爱奇艺会员业务预防系统腐化探索与实践
01# 背景介绍
1.1 系统迭代及运维的痛点
在保证系统高可用性的背景下,我们通常依赖监控和报警系统来实时监控现有应用系统和中间件。当应用系统运行出现异常情况时,监控系统能够在第一时间发现问题,并报警通知相关人员,以便快速响应。这种做法有助于控制问题的影响范围,减少故障带来的损失。然而,这种事后减少损失的方式并不是完全理想的策略。
为了进一步提升系统的高可用性,我们需要在问题发生之前就能识别和解决潜在的隐患,从而防患于未然。
1.2 如何解决痛点
通过自动化的方式,定期对系统进行各项巡检,提前发现可能存在的隐患以及系统腐化的问题。
定期检查:
在当今普遍采用敏捷开发原则的场景下,系统可能因各种原因而被开发人员修改。为确保系统的稳定性和安全性,巡检系统会根据预设时间表,定期对系统的部署环境、运行参数设置、网络环境等多个方面进行全面检查。通过这种定期、多方位的检查机制,可以及时发现潜在问题和安全隐患,确保系统处于更优状态。
定期优化:
随时间推移,系统规范可能会发生变化,而开发人员可能未能及时了解或实施这些新规范。为应对这种情况,巡检系统会在新的规范发布后,将这些规范配置在评价指标表中。通过定期提醒开发人员优化系统配置,确保所有关键参数设置(例如健康检测、限流参数、连接池配置等)符合最新标准,有效促进系统的持续优化。
生成报告和建议:
巡检系统会生成详细的检查报告,记录检查内容和发现的问题,并提供优化建议。这些报告可以作为系统维护和优化的重要参考,支持开发团队持续优化与改进相关系统。
1.3 巡检系统是什么
巡检系统是一个用于定期检查和维护应用系统、中间件以及其他系统组件的解决方案。它旨在通过系统性、全面性的检查,提前发现和解决潜在问题,进行预防性维护,从而保证系统的长期健康稳定运行。
1.4 巡检系统带来的收益
提前发现问题:
通过定期和全面的检查,巡检系统能够在问题尚未影响系统运行之前就发现隐患,并跟踪修复进度,从而防范于未然。
避免腐化:
系统腐化常常随着频繁的版本更新、团队成员更替和系统交接而发生。巡检系统可以在平时开发的过程中及时发现不当的系统配置和异常情况,从而避免系统的腐化。
标准统一:
巡检系统通过提供一套统一的技术标准,帮助各团队维持一致的技术方向,从而解决由于标准缺乏而导致的各团队技术方向分散问题。
全局视角:
通过体系化、系统化、综合分析的方法,解决单一视角无法全面掌握系统总体现状的问题。这样,可以从整体上洞悉各系统运行状况,识别潜在问题。
主动化运维:
相比于出现问题后进行被动运维,巡检系统帮助开发和运维团队提前发现系统的潜在风险,从而能够预先有针对性地改进和优化系统。这种主动式的运维方式显著提升了运维效率,并减少了重复错误的发生。
公共平台:
构建一个能够为其他团队赋能的公共平台。该平台旨在成为一个集成和协调的中心,以支持组织内各团队在更高层次上实现创新和发展。
提高系统稳定性:
定期的配置优化、安全检查和性能调优,可以提高系统在各种负载条件下的稳定性,减少崩溃和故障的发生频率。
增强系统安全性:
巡检系统能够及时发现从而修补安全漏洞,确保系统和数据的安全性,降低外部攻击的风险。
02# 技术设计与实现
2.1 整体架构
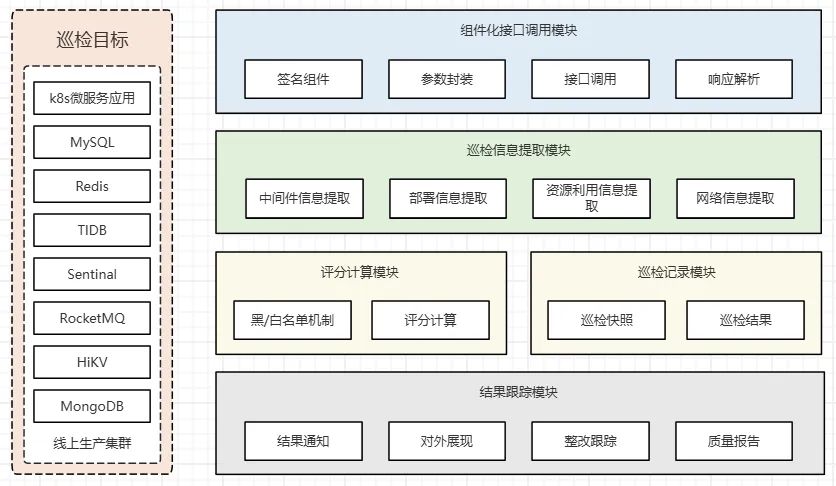
