抖音集团大数据血缘演进与深度应用
数据资产管理平台是抖音集团在复杂业务场景中思考的新方向,本文将简单介绍“抖音集团数据资产管理平台”全貌,启发大家对于元数据以及数据资的全新思考,让大家以更宏观视角认识血缘,并对于建设好数据血缘,提供一些建设性思路。
首先整体介绍下抖音集团的一站式数据资产门户平台。
在大数据领域,各大公司通常会开展元数据采集以及数据地图的建设工作,行业内的普遍认知聚焦于“元数据”。而在抖音集团,我们的认知核心在于“数据资产”。
其核心点在于,我们发现若要真正服务好用户,单纯依靠原始元数据,难以满足更精准化的找数需求。因此,我们经过全方位的思考,构建了更具系统化的“管、找、用”数据资产平台。
我们的资产平台支持丰富的数据源类型,借助于强大的元数据采集能力,将所有数据源元数据采集至元数据中心,形成统一元数据湖,其中就包括全链路血缘。
基于采集后的原始元数据,数据BP会通过资产管理进行二次上下架、分级分类等管理操作,平台会借助主动元数据手段(Gartner提出)等,持丰富资产元数据。我们会建立资产评估体系评估资产的完善度,牵引资产不断做好。
在消费场景上,我们基于数据资产元数据构建搜索、门户以及推荐等产品化能力,同时结合大模型构建AI搜索,通过多样化产品矩阵满足数据资产元数据消费需求。以上是数据资产平台整体简单介绍。
本次分享将聚焦于资产体系中的全链路血缘,文章将围绕下面四点展开:
● 抖音集团血缘整体介绍
● 抖音集团血缘系统架构
● 抖音集团血缘应用场景
● 未来展望
01 血缘整体介绍
/ 整体概览
在抖音集团内,对于数据血缘建设的目标是:构建全覆盖、实时、准确的大数据血缘,基于血缘数据打造全场景血缘应用赋能提效。这里我们的认知是:数据血缘是元数据的核心基础能力,如果想致力于打造更高效的数据平台,可提高对于数据血缘的建设重视程度。
/ 建设背景

血缘,即元数据实体之间的关系,也可以简单理解为大数据任务ETL的结构化信息。抖音集团内部数据血缘建设背景,可以分为四个方面:
1. 看链路:整个大数据是一个超大的数据链路,集团内有百万级别的任务,需要结合血缘看清楚这些业务之间的关系。
2. 保质量:生产任务每天都在线上迭代,每天有万级别的线上任务变更,该如何评估好这些迭代对线上是否会产生影响,需要结合血缘链路去评估,以保障整个生产的质量。
3. 保安全:安全是企业数据数据的生命线,如何高效发现企业中的敏感数据,需要依赖血缘数据传播能力。
4. 降成本:超大规模集群规模背后是大量的计算、存储资源,如何合理利用资源,并精准发现低价值资源,并驱动治理,也需要依赖血缘实现。
因此,建设好大数据血缘对我们来说迫在眉睫。
/ 血缘整体链路

那么如何建设好一套大数据血缘呢?
