基于集成网络的离线到在线强化学习
01 前言
强化学习(Reinforcement Learning, RL)有两种基础的训练范式:在线强化学习(Online RL)和离线强化学习(Offline RL)。在线强化学习需要让智能体和环境进行交互,利用收集到的数据同步进行训练,但在环境中进行探索的开销很大;离线强化学习不需要和环境交互,直接利用已有的离线数据进行训练,但这种范式训练的智能体会受限于离线数据的质量和覆盖范围。
基于此,研究者提出了离线到在线强化学习(Offline-to-online RL)训练范式,先利用已有的离线数量训练得到离线策略,然后将其应用到在线环境进行少量步数的微调。这种范式相比于前两者,一方面通过收集少量的在线数据,能够突破离线数据的限制,更贴近实际场景;另一方面在线阶段的微调是以离线策略为起点,相比于从零开始的在线强化学习,只需要非常少量的交互就能快速收敛。这一研究领域主要研究两个问题,一个是分布偏移引起的性能下降,就是如果直接将离线策略应用到在线环境进行微调,会在微调初期出现性能的急剧下降;另一个是在线优化效率,由于在线交互的开销很大,需要用尽可能少的交互次数实现尽可能大的性能提升,这两者可以归结于稳定性和高效性。
在IJCAI 2024上,哔哩哔哩人工智能平台部联合天津大学将集成Q网络(Q-ensembles)引入到离线到在线强化学习训练范式中,提出了基于集成网络的离线到在线强化学习训练框架(ENsemble-based Offline-To-Online RL, ENOTO)。ENOTO以集成Q网络为基础,充分利用其衡量的不确定性来稳定两个阶段的过渡和鼓励在线探索,可以结合多种强化学习算法作为基线算法,在离线到在线强化学习设定下提升稳定性和学习效率,具有较好的泛用性。团队在强化学习的经典环境MuJoCo、AntMaze任务和多种质量的数据集上对ENOTO进行了广泛的实验验证,和以往的离线到在线强化学习算法相比,很大程度地提升了稳定性和学习效率,在大部分数据集上的累积收益提升约有10% - 25%。
02 动机
对于早期的离线强化学习算法,如Conservative Q-Learning(CQL)[1],会显式惩罚分布外样本的Q值,鼓励策略选择数据集内的动作,而这种思想在Double DQN中就有提到。因此我们可以将这里的Q网络从2个增加到N个,这就是集成Q网络。令人惊讶的是,这种简单的改变对于离线到在线强化学习的提升却是非常明显的。我们首先进行了一项验证性实验,使用CQL这个被广泛认可的代表性离线强化学习算法作为基线算法,在经典的强化学习环境MuJoCo上进行实验,实验结果如图1所示。离线到在线强化学习训练有两种很简单的方法,一个是在线阶段继续复用离线强化学习算法,也就是这里的CQL→CQL,但由于离线强化学习算法的保守性,在线优化效率会很低,即图1(a)中的红线;另一个是切换到在线强化学习算法,也就是CQL→SAC[2],但是这种目标函数的切换会导致性能波动,即图1(a)中的橙线。而引入集成Q网络后,CQL-N→SAC-N算法可以在确保稳定性的同时,提升一定的学习效率,即图1(a)中的黑线。
