得物自建Redis无人值守资源均衡调度设计与实现
一 为什么要做资源均衡调度
得物 Redis 管理平台目前管理着几百个集群、数万个 Redis-server 节点、几千台 server 宿主机,而且通过精细化运维管理,目前 Redis-server 宿主机平均内存使用率和内存分配率均达到一个合理且较高的水位,资源管理处于业内第一梯队,使用最低的成本做到最大的支撑业务缓存需求。
同时,随着业务使用量的持续增长,单台宿主机上的内存使用率越来越高,为了保证宿主机上所有节点的业务日常增长需求或者突发的业务内存上涨,以便能够做到秒级快速垂直扩容,以及添加节点、RDB 离线分析等功能需要的资源,单台宿主机的内存使用率都需要动态的控制在一个合理水位线以下,于是,Redis 管理平台会每天定期自动巡检所有宿主机内存使用率,对于超过合理阈值的宿主机,会选择一部分 server节点进行打散,迁移到其他宿主机上。
二 为什么要做自动化资源均衡调度
在 Redis 系统承接业务后,资源使用量快速增长的初期,逐步出现需要进行资源均衡调度的需求,一开始也是 DBA 手动进行节点迁移。为此还特意开发了一个批量选择节点进行添加从节点、主从切换、节点下线等批量操作功能。
然而即使提供了批量操作功能,手动迁移依然需要 DBA 每天投入相当多的精力来进行资源均衡调度,并且存在稳定性风险。
首先,需要 DBA 每天都要关注资源整体的使用情况,一旦出现内存使用率较高的机器,就需要进行打散迁移;
随着机器增多、Redis 服务承接的业务快速增长,每天需要打散的机器越来越多,每次需要打散的节点也越来越多,操作迁移花费的时间也越来越多,到后期差不多每周需要投入 2 人天的工时专门进行资源打散;
另外,由于人工操作,选择大量节点同时进行,难免出现漏操作、重复操作、误操作等情况,增加了资源迁移给集群稳定性带来的风险。
于是,Redis 管理平台设计并开发了无人值守资源均衡调度功能,为了尽量降低迁移过程对业务的影响,默认选择在凌晨5点业务低峰期进行执行,并且自动巡检、选择机器、选择节点、节点迁移等整个资源均衡调度过程均是每天定点自动完成。
