爱奇艺金融数据入湖实践
01#
背景与挑战
在金融业务快速发展的过程中,用户运营、风控分发、产品设计等各个方面对数据的依赖程度与日俱增。为满足实时分析、量化运营、风控建模、机器学习等场景需求,我们需要构建一套大容量、低延迟、维护便捷的数据存储分析体系。
原有方案的局限性
在历史方案中,存在两套数据同步链路:
通过DBIO将多个数据库的数据实时同步至采用TokuDB引擎的MySQL集群,依靠TokuDB引擎较为出色的数据压缩比例, 承担了业务数据的归档和历史数据的查询分析。
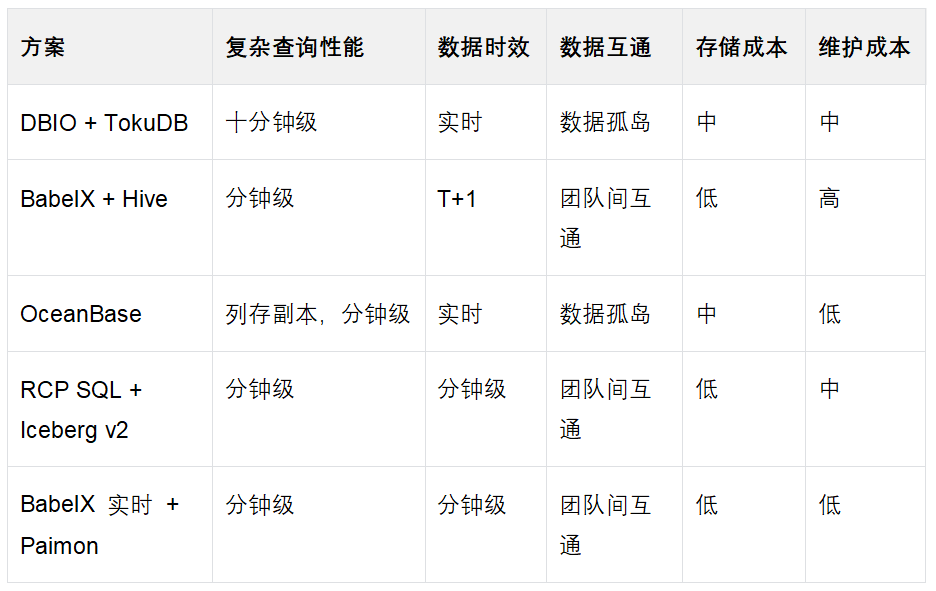
性能瓶颈:复杂查询耗时长达几十分钟,线上场景无法使用。对于即席查询,等待过程也形成了很多碎片化的时间,难以有效利用。
数据壁垒:跨团队取数困难,外部数据大多在数据湖存储, 关联使用时需要额外同步数据到数据湖中。向其他团队共享数据时,也无法有效的对表和指定字段做权限隔离。
成本高企:存储成本达数千元/T/月,且随着数据量增长线性上升。
通过BabelX将T-1日数据同步至数据湖中,用于需要与外部数据关联使用的场景。
数据延迟:数据采用T+1批处理模式,无法满足风控等要求数据时效的场景。
数据变更不友好:对于记录会跨天发生状态变更的场景,T+1的同步逻辑存在劣势,数据的一致性和完整性难以得到保证。
补数困难:按日分区的数据,新建好表后,追溯数据需要大批量的重跑历史任务。 如果发现历史记录有错误需要修正时,也需要记得重跑历史同步任务。
而且因为同时维护了两条链路,额外增加了维护成本,在发生表结构变更时,需要额外的人力支持。如果忘记同步变更,就会发生数据损失。
随着数据规模持续膨胀、使用场景的多元化、 变更维护成本高昂,这些问题直接制约了金融业务的敏捷迭代与数据价值挖掘,推动了我们尽快对数据架构进行升级。
02#
方案选型
初试方案:RCP SQL + Iceberg v2
2024年初,我们在结算业务中尝试在 RCP 平台 (Realtime Compute Platform是爱奇艺内部的统一实时计算平台,提供了实时大数据摄取、计算和分发能力)通过Flink SQL + Iceberg v2 方案进行数据入湖。该方案主要用来解决结算离线数仓面临的订单表状态变更处理难题——交易订单记录会随用户行为动态变化,传统T+1批处理的两类同步方案都存在着局限:
全量快照同步:以每日为单位同步上游全量数据快照,虽能保证数据完整性,但同步耗时久, 数据量大,并且需要特殊处理上游已经归档的数据。
终态数据同步:仅根据订单完成时间或退款时间同步当日数据,虽能控制数据量、避免重复,但无法获取中间态的订单数据,影响转化分析。如果产生历史数据的修改,也需要进行数据重跑。
Iceberg V2的行级数据变更特性有效解决了上述问题,通过引入delete file记录需要删除的行数据,在不重写原有文件的前提下,实现了行数据的更新与删除。在实际使用体验上,我们已经可以将数据湖中的数据视为业务的从库来使用了。在一年多的时间内稳定运行,未出现任何报错与数据差异情况。
然而,在金融业务场景下, 依然有一些需要解决的问题:
Schema变更繁琐:金融业务的开发流程很敏捷,后端人力紧张,面对较为频繁的表结构变更,维护成本没有减少。开发人员需手动同步修改 Iceberg 表结构与同步任务,一旦操作疏漏或延迟,就会导致数据缺失。
资源利用率低:由于每张表需独立创建任务且分配固定的CPU 资源,CPU 实际利用率仅为 2%左右,不符合我们的降本目标。
调研方案:OceanBase HTAP 是否是银弹?