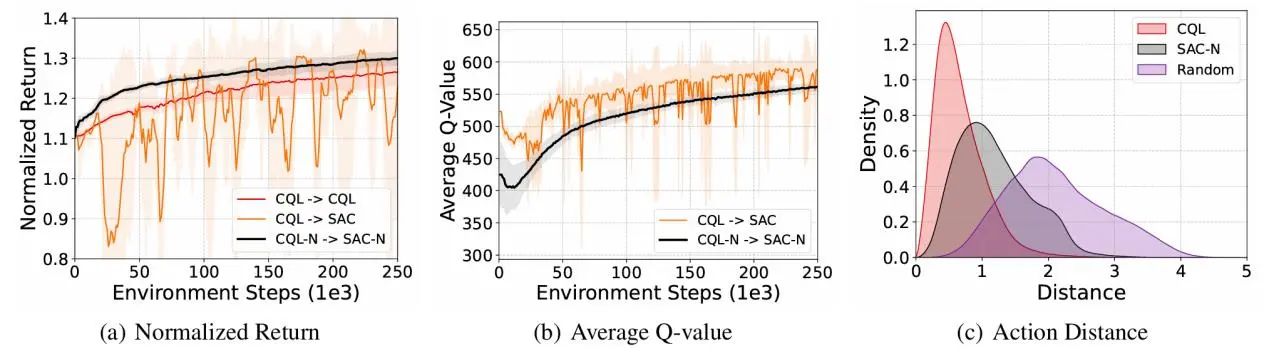
图1 集成Q网络在离线到在线强化学习训练框架中的验证性实验
我们还可以通过可视化的方式来分析集成Q网络的优势。首先我们将CQL→SAC和CQL-N→SAC-N在在线微调阶段的Q值变化过程进行可视化,如图1(b)所示,CQL→SAC这样直接切换优化目标的方式确实会导致Q值的高估并且非常不稳定,而引入集成Q网络之后,由于SAC-N仍然具有保守低估Q值的能力,其相比于SAC算法的Q值也就会偏小并且保持相对稳定的变化。
值得注意的是,CQL-N→SAC-N不仅能够相比于CQL→SAC提升稳定性,实现稳定的离线到在线强化学习训练,而且相比于CQL→CQL还能提升一定的学习效率。针对这一现象,我们通过分析SAC-N和CQL在在线微调阶段的动作选择区间来进行解释说明。具体来说,我们比较了SAC-N、CQL和随机策略在在线微调过程中采取的动作相比于离线数据集内动作的距离。结果如图1(c)所示,SAC-N能够比CQL选择更广范围的动作,这意味着CQL-N→SAC-N能够在在线微调过程中进行更充分的探索,也就有着更高的学习效率。
03 方法
ENOTO框架可以细化为三步渐进式的优化,仍然在经典的强化学习环境MuJoCo上进行实验,但这里展示的是在所有任务和数据集上的综合结果,如图2所示。
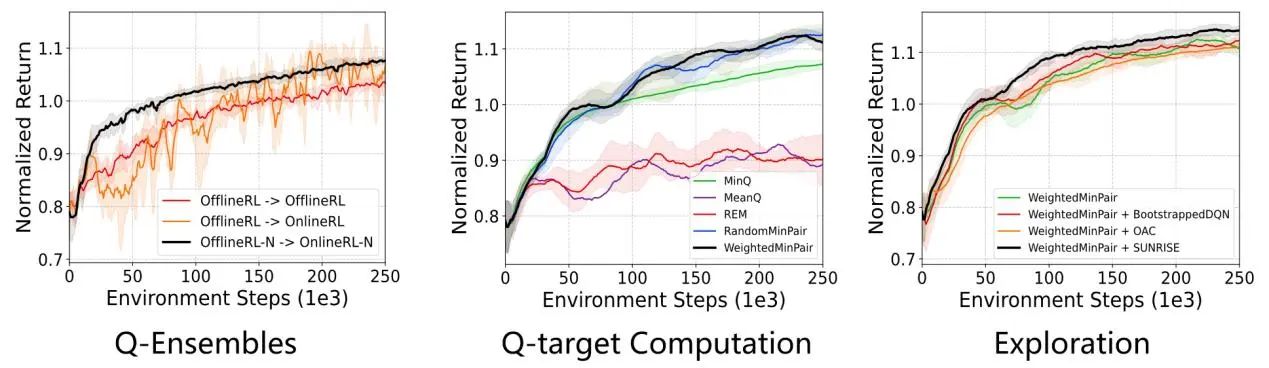
图2 ENOTO的三步渐进式优化
第一步,在已有离线强化学习算法的基础上,我们使用集成Q网络连接离线训练阶段和在线微调阶段,将离线阶段算法和在线阶段算法中使用的Q网络拓展为N个,然后选择所有Q网络中的最小值作为最终的目标Q值进行更新。这一步的主要目的是利用集成Q网络提升过渡阶段的稳定性,当然也提升了一定的学习效率。
第二步,在确保稳定性的基础上,我们考虑提升在线优化效率。第一步的目标Q值计算方法使用的MinQ,也就是N个Q网络选最小值作为目标Q值,但是这种方法对于在线强化学习来说还是太过保守,因此我们又研究了另外几种目标值计算方法,经过实验比较最终选择WeightedMinPair作为ENOTO的目标Q值计算方式。
第三步,我们还可以利用集成Q网络的不确定性来鼓励在线阶段的探索,进一步提升学习效率。具体来说,我们使用集成Q网络的标准差来衡量不确定性,在选择动作时不仅会考虑Q值的大小,还会考虑不确定性的大小,通过超参数调整权重来选择出最终的动作。因为见得少的动作的Q值估计不准,不确定性也会更大,这就是ENOTO中基于不确定性的在线探索方法。
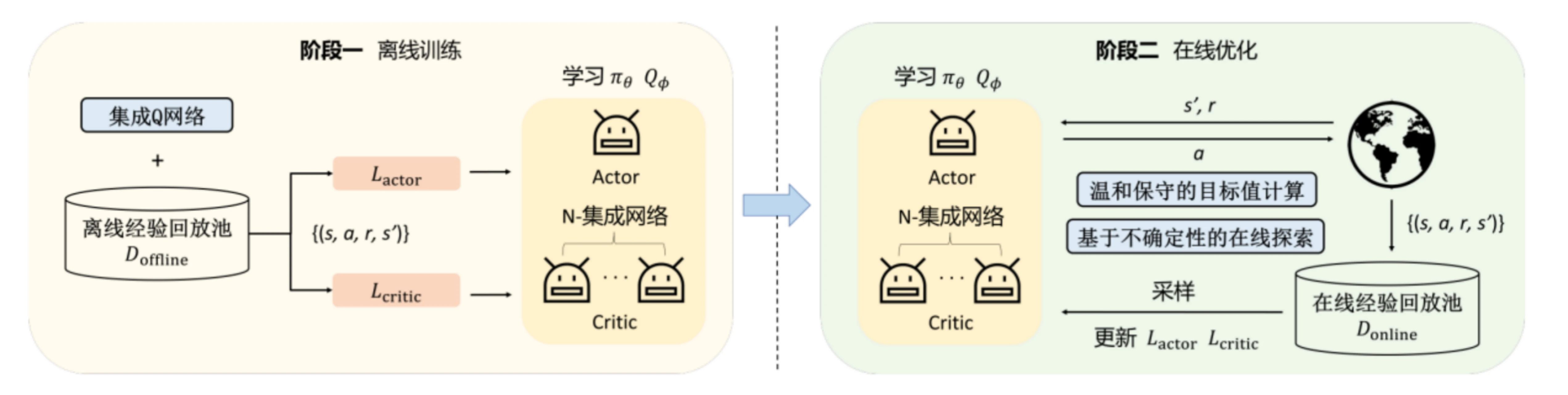
图3 ENOTO框架