迁移过程中怎么合理的选择一部分节点还是无脑随机选择几个节点,怎么保证迁移的稳定性是核心能力?
三 如何合理选择迁移节点
迁移过程的第一步是需要挑选内存使用率超过预设阈值的宿主机机器,并且挑选机器上部分节点进行迁移,使得这些节点迁移后,该宿主机内存使用率下降到合理水位线以下。
那么选择节点是不是无脑随机挑选一部分节点呢,理论上来说当然也没有什么问题,但是为了保证迁移过程对业务影响最小、且使得迁移后,所有集群节点分布更均匀,我们还是设计了一系列最优选择规则,选择最优节点原则包含:
优先节点数量多的实例节点,这样可以在资源均衡的同时,可以使得同一集群节点也更均衡,同一集群节点尽可能的分散到不同的机器上。
优先实例等级为非 P0 的实例。
优先从节点:从节点迁移对大部分业务(同城双活业务除外)都没有任何影响。
优先节点规格中等规格(1-4G)实例、再选择 1G-5G 规格实例、最后选择其他规格的节点;如果选择的节点太小,为了满足条件需要迁移更多的节点,如果选择的节点规格太大,迁移时加载数据时间更长,另外如果同时刚好对应节点的写流量比较大,加载数据时从节点连接池缓冲区写满会导致同步过程失败,也就是大规格节点迁移过程失败的概率更大。
不同时选择同一个集群同一个分组的节点。
选择节点算法流程图如下:
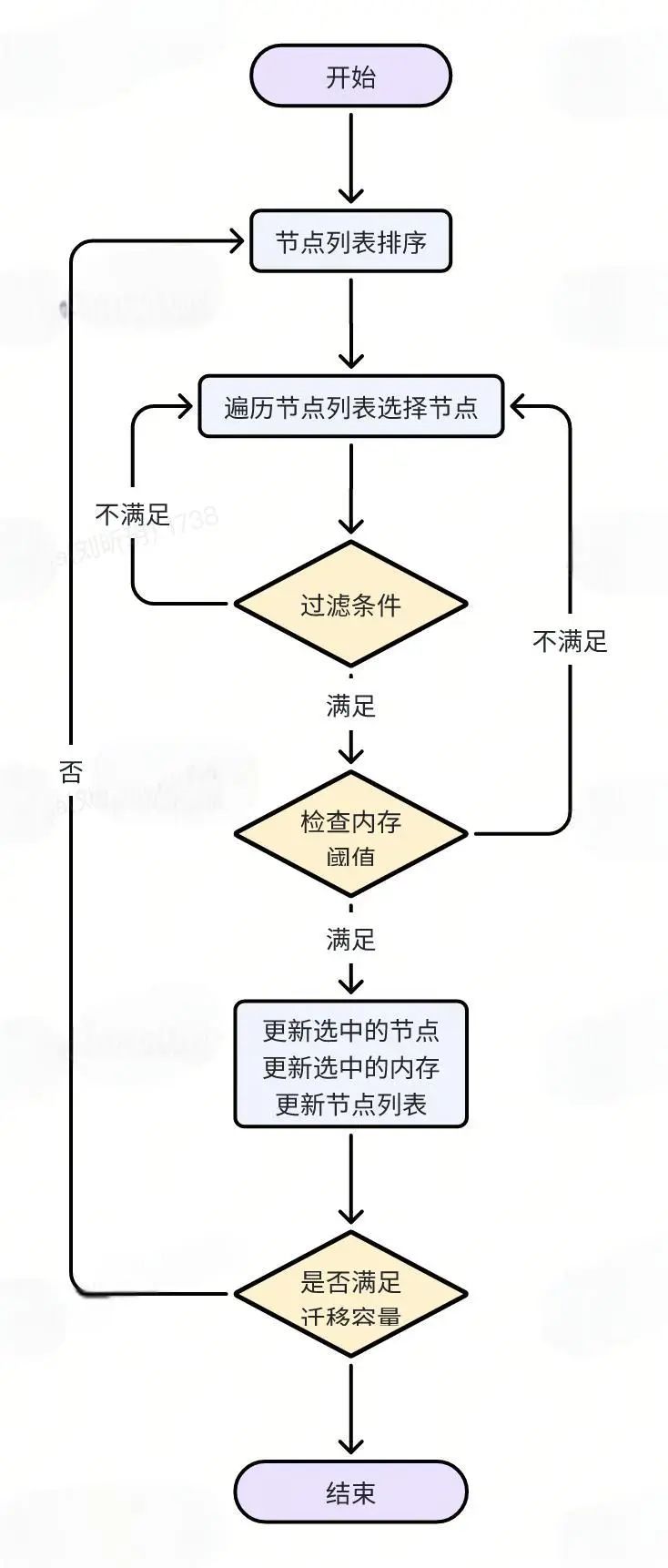
节点列表排序,对机器上所有 server 节点按照所属同一集群的数量和内存大小排序,从同一集群节点数量多的集群开始选择满足条件的合适节点;
前两轮选择中,均选择非 P0 集群节点,第一轮选择节点规格为 1-4G 的节点、第二轮选择节点规格为 1-5G 的节点;
第三轮选择则包含所有集群(即也包含 P0 集群)、节点规格为 1-4G 的节点;
最后如果还不满足需要迁移的节点内存,则按照遍历顺序直接选择任意节点;
每轮选择过程中,均避免同一集群同一个分组的节点同时选中。
