一、趣丸多云架构现状
1、多云时代

根据Flexera 云状态报告在2021年有92%的企业采用多云战略,45%的企业使用了多云,到2024年报告表明有89%的企业使用了多云,使用多云是趋势。趣丸在21年开始引入多云,到现在经历了2年多的时间。引入多云的好处我这里总结了四点(成本、资源、稳定性、发展):
防止供应商锁定,在成本上有更多选择。比如有的云商可以提供 AMD 机型,在成本上更便宜。
资源弹性,相信大家都遇到过k8s节点资源池无法弹出的情况,使用多云可以解决此类问题。每个云的机型迭代不同,可以使用更优的计算资源。
故障转移,确保业务连续性,当一个云出现问题时,可以将流量切到其他月,保障业务可用
优势互补,满足业务需求,每个月都有各自的特点和优势产品,对业务来说可以有更多的选择。
从业务方面出发,现在都业务出海或业务全球化,多云可以让我们灵活地选择部署区域,不受限于某个云厂商的服务能力,部署不会受限于某个区域。
2、趣丸架构现状
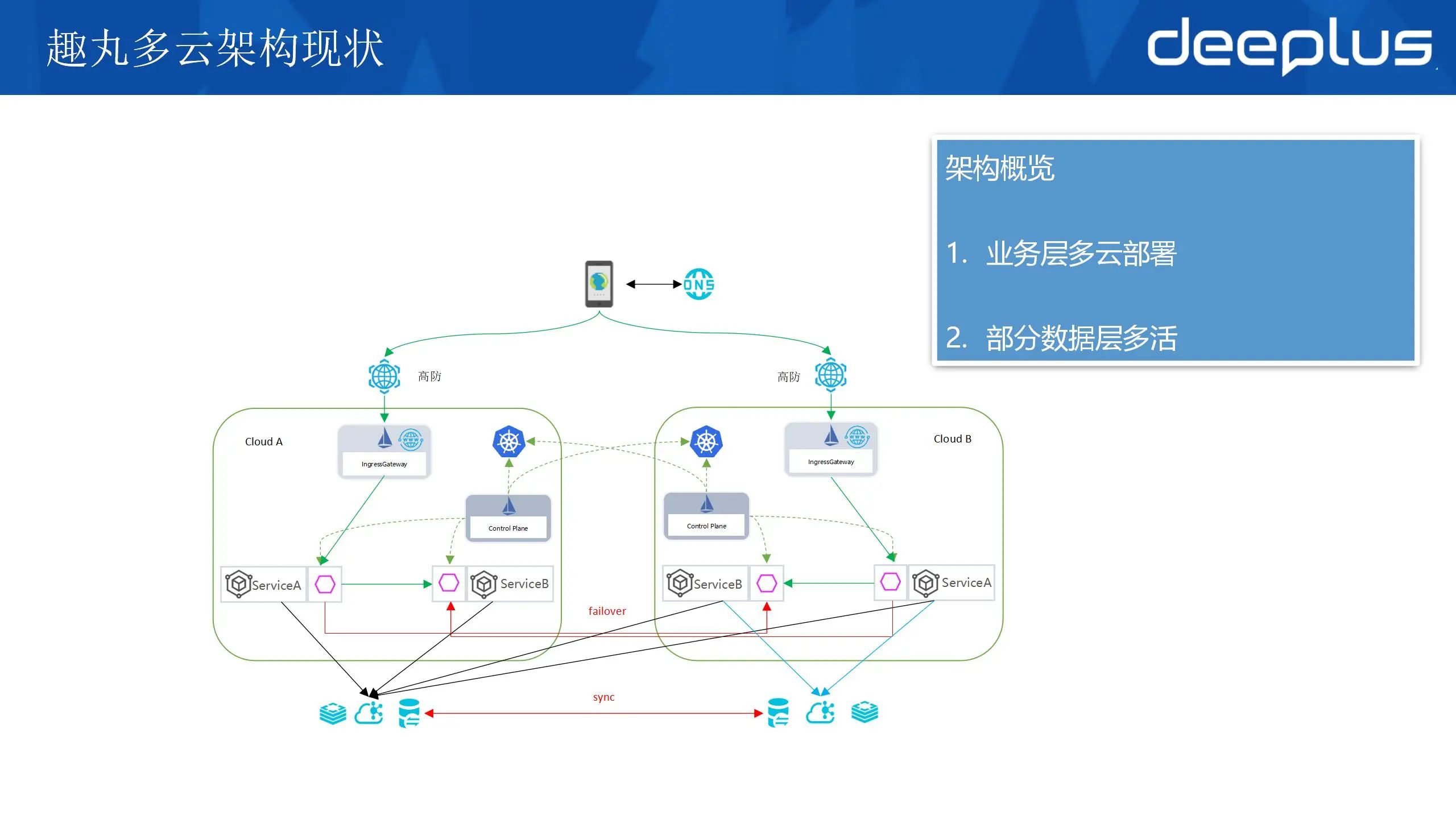
首先对趣丸多云架构现状做一下介绍:在线业务部署在两个云,业务流量通过智能DNS调度到两个云,业务层使用 istio 进行流量管理和故障转移,部分业务改造完成实现数据层跨云容灾。
多云带来优势的同时也必然带来一些挑战,这里我总结了四点:
多云网络互联互通,在单云的架构下,网络环境由云商负责提供。引入多云后需要协调云商,解决连通性问题。