简化来看大数据链路:从埋点到消息队列(或者上游的业务DB),构建离线数仓、实时数仓,数仓加工完后写入到高速存储,提供线上服务或者产品化能力。
基于大数据链路,我们需覆盖血缘包括以下三类。粒度上覆盖表级血缘和字段级血缘,其中字段级我们更多提细粒度字段级血缘,包括行级血缘和算子血缘。
● 数据源或数据采集的血缘:埋点血缘
● 数据生产链路的血缘:实时数仓血缘、离线数仓血缘
● 应用端的血缘:服务/产品应用的血缘
/ 血缘模型抽象
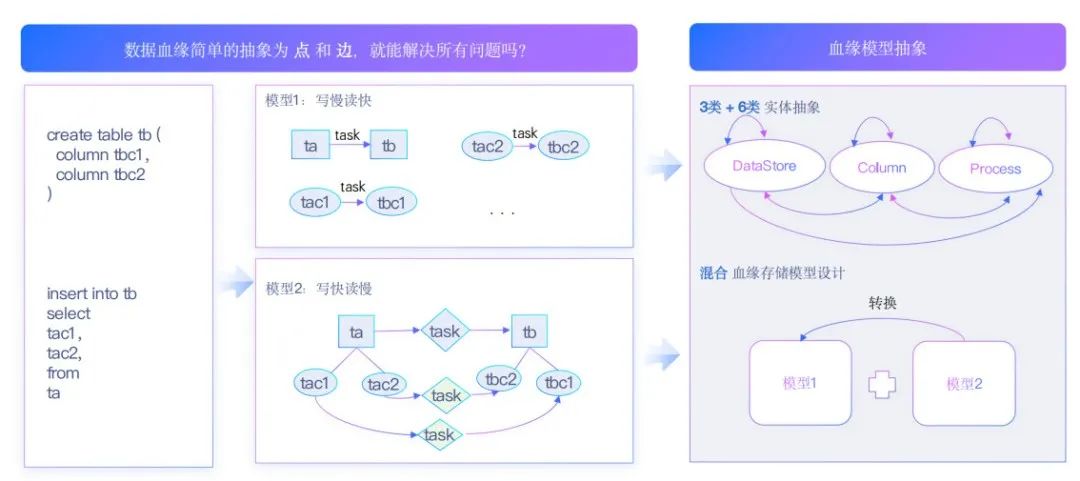
在建设血缘时,该如何抽象模型呢?
前面介绍到,血缘可以简单理解为关系,那是否把血缘抽象为点和边就能解决血缘的问题呢?如上图示例,表tb包含两列,列都来自于表ta,ta和tb通过任务产生的关系,同时两个表的列也都产生了关系,这是最直接的模型。
另外,会发现是这个任务让两个实体产生了关系,所以另外一种模型方式是把任务节点也抽象出来。我们可以通过这两种模型来表达血缘关系,但实际两个模型其实存在差异。
第一个模型:表现更新时会非常慢,一旦任务变更,需要去更新所有任务相关实体节点,但读取会非常高效,因为关系被直接被固化存储;
第二个模型:更新非常快,更新任务时只需更新任务相关的关系,但读会非常慢,需推导最终血缘关系。
基于该案例推演,我们设计了更泛化的血缘模型,在模型中抽象三类实体。
第一个DataStore实体,与通常的Hive Table对应;
第二个抽象是Column,由于实体和实体之间存在从属的关系,所以再往下抽象一层即column,column可以从属于DataStore;