2.1 整体架构图

2.2 流程图
组件化接口调用模块
模块化接口调用的组件可以通过配置来实现接口的调用。由于巡检平台需要与不同的系统和组件运行平台对接,传统做法是每接入一个新系统或组件都开发专门的接口来获取信息,而通过配置化接口调用的方式,可以显著减少开发工作量。巡检系统普遍采用了这种配置化的实现方式,实际能够节约90%以上的时间。
巡检信息提取模块
巡检信息提取模块用于从接口调用模块获取的响应中提取系统与中间件的相关信息。具体来说,该模块通过配置化方式,从上一个模块提供的原始数据中提取评价指标关注的相关信息。与传统的逐个开发实体类来获取相关信息的方式相比,采用这种配置方式更具可扩展性,并能够兼容不同接口返回的数据结构。
评分计算模块
评分模块用于计算某个系统在各个评价标准上获得的评分。通过动态执行预设的评分脚本,模块可以生成各个评价指标对应的评分,从而实现灵活的指标评分方式。
• 自定义脚本配置:用户可以编写和配置自定义脚本,以便适应特定的评分需求。例如,在对某系统的线程池进行评分时,可以指定某个线程池不参与评分。
• 黑名单和白名单机制:模块支持在系统维度上通过黑名单和白名单来选择性跳过某些评价指标。白名单保证关键指标必被评估,而黑名单则允许忽略不相关或需暂时排除的指标。
巡检记录模块
巡检记录模块用于汇总各个系统在不同评价指标上的评分,得出该系统的总体评分以及对应的评分等级,并将这些数据持久化,从而有助于追踪系统评分的变化,支持主动化运维。
结果跟踪模块
结果跟踪模块负责生成各个系统的评分质量报告,并通过邮件将这些质量报告发送给各个系统的负责人,确保相关人员及时了解系统状态以便进行整改和跟踪,并且提供相关的数据接口供外部系统使用,从而支持其他团队进行更深入的分析和应用。
2.2 巡检指标
目前,巡检系统已接入近百个不同的巡检项。这些巡检项按照特定的类目分布如下:
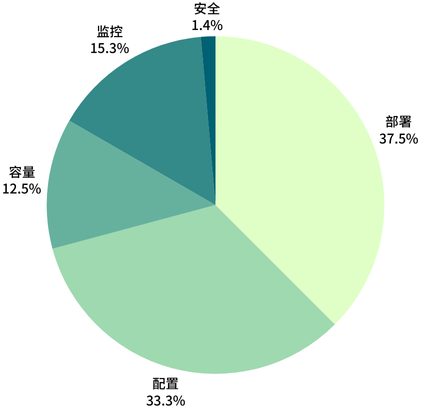
部署类指标: 包括异地多活、集群实例数,预发环境等相关配置。重点在于通过优化部署提升系统的高可用性。
配置类指标: 涵盖健康检测、启动预热、连接池配置、限流配置、组件版本等相关配置。重点在于确保系统与中间件的各项配置按照标准配置,提升系统健壮性。
容量类指标: 关注自动弹性、各硬件使用率等相关容量限制,重点在于检查资源使用和容量管理,避免由容量不足而产生的故障风险。
监控类指标: 用于检查监控相关的配置是否符合规范,确保有及时的监控机制和足够的人员接收告警,防止忽略重要问题。
安全类指标: 专注于内外网访问以及账号授权,避免安全相关问题的发生。
03# 未来规划
会员内部系统已全面接入巡检系统,有效防止系统腐化。巡检系统的未来发展将融入AIOps(人工智能运维),通过智能化技术全面提升运维效率和系统质量:
细化巡检结果:对巡检发现的问题进行深入分析并反馈分析结果,旨在发现更多相关隐患。
提供修改建议:依据相关配置标准,提供符合要求的配置建议,从而简化优化过程。
自动化配置:实现对巡检发现隐患进行自动修复,提高运维效率。
智能化配置: 当前巡检系统依赖人工配置相关指标,未来将通过智能化技术降低人工配置依赖,提升巡检系统的便捷性以及系统能力。