业务层流量调度,需要解决业务层流量调度问题,由A云进入的流量要在A云闭环,只有在A云业务层有故障的时候才会跨云调用。
多云异构可观测,需要屏蔽不同云商监控的区别,在上层构建统一的可观测系统。
数据层跨云容灾建设,在业务没有完成单元化之前,只要做多云多活数据层的多活/容灾就是需要解决的难题,方案也会比较复杂,这里涉及数据同步、仲裁中心、业务切换、数据补偿等问题。
这里我只针对前面3点给出一些实践经验,对于数据层的跨云容灾我们也在探索。
二、趣丸多云架构实践
前面部分简单介绍了架构现状,第二部分通过3个章节介绍解决多云架构三类问题的实践经验。
1、多云互联互通网络构建
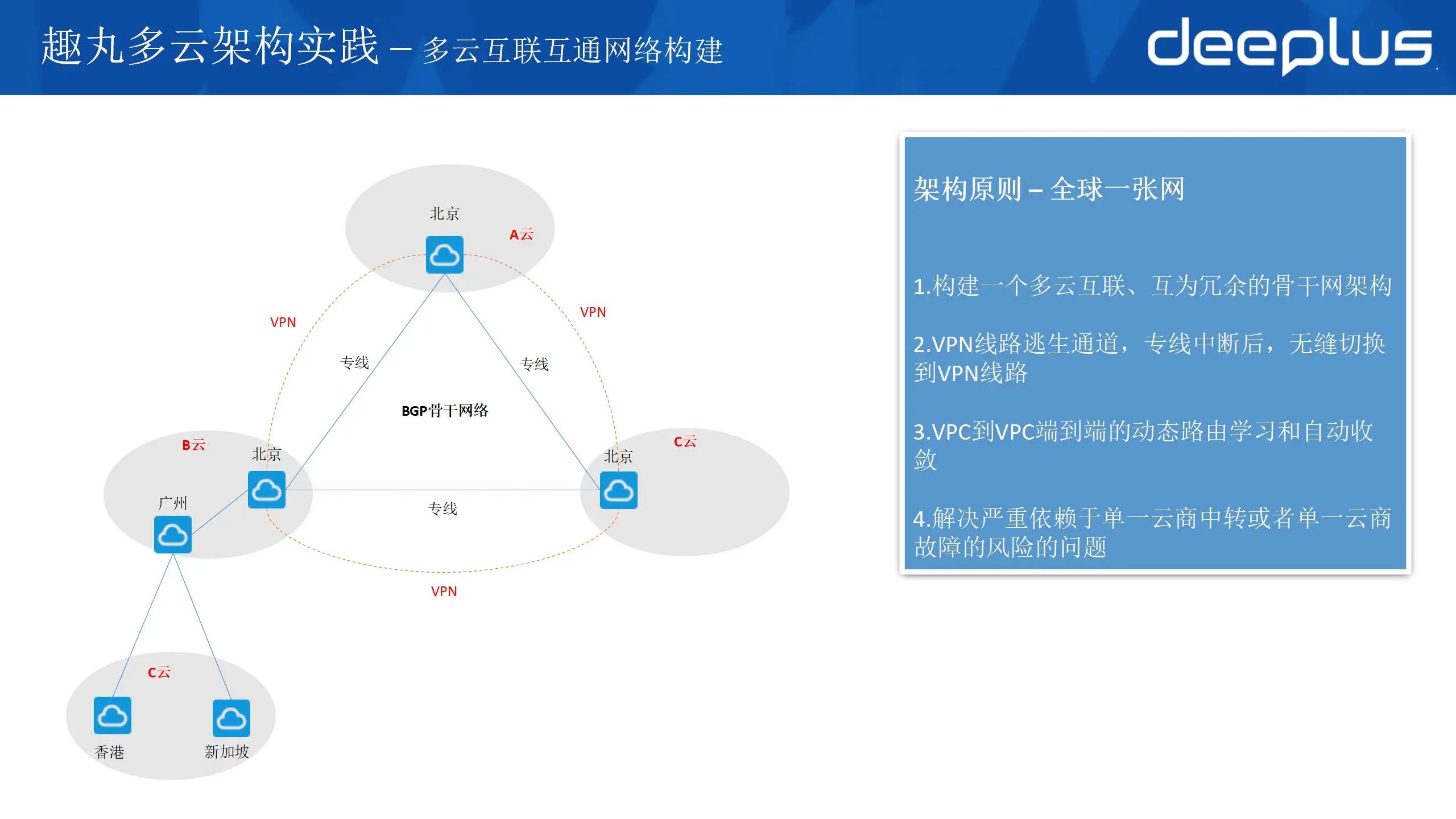
多云架构的基础:多云互联互通骨干网络构建。多云架构对跨云网络联通稳定性要求非常高,从图上来看整个解决方案和传统IDC的网络互联架构没有区别。但是这套架构在云构建时会非常复杂。这里总结了3点:
云商的专线接入产品和能力不一致,需要了解各个云商的产品特点,充分的与云商进行沟通。
云商与专线供应商协商pop点要通过不同的机房或设备接入,防止单点故障(看起来是多条专线,其实接入点都在一起,一个设备问题影响所有专线,这里我们是踩过坑的)。
BGP 收敛速度,BGP 收敛慢一般需要5分钟,需要其他方案加速路由收敛。采用BFD方案加快路由收敛到秒级。
