凌晨突发的数据库重大故障,我排查了一整天
春节期间过得太热闹了,上班确实没啥状态,这不刚发生的一个重大性能故障,排查了整整一天,后面的领导都站成了一排,本次把故障发生的详细分析过程分享给大家!
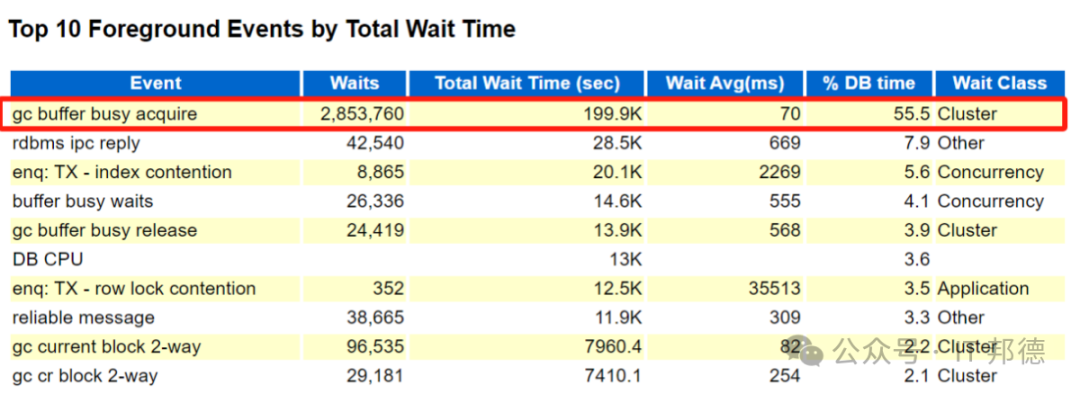
本次故障发生在凌晨,核心应用卡顿非常严重,Oracle数据库直接夯住了,出现异常等待事件gc buffer busy acquire,以及部分索引和行锁争用。
一、首次定位
首先通过alert日志排查发现了index unusable,怀疑触发bug导致,见Doc ID 849070.1,数据库分区索引出现了大面积失效,首先停机进行索引重建的工作。
--不管是全局索引和本地索引,只要出现了数据移动,那么索引或分区索引都会失效:1)对分区表的某个含有数据的分区执行了 TRUNCATE、DROP 操作可以导致该分区表的全局索引失效,而分区索引依然有效,如果操作的分区没有数据,那么不会影响索引的状态。需要注意的是,对分区表的 ADD 操作对分区索引和全局索引没有影响。
2)执行 EXCHANGE 操作后,全局索引和分区索引都无条件地会被置为 UNUSABLE(无论分区是否含有数据)。但是,若包含 INCLUDING INDEXES 子句(缺省情况下为 EXCLUDING INDEXES),则全局索引会失效,而分区索引依然有效。
3)如果执行 SPLIT 的目标分区含有数据,那么在执行 SPLIT 操作后,全局索引和分区索引都会被被置为 UNUSABLE。如果执行 SPLIT 的目标分区没有数据,那么不会影响索引的状态。
4)对分区表执行 MOVE 操作后,全局索引和分区索引都会被置于无效状态。
