前端怎么做好稳定性保障体系建设?
前言背景:实话实说才能做的更好
1.业务间的监控策略层次不齐:前后端针对监控专项的标准规范缺失,导致有的业务监控完善,其他业务缺复用不了
2.集团前端监控平台能力不完善,导致告警噪音大,一线研发无法通过自行思考抽丝剥茧,做有效合理监控,久而久之,监控告警熟视无睹
3.平台大盘能力、日志能力和告警能力均欠佳,与业界差距较大,无法对已有的监控策略形成体系的工具价值
4.前端监控无法形成独立的技术价值,无体系的建设,容易让前端监控变为后端监控的重复建设。挖掘前端监控的价值点,比如用户体验、设备兼容性以及缺失等等,都应该成为前端监控独有的价值点
一、前端监控的业务价值定位
1.1 链路定位
下图的1、2、3、4、5都是会导致前端故障的通用核心链路监测
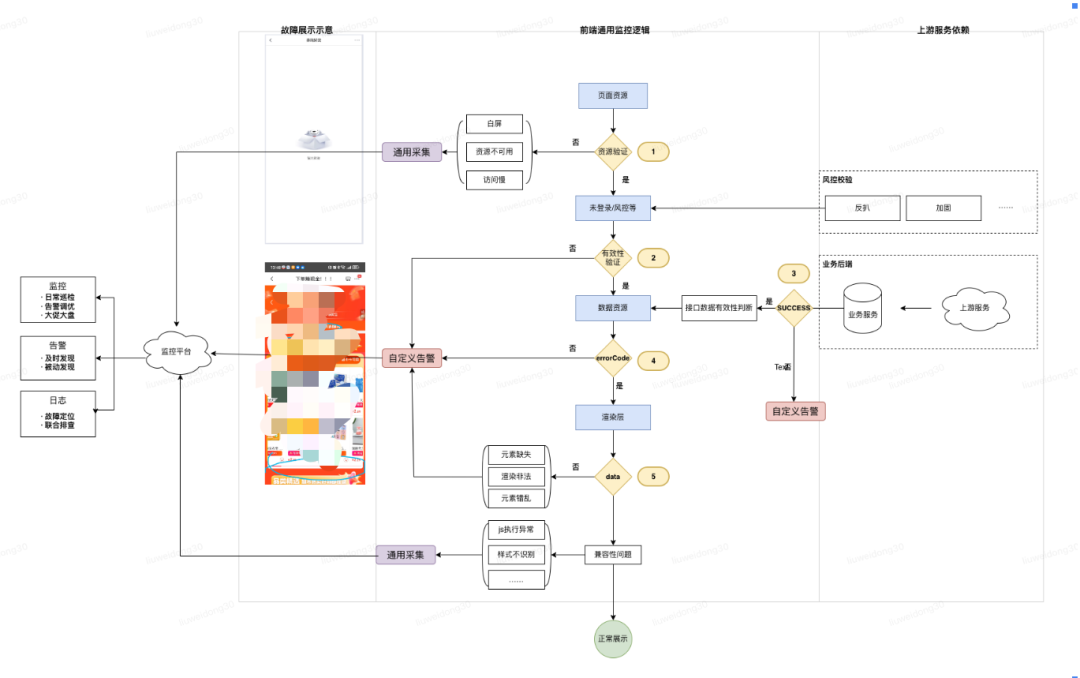
1.3 监控分类
监控大类
· 被动采集:性能监控、资源可用性、资源加载耗时、运行时异常(兼容性等);
· 主动上报:非正常业务响应监控、业务可用性监控、渲染故障监控;
详细分类
资源可用性(通用监控SDK自动采集)
1.页面资源:(HTML)加载超时/慢访问
2.逻辑资源:(JS)加载超时/慢访问
3.样式资源:(CSS)加载超时/慢访问
4.图片资源:加载超时/慢访问
5.接口资源:超时/慢访问(前端默认3s)
6.上游依赖库/三方SDK/接口服务
故障定位(自定义上报)
目标:及时发现,快速止损。
1.客诉故障:快速根据用户信息获取会话级用户端请求/响应日志,协作后端故障定位快速止损