这里建议与云商共建,充分利用云商的特点构建骨干网络。这套网络架构,满足趣丸网络架构原则- 全球一张网,也保障了多云互联网络联通的稳定性。由于受限于云商的产品能力,目前针对流量的 QOS 当前尚不完善。
另外需要考虑的一个点是 VPN 的带宽,当有多条专线时(SLA 无限接近于100%) VPN 作为逃生通道无需承载全部流量(也很难做到),只需要考虑专线全部中断时,作为管理流量的逃生通道。
2、云原生架构下的多云流量调度
说到云原生一般都会想到云原生15 要素 和 云原生的特点:微服务、容器化、不可变基础设施、服务网格、声明式API等。趣丸通过这些原则和实践,从18年开始对业务进行了大量的改造,比如通信协议、服务发现等等,实现了应用的快速迭代、灵活部署和高可用性,推动了业务的持续创新和稳定发展。
下面我主要在流量调度层面介绍一些落地实践。
1)部署方案和东西流量管理
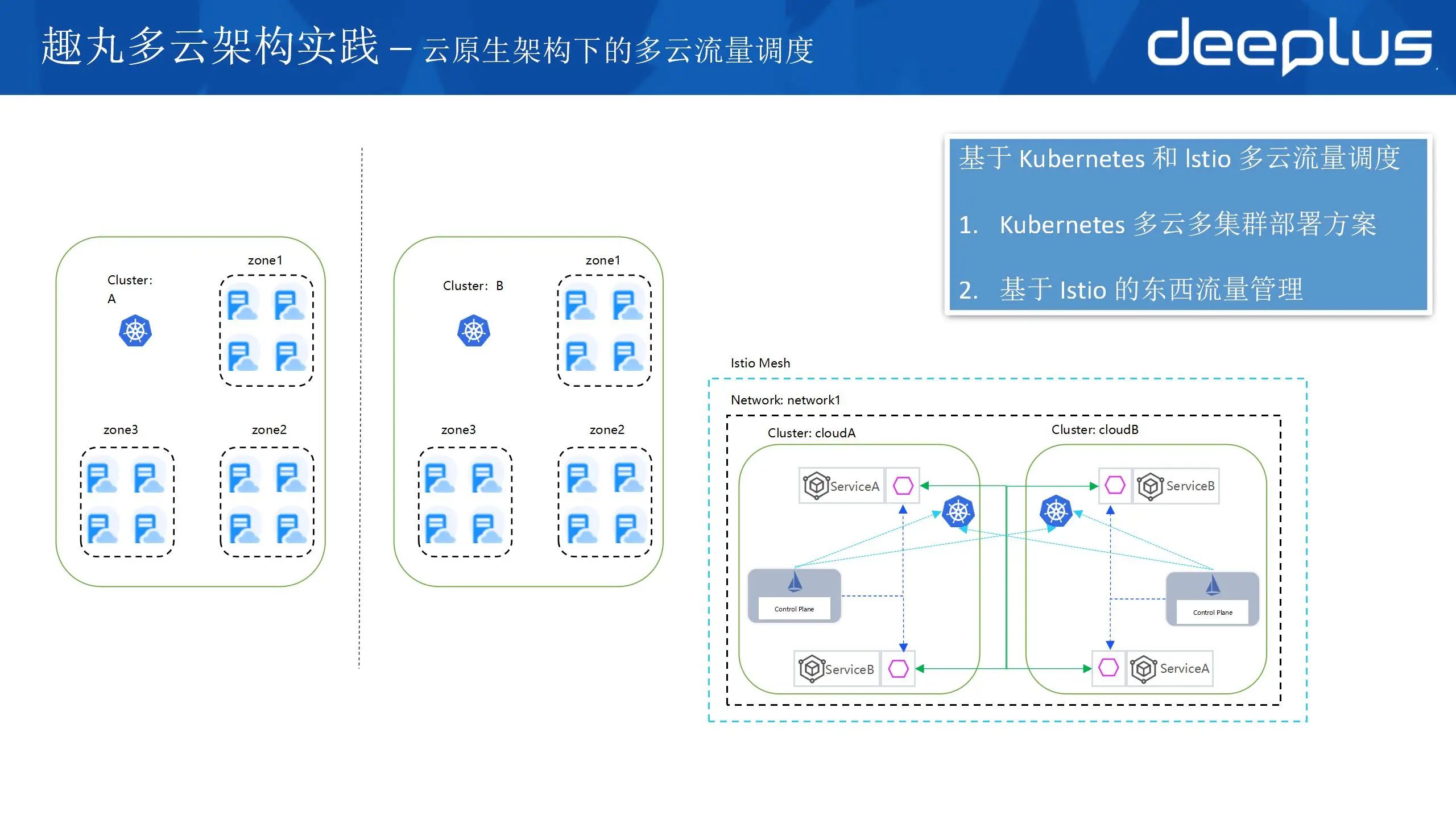
Kubernetes 集群部署相互独立,业务通过一套CICD进行多集群部署,没有采用多集群管理的方式。
我们出于以下3点考虑:
多个集群相互独立可以满足一定的隔离性,防止集群全部瘫痪。
集群部署方案是跨zone部署,要求每个集群分布在3个zone,不会因为单 zone 故障导致整个集群不可用。
更好的使用的弹性资源,防止因为 单 zone 没有资源无法弹出节点,导致业务受损的问题。
