更好地切身感受到温度变化、气流组织变化等状况。
1.温度变化:按照规范,机房温度可以在18-27度之间。如果连续两次巡检结果分别是23和26度,虽然数据正常,但仍需做出预警,判断单机柜散热、末端制冷是否出现问题。
如果同一台空调的回风温度在几周内从23℃缓慢升至25℃,再到27℃,有可能意味着过滤网正在逐渐堵塞,导致换热效率下降。需要及时清理避免因过热导致的设备故障或者效率下降。
2.内阻升高:同一组蓄电池,如果某节电池的内阻在几周内呈现持续升高的趋势,即使未超过告警阈值,也强烈预示着其性能可能正在劣化。
此类情况,巡检后现场人员要做重点标注给到后台网管,网管动态调整预警门限做重点观察。
重点2:运行环境的变化
即使A级数据中心依然会有很多区域无法实现传感器的无死角全覆盖,人为巡检可以理解为传感系统的补充和“最后一道防线”,能有效提升隐患的发现率。
巡检人员可以通过视觉(观察设备外观变化)、听觉(听到异常噪音)、嗅觉(闻到烧焦味或化学气味)、触觉(感觉设备过热)来感知细微变化。这些主观感知往往比传感器更敏感,能在隐患萌芽阶段介入,防止小问题演变为大事故。


1.气味异常:在机房或配电室内闻到异常气味,可能情形和处理方法:
1)刺鼻“金属/电火花”味:可能发生电弧、接触不良或者静电放电。需要通过测温枪、热成像仪等检查接线端子等重点部位。
2)“鱼腥/焦糊”味:可能发生电容/线缆绝缘过热、塑料件发热老化。需要通过测温枪、热成像仪等检查电子器件、电缆等重点部位。
3)“臭鸡蛋/硫化氢”味:可能发生蓄电池过充、溢出或者下水口返味。需要进行逐项的查看和验证。
4)柴油/燃油味:可能发生日用油箱、输油管路甚至柴油渗漏。需要重点检查油箱油位、输油管接头等。
2.声音异常:在机房内听到异常声音,比如配电柜、UPS、精密空调或发电机发出异常的嗡嗡声、爆裂声,以及明显高于平常的振动都属于异常现象,可能情形和处理方法:
1)对于电气设备,异常噪音可能意味着元器件、接头、紧固螺丝等松动问题。需要综合判断。
2)对于机械系统(空调、水泵),剧烈振动可能预示着轴承磨损、风扇叶片损伤甚至是共振等问题。可以重点查看轴承转速和温升情况。
3.视觉异常:在机房内看到异常情况,重点包括:
1)异常水情况:当保温管路、吊顶、地板出现异常水印,可能是冷凝水或者接口异常;管路附近出现不明积水,可能是由机房内供水管道损坏、空调排水泵故障或排水管故障;空调排水口附近出现异常,需要重点检查室外排水系统是否畅通,特别是汛期要重点做好梳理。
2)异常变化:电池鼓包/渗液、排气阀结晶等等,可能是电池失效征兆。需要查看内阻、电压与温度一致性。
4.触觉异常:虽然动环等系统可以初步判断温感分布和局部热点情况,但是巡检时,可以通过身体更好的感知到风速和风向的变化,做出更好的优化。
重点3:业务调整后的状态
业务上架和退网是数据中心最常见的变更操作,通常在操作后的24小时内,各专业要组织开展一次联合巡检,重点识别变更带来的新风险。不同于刚上架时的验证,持续的巡检对于确保业务稳定和性能调优至关重要。
1.业务新增:重点关注供电、制冷和网络的匹配能力。比如单PDU负载情况、电缆温升情况、机柜局部热点情况等,特别警惕制冷不足或者冷量分配不均带来的风险。在确保平稳运行后,开始转向系统调优。
2.业务退网:重点关注物理和逻辑资源的变更情况,资源是否释放、物理资源是否清理,DCIM系统账卡物是否相符等等,做好和业务部门的协同。
重点4:变更操作后的状态
系统升级、硬件更换、设备更新和参数优化等都是常见的变更操作。变更操作后巡检的核心目的,不是常规的预防性检查,而是对变更结果的验证和风险的再评估。巡检的重点不仅是要确认改造预期效果,更要确认是否引入新的不稳定因素。
1.性能指标:确认新系统或新硬件是否按设计目标正常运行,性能指标是否达标。
2.稳定性:改造后新版本、新系统、新硬件在运行初期的“磨合”状况,重点捕捉微小变化。
3.关联影响:也是最容易被忽略但风险很高的部分,包括兼容性、连通性。很多变更操作后,现场只是做了单机验证,并没有做上下游的联动检验,需要巡检重点关注。
重点5:隐患和盲区
数据中心巡检时,盯好隐患与盲区也是关乎业务连续性的核心。各专业要梳理好重大危险源和监控盲区的清单,按周期进行检查,这也是体现运维深度和专业性的关键。
1.重大危险源:数据中心的储油区、蓄电池区、气体灭火区、制冷剂存放区等都可以归集到重大危险源或者主要风险点,这些区域出现问题很容易引发重大事故,相比于常规区域需要更加细致的巡检。
2.监控盲区:电缆隧道内、架空地板下、入局光缆井等区域虽然可能有温感、水浸等传感器,但存在很大盲区。虽然不需要每天巡检,但需要制定计划,按照周期定期现场查看。
重点6:季节性重点
数据中心巡检的内容和重点并不是一成不变的,要结合季节特性动态调整。运维团队应基于历史数据,制定详细的全年巡检计划,将季节性防范措施融入日常工作中。

巡检中,春季要加强对空调、新风过滤网的检查,严防堵塞引发的效率下降;夏季要加强对制冷系统、水循环管路及湿度监控的巡检频次,严防过热宕机与凝露;秋季要加强对园区排水系统等巡检;冬季则重点关注户外管道防冻、静电预防及加热装置运行状态。
当然,运维团队一定是在季节变化之前制定并实施相关措施,巡检只是其中一部分。
写在最后
巡检是数据中心基础设施运行维护的一项重要工作,也是保障基础设施可靠性、效率、安全性和合规性的核心环节。
运维管理人员要不断地结合季节变换、业务调整、系统年限、技术更新等,动态优化巡检的细节,使其发挥最大的作用。

