Fileset:小米 AI 数据管理平台落地
01 概念释义
1. AI 数据
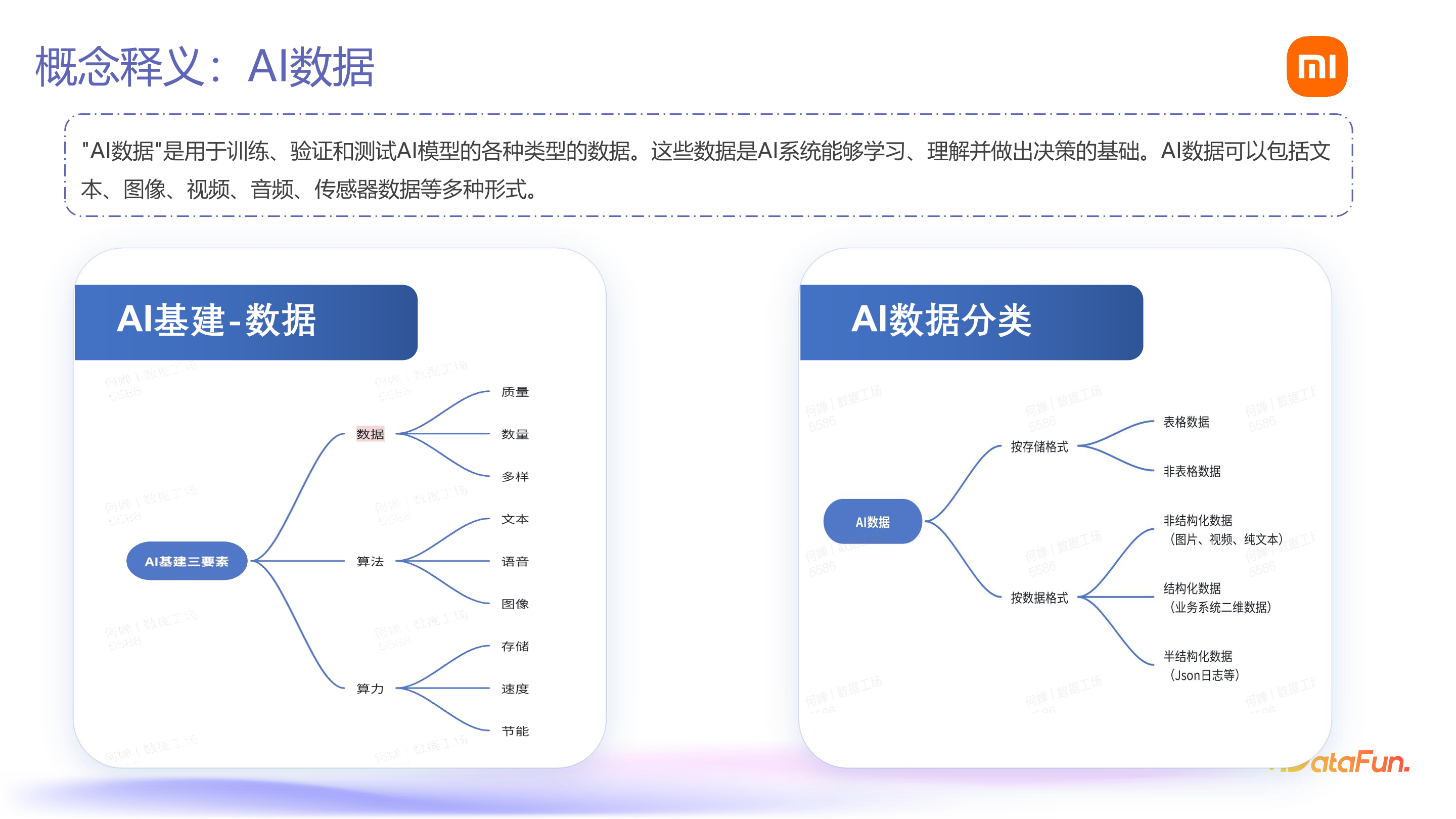
AI 数据,是用于训练、验证和测试 AI 模型的各类数据,是 AI 系统学习、理解和做出决策的基础。AI 数据包括文本、图像、视频、音频、传感器数据等多种形式。AI 基建中包含数据、算力、算法三个要素,以支撑人工智能的相关应用。AI 数据正是AI 基建的要素之一。
按照存储格式分类,AI 数据可分为表格数据和非表格数据。按照数据格式分类,则包括结构化数据、半结构化数据和非结构化数据。
2. 非结构化数据
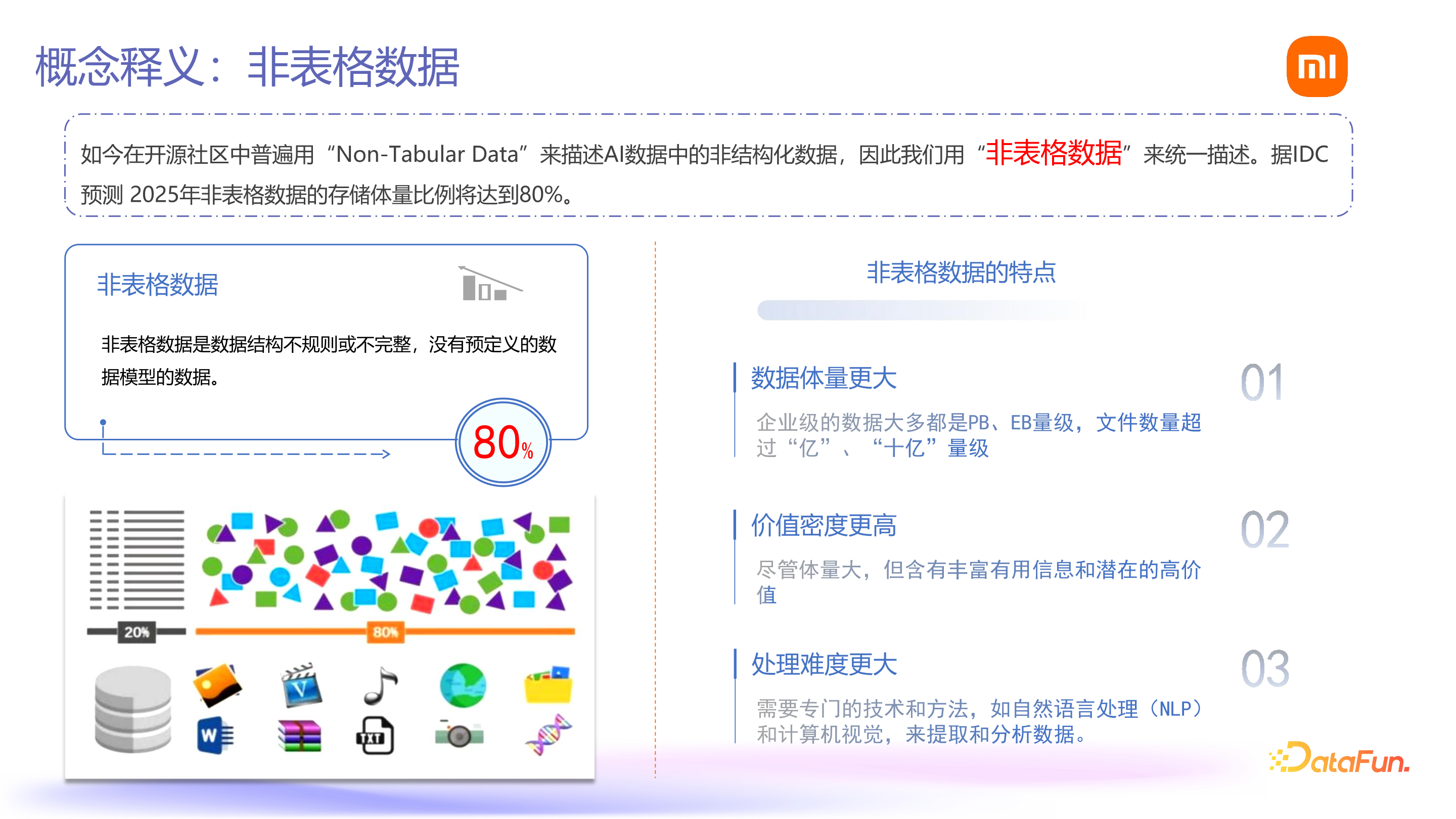
在开源社区中,AI 数据中的非结构化数据已使用“非表格数据”来描述。以往在大数据领域的处理对象一般都是指表格数据,其数据量仅占整个数据体量的 20%。剩余的非表格数据(包括音频、视频、TXT 等非结构化数据)的预计体量将达到 80%。
非表格数据具有三个特点:一是数据体量大,企业级一般达到 PB 级别,甚至 EB 级别,文件数量可达亿级、十亿级,这个体量在表格数据中较少见;二是价值密度大,因其包含音频、视频等,能承载的信息量更多;三是处理难度大,表格数据可通过 SQL 进行处理和分析,而对于非表格数据,需要用到自然语言处理或其他机器学习方法,对技术人员的要求更高。
02 平台建设背景
2022 年 AI 的大爆发为 AI 基建的发展带来了机遇和挑战。数据作为 AI 基建的三要素之一,其高效、安全和智能成为 AI 基建发展的重要模块。这一外部趋势是促使我们进行 AI 数据建设的背景之一。