2024 年Q3,部门内针对分布式数据库在交易类业务中的应用展开调研。凭借横向扩展能力、高效读写性能、经济的存储方案以及 HTAP(混合事务和分析处理) 概念,对解决分库分表、数据容量与提升AP性能等问题极具吸引力,能够大幅减轻运维负担。
但深度评估后发现对于当前的金融业务需求,仍有一些需要解决的问题:
数据孤岛:尽管通过 StarRocks 的 JDBC Catalog 可实现实时查询场景下的数据互通,但在量化运营、风控指标计算等流 / 批处理场景中,尚未找到高效可行的解决方案。
存储成本:LSMTree提供了较高的数据压缩比例, 冷数据归档方案接近公有云商用,但整体集群部署方案核算下来相比业务在线库+数据湖方案高。
在后续计划中,我们会在在线交易中试用OB,探索成本优化空间。
最终选型:BabelX 实时版 + Paimon
2024 年 10 月,我们收到了BabelX 实时版(基于Flink CDC 开发的实时数据同步工具, 提供yaml和图形化的DAG配置)的调研问卷,经过进一步的沟通了解,我们基于 BabelX 实时版展开方案试用。在大数据团队的帮助下,解决了 Paimon 表小文件过多、pt-osc 类 DDL 工单 Schema Evolution 支持等问题。目前我们通过6个任务,完成了20+业务表的同步任务配置,相关任务已稳定运行超半年。
该方案通过简化同步任务字段映射、正则表达式减化分库分表同步、自动化的目标表创建与 Schema Evolution,搭配可视化的监控界面,极大降低了业务数据入湖的人力投入与操作复杂度。
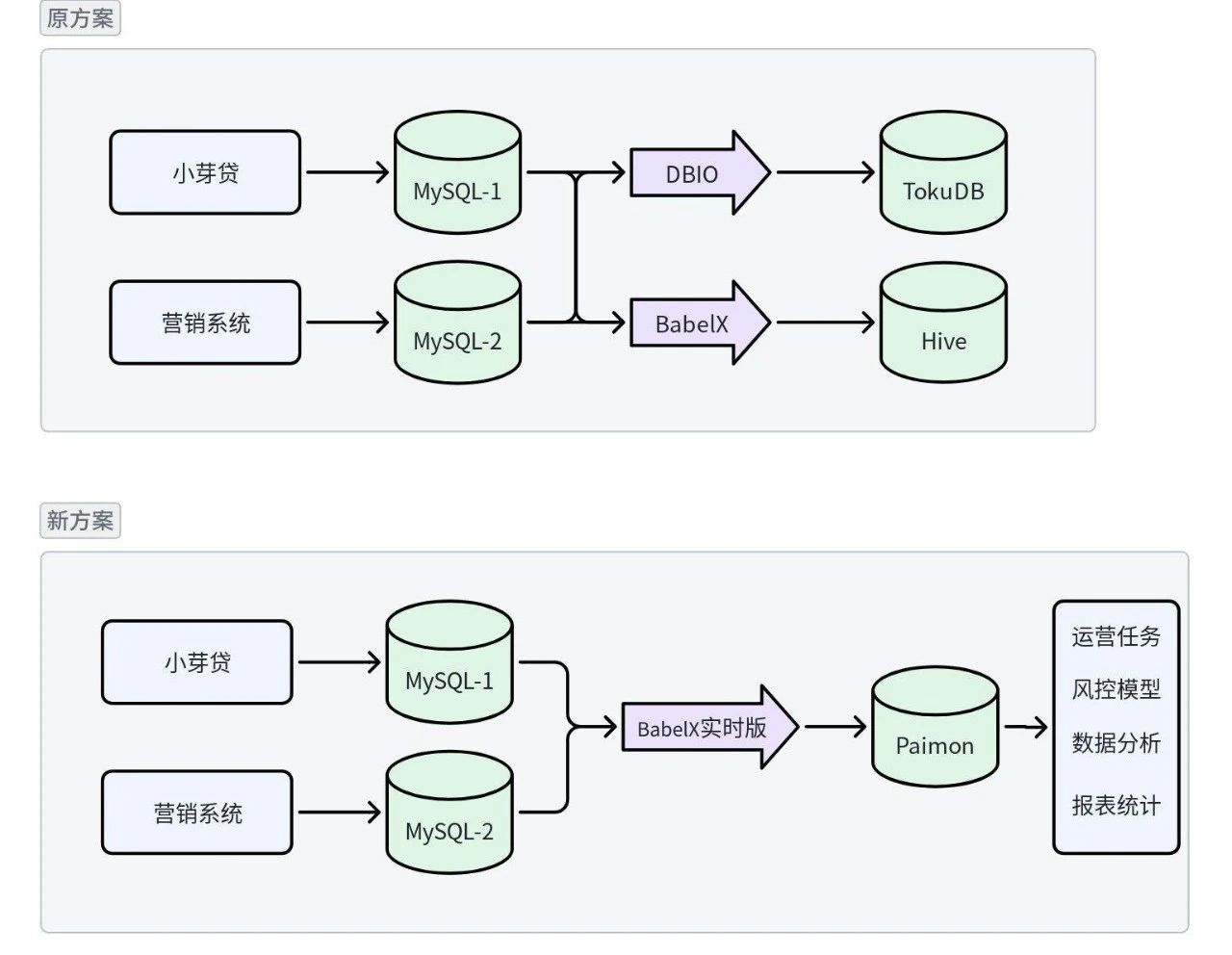
图1: 方案变更后,整体链路简化
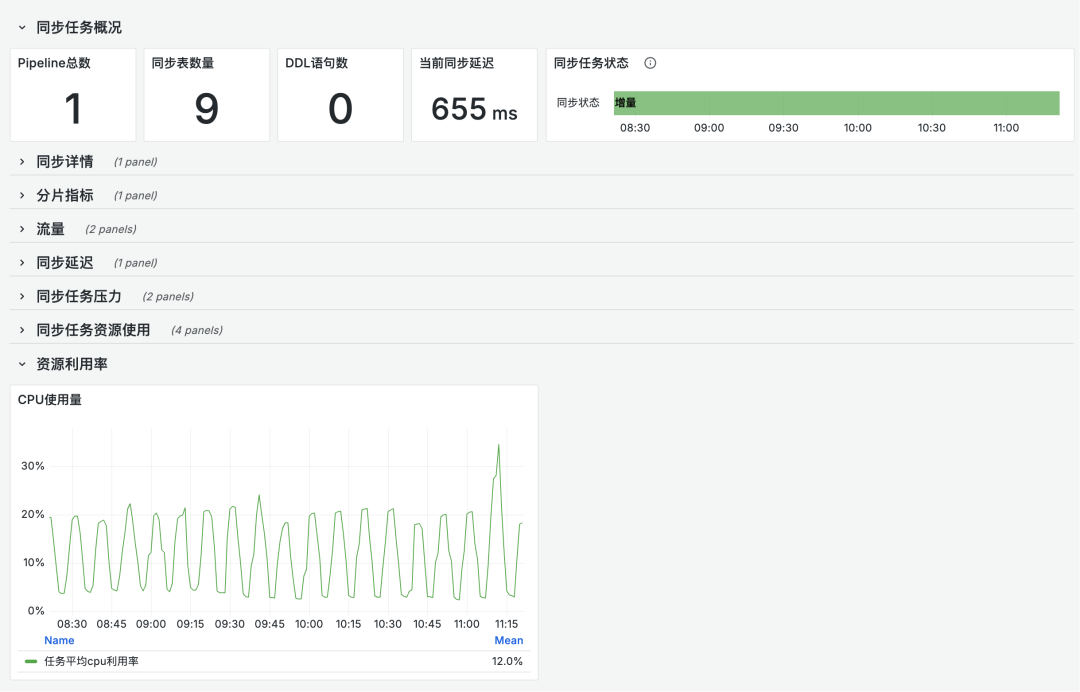
