震撼!昇腾凭什么把DeepSeek效率“拉到满格”?
在人工智能蓬勃发展的当下,模型架构的创新与计算效率的提升成为推动行业前进的关键力量。DeepSeek系列模型凭借独特的MLA(Multi-Layer Adaptive Architecture)架构崭露头角,而昇腾CANN创新的MLA算子,无疑是助力DeepSeek效率倍增的幕后英雄。
DeepSeek系列模型的MLA架构,堪称AI领域的一项重大突破。它打破了传统Transformer模型逐层递进的线性思维定式,构建起多层异构网络的动态协作模式。这一架构就像为AI赋予了“动态思维中枢”,使模型在面对复杂任务时,各层网络能依据实时需求自主激活、重组甚至创造全新连接路径,实现从语义理解到逻辑推理的跨维度跃升,大大拓展了AI解决实际问题的能力边界。
昇腾CANN团队敏锐捕捉到MLA架构的潜力,早在2024年5月DeepSeek-V2发布后,仅用2个月时间就完成适配优化,首发支持MLA融合算子,并实现与DeepSeek系列模型的原生适配。
随着DeepSeek系列模型不断演进,昇腾持续深耕MLA推理预处理阶段的计算加速技术,探索出VV融合(多个Vector算子融合)及更底层的超级融合方式。
以DeepSeekV3-671B模型为例,其计算流程复杂且精细。初始token的HiddenSize为7K,在预处理阶段,首先通过Q和KV两个降维矩阵进行降维操作,降维后Q的HiddenSize变为1536,KV为576。
Q经过RmsNorm归一化处理后,进入升维矩阵进行矩阵乘法运算,每个token会扩展为128个Head,每个Head的HeadDim为192。随后,Q与KV分别对每个Head进行切分,切分后的部分数据分别进入rope、RmsNorm和升维矩阵等进行后续计算,最终将各自的Head合并,输出结果供MLA算子使用。
在这一过程中,昇腾采用了巧妙的优化策略。具体是如何实现的呢?
首先通过VV融合的方式,它将2串密集的Vector小算子融合为单一算子,简单高效地实现了性能翻倍。这一融合方式如同将原本零散的计算步骤整合为连贯的流程,减少了数据传输与处理的中间环节,大幅提升了计算效率。
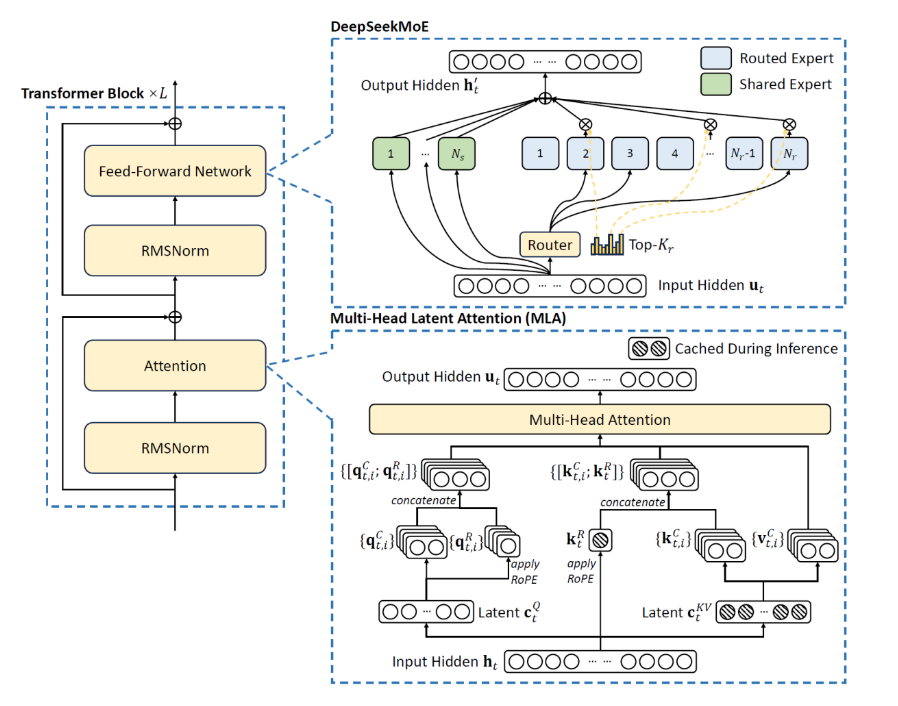
而更为关键的是,昇腾进一步探索底层优化,将整个MLA预处理阶段涉及的Vector和Cube计算进行并行处理,并运用流水优化技术,把前处理过程中的13个小算子融合成一个超级大算子MLAPO(MlaPreprocessOperation)。
融合后,小算子的头开销和下发开销基本消除,在VV融合的基础上,算子性能再次提升50% 以上,计算耗时大幅降低,DeepSeek-V3整网计算性能提升20%以上。
笔者看来,这些技术创新带来的成果意义深远。对于AI研究人员和开发者而言,计算效率的大幅提升意味着可以在更短时间内完成模型训练与推理,加速算法迭代,降低研发成本。在实际应用场景中,无论是智能语音交互、图像识别,还是自然语言处理等领域,更快的计算速度能够为用户带来更流畅、更智能的体验。
目前,针对DeepSeek系列模型的计算优化仍在持续探索中。昇腾团队将沿着从小融合到大融合、多流水并行的技术路线不断前行,挖掘更多提升计算效率的可能性,以工程创新释放更强算力,为AI行业的发展注入源源不断的动力,推动人工智能技术迈向新的高度。