其次,结合小米内部的发展情况。以前我们更多聚焦于数据中台的表格数据相关的开发处理能力。基于这一背景,对于非表格数据的现状,我们开展了前期业务调研,总结了五个痛点问题。
安全隐私风险:大量数据资产存储在本地或在平台处理后下载到本地,存在数据泄露风险且无法有效监管,数据下载到本地后流向不明确。
数据使用效率低:小米内部存储系统众多,因没有统一的非表格数据管理,各业务系统根据自身情况选择存储系统,如 HDFS、FDS、FS、NAS、KS3 等。不同业务方直接对接系统,导致数据使用效率低下。
资产转让管理困难:由于缺乏平台能力,数据的血缘缺失,无法清楚知道数据的使用情况,哪些数据真正在用,以及每个文件的使用频率等,导致低价值数据难以治理,占用大量存储成本。
缺乏算法代码调试环境:本地调试代码后上传到训练平台,若代码执行不符合预期,需重复本地训练和上传的流程,代码开发到最终运行的流程复杂。
体系割裂:现有的 AI 体系与 Data 体系割裂,AI 使用数据时通过直接对接 HDFS 文件,而非通过更平台化的能力进行数据对接,导致使用上出现断层问题。

以上是两个背景,外部 AI 的发展以及内部 AI 数据管理存在的诸多问题和痛点,这促使我们需要在降低成本、进行 AI 数据治理、提高算法开发流程效率以及挖掘数据价值方面提供相应的能力。
03 平台方案设计
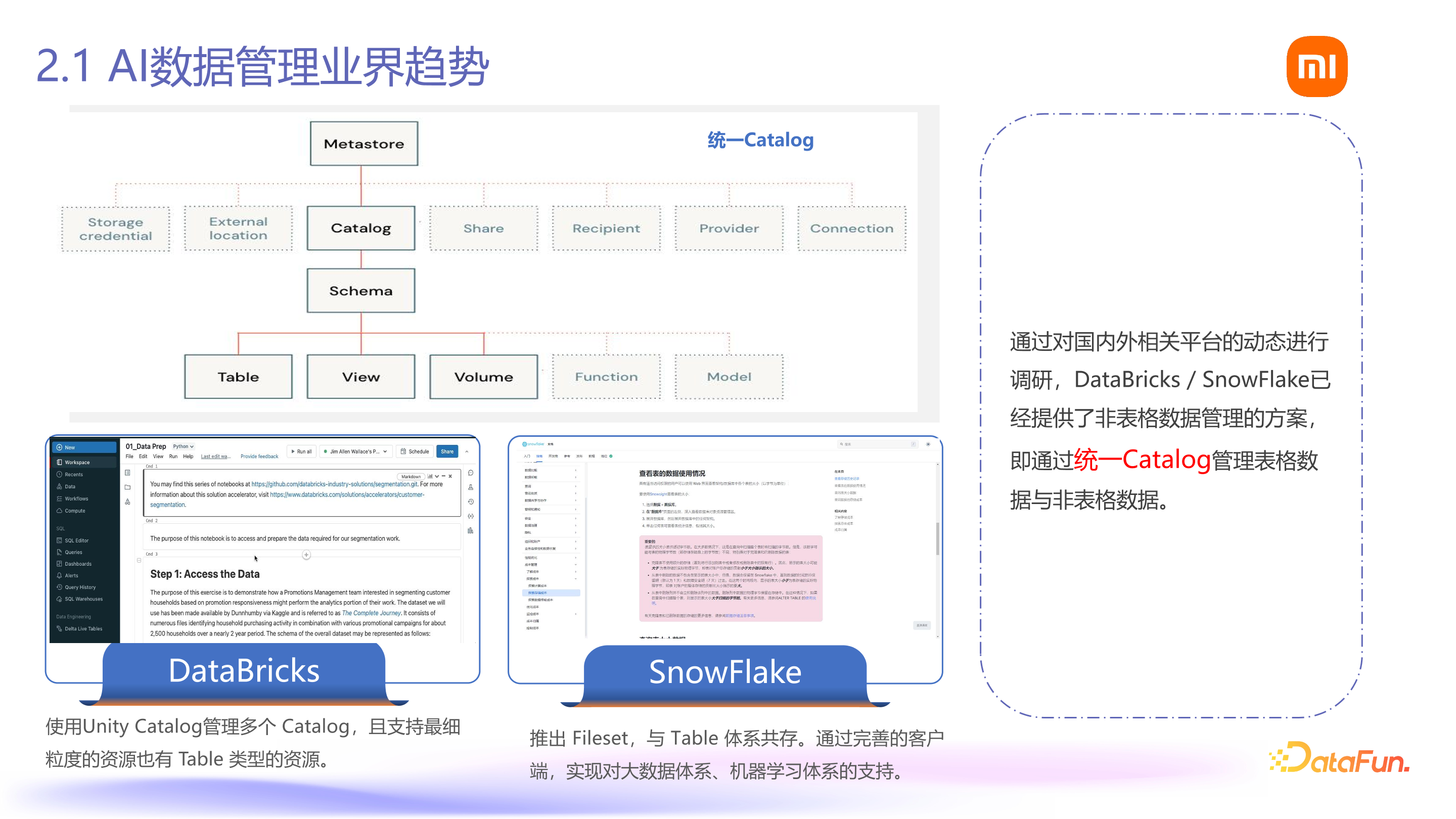