第三个抽象是Process,实体与实体通过task产生关系,所以抽象出Process来表达task。
通过三类实体产生六类关系:实体和实体的关系(如表和表的血缘关系),列与列的关系(即字段血缘),任务和任务之间的关系等。
通过实践验证,该模型能够覆盖到所有血缘关系,在实际存储过程中又考虑到以上两个特点,我们存储了两类模型,写入时使用第二个模型,查询时使用第一个模型,从而满足大数据场景下高效的存储和读取。
/ 血缘衡量指标
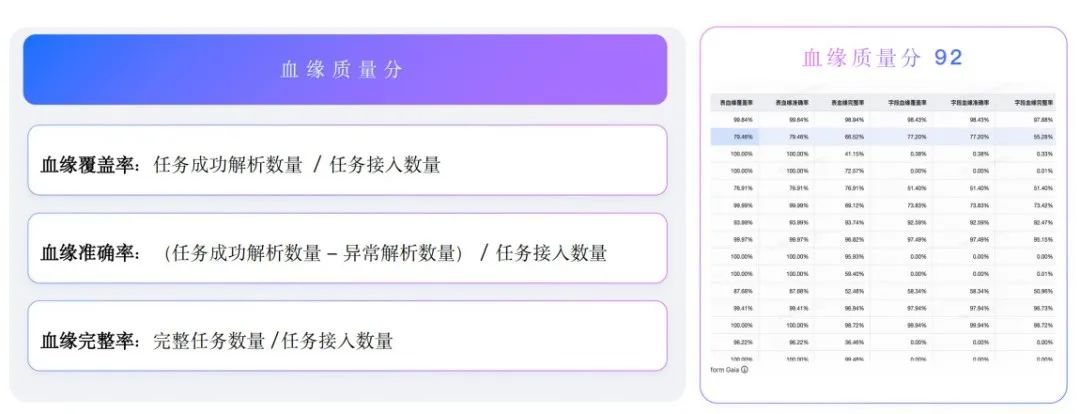
我们定义了“血缘质量分”指标来衡量血缘质量,通过三个一级指标,加权后为血缘质量分。抖音集团内部当前血缘质量分处于较好水平,但仍然也需要持续提升。
1. 血缘覆盖率:考虑任务成功解析的数量,覆盖多少任务;
2. 血缘准确率:成功解析并不代表完全正确,会在覆盖基础上近一步排除异常解析的情况。
3. 血缘完整率:成功解析也不一定完整,最终通过完整率来看清楚血缘是否完全覆盖。
/ 血缘整体生态体系
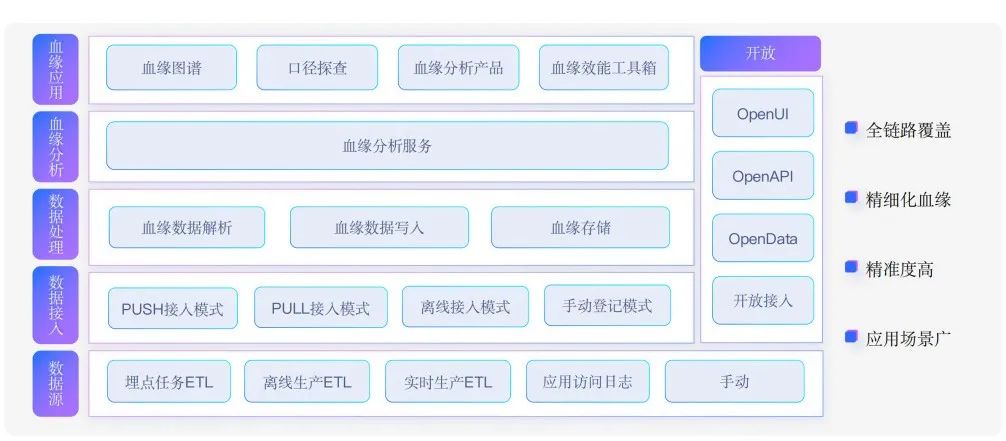
血缘数据重点依赖依赖上游生产任务逻辑或者日志,通过多种接入模式采集,然后通过血缘处理(其中重点是解析)形成统一血缘数据。
对外提供血缘分析服务以及血缘应用,包括血缘图谱、口径探查、血缘分析以及基于血缘的各种工具箱,帮助用户方便快捷地使用血缘。借助于血缘开放生态,希望人人能够贡献血缘,人人能够用好血缘。
整套血缘体系有几个特点:覆盖全链路、精细化血缘、准确度非常高、应用场景广泛。
02 血缘系统架构
/ 血缘系统建设挑战
血缘系统建设主要面临如下一些挑战:
● 首先,如何精准化解析细粒度血缘;