节点选择完成后,按集群 ID 生成迁移任务,迁移任务默认每天凌晨 5 点定时执行,生成的迁移任务会同步发送给各业务域对应 DBA 确认,确认过程中可选择取消或者修改执行时间。
四 如何保障迁移过程中可靠性
等待执行的迁移任务到达设置的定时执行时间后,开始执行自动迁移流程,整个迁移过程包含添加从节点、主从切换、删除迁移节点等步骤。
迁移任务执行过程流程图如下所示:
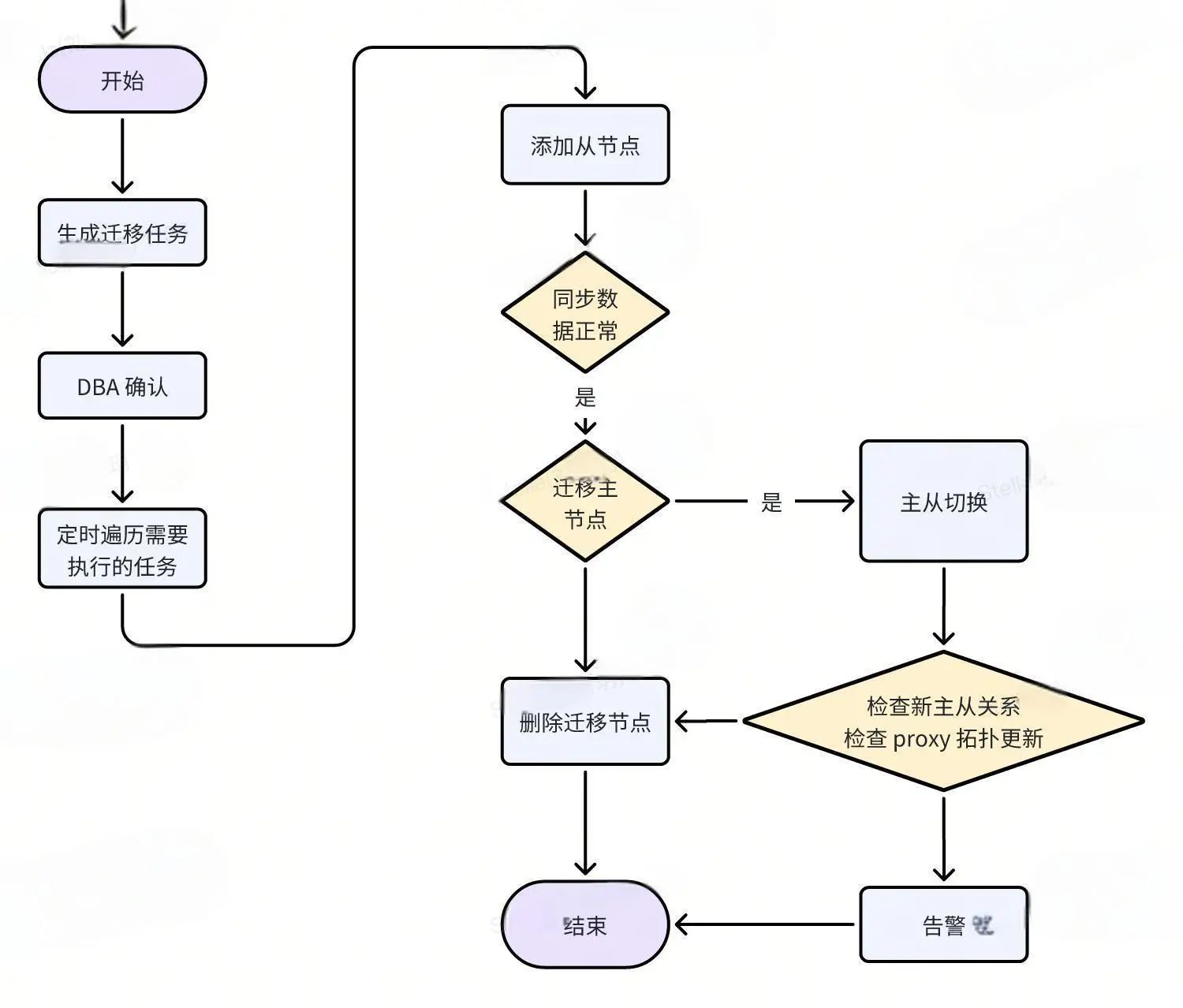
迁移过程中,为了节点迁移不出现异常,每一步执行都进行多维度严格的校验,确保正常才进行下一步操作,下面详细介绍迁移过程中每一步操作是如何进行校验保障可靠性的。
添加从节点
到达某个节点的迁移任务执行时间时,第一步是先添加一个从节点来替换准备迁移的原有节点。
一个缓存实例或节点的部署非常复杂,涉及机器选择、端口分配、配置文件准备、节点安装与启动、槽位分配、主从关系设置、SLB 分配与绑定、以及相关组件的部署等一系列动作,目前 Redis 集群部署、以及单个节点部署都是自动化部署完成。
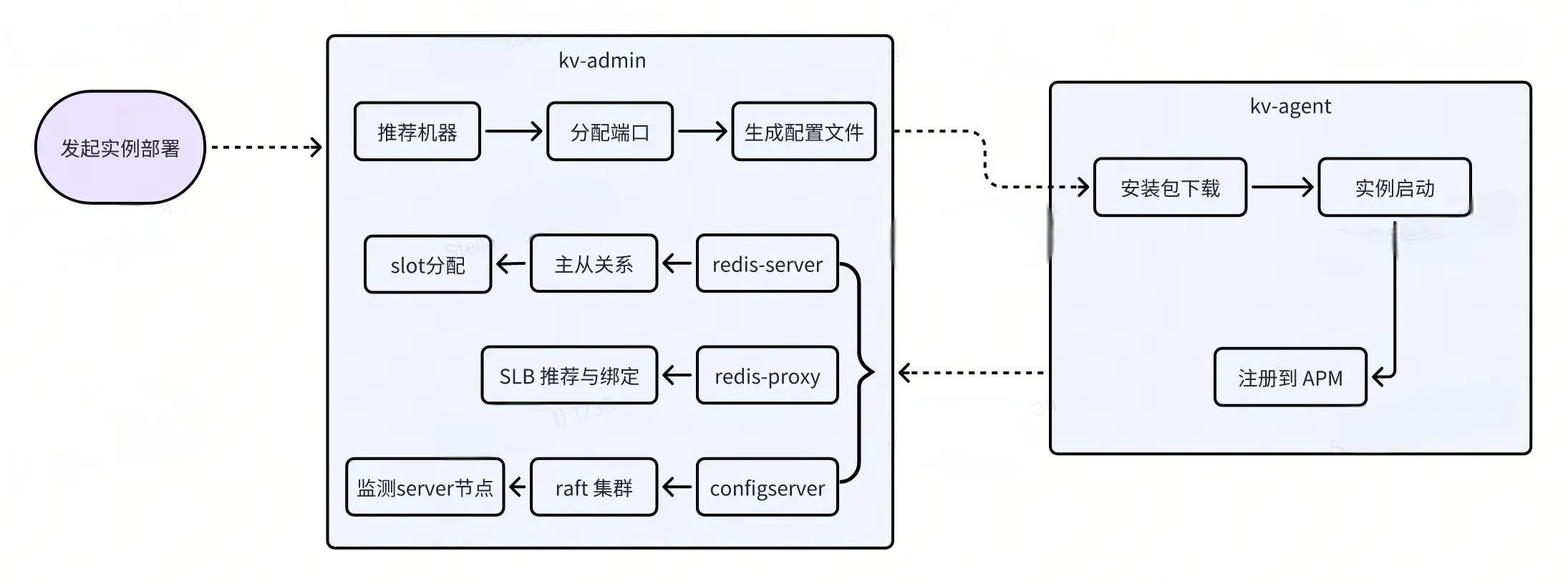
为了保证迁移过程中节点的高可用,迁移节点自动化部署过程中包含一些必要的部署规则:
新分配节点保持与待迁移的原节点在同一个可用区
新分配节点不能分配到待迁移的原有节点同一台宿主机上
新分配节点分配的宿主机保持在原节点所在同一资源分组
新分配节点的规格、版本与待迁移的原节点保持一致
避免同一个集群实例的多个 Redis-Server、Redis-Proxy 节点部署在相同的宿主机上
每个宿主机最多分配总内存容量的 90%,预留一定的数据增长空间
根据宿主机可用内存,优先推荐剩余可用内存多的机器
检查同步数据正常
完成添加从节点动作后,需要检查新节点是否分配正常、以及新节点同步数据是否正常,只有新节点同步数据正常才能可靠的执行主从切换或者删除原节点。