首先,看一下 AI 数据管理的业界趋势。在项目启动前,我们调研了许多平台,如 Databricks 和 Snowflake。Databricks 很早就使用了 Unity Catalog 的概念,将表格数据和非表格数据在统一的 Catalog 下进行管理。同样 Snowflake 也使用了 Fileset 的概念。如图所示,Databricks 有统一的 Metastore 存储,通过统一的 Catalog 管理表和 Volume 等文件数据,表格数据和非表格数据在一个体系下进行管理,这是业界关于 AI 数据管理或 Data 与 AI 在数据上融合的趋势。
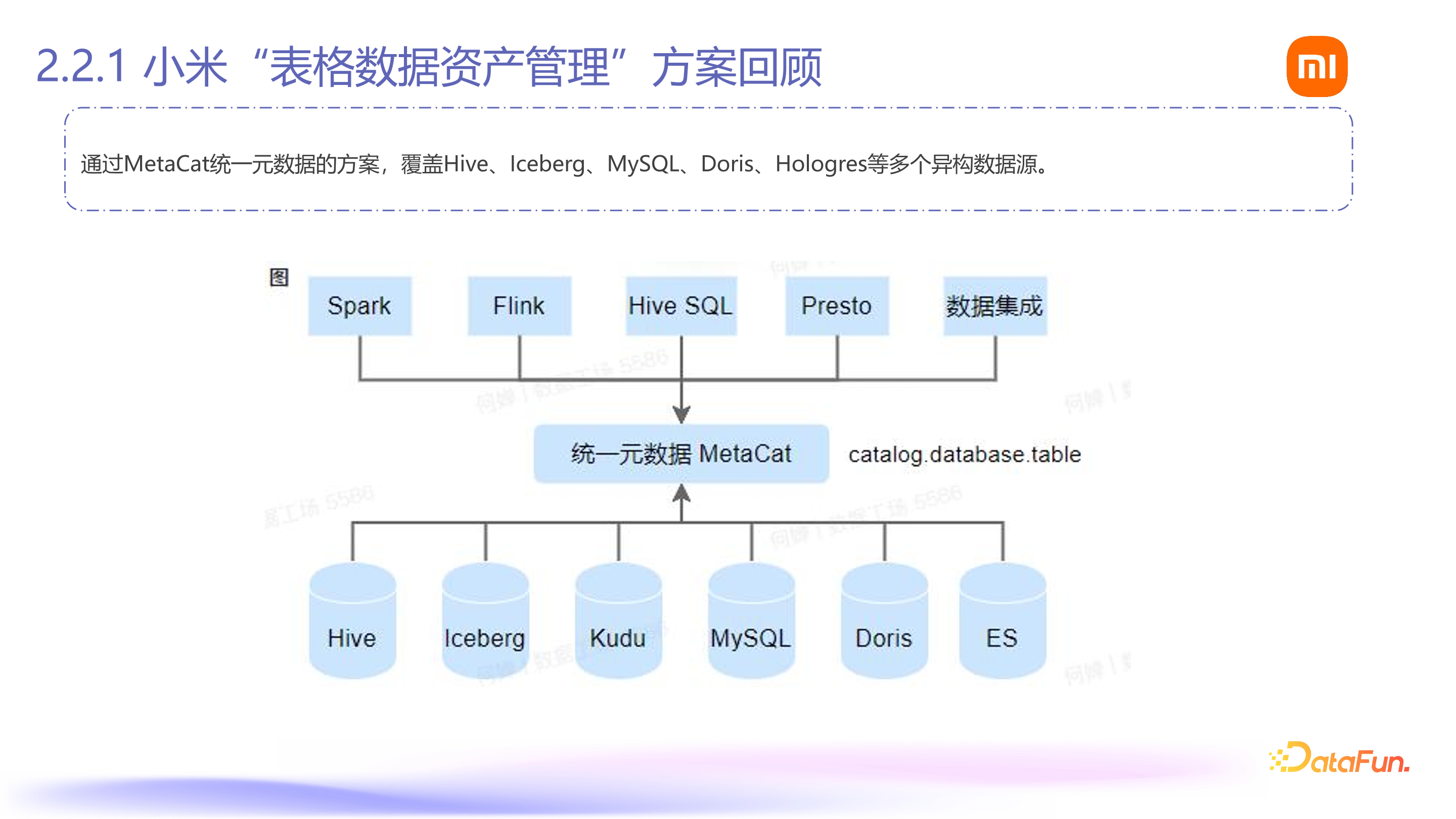
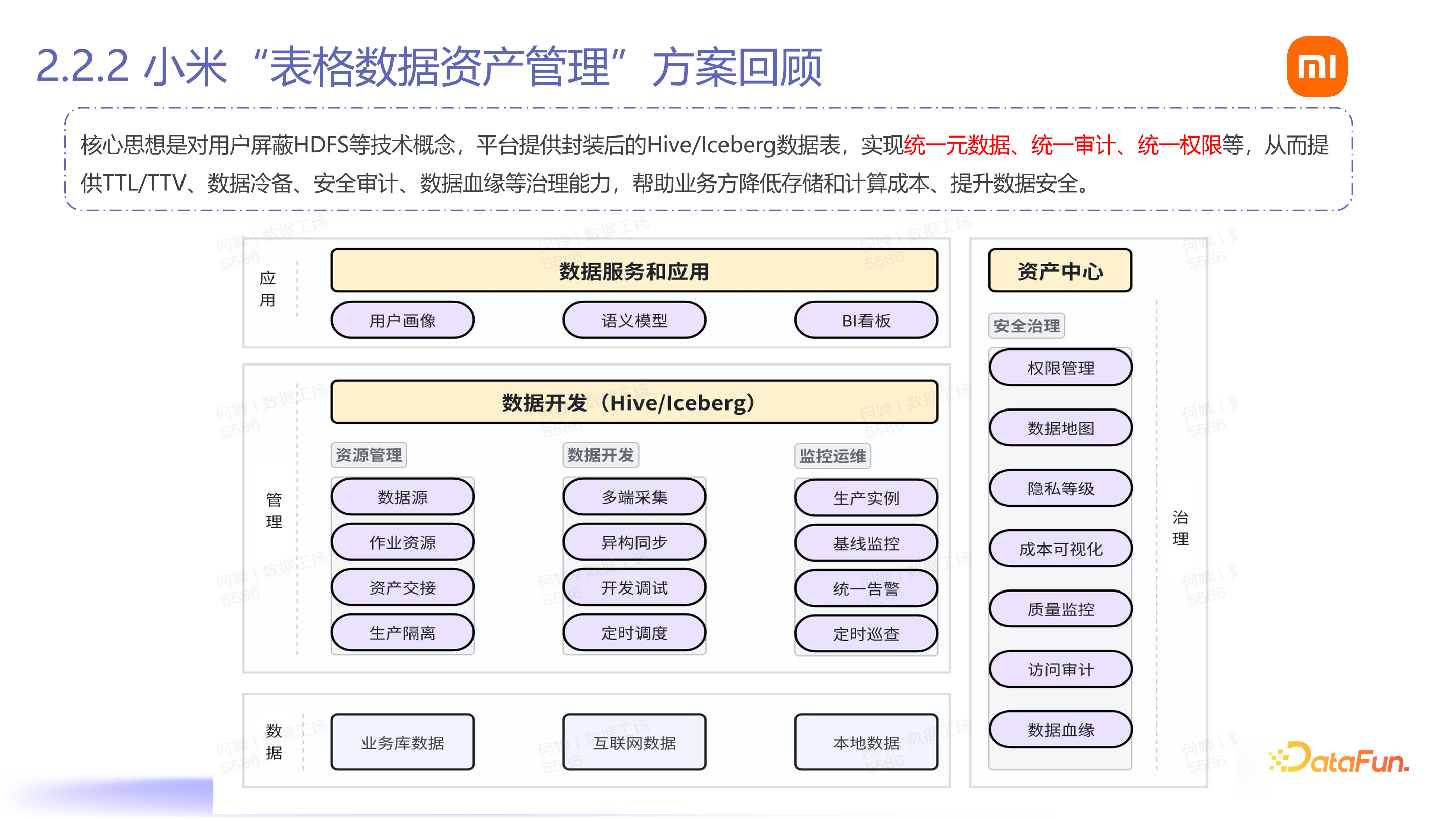
小米的现状是,此前在做表格数据治理时,内部有许多存储系统,如 Hive、Iceberg、Doris、MySQL 等,不同存储系统存在难以审计、追查,权限割裂不统一等问题。当时提出的方案是用统一的目录名 MetaCat,将所有表(如 Hive 表、Iceberg 表等)用三元组的形式进行统一,由三元组在数据管理平台上进行管理,再与上层引擎(如 Spark、Flink 等)进行数据运算处理。有了统一 Catalog 后,能够进行各种权限审计和跨数据源的数据治理。