如图3所示,ENOTO框架和经典离线到在线强化学习训练范式的框架相同,也分为离线训练和在线微调两个阶段。首先在离线训练阶段,以离线强化学习算法为基础,通过引入集成Q网络,利用已有的离线数据集训练得到1个策略网络和N个Q网络;然后在线阶段迁移离线阶段的策略网络和Q网络作为在线微调的起始状态,在确保稳定性的同时,仍然基于集成Q网络进行设计,通过使用新的目标Q值计算方法和基于不确定性的在线探索方法来提升在线微调阶段的学习效率。整个ENOTO框架以集成Q网络贯穿始终,通过多种训练机制的设计实现了稳定高效的离线到在线强化学习训练。
04 实验
我们首先选择强化学习领域广泛使用的MuJoCo(Multi-Jointdynamics with Contact)[3]作为验证算法的实验环境,在其中的三种运动控制任务HalfCheetah、Walker2d、Hopper进行实验验证。作为离线到在线强化学习训练范式的第一阶段,离线训练需要有离线数据,我们使用离线强化学习领域广泛使用的D4RL(DatasetsforDeepData-Driven Reinforcement Learning)[4]数据集用于离线训练,并且为了证明方法的泛用性,我们选择了不同质量的离线数据集进行实验验证,包括medium、medium-replay、medium-expert 这三类离线数据集。对于baseline,我们选择了离线到在线强化学习研究领域中的经典算法、性能优异算法以及一些在线强化学习算法进行比较。
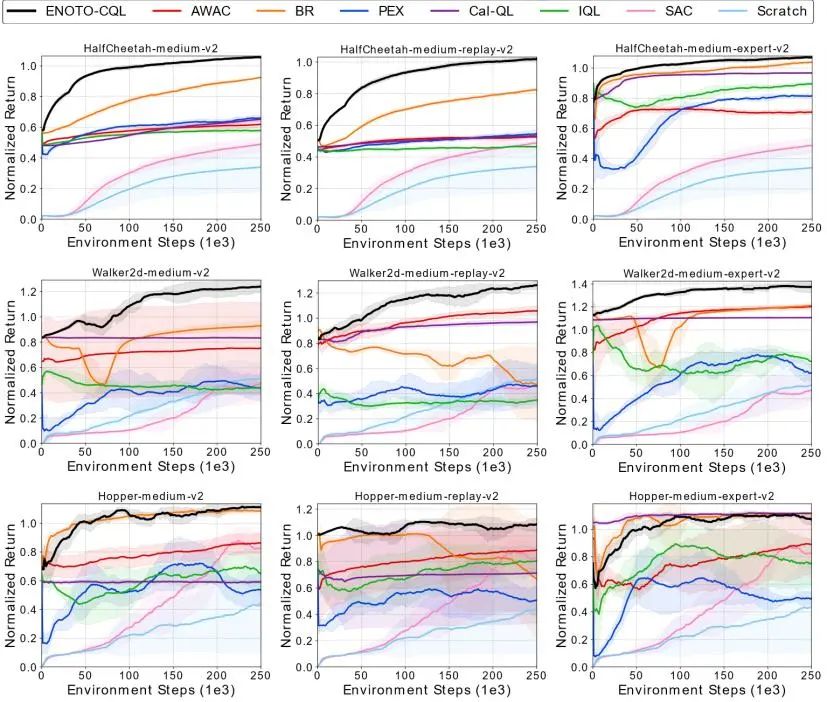
图4 MuJoCo实验结果
图4展示了ENOTO-CQL方法(ENOTO在CQL上的实例化)和基线方法在在线微调阶段的性能表现。与在线强化学习方法如SAC和Scratch相比,ENOTO-CQL从一开始就拥有一个表现良好的策略,并且学习速度快且稳定,证明了离线预训练的优势。对于离线强化学习方法,IQL[5]在在线微调阶段的改进有限,因为完全悲观的训练不再适合在线微调,而ENOTO-CQL则表现出快速的微调能力。在其他离线到在线强化学习方法中,AWAC[6]的性能受到数据集质量的限制,因为其策略的训练是为了模仿具有高优势估计的动作,导致在线阶段的改进缓慢。尽管BR[7]在某些数据集上可以获得仅次于ENOTO-CQL的性能,但其训练过程也不稳定。PEX[8]在在线微调初期阶段的性能在各种数据集上显著下降,这归因于新训练策略在早期阶段的随机性,影响了训练的稳定性。关于Cal-QL[9]算法,尽管其在复杂任务如Antmaze、Adroit和Kitchen中的有效性显著,但在传统的MuJoCo任务中表现较为平淡。在线阶段的提升相对有限。然而,其最显著的特点在于其出色的稳定性,有效避免了性能下降的问题。值得注意的是,Hopper-medium-expert-v2数据集是一个特殊案例,大多数离线到在线RL方法在该数据集上表现出不同程度的性能下降,而Cal-QL则保持了其离线阶段的性能并且非常稳定。