● 其次,如何覆盖非结构化数据源,比如实时链路中会有Redis、Kafka等;
● 然后,如何覆盖跨region的机房血缘;
● 最后,如何覆盖调用较大的应用端调用血缘。
/ 血缘系统解决方案架构
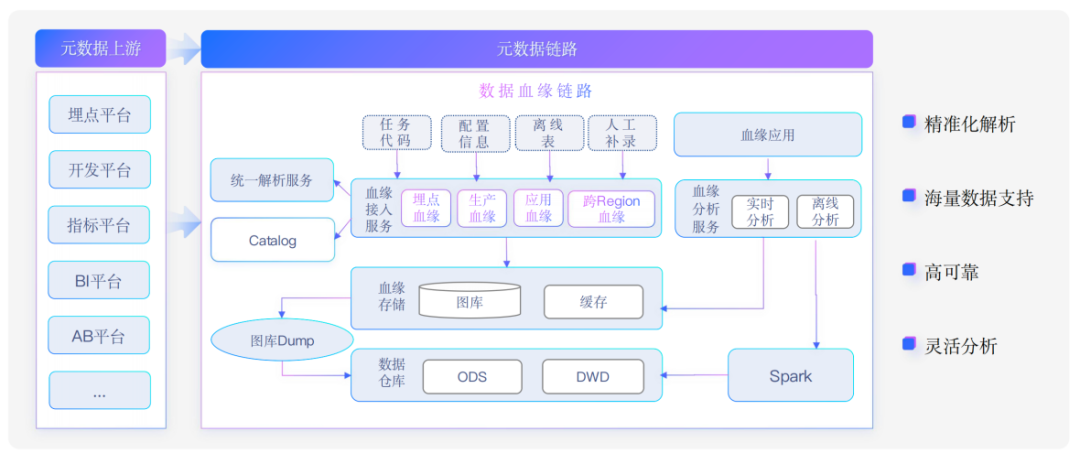
基于以上四个挑战,我们设计了整套血缘架构。
1. 数据源:覆盖各种上游数据源的有价值信息,包括任务代码、配置信息、离线表以及人工补录的数据。
2. 采集:元数据链路和血缘链路,元数据链路重点关注元信息采集到元数据的体系里面;血缘链路,重点结合解析服务和Catalog,提取血缘数据;
3. 存储:通过图库存储血缘数据,开源图库有JanusGraph、Neo4j、NebulaGraph等。离线链路通过图库Dump任务到hdfs,并构建数仓;
4. 分析:通过实时数据和离线数据,以通用的血缘分析服务,支持实时以及离线的分析场景。
/ 统一解析服务
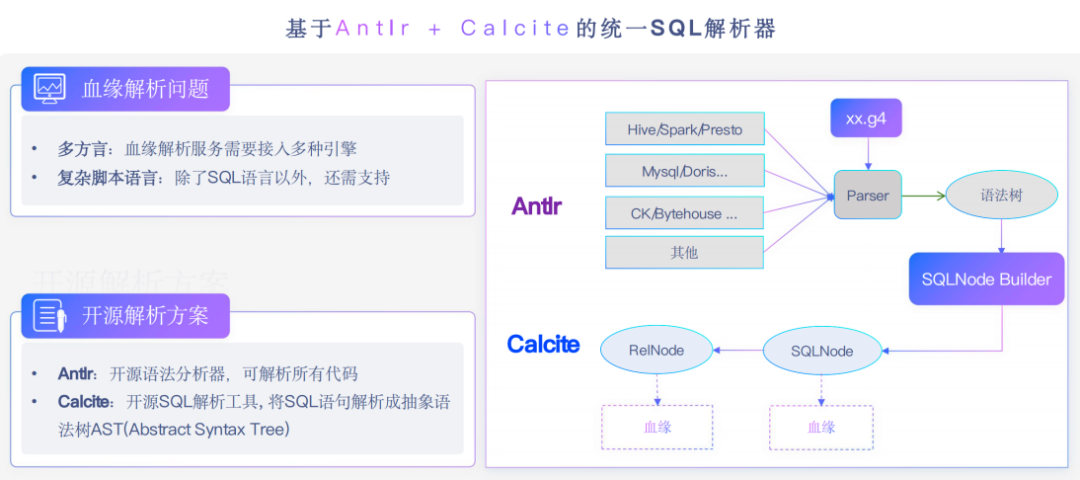
Java体系中有两个比较出名的解析器:Antlr和Calcite。
Antlr是一个词法和语法解析器,能够方便地帮我们解析各种各样语言,变成抽象语法树。Calcite对SQL领域适配较好,SQL方面定义了RelNode,和对SQL相关的优化规则。
解析是血缘领域非常核心的组件,需要关注支持多种方言,因为生产任务是多样化的,有实时、离线、OLAP、非结构化数据以及更复杂的任务脚本。
这里我们提出的比较理想解析方案是:基于Antlr+Calcite的统一解析器,既能覆盖多方言,又能处理复杂脚本,充分利用两个解析器的优势。