基于此技术方案,我们有一个产品结构。底层有表格数据相关的数据体系,将数据集成到数据管理平台上进行资源管理、数据开发、监控、运维等管理能力,基于这些管理能力提供数据应用,如常见的 BI。在数据开发场景中,进行数据仓库的处理,然后提供上层 BI 应用,同时旁边有整个资产中心,对表格数据进行权限管理、审计、成本可视化、数据质量监控、访问审计、数据血缘等能力,以确保数据开发过程中的成本、安全和治理能力。这是小米在表格数据资产管理方面的经验。
对于 AI 数据管理,我们结合业界趋势,将 Data 与 AI 进行融合,数据与算法流程进行融合,实现非表格数据或 AI 数据的可追溯,知道每个文件的使用情况、管理方式以及如何进行数据治理,联通整个AI 与 Data 的开发链路。基于这四个点,我们提出了小米的存算管治方案,即 Fileset。
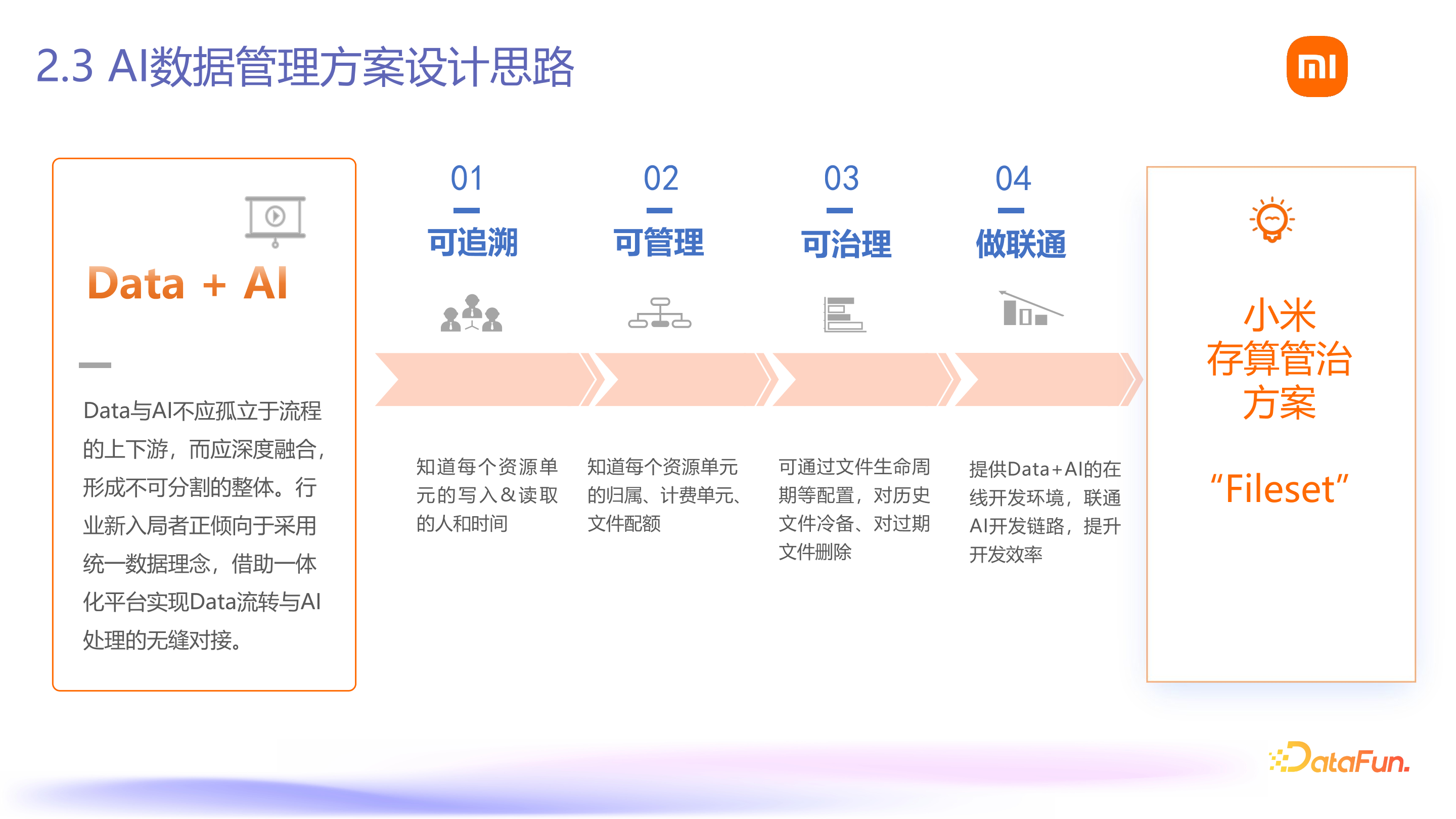
我们有四个设计原则:
第一,方案要满足业务现有降低存储成本和提高算法流程的需求;
第二,兼容业务已有的用法,避免提供与现有用法割裂的方案,导致使用或迁移成本过高,难以推动新方案;
第三,能够快速落地,考虑使用哪些引擎的能力以及与开源社区的协作方式;
第四,方案要具有先进性,能满足长期业务发展,包括表格数据和非表格数据的协同发展。

基于这四个设计原则,最终 Fileset 的方案有两个关键点:
首先,我们在现有的大数据开发平台中引入了 Fileset,对数据进行封装,而不是创建一个新的平台。在现有的表格数据管理系统中,我们融入了 Fileset 的非表格数据管理能力,实现数据的统一治理和追溯,从而建立数据的连通性。那么,如何实现这种统一呢?如左侧下方图示所示,我们将所有数据纳入一个统一的元数据系统。