通过 Istio 的多集群流量调度实现业务东西流量调度。istio 集群的部署模型我们采用的是单一网格的多主架构模式,这个模式业界采用较多的方案。主要有两个好处:
每个集群一个控制面,可用性更高,不会因为一个控制面出问题影响整个网格。
2隔离性更好,每个控制面可以分开配置、升级。
多主架构模式的特点是:多个集群一个网格,每个控制面的 istiod 都能发现其他所有集群的 svc 和 endpoint,并通过 xDS 下发给本集群的 istio-proxy,实现工作负载可以直接互相访问(跨k8s集群workload的互相访问)。这个架构有一个前提条件是所有云商的网络是打平的。
这个架构也存在三个问题:
istio 发现的svc 和 endpoint 越多 xDS 就会越大,导致 xDS 下发成为瓶颈。缓解 xDS 下发性能的方案有几种,最有效的还是通过 Sidecar 做隔离,减少不相干 xDS 的推送。这不是多云独有的问题。在Istio 1.21 版本中针对xDS下发性能问题,官方提供了 delta xds 的功能,我们也是在测试环境开启测试。官方方案之外有一些第三方的解决方案,整体思想都是 xDS lazyload,不过这些方案都不够成熟。
工作负载跨云访问,会引发不必要的流量和请求延迟。
工作负载互相访问,也带来安全边界的问题。
2)多云流量调度
针对目前架构存在的问题2和问题3这里给出一些解决方案。