我们只要定义词法文件和语法文件,通过Antlr生成语法树,然后把语法树通过SQLNode转换器转换为Calcite的SQLNode,在SQLNode和RelNode中提取出血缘信息。
/ 血缘接入服务-生产血缘
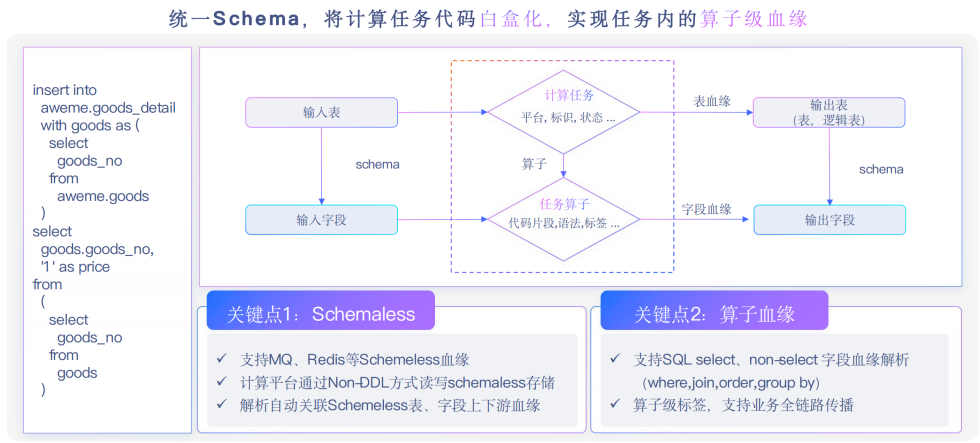
上图中是数据生产血缘示例,一张商品表写到下游的一张表。解析器将任务逻辑解析,获取到表与表的依赖关系,比如商品的detail表依赖商品表,商品detail表里商品的number依赖下面表的商品number。
我们会存储几个关键的信息,字段与字段的裁剪掉代码片段,还会将计算算子存储下来,比如先做aggregate -> select -> where,存到字段的血缘里面,这就是算子级别血缘。
对于no schema的任务,需要去查询catalog构建血缘信息,catalog中已提前管理MQ/Redis的meta信息。对于算子血缘,希望能够尽量全的存储计算信息,会在一些场景使用。
/ 血缘接入服务 - 跨Region血缘
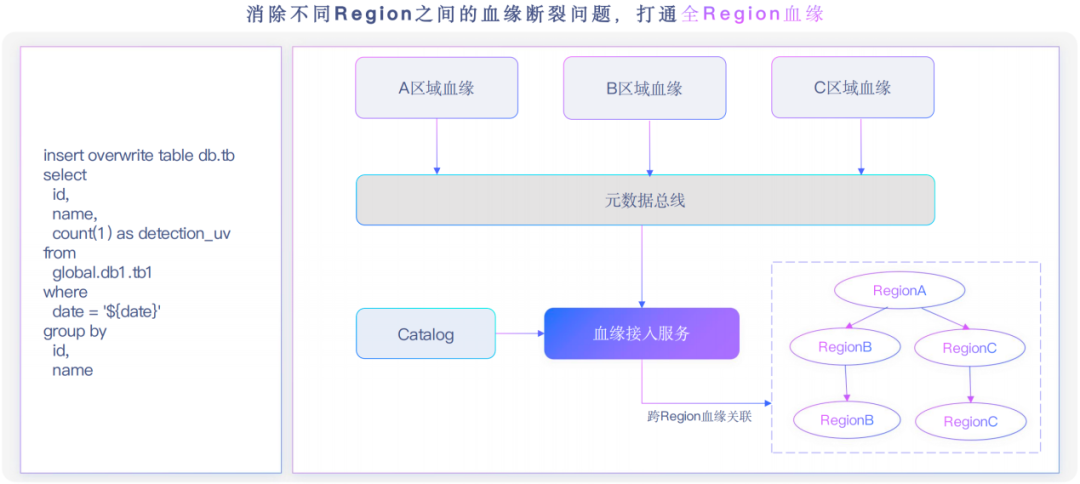
在集团内部有很多region,region之间的数据可能会涉及到一些关联计算,因此需要跨region血缘去处理。
例如A、B、C三个区域的血缘,我们会先在本区域获取local血缘,然后发到总线上去构建跨region血缘。
如果某个区域是一个global表,我们会借助某个区域访问catalog,将global表展开到具体region。
/ 血缘接入服务 - 应用血缘
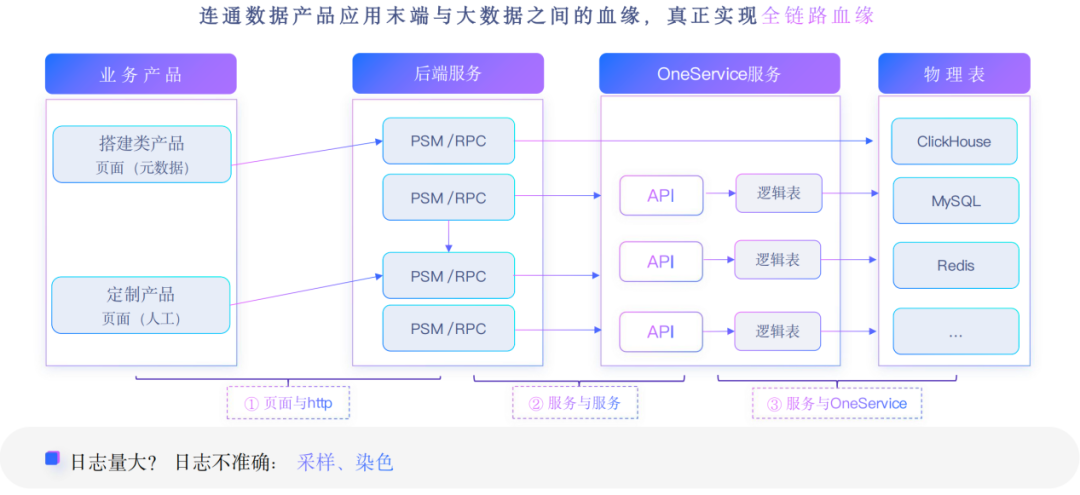