2.上线故障:新功能/页面/组件上线后,边界情况发生,前后端进行双线告警,被动发现及时止损
3.业务入参异常
渲染故障(自定义上报)
1.元素(组件、楼层)缺失
2.元素错乱:建设中……
3.元素露出非法值(价格为0、负数等非法金额)
4.元素渲染失败
5.元素渲染兼容性故障
6.白屏监控:建设中…
业务不可用(自定义上报)
1.系统异常(接口不可用)
2.上游服务不可用
3.接口超时
4.身份不匹配
5.无可用数据(券无品等)
6.活动太火爆
7.其他业务属性
二、监控策略&告警策略
2.1 监控标的
•重点监控对象:常驻元素重点监控、大流量页面/组件重点监控、高价值组件重点监控、易资损组件/页面重点监控;
•日常巡检对象:低活组件/页面、组件按计划按需求迭代上线监控点;
2.2 高效上报
一次上报,配套多个监控点。
利用平台的正则模糊匹配的能力,对message字段内容监控配置,可以对灵活的对一个接口的下游全链路进行监控。
2.3 有效监控(调优)
•技术方案设置监控策略,找出业务边界case;
•线上日志定期排查,丰富/调优告警和监控;
•定期清理僵尸监控和告警;
三、监控告警标准化
3.1 接口服务故障标准化
接口基础响应体结构
{ "success": false | true, //通讯码:接口是否正常返回 "errorCode": "xxxxxx", //错误码:标识接口响应数据异常原因与错误类别信息 "data": {}, //业务数据:业务具体详细数据,前端使用data的数据进行具体内容的显示 "message": "xx接口不可用", //异常日志:简短文字说明接口异常返回具体信息与可能原因。 ……其他字段……}
