应对AI挑战,货拉拉机器学习平台海豚出战
1 前言
随着AI技术的不断成熟和广泛应用,已经逐渐成为各行各业用来提升生产力的重要工具。货拉拉作为互联网物流科技企业,过去几年不断深耕AI技术,推动物流行业的智能化发展,并在AI定价、AI营销、AI客服、AI安防等多个领域取得显著成就。
尽管AI技术已广泛应用于货拉拉的各大业务线,并显著提升了运营效率,但在实际的AI模型开发过程中,我们仍面临多重挑战:例如,如何加快模型的开发和交付、提升算力资源利用率等。针对这些问题,我们构建了一套覆盖数据处理、模型开发、训练、部署、在线推理的全链路AI开发服务体系,并通过算力资源的统筹管理,打造了一个低门槛、高性能的一站式云原生AI开发平台。
接下来将详细介绍这些挑战及其解决方案。
2 AI能力落地的挑战
2.1 模型交付效率低
在技术发展初期,AI模型服务从需求提出,到模型开发训练,再到交付上线的完整环节和流程如下图所示:
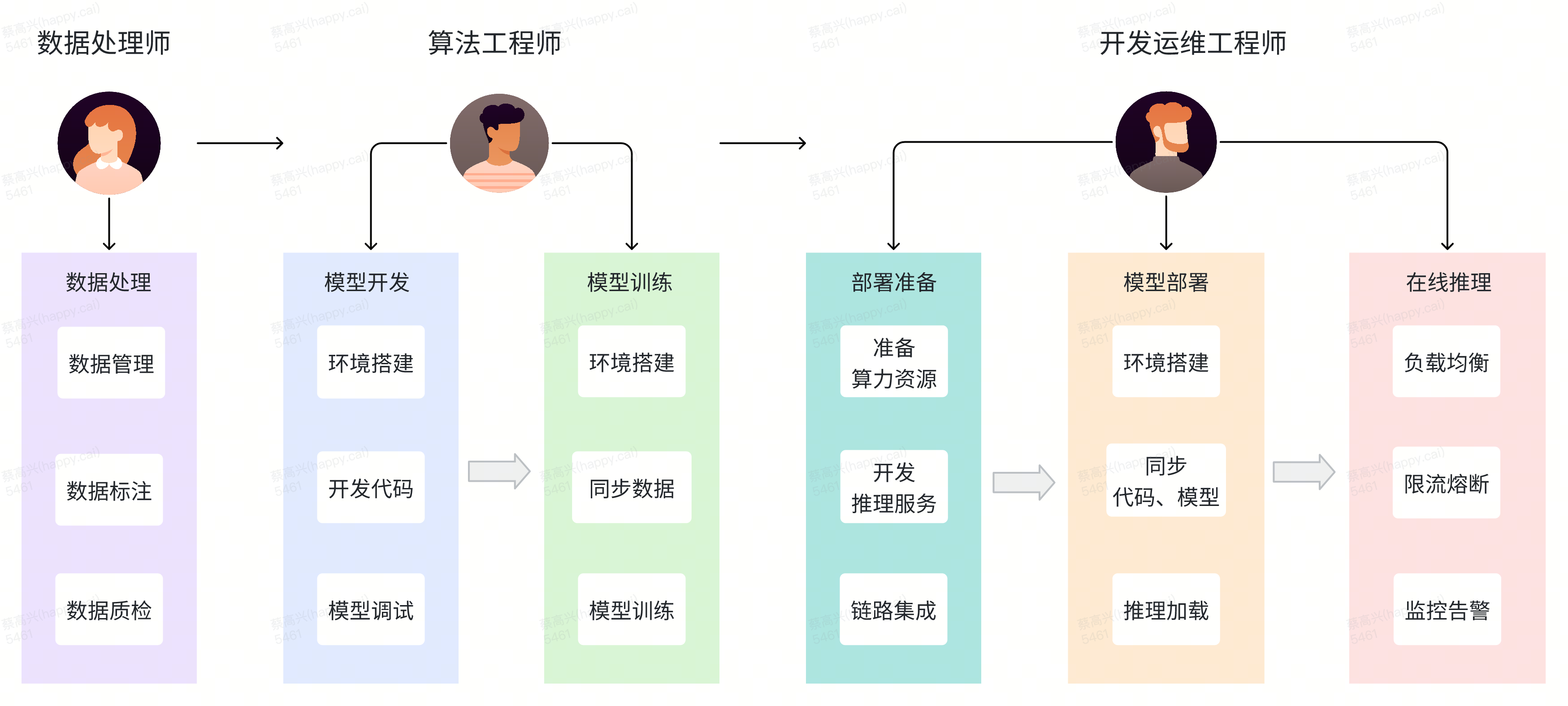
模型生产交付流程复杂:整个流程涉及数据收集、处理、模型开发、训练、部署等多个环节,往往需要跨平台操作实现,增加了流程上的管理和协调的难度。
跨平台导致的数据割裂:各环节和平台之间的数据不共享,导致数据、代码、模型文件需多次手动拷贝传输,尤其是当前大模型动辄几十G的大文件,增加了操作复杂性和出错风险。
环境配置无法跨平台复用:多个平台环节需要手动搭建相同的算法模型运行环境,重复工作多,拖慢整体进度。
2.2 算力资源利用率低
AI应用需要大量的算力资源,尤其是GPU资源,目前是由不同团队各自维护管理,缺乏统一的资源管理和协调能力;算力资源按照机器维度进行分配,多机器之间算力资源使用率不均衡,整体资源利用率低;多模型服务共享同一节点的部署方式在一定程度上可以提升算力资源利用率,但是人工调度的方式,无法准确的把控资源冗余、实时调整资源大小,所以资源利用率有很大的提升空间。
3 海豚平台介绍