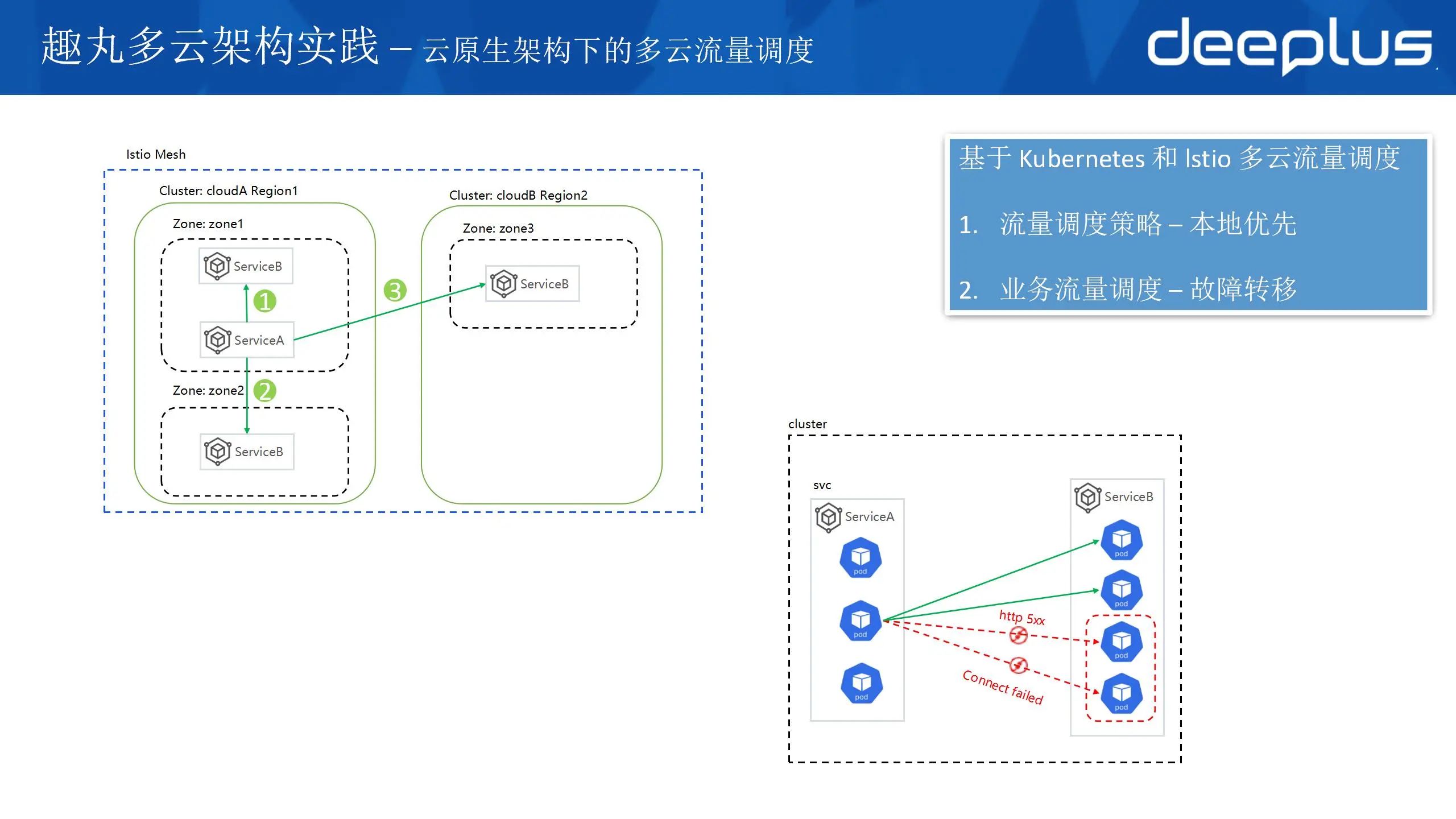
防止非必要的跨云流量,需要制定一个流量管理策略:本地优先,在本云内闭环,本地失效时流量调度到其他区域。
通过istio 的负载均衡规则的 failoverPriority(故障转移策略)来实现需要的流量管理策略:
loadBalancer:localityLbSetting:enabled: truefailoverPriority:- topology.istio.io/network- topology.kubernetes.io/region- topology.kubernetes.io/zone
这个策略可以保障:
优先访问本Region,本Zone
本Zone失效,优先访问本Region其他Zone
本Region失效,访问其他Region的Zone
需要注意的是让pod均衡的分布到多个可用区(建议使用k8s 的Pod 拓扑分布约束:topologySpreadConstraints )。
解决了zone和region级别的容灾能力,经常遇到一个应用的部分pod也出现问题。例如:
xDS 下发延迟导致 endpoint 刷新不及时,请求依然会发送到由于缩容已经被销毁的pod上导致连接失败
应用的某个 pod 因为一些原因,比如调用数据库失败,无法处理请求。