图2:单任务同步多张表时的CPU利用率依然保持较低水位
方案对比
结合业务核心痛点,我们在查询性能、数据时效、数据互通、存储成本、维护成本五个关键维度,对上述技术方案进行了对比分析,可以发现最终选型方案更加符合业务需要。
03#
价值实现
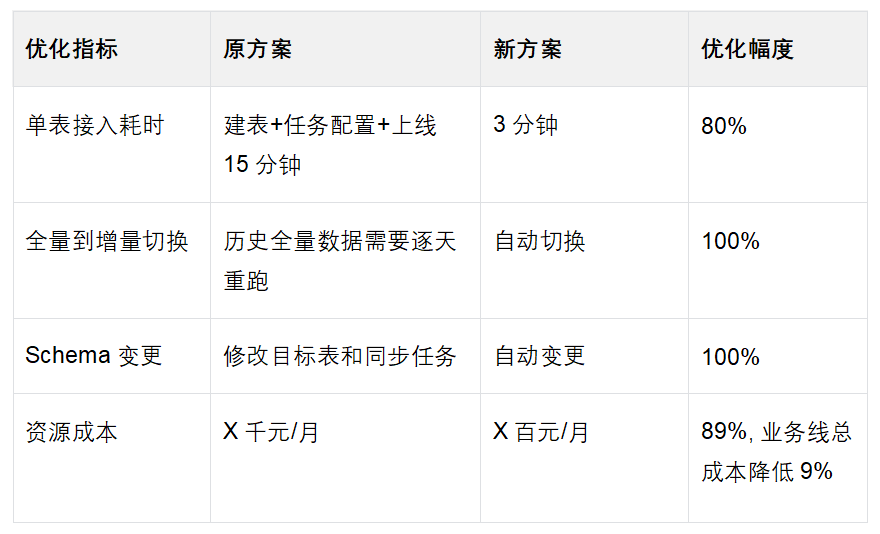
降本增效:
性能指标提升:
数据延迟:从T+1优化至分钟级,满足实时风控需求
查询性能:复杂分析查询耗时从几十分钟降至1-3分钟,提升10-30倍
并发支持:同时支持10+并行查询,无性能衰减
数据治理成果:
打破孤岛: 成功整合Pingback 、风控、用户增长等数据源,实现数据互通。
归档优化: 利用数据湖低成本存储特性,有效解决冷数据归档与查询问题。存储成本降低。
数据质量提升:通过自动化Schema管理,数据一致性问题减少90%。
业务赋能:
金融风控: 实时获取数据用于风控指标计算、联合运营、 反诈拦截、机器学习,提升风控时效性,有效降低中介、诈骗等客诉, 提升贷后数据表现。
量化运营: 通过关联用户多场景数据(活跃度、意愿度、相关度),实现高意愿用户自动化营销,带动业务增长。
04#
后续计划
加工用户实时标签,优化金融营销系统的标签体系
完善业务监控,结合前后端数据,构建全链路监控
统计报表迁移,提升报表数据的产出耗时
结合chatBI构建自助式数据服务平台,降低业务侧使用门槛
05#
使用参考
在这里也提供一些对于BabelX实时版的使用参考,更多资料可以查询FlinkCDC官方文档。
引擎配置:
大表出现报错Exceeded checkpoint tolerable failure threshold. 时可以适当增加checkpoint的超时时间:execution.checkpointing.timeout=30min。