海豚平台是一款面向算法和工程团队而设计的低门槛、高可用的云原生AI开发平台。平台集成了数据处理、模型开发、训练、部署与在线推理等模型交付的核心能力,实现了数据、模型和服务的一站式闭环,助力AI应用在货拉拉的快速落地。
平台架构:

3.1 一站式AI开发平台
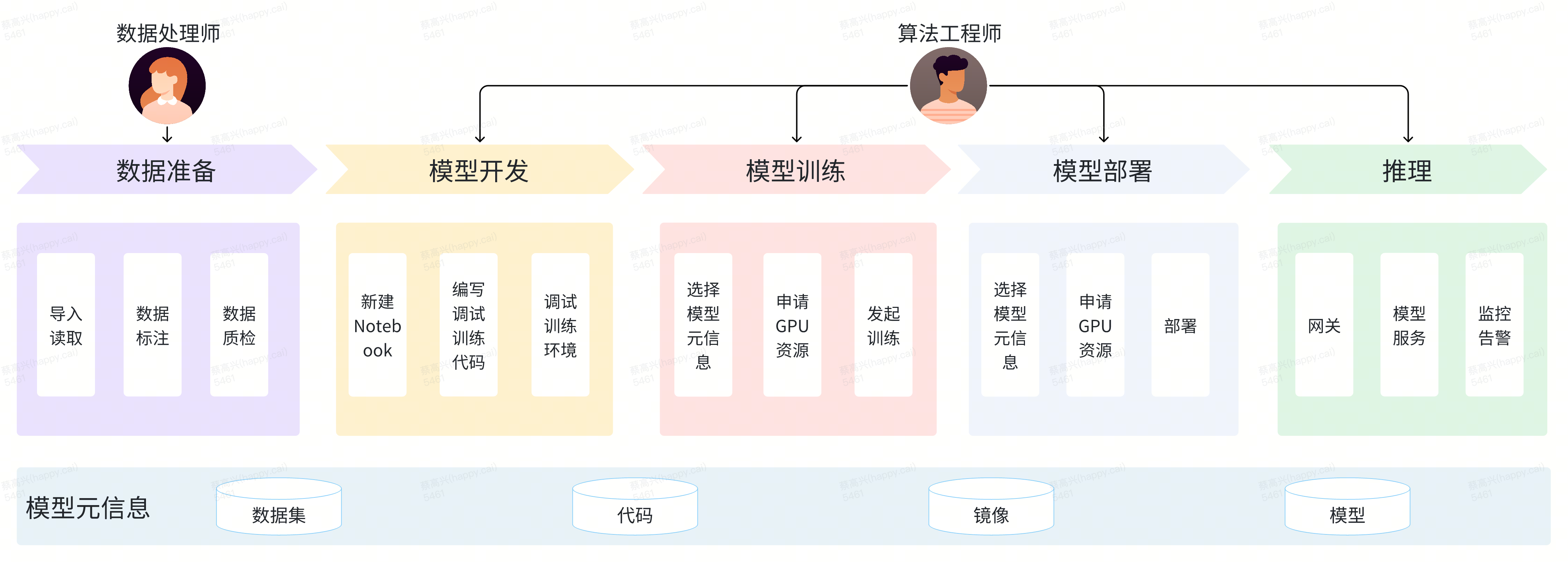
上图展示了如何使用海豚平台进行一个模型交付的流程。算法工程师只需在一个平台内即可实现从数据准备、模型开发、训练到部署的模型交付全过程,并且模型的元信息贯穿AI开发全生命周期,真正做到了一站式的云原生AI模型开发。
3.1.1 分布式存储
为了解决各个环节之间数据(数据集、模型、代码)互通共享的问题,海豚平台通过分布式存储,实现了平台内各环节直接勾选和使用相关数据的能力,无需反复的手动上传和拷贝,打通了各个环节之间的数据孤岛。
个人工作目录:
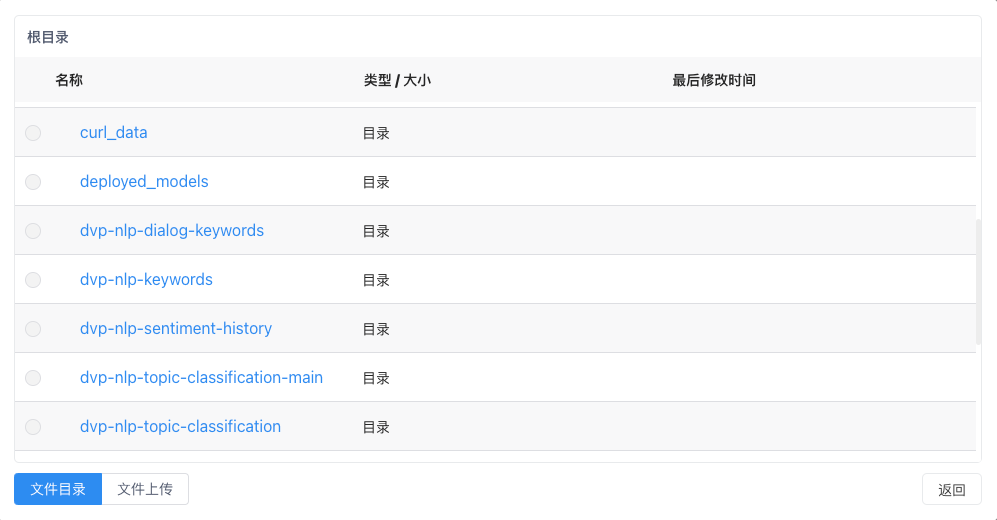