通过 istio 的离群检测(故障转移)outlierDetection 能力来缓解或解决上述问题。
在 tcp 层面尽快连接超时,在云内200ms都无法建联我就人为它有问题了;
是在 http 层面根据 http 状态码检测,识别到有问题的 pod。将有问题的 pod 做离群处理。(这里需要注意的是根据 http 状态的故障转移规则需要标准化使用状态码,尤其是 5xx 的。这里要和研发对齐,比如参数错误不能返回5xx 应该返回 400等否则很容易引发不正确的故障转移,导致故障。)
3)金丝雀发布和访问控制
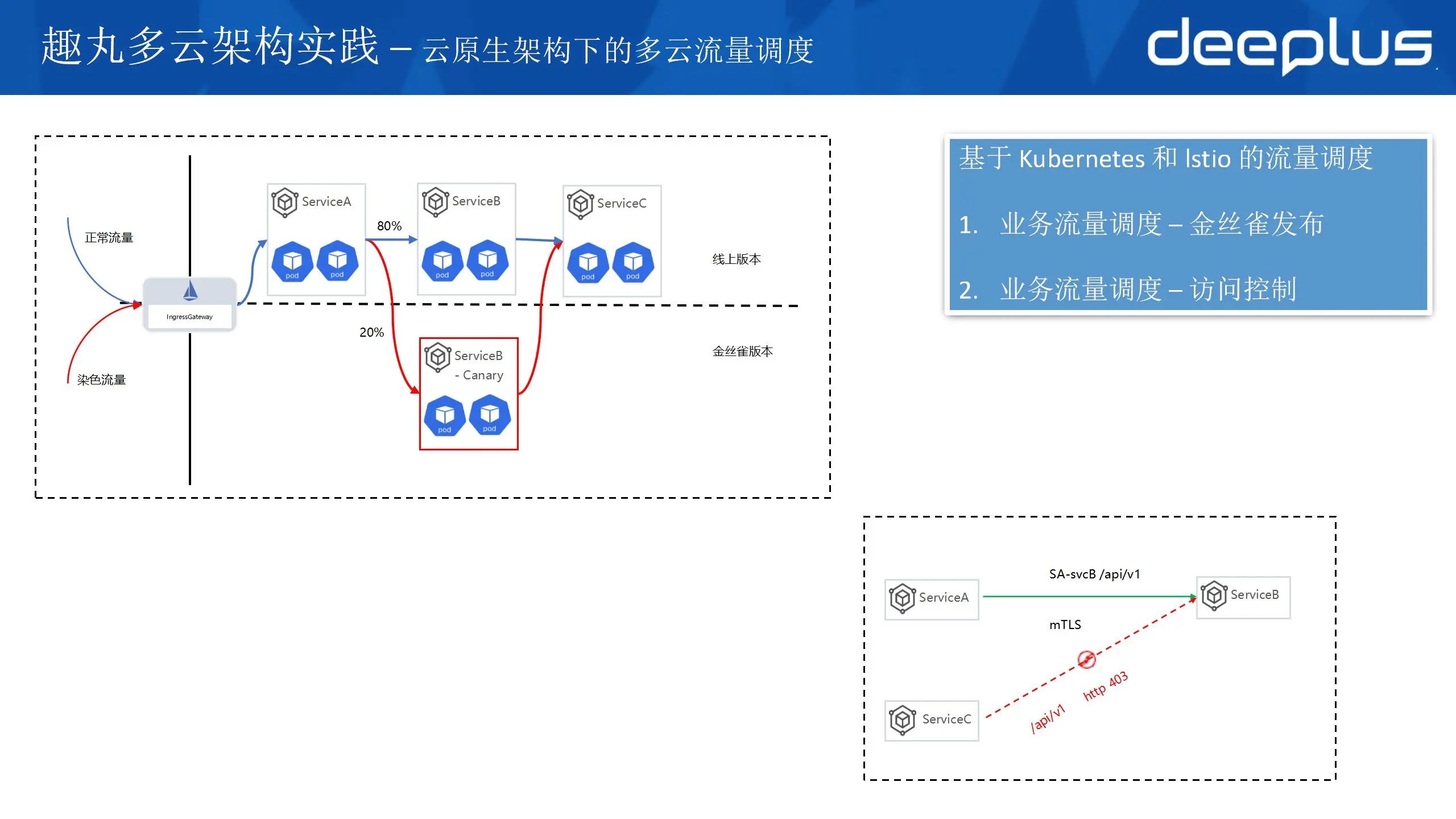
业务常见的发布方式是金丝雀,通过精确的流量分割和控制,逐步将用户流量从旧版本转移到新版本,可以很好的控制更新过程中可能出现的故障影响范围。通过精确的流量分割和控制,逐步将用户流量从旧版本转移到新版本,可以很好的控制更新过程中可能出现的故障影响范围。
金丝雀发布与多云关系不大,这里拿出来讲的原因是 istio 提供的金丝雀能力非常强大,可以非常方便的的解决全链路金丝雀流量调度的问题。istio流量染色可以根据业务标记(最常见的是 http 头)将流量调度到集群金丝雀版本中,并且可以精确的控制流量百分比。
通过 mesh 打通,可以方便的跨集群访问,在带来方便的同时也存在未授权访问的安全风险。Istio本身提供了非常好的无入侵的安全防护能力,主要体现在2个方面:
Istio集群默认开启 mTLS 功能,网格内的流量访问都是经过 TSL 加密的
Istio 提供基于授权策略的安全防护能力,可以精确控制服务之间的访问
基于授权策略的安全防护能力提供了非常丰富的访问控制能力,可以基于SA,请求接口(path),namespace 等属性进行访问控制。实现应用级别的安全访问边界(零信任)。
3、多云异构可观测实践
遥测是云原生的一个新要素,是质量保障的关键环节,趣丸通过集成不同云平台的监控工具和日志系统,实现统一的数据收集和分析,在上层屏蔽云商差异从而优化运维效率和提升决策质量。
1)基于Prometheus的多云异构可观测方案
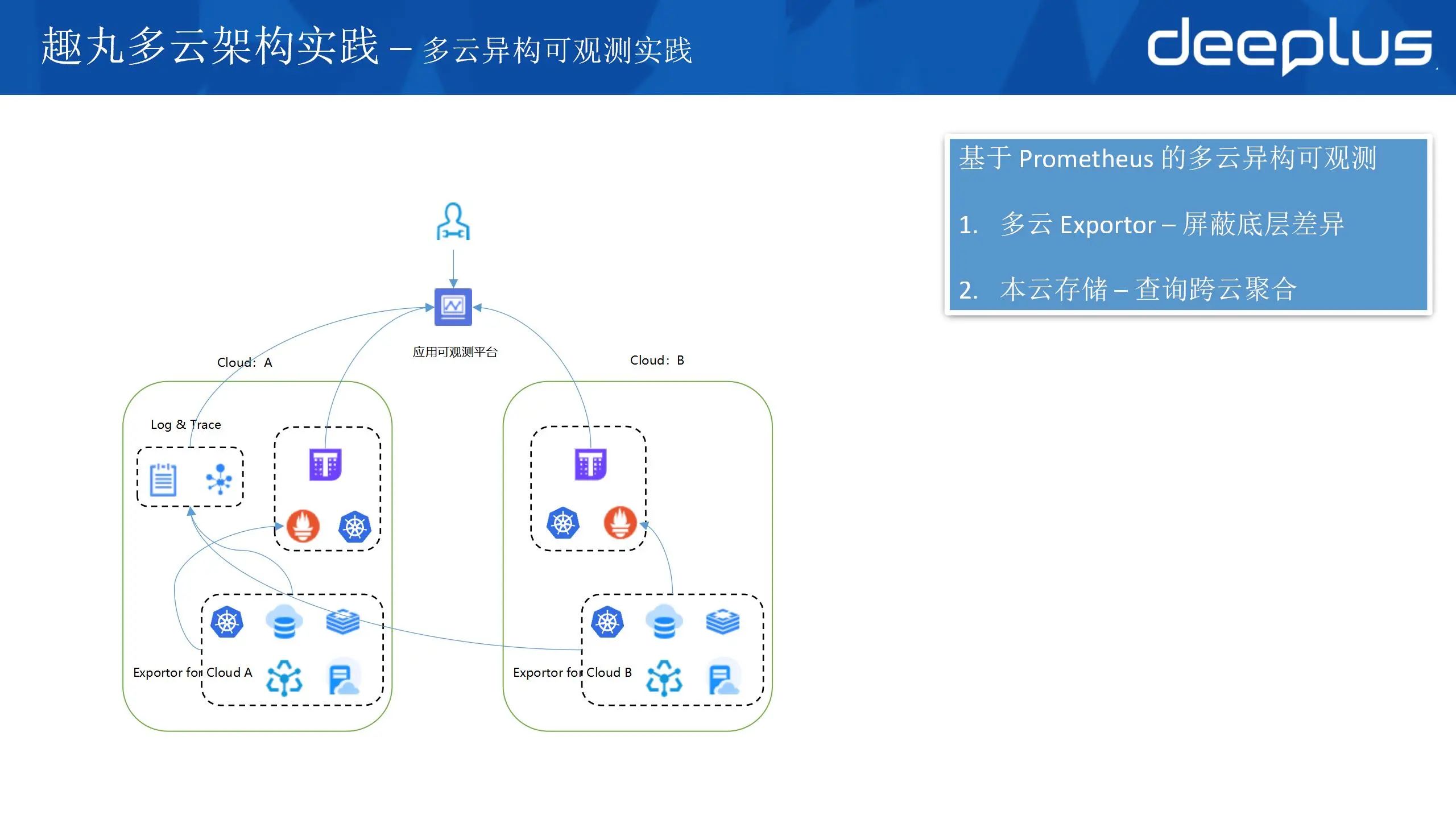
可观察包含三个方面:监控、日志、追踪链。并且可观测的数据有个特点,写入量大,实际使用少。大部分情况是业务出现问题时才使用,尤其是日志数据。所以大量的写流量都走专线不合适。整体方案是就近存储,本地计算,跨专线聚合查询。监控指标数据我们是通过 Prometheus 自建的,实现就近存储,跨专选聚合查询。日志和追踪链使用的云产品,无法做到就近存储,所以对专线带宽有很高的依赖。
解决多云产品异构的问题,思路也很简单,就是开发一套 exporter ,每种产品通过统一的标签存储到 Prometheus 中,屏蔽底层差异,作为可观测平台的数据基础。这样做也带来了问题,云产品是非常多的,不同云之间的差异也非常大,导致新云接入时可观测能力的支持需要投入大量的人力。