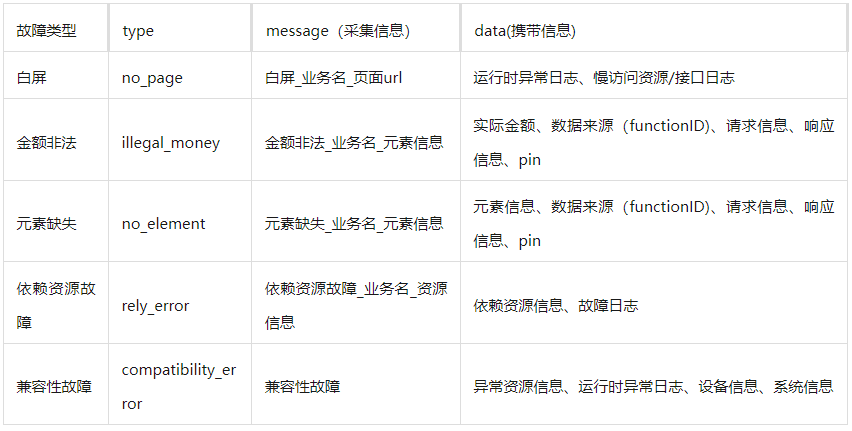
3.2 渲染层故障标准化
3.3 上报动作标准化
monitor.reportError({ type: 'interface_error', message: 'xx服务异常,故障信息:' + functionID + '...' data: { request: {...}, response: {...} }})
monitor.reportError({ type: 'render_error', message: '元素缺失_xxx_楼层', data: { element: 元素信息, funtionID: xxx, request: {...}, response: {...} pin: xxx }})
四、故障应急SOP(精准发现故障问题)
4.1 SOP
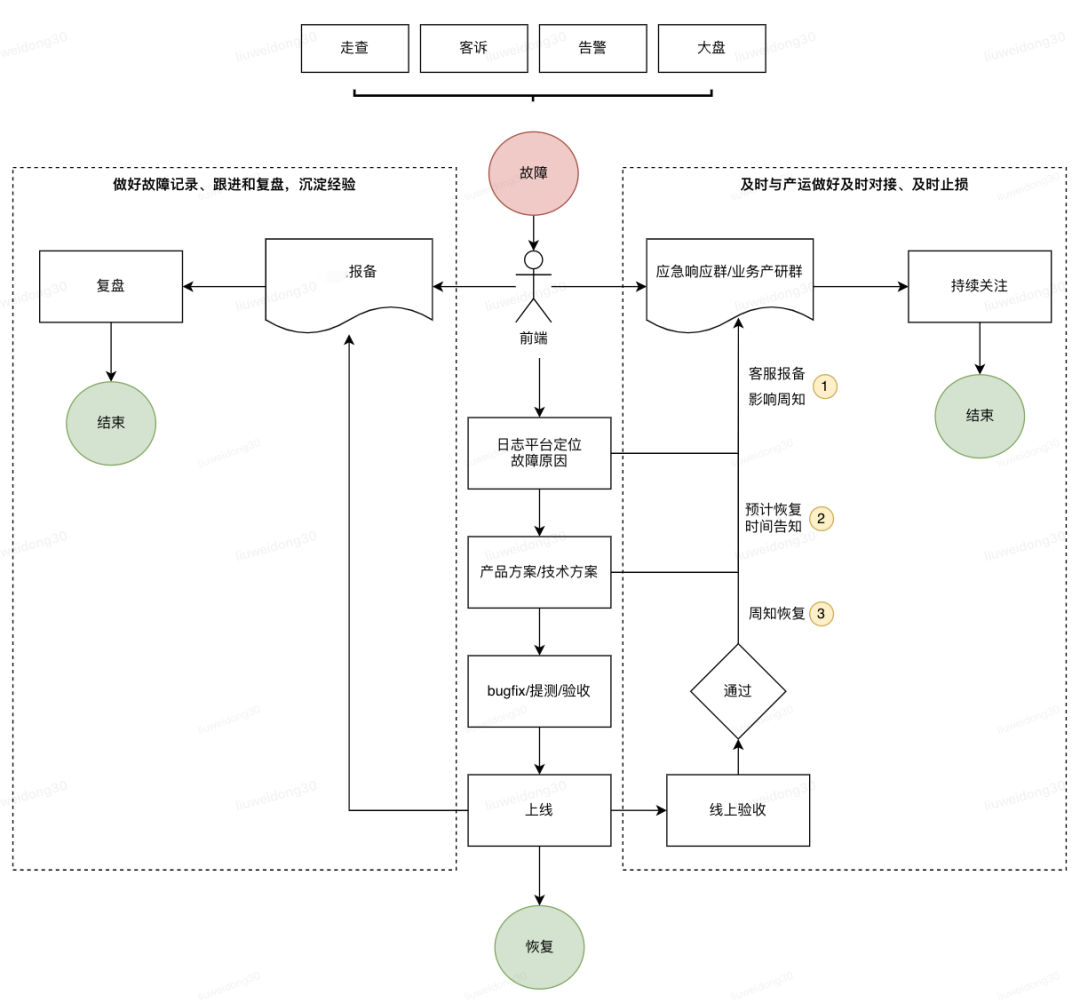
1、监控点采集上报
2、设置多条符合业务故障的告警
3、平台收到告警
4、点开告警查看故障曲线
5、根据告警信息查看具体日志、基本定位故障问题
6、提报监控平台、建立联动群进行故障进一步定位
7、报备产研潜在客诉风险、资损风险及系统功能风险
8、制定产研应急止损方案,转成技术方案
9、bugfix提测跟进上线,观察告警故障曲线
10、应急响应及业务群周知故障已解决
11、跟进故障平台、及时复盘