然后,我们在难度更高的导航任务AntMaze上进行实验验证。具体来说,我们使用AntMaze任务中三种不同难度的迷宫进行实验,包括umaze、medium、large,三种迷宫从易到难,能够从不同层面检验算法的各项指标。而作为用于离线训练的离线数据集,我们同样使用D4RL数据集。在D4RL数据集中收集了两类的AntMaze数据:play和diverse。因此,我们在AntMaze任务的large-diverse、large-play、medium-diverse、medium-play、umaze-diverse 和umaze这6个数据集上进行实验验证。同时,为了验证ENOTO对于多种基线算法的适配性,我们在这里使用ENOTO-LAPO(ENOTO在LAPO[10]上的实例化)进行实验。由于Antmaze是一个更具挑战性的任务,大多数离线强化学习方法在离线阶段难以取得令人满意的结果,因此我们仅将我们的ENOTO-LAPO方法与三个有效的基线方法(IQL、PEX和Cal-QL)在此任务上进行比较。

图5 AntMaze实验结果
图5展示了ENOTO-LAPO和基线方法在在线微调阶段的性能表现。首先,LAPO在离线阶段表现优于IQL,为在线阶段提供了更高的起点,特别是在umaze和medium maze环境中,它几乎达到了性能上限。而在线微调阶段由于离线策略的约束,IQL表现出较慢的渐近性能。基于IQL,PEX通过引入从头训练的新策略增强了探索程度,但这些策略在早期在线阶段的强随机性导致了性能下降。需要注意的是,尽管IQL和PEX具有相同的起点,PEX在大多数任务中表现出更严重的性能下降。关于Cal-QL算法,类似于原始论文中描述的结果,它在Antmaze环境中表现出强劲的性能,显著优于其在MuJoCo环境中的表现。值得注意的是,与基线方法IQL和PEX相比,Cal-QL展示了更好的稳定性和学习效率。对于我们提出的ENOTO框架,我们证明了ENOTO-LAPO不仅可以提升离线性能,还能在保持离线性能不下降的情况下,实现稳定且快速的性能提升。
05 总结
本项工作在离线到在线强化学习中引入了集成Q网络作为训练机制,通过构建多个Q值估计网络来捕捉不同数据分布偏移情况下的多样性,提出了ENOTO训练框架。在离线训练阶段,ENOTO让集成Q网络从离线数据中学习多个Q值估计,以适应不同数据分布偏移情况,然后在在线微调阶段整合多个Q值估计,生成稳健的在线策略。在确保稳定性的基础上,我们重新设计了目标Q值计算方法,以在保持稳定性的同时提升学习效率。此外,我们利用Q值的不确定性信息,鼓励智能体探索不确定性较高的动作,从而更快地发现高性能策略。实验结果表明,ENOTO在强化学习经典环境MuJoCo和AntMaze上不仅可以提升离线性能,还能在保持离线性能不下降的情况下,实现稳定且快速的性能提升。这种方法使得离线智能体能够快速适应现实环境,提供高效且有效的在线微调。