CheckPoint间隔:如果能够接受分钟级延迟,可以适当调增,降低小文件数量
计算资源:全量同步阶段可以适当增加资源,切换到增量同步后,可以观察监控中的cpu利用率,降配。合理使用多表同步的能力,降低配置成本,提升资源利用率。
队列:对BabelX实时版和RCP任务分配专用的流任务队列,做好资源隔离。
MySQLSource配置:
任务中途添加新的同步表:scan.newly-added-table.enabled=true。
按日期动态分表的正则场景,希望对新增表自动开启同步:scan.binlog.newly-added-table.enabled=true, 注意这个参数和上面的参数冲突,只能选择一个。
对pt-osc类无锁DDL工单的Schema Evolution支持:scan.parse.online.schema.changes.enabled=true, 注意目前这仍然是一项实验功能,配置开启后请勿再进行额外的字段映射。
忽略上游的指定操作:debezium.skipped.operations=[c,u,d,t],比如作为归档库我希望忽略定期的清理数据,可以配置为debezium.skipped.operations=d,t , 忽略delete和truncate操作。
Paimon Sink配置:
commit.user:在需要清空状态重启任务时,建议修改commit.user为新值,确保数据能够提交到Paimon。
table.properties.bucket:根据表存储大小、分区数合理评估bucket数量,bucket数过多会导致小文件。
表:任务支持自动根据上游schema自动建表,没有特殊情况时,可以不用提前建立Paimon表,在pipeline做好表名映射即可。