应用端血缘在业界并不常见,是抖音集团血缘的一大特色。我们有非常多的应用端服务和产品,因此希望能够覆盖端到端的血缘关系,实现真正的全链路血缘。所以,我们构建了应用端的血缘。
应用产品大体可以分成两类,第一类就是搭建类,可以通过低代码平台去搭建应用产品,第二类就是定制开发的一些应用产品。
这两类都会通过HTTP或者RPC,去调用后端服务。后端服务会调用大数据one service(统一数据服务),one service服务会调用到物理表。另外一种可能是服务会直接调用物理表。
应用产品页面跟后端服务的血缘关系打通几个方案:
1. 对于搭建类的产品,借助于低代码的meta信息去构建血缘;
2. 通过spider爬取页面信息,通过页面信息提取出页面和接口的信息;
3. 通过trace日志,基于一套日志规范,让业务去按照规范打日志,血缘系统中提取日志获取血缘数据。
服务和服务之间的血缘,主要依赖trace日志去构建血缘关系。服务和one service,基于one service元信息构建血缘关系。
应用血缘采集过程中面临的关键问题:埋点日志量可能会非常大,我们采取日志聚合或采样来缩小量级;埋点日志不准确,业务方把关系打在日志中,我们称之为染色。
03 血缘应用方案
以上介绍了数据血缘系统的建设思路,接下来介绍血缘在内部具体的应用场景。
/ 血缘应用整体介绍
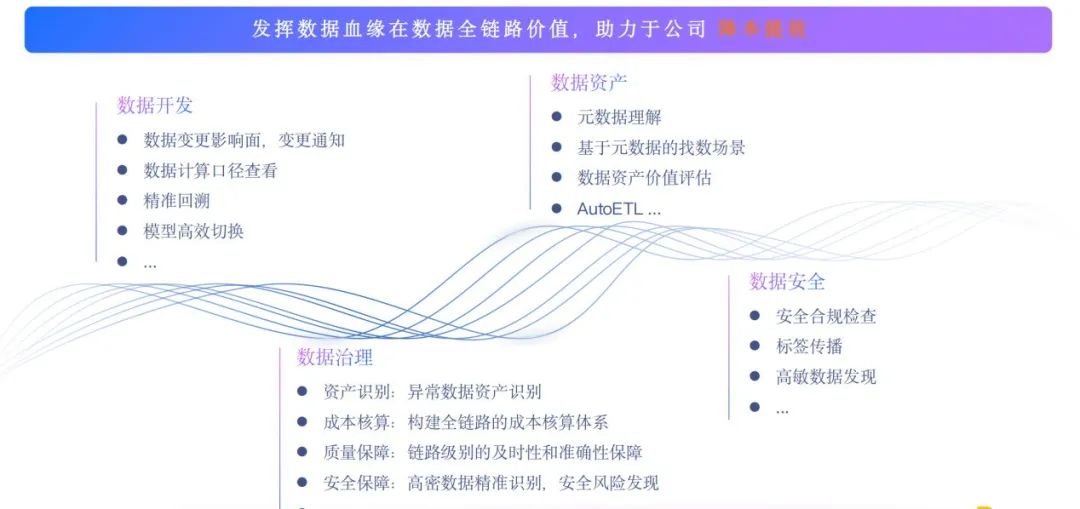
我们希望能够发挥数据血缘在数据全链路的价值,助力公司降本提效。这里列举了四大应用场景,分别为数据开发、数据治理、数据资产和数据安全,其中一些已经覆盖,还有一些正在建设中。接下来将详细介绍各个场景的应用。
/ 数据开发场景的应用