个人工作目录下的文件,通过PVC文件挂载技术,直达容器内部;个人工作目录下的文件仅自己可见,并永久存储。
模型训练代码和数据集挂载:
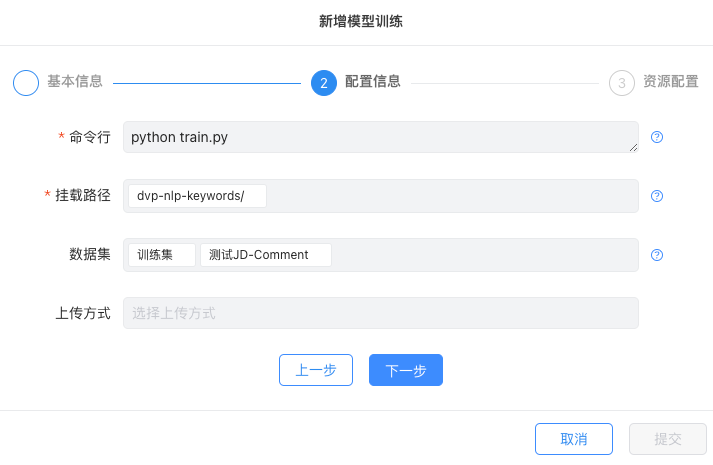
同样在模型训练时只需勾选需要的数据集和模型文件产出的挂载路径,对应的数据集将直接挂载至模型训练的容器内部,同时模型训练后的模型文件将自动存放至个人工作目录下。
3.1.2 镜像管理
在容器技术中,镜像是生成和运行容器的基础,其具有环境一致性、可移植性和版本控制等特点。海豚平台通过使用容器+镜像的能力,有效解决了模型交付流程中模型运行环境重复搭建的问题。
平台内置镜像:
海豚平台内置了多种常见的机器学习、深度学习、大模型相关的的开发和推理镜像(如 Triton、TensorRT-llm、Vllm)
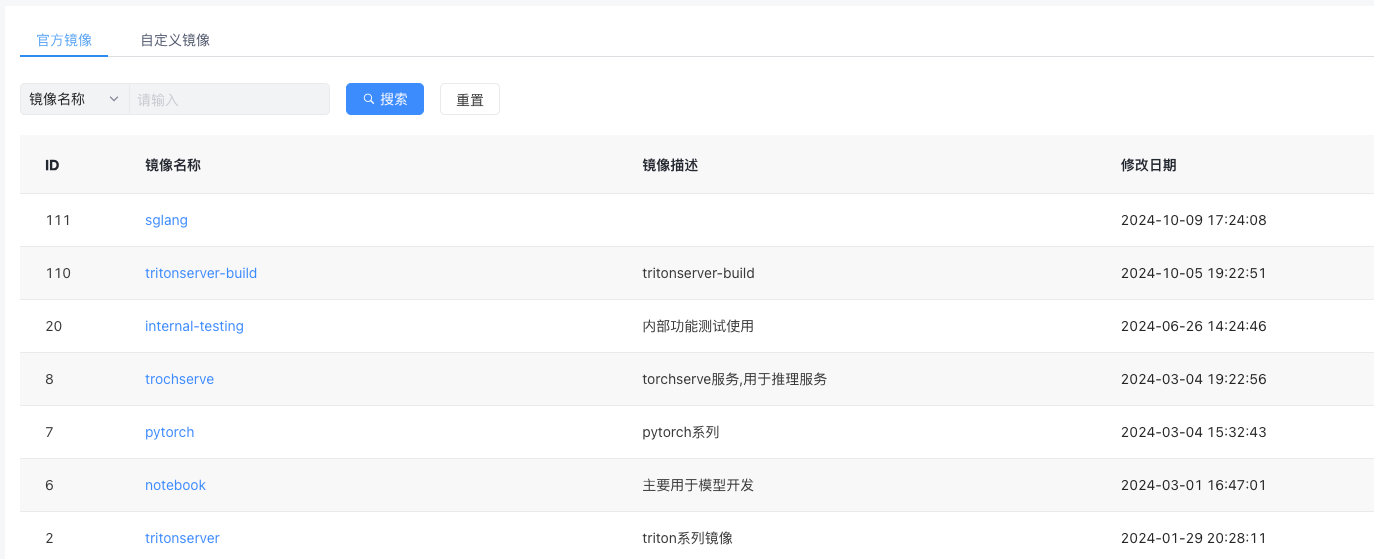
自定义镜像:
同时平台也支持算法工程师通过提交Dockerfile或者基于现有的镜像添加依赖的方式构建自定义镜像。
3.1.3 模型一键部署
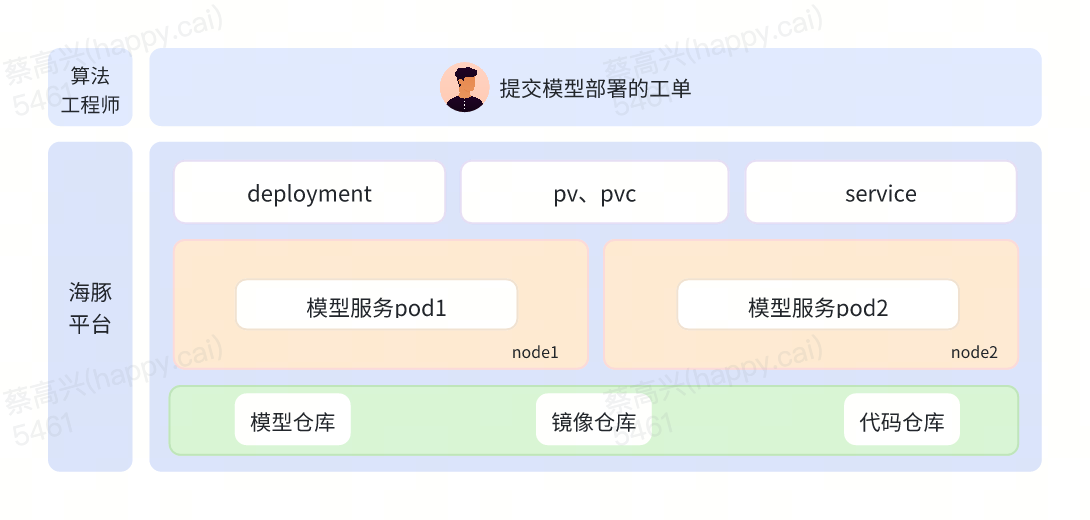
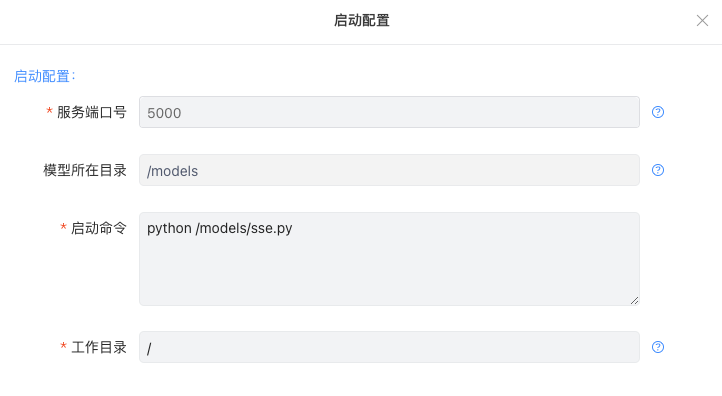
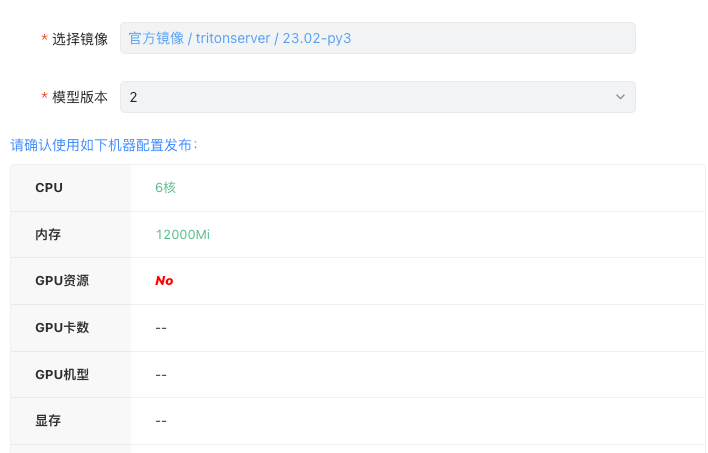
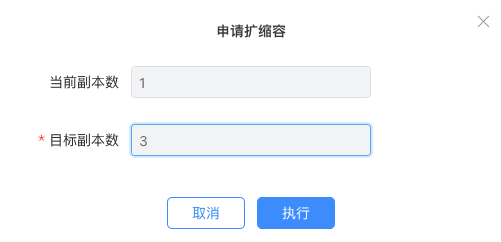
海豚平台通过 Deployment 实现模型服务的容器化部署,算法工程师只需配置模型的启动命令、申请适当的算力资源,并选择对应的模型运行镜像环境,即可快速地完成模型服务的部署。同时面对突发流量,海豚平台可一键完成快速的模型服务扩缩容。
1. 发布配置
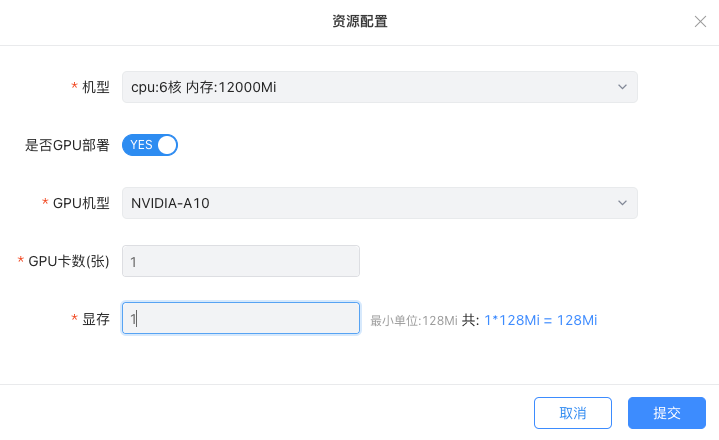
2. 调整算力资源
3. 选择镜像和版本
4. 扩缩容