原有的表格数据通过一个三元组的目录(Catalog)进行管理,现在我们也将 Fileset 的数据整合进来,涵盖 HDFS、JuiceFS、FDS 等各种存储系统。用户无需了解底层的复杂性,只需知道 Fileset 本质上是一种特殊的表,它兼具了表和文件的属性。
其次,我们需要提供相应的开发能力。在传统的表格数据管理过程中,无论是数据出仓还是数据处理,我们通常只需使用 SQL 语言。然而,在涉及算法流程时,仅使用 SQL 语言是不足够的,我们还需要更多的编程语言支持,如 Python 和 Scala。在底层数据层面,我们不仅需要处理表格数据(Table),还需要处理 Fileset(即非表格数据)。这些数据都需要在统一的数据管理平台中进行管理,并通过 SQL、Python、Scala 等语言进行处理,从而支持模型训练。因此,我们建立了一个综合的开发能力体系。
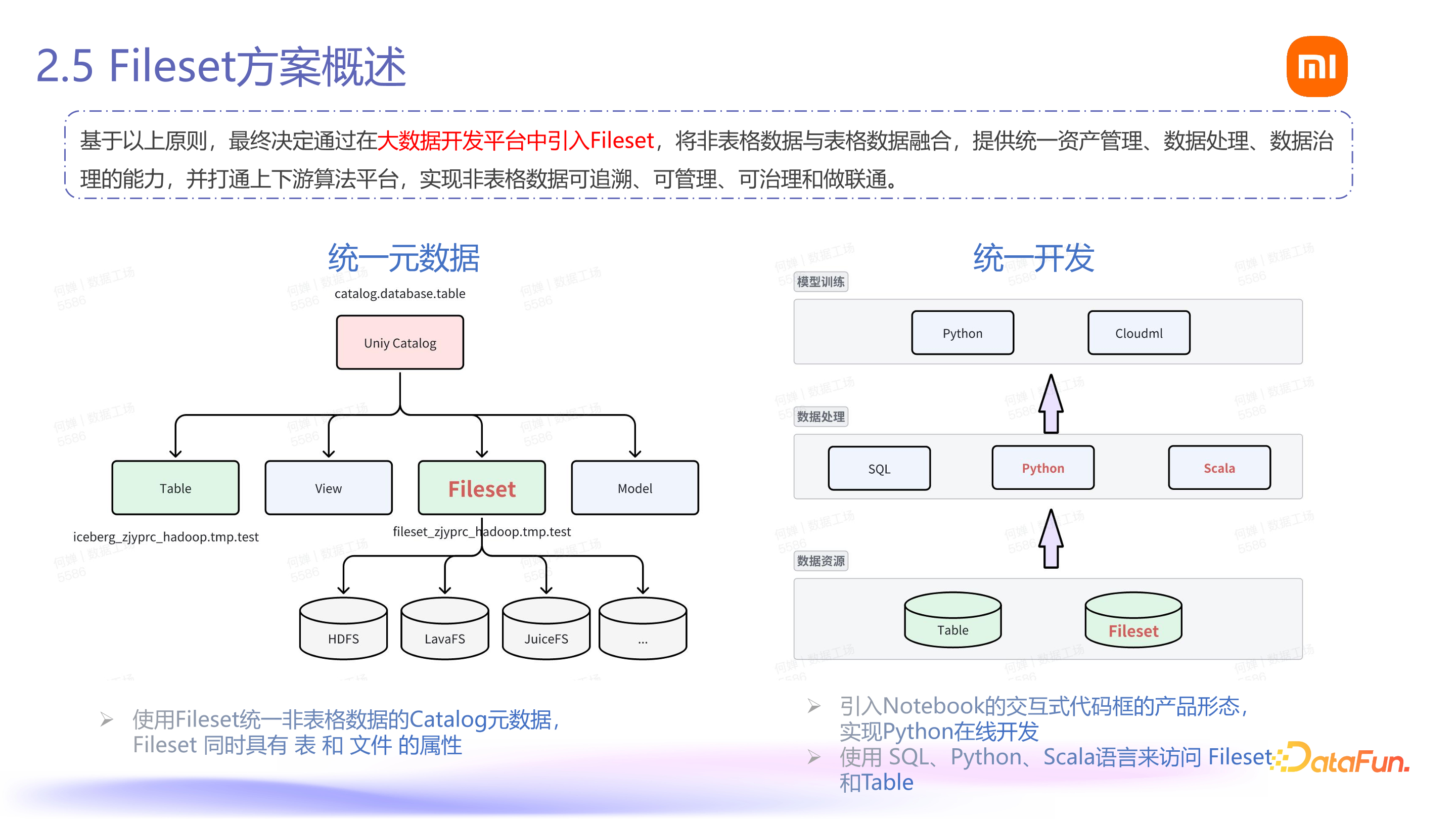
以上就是关于 Fileset 方案的整体概述。
04 平台落地实践
Fileset 在小米内部是如何落地的呢?其中涉及四项核心能力。
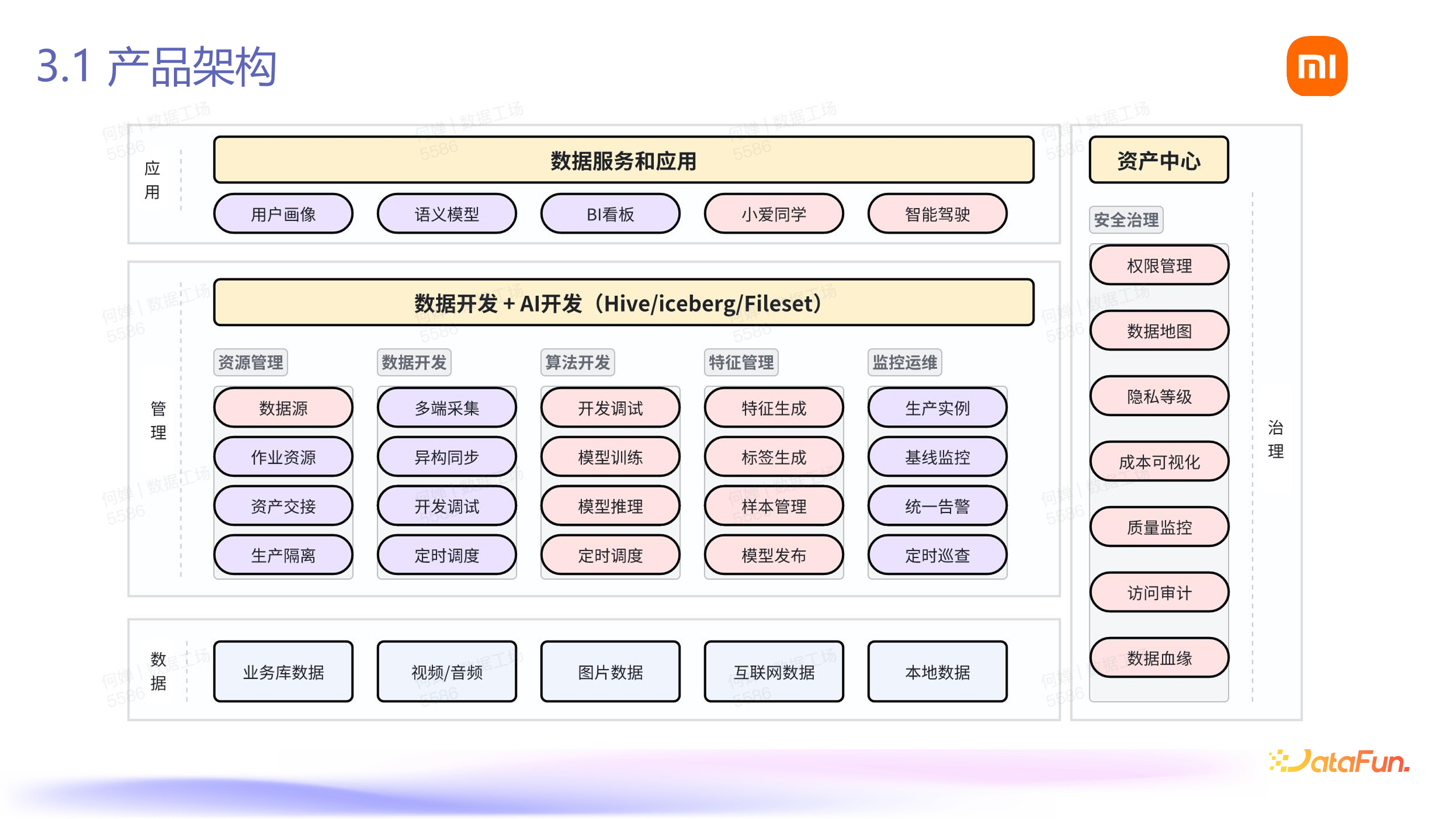
首先,非表格数据是在表格数据的基础上进行融合的。从架构上看,我们在各个能力上,如数据源能力、开发能力上融入了非表格数据,应用方面除了原来的 BI,还包括小爱、智能驾驶等各种应用能力,都是在数据管理能力基础上进行的。所有资产的能力也都融入了非表格数据相关的能力。