5)手动置其无效:ALTER INDEX IND_OBJECT_ID UNUSABLE;。对于分区表而言,除了 ADD 操作之外,TRUNCATE、DROP、EXCHANGE 和 SPLIT 操作均会导致全局索引失效,但是可以加上 UPDATE GLOBAL INDEXES 子句让全局索引不失效。
二、二次定位
处理完索引失效的问题后,发现异常等待事件gc buffer busy acquire依然存在,索引和行锁消失了,接着分析ADDM报告,发现阻塞的SQL占用大量IO,数据库执行计划多变,进行执行计划绑定,收集统计信息。

同时发现有大量并行,然后对取消了并行度。
三、最终定位
异常等待事件gc buffer busy acquire依然存在,开始全方位定位分析,异常全部集中在网络。
AWR报告进一步分析,发现实例2心跳网络延迟很高
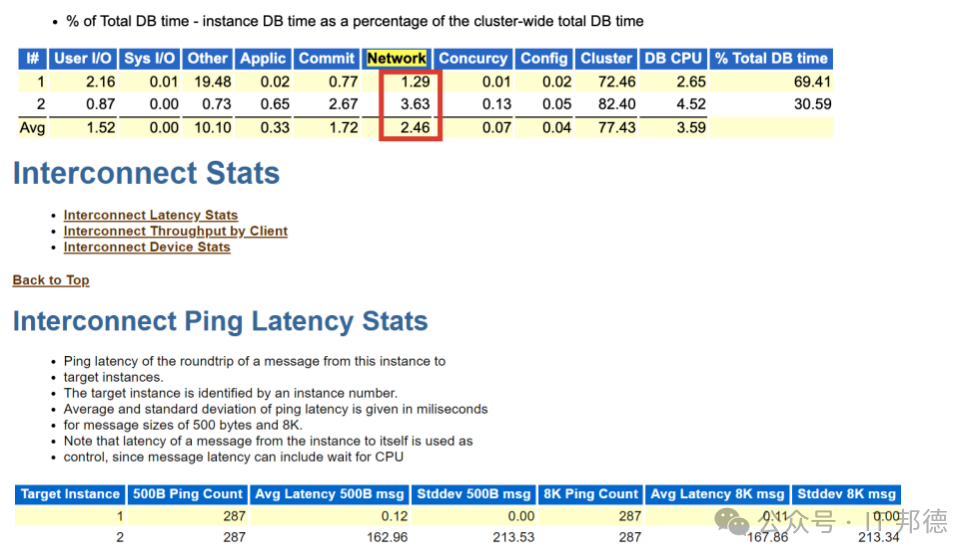
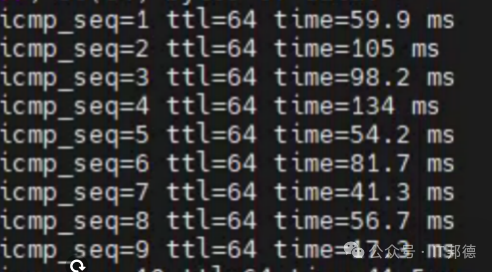
硬件介入排查系统日志发现新跳网卡持续出现duwn,up状态,而此时心跳网络ping发现节点间心跳网络有问题,延迟最高达到358ms!
四、反思
本次故障为硬件导致的数据库性能事故,数据库服务器双节点之间心跳网线连接接触不良导致gc buffer busy acquire异常等待,最终导致数据库夯住。故障排查处理方式过于局限,在这里我将gc buffer busy acquire异常等待事件的所有可能原因总结如下:

五、整改措施
本次心跳线为直连,容易出现接触不良的情况,改造方式为单网线实现网卡网卡聚合、心跳线直连替换位过交换机。
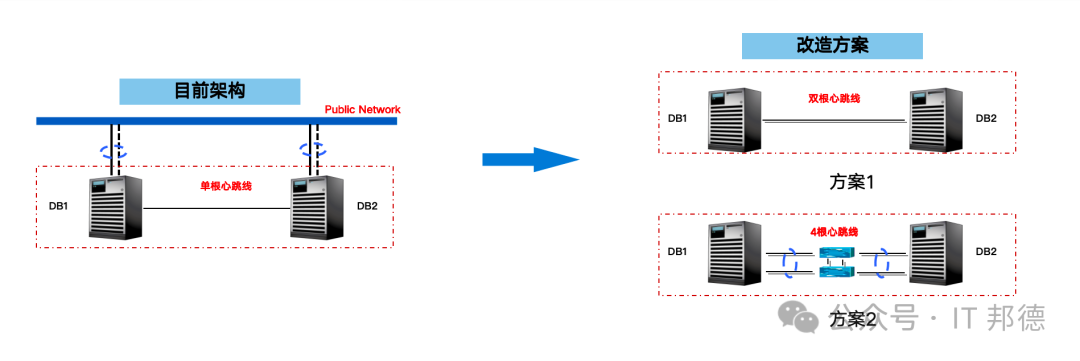
心跳先直连的风险如下:
网线接触不良时导致集群不稳定,节点被驱逐
将集群节点总数限制为2,无法实现扩展
网线再次松动,会导致GC等待
总结
报告分析采集的越全面,故障才能更快的定位,稳住,拿捏它!