3.2 算力资源管理
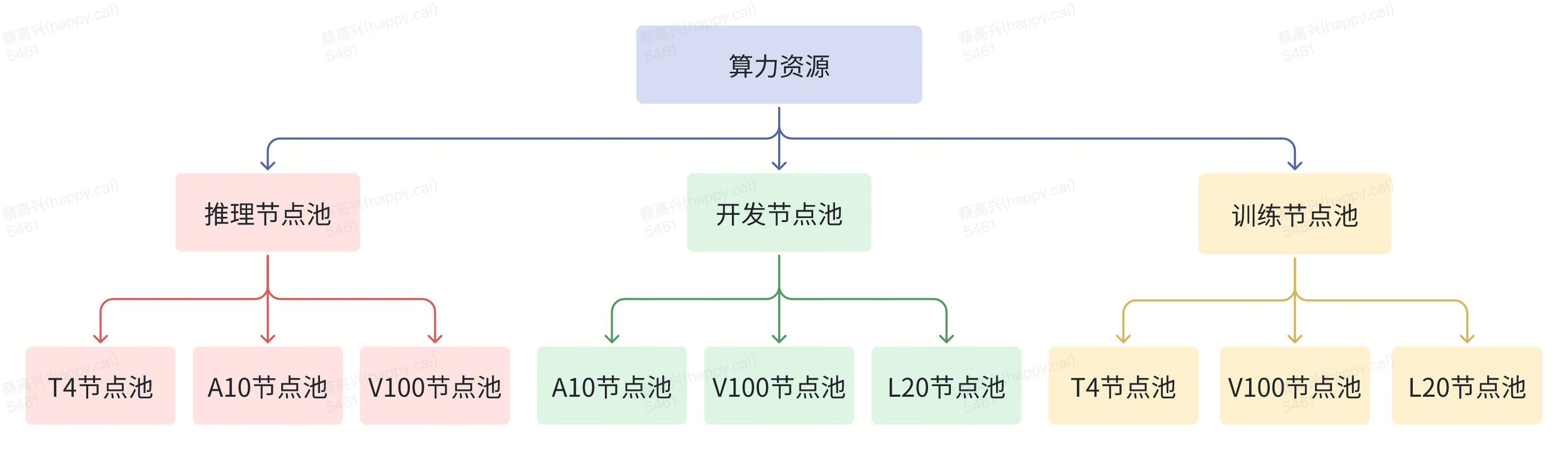
3.2.1 算力资源池化
海豚平台通过Kubernetes实现了算力资源统筹管理,根据不同的使用场景划分了多个资源节点池,每个节点池支持多种类型的GPU机器,在实现算力资源统筹管理的同时,还确保了开发、训练和推理环节的资源物理隔离。
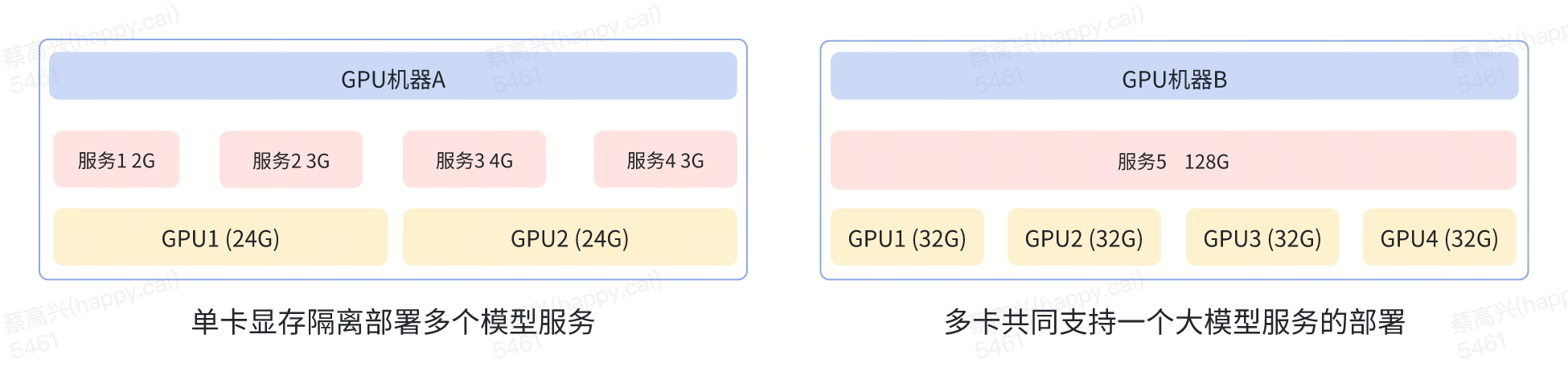
3.2.2 算力分配多样化
多服务共用一张卡:针对业务小模型应用场景,海豚平台基于GPU共享技术,实现了细粒度算力资源管理分配,支持最小128Mi显存单位的申请和释放。
单服务占用多张卡:针对大模型应用场景,当单张卡的显存不足时,海豚平台支持通过分配多张显卡支撑大显存模型的部署。
3.2.3 算力资源自动回收
模型开发自动释放机制:在模型开发过程中,用户申请的算力资源存在闲置且未及时释放的情况。为避免算力资源的浪费,平台分配资源时限定了使用时长,到期未使用的情况下,平台将自动释放这些闲置资源。