具体来说,Fileset 的创建具有以下价值:能够屏蔽掉 HDFS 的概念,规范文件使用。例如,限制文件路径为三层,避免用户直接对接 HDFS 时路径混乱(三层到十几层不等,且一个 HDFS 附目录下可能有亿级别的子文件),提升每个 Fileset 的可复用性。
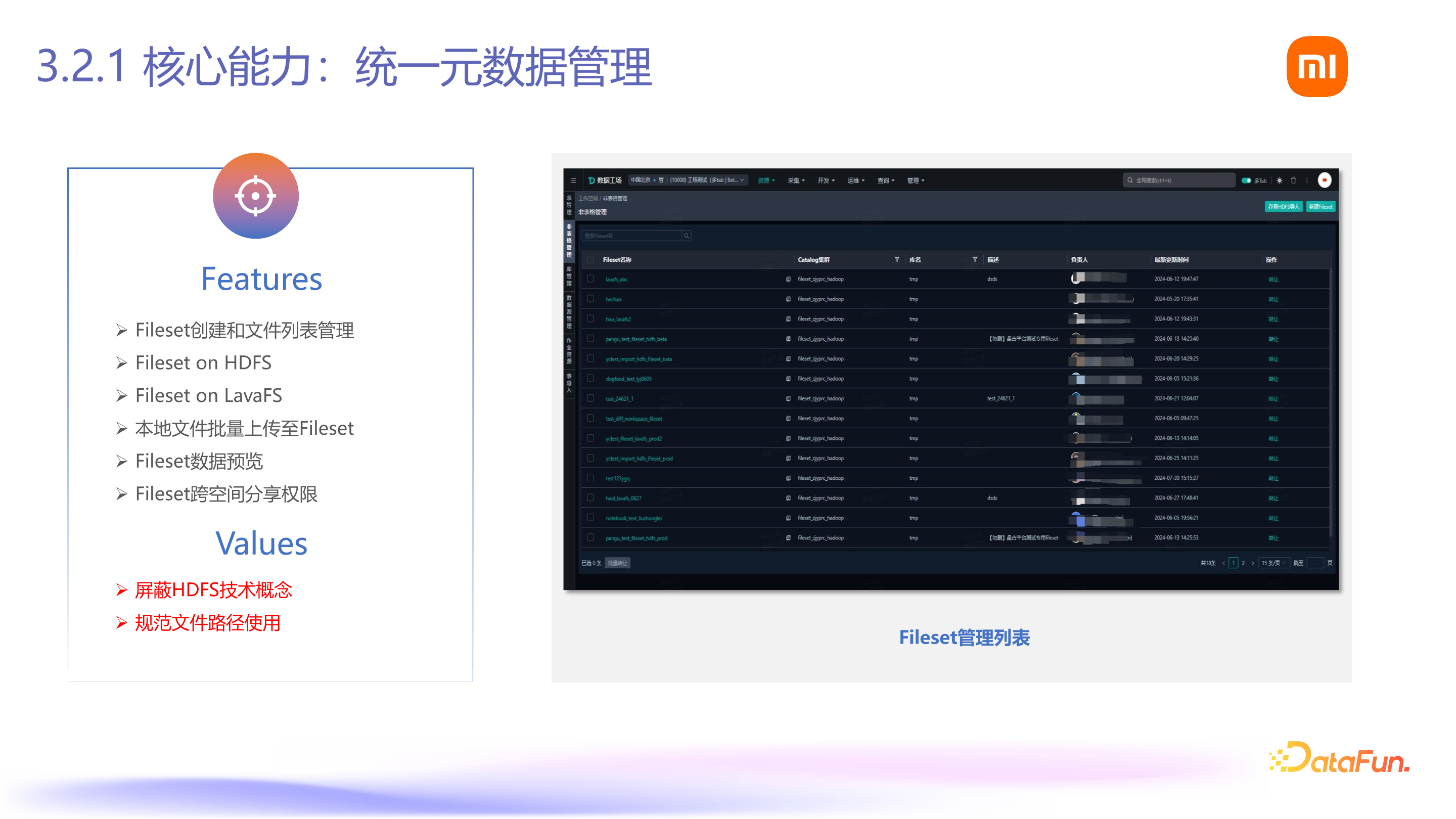
其次,我们提供了 Notebook 的在线开发能力,以前使用 SQL,现在提供 Python、Scala 等开发语言的能力,Notebook 的交互式开发产品已在内部平台落地,其价值在于提供算法开发的调试环境,后续还将提供 GPU 资源,用户无需在本地使用其他机器或跳板机进行算法处理,可直接在平台上进行算法开发。

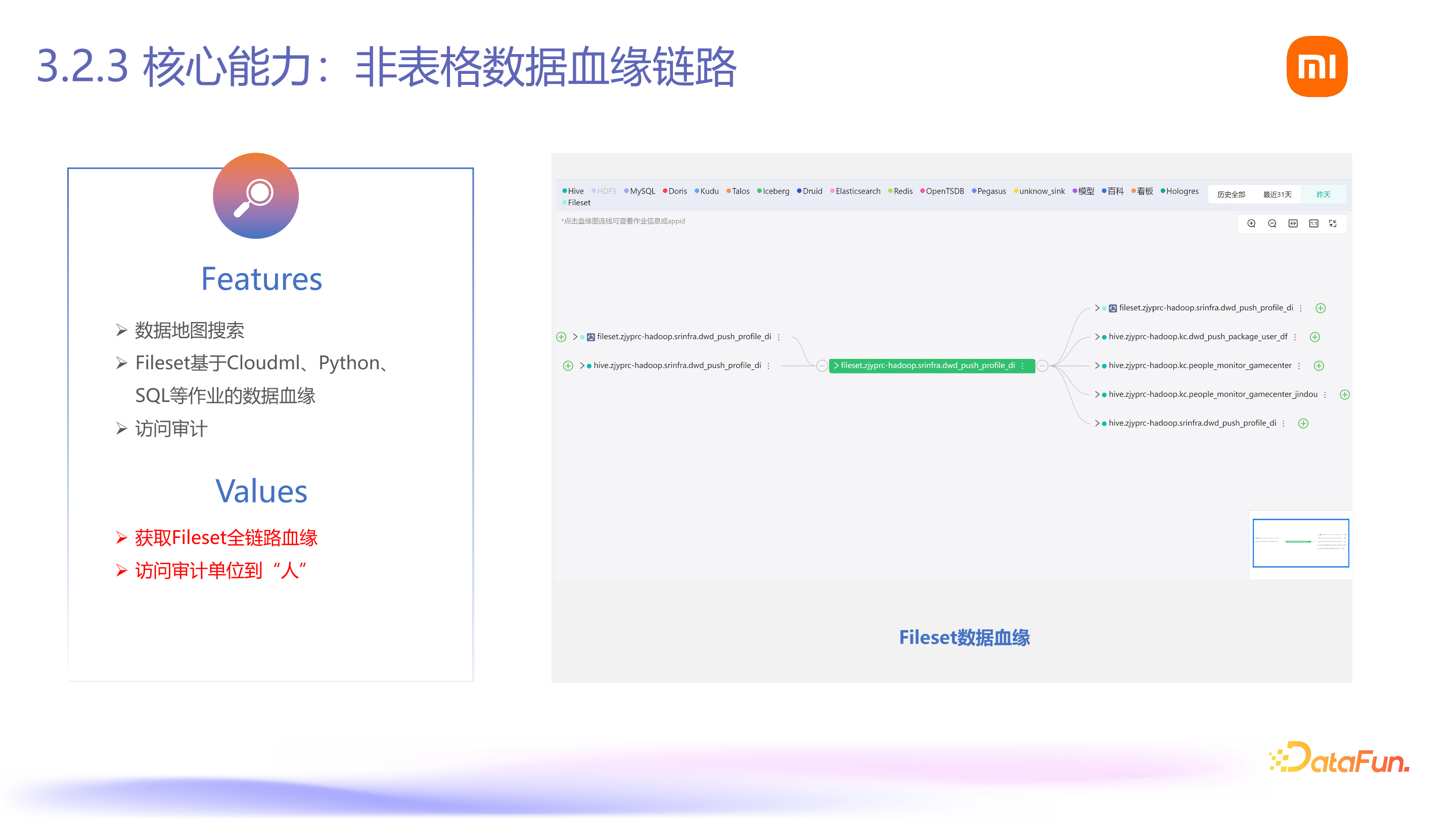
第三个核心能力是对非表格数据进行治理,这一点在前面也有所提及。我们需要明确某个数据或具体文件的使用情况,例如它涉及了哪些作业,来源于哪些表格数据,以及下游数据的去向。通过建立这样的数据血缘链路,我们能够更好地进行数据治理。因此,我们的产品方案中包含一个数据血缘图,展示了上游数据来源和下游数据所依赖的表格信息。此外,该图还显示了在线作业的具体使用情况和所涉及的作业内容。具备这种数据血缘分析能力后,我们就可以进一步优化和处理数据。
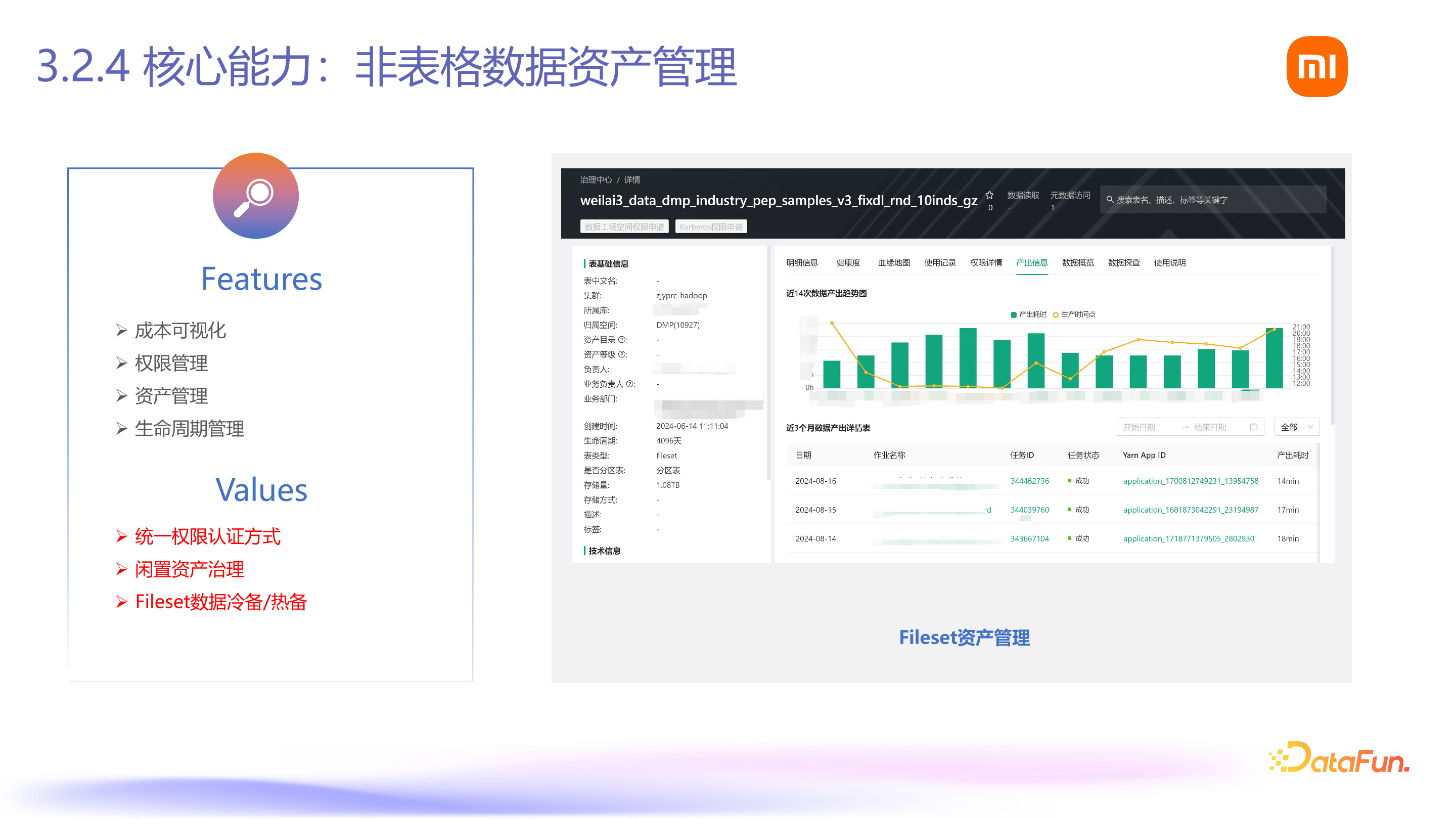