数据开发场景中的应用主要包括:
● 数据变更影响面评估:提供全链路任务、表、列的血缘关系查询、筛选和展示,支持切换select血缘及non-select血缘,帮助用户看清数据之间的关系。
● 快速查看字段或者指标加工口径:通过血缘能力计算数据开发链路,并根据指定字段进行代码裁剪, 只展示该字段相关逻辑,大幅减少无关代码,提高阅读效率。
● 实时开发任务提效:基于指定任务,使用血缘能力为下游任务链路创建影子链路,提供测试链路数据预览功能及线上数据比对功能,预览最终产品的变动。
● 精准选择待回溯链路:基于列级别的回溯范围计算,同时支持用户指定首尾节点、根据特征进行二次筛选等,提升回溯的整体效率和准确性。
● 上游数据变化及时感知:监听元数据埋点变更,根据血缘关系判断影响范围,并实时发送通知,帮助开发人员及时感知上游变更。
● 数据模型重构高校切换:基于用户配置好待切换模型后,根据血缘计算出待切换任务列表,自动生成切换代码,自动完成数据比对。
/ 数据治理场景的应用
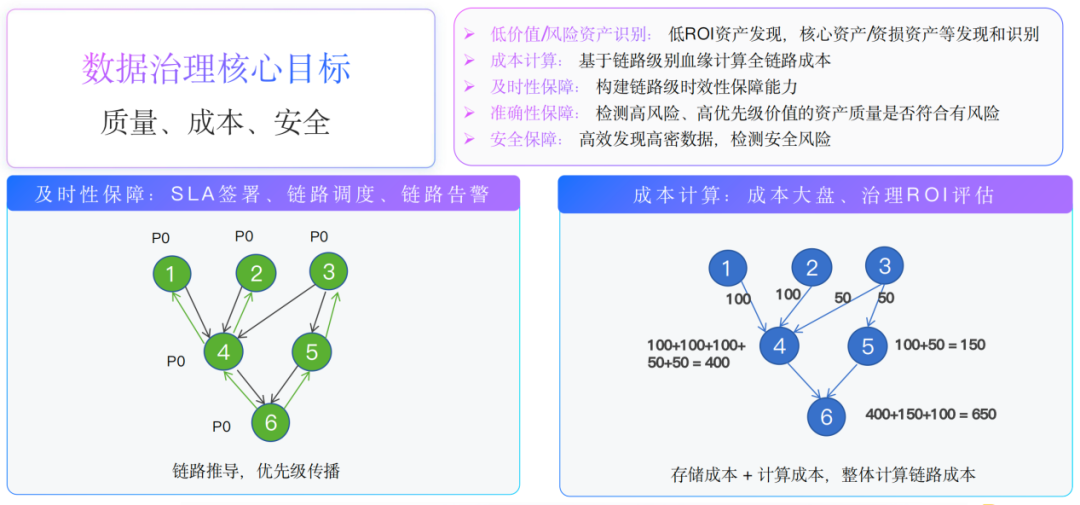
下面重点看数据治理链路应用,数据治理的核心目标是质量、成本、安全。
● 低价值/风险资产识别:通过血缘发现耗费大量资源、下游使用很少的,低ROI的资产,以及一些高风险资产。
● 成本计算:基于链路级别血缘计算全链路成本。
● 及时性保障:构建链路级别的时效性保障能力。
● 准确性保障:检测高风险、高优先级价值的资产质量是否符合预期,是否存在风险。
● 安全保障:高效发现高密数据,检测安全风险。
对于及时性保障场景:通常大家做及时性保障,可能会做单点保障,比如监控某个任务的完成时间。