我在想CNCF可以制定一个标准来约束云商对于产品指标暴露的一个规范,降低企业使用多云的投入。
2)以应用为中心的观测能力
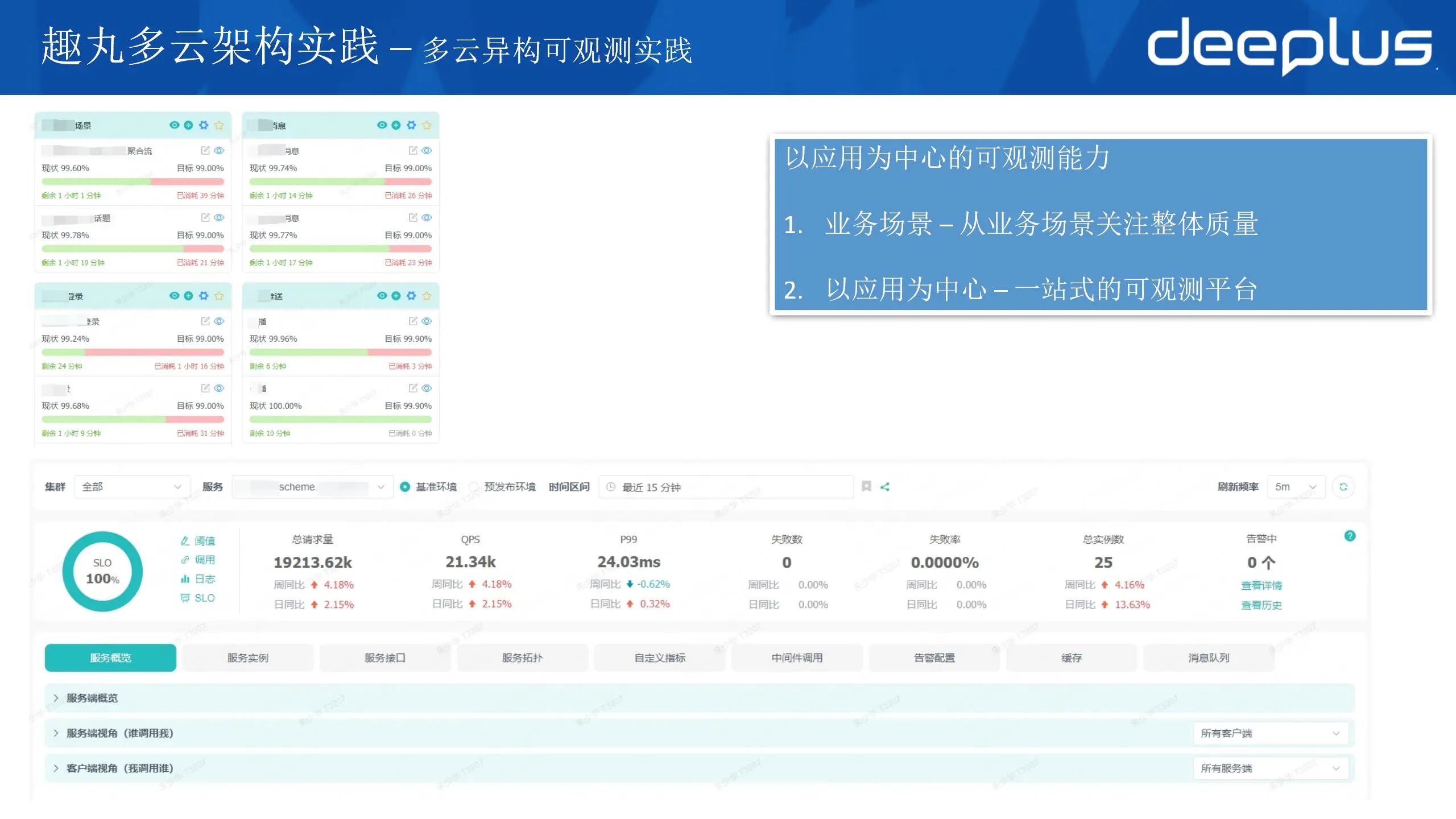
有了数据的支持,结合以应用为中心的理念,将应用与人、资源、告警、指标、调用链、日志进行关联,构建一个以应用为中心的的可观测平台。将质量相关的数据信息汇总到一起,排查问题时就不需要登陆到各个平台去收集信息,形成一站式的可观测平台。
我们的可观测平台实现了宏观层面-业务场景层面和微观层面-具体服务/接口 两个层面的质量展示,可以更直观的发现问题。
三、展望

多云架构还有很多挑战,针对业务的需求,再结合云原生技术的发展方向我总结了4点:
接入层,在前面没有做接入层流量的介绍,现状还是传统的高防接入,后续的一个演进路线是通过 httpdns 的快速收敛能力 + 智能 DNS 的检测,快速切换入口的方案来替换高防方案。
数据层,跨云容灾,多云多活 这方面我们在去年有过一些探索,出于规模和成本的考虑当前处于停滞的状态。我们也在思考如何通过云原生的能力来解决。
流量调度,istio本身提供的流量调度已经足够强大,但是 wasm 能力的加入让 istio 在精细化流量控制方面有了更多的可操作空间。
可观测,eBPF 在可观测能力上有了更多可能。