最后一个核心能力是非表格数据的资产管理,包括成本管理、权限管理和生命周期管理等。有了这些能力后,我们能够对用户的文件进行统一而全面的管理。对于闲置的资产(例如存储了多天的大量文件),我们可以采用类似于表格数据的管理方式,例如 TTL 生命周期管理和 TTV 来完成数据的冷备和热备管理。总体而言,我们的思路是基于表格数据治理的经验,进一步扩展到非表格数据的管理能力。
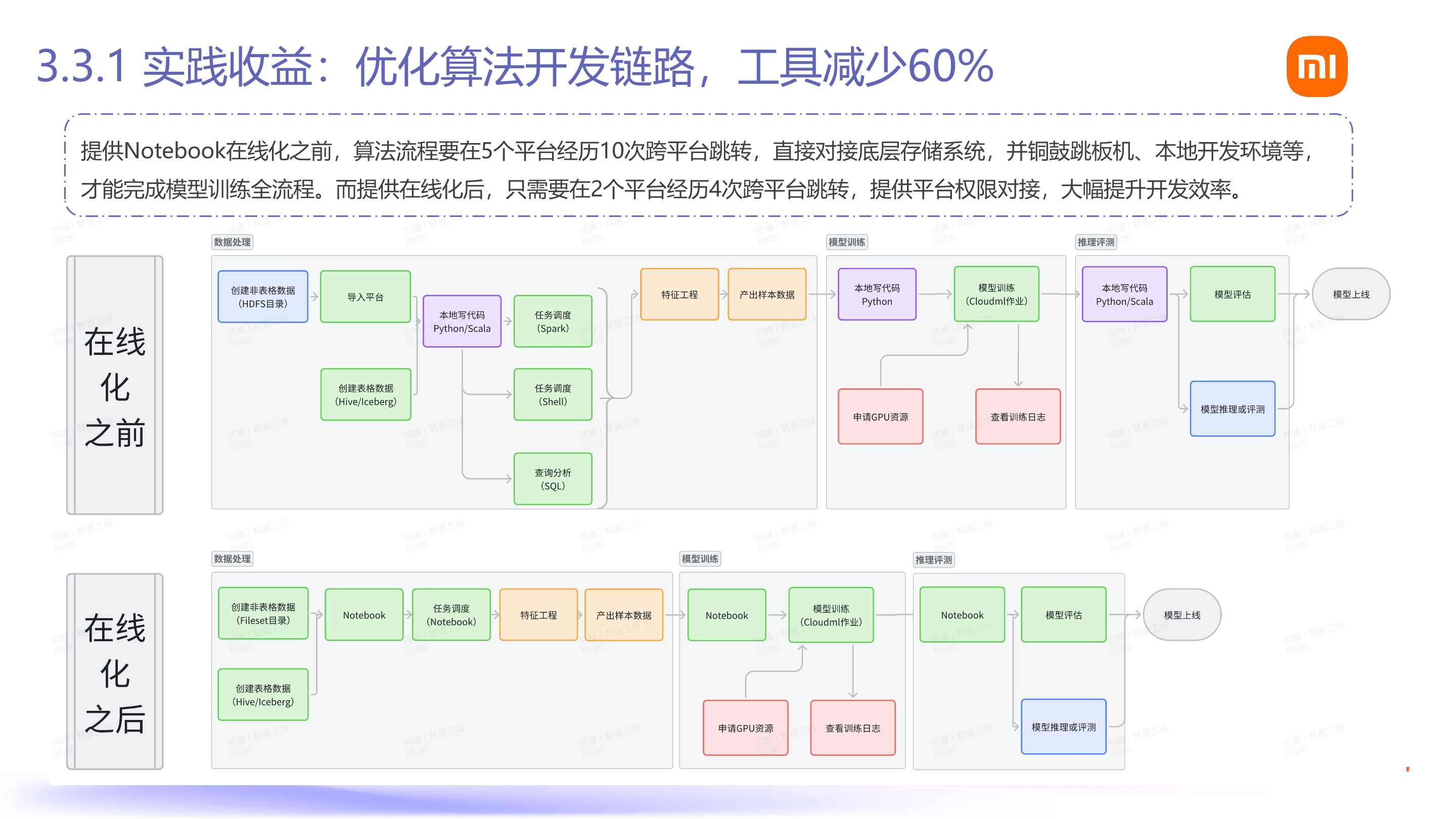
功能落地后,在业务上取得了以下收益:
一是链路减少,效率提高。通过提供 Fileset 和 Notebook 的方案,原链路较长,需要多次在本地和线上之间跨平台操作,每个跨平台流程都需要单独进行认证。在线化后,所有东西都在一个管理平台上完成,除了特征平台可能有单独平台外,所有 AI 数据处理流程都在一个平台上,统一用 Fileset 进行对接和权限空间权限的对接。用户无需直接对接存储系统,只需要知道 Fileset 这个类似表格的概念,无需跳板机和本地开发环境,可在开发平台线上完成。
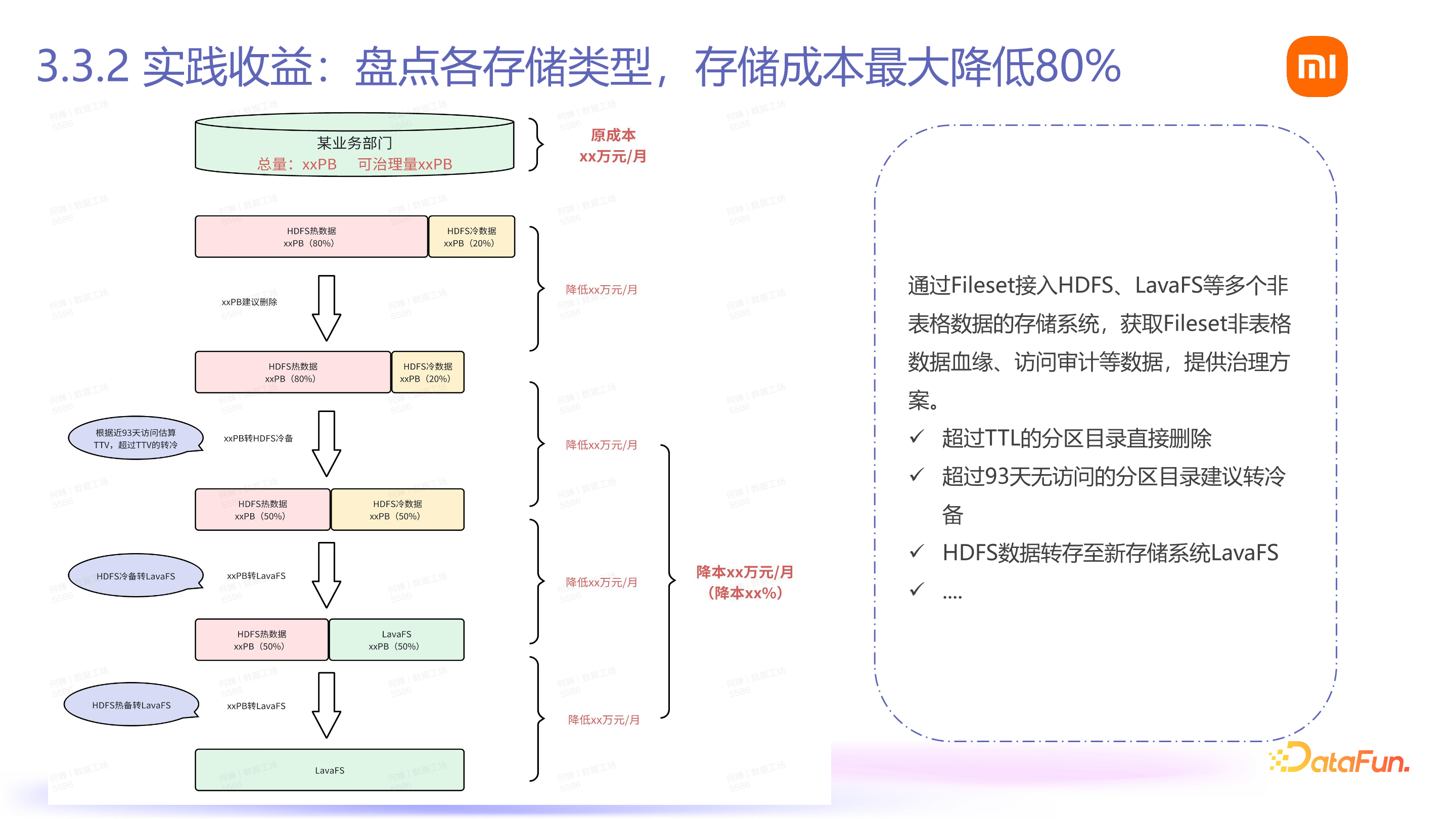
二是成本降低。如图所示,某内部业务中,在有了血缘和审计能力后,能明确哪些 PB 的数据可以删除,哪些可以冷备,哪些需要转移到另一个存储系统(如小米自研的 LavaFS 存储系统)。经过内部算法处理,LavaFS 存储系统的存储成本理论上比 HDFS 降低 80%。用户只需要知道 Fileset,无需知道其下面存储的数据和存储系统,就能大大降低存储成本。通过 Fileset 概念,查找数据的访问情况、数据血缘情况和使用情况,才能对非表格数据进行各种数据治理。