我们可以充分利用血缘传播能力,当我们发现6这个任务是一个非常核心任务时,我们可以优先级传播到整个链路,进而可以提升链路优先级。
当要求任务6需要6点完成,在任务1执行时可以预判,任务6在6点完成是否有风险,进而实现链路预测告警。
另外,还可以做跨部门SLA签署,比如要保某个任务,需要上游一起保障,就可以通过血缘发现相关资产,然后联合相关部门签署SA,从而保障整个资产及时性。
对于成本计算场景:在大数据链路里面,我们希望看到每个节点实际的资源成本消耗。例如任务6本身消耗资源并不大,但是为了计算6,需要12345这五个任务来辅助计算,那这5个任务的成本也要算在6的成本上,这时就可以基于血缘关系将成本分摊下去。
计算成本是为了能够看清楚资产的计算成本,同时也可以用于评估资产的ROI,结合治理规则,找到低ROI的资产做治理。
04 未来展望
最后简单介绍一下对未来的设想。
/ 数据血缘未来规划
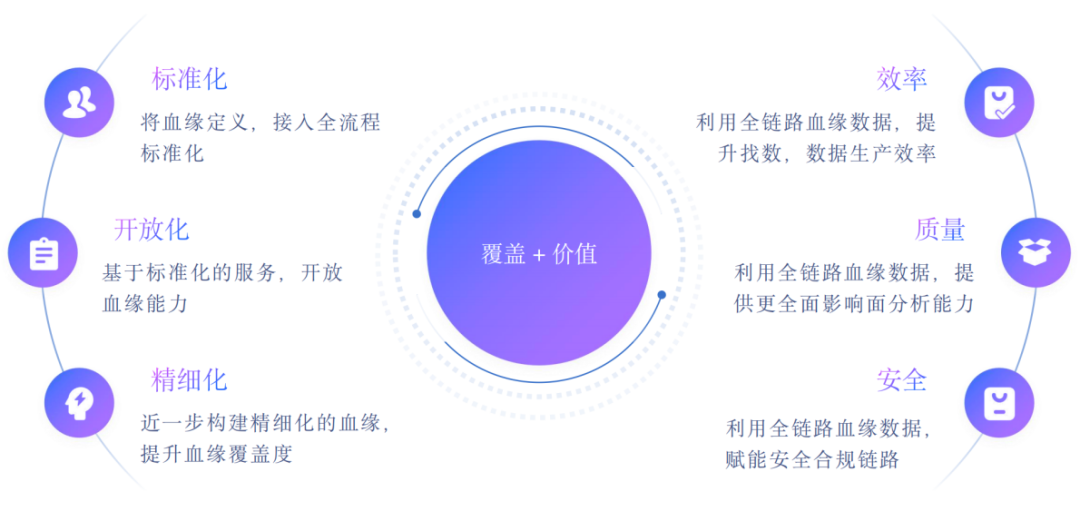
对于血缘的未来规划:全覆盖 和 血缘价值。
首先,会将血缘能力做得更加标准化,简化血缘的理解和接入;其次,基于标准化,做更高维度的能力开放,让人人都可以贡献血缘;最后,进一步构建更细颗粒的精细化的血缘,比如行级血缘。
近一步挖掘数据血缘在质量、效率、安全方面的价值。
/ 数据资产平台未来展望
我们一直致力于打造一套领先的数据资产全链路能力,解决数据资产“管、找、用”的问题,未来期望在集团内部产生更大价值。
我们会构建更完善的元数据,行业里面有主动元数据、大模型等新的理念,结合算法能力挖掘更多元数据,形成统一的元数据知识图谱。持续借助平台能力把数据用好,例如数据资产门户等。