3.3 稳定性建设
3.3.1 可观测性
系统的可观测性是指通过监控、日志和链路追踪等手段,帮助快速发现并定位问题,为系统稳定性保驾护航。海豚平台通过统一收集和分析集群、模型服务、网关系统的监控和日志数据,快速感知异常问题并及时通知负责人,确保问题及时感知和处理。
集群监控:
服务监控:
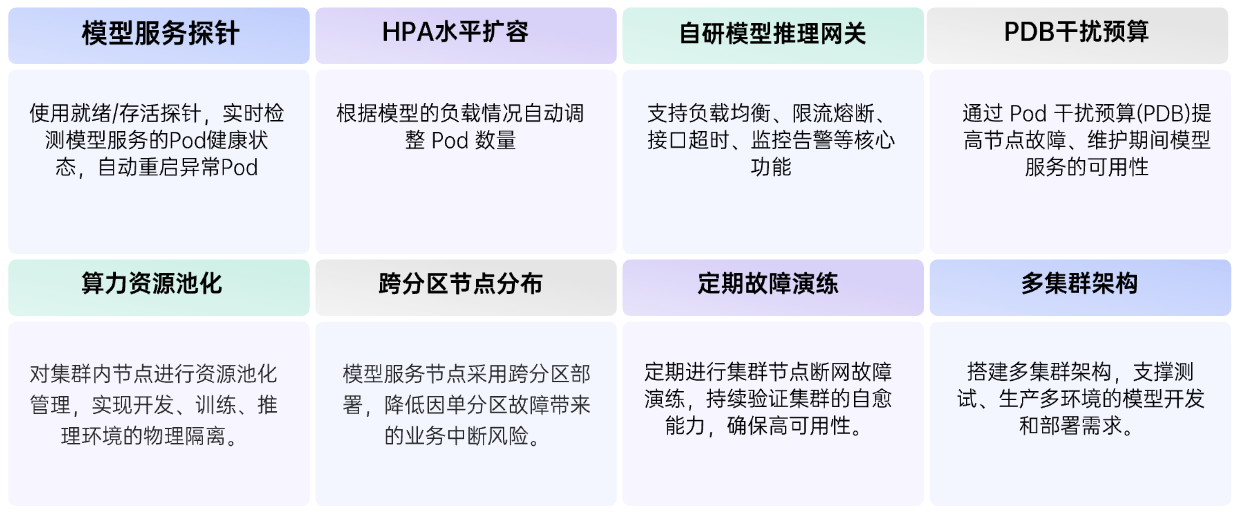
3.3.2 高可用建设
4 海豚平台应用
4.1 通用场景解决能力


基于海豚平台,结合货拉拉的内部业务需求,我们整理并持续优化了通用场景的 AI 解决方案。平台对图像检测、自然语言处理、语音合成识别等常见的 AI 能力进行了产品化封装,业务方对这些能力无需再次开发可直接快速接入应用。
4.2 大模型应用市场
随着大模型技术在自然语言处理、智能问答、文本和图像生成等领域的广泛应用,技术门槛高、计算资源消耗大的问题限制了其在各业务场景中的推广和使用。针对这一痛点,海豚平台打造了大模型应用市场,集成了丰富的预训练模型,支持通用大模型的一站式快速部署与接入使用。
平台还支持通过配置化方式进行模型微调、训练和评估,简化了大模型在各业务场景的应用流程,为其快速落地提供了强有力的支持。

5 海豚平台未来规划
海豚平台已初步完成 AI 开发平台能力的搭建,并成功支持了货拉拉内部多个业务线的AI应用,实现了 AI 能力在多业务场景下的快速落地。接下来,我们将从以下几个方面进一步提升平台能力:
业务赋能:扩大 AI 能力在更多业务部门中的应用场景,为货拉拉各业务线提供智能化支持,全面提升业务效能。
算力资源提升:进一步优化按需分配机制,提升GPU算力利用率,实现多场景下算力资源的高效分配与使用。
大模基础设施完善:丰富开源大模型应用市场,支持多样化的模型训练与微调方式,提供更高性能的模型在线推理,为大模型的创新应用提供更强大的支持与保障。