05 总结与未来规划
最后对本次分享进行一下总结,并介绍一下 Fileset 的未来规划。
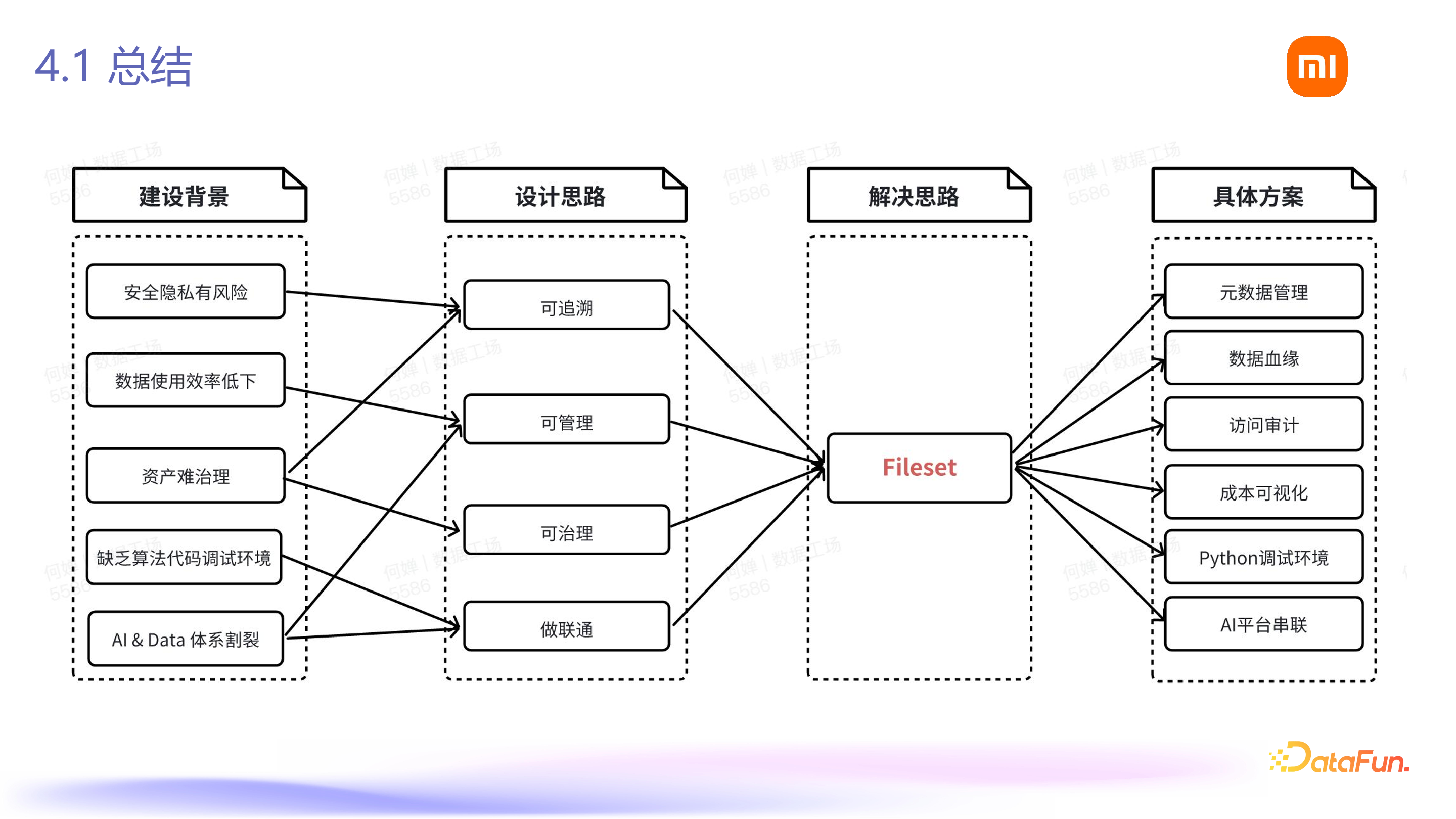
回顾整个分享的思路,我们从建设的背景出发,讨论了设计的理念。背景主要包括安全、效率、治理、环境以及体系分类等问题。在此基础上,我们提出了设计思路,希望实现数据的追溯、管理和治理,同时建立数据上下游的连通性,最终形成了整体解决方案,即 Fileset。在 Fileset 的框架下,我们考虑到小米目前表格数据处理的现状,并在现有能力的基础上,开展元数据管理、数据血缘分析和数据访问等工作。我们将表格数据治理的经验,应用到非表格数据的管理方案中,这是 Fileset 相关产品建设的整体思路。
接下来,我们的工作重点有以下几个方向:
首先,目前 Fileset 主要对接的是 HDFS,未来我们计划逐步接入更多的数据源,例如 JuiceFS 等。我们会基于调研和用户使用情况,将这些数据源逐步纳入 Fileset,实现各种存储系统的统一,从而构建一个以 Fileset 为特殊表概念的统一存储系统。
其次,我们将提供一个基于线上的框架,包括对 PyTorch、TensorFlow 等用户常用框架的支持。我们的目标是在平台上逐步替代本地平台,形成一个统一的开发平台。
第三,我们将打通上下游的开发链路,实现 AI 应用平台、资源平台等多种平台之间的无缝衔接,避免用户在不同平台间频繁切换,并简化使用过程。
最后,我们将不断改进和提升产品体验。
以上是对小米 Fileset 的整体介绍。谢谢。