在 Redis 中,可以通过 info replication 命令查看主从节点同步状态,在自动迁移过程中,会分别从主节点和从节点的视角多维度综合判断当前主从同步是否正常。
一个状态正常的主从同步,从主节点视角通过 info replication 命令查看显示如下所示:
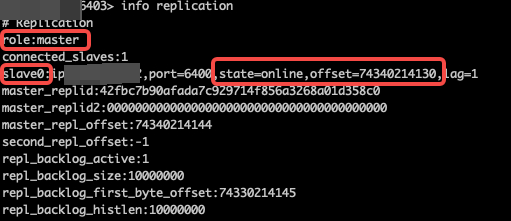
从主节点视角,自动迁移过程中,会判断连上主节点的从节点中是否包含了新增的从节点、并且新增从节点的同步状态 state=online 且 offset != 0
一个状态正常的主从同步,在从节点视角通过 info replication 命令查看显示如下所示:
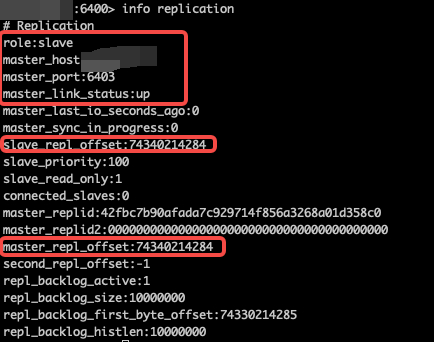
在新增的从节点视角,自动迁移过程中,会判断节点角色为 slave、且当前同步的主节点信息与节点所在分组的主节点信息(ip 和 port)一致、并且与主节点的同步状态 master_link_status:up 且 master_repl_offset != 0
而且,自动迁移过程中,第一次检查新增节点主从同步成功后,会间隔一分钟后,再次检查一遍,确保节点的同步正常。
执行主从切换
如果待迁移的原节点角色是从节点,新增从节点成功后,直接进入删除待迁移节点流程即可。但是,如果待迁移的原节点角色是主节点,则需要先对新增的节点执行主从切换,将新增的从节点选举为新主节点后,才能删除待迁移原节点。
获取新增从节点,发起主从切换选举操作,也即对从节点执行 slaveof no one 命令,将从节点选举为新主节点,对分组中原主节点和原其他从节点执行 slaveof 命令,设置为新主节点的从节点,同步新主节点。
检查主从切换正常
检查主从切换是否正常,与前面介绍的检查同步数据是否正常逻辑基本一样。分别从新主节点和所有从节点的视角,通过 info replication 命令查看主从节点同步状态。
从主节点视角,查看新主节点角色是否为 master,包含的从节点数量是否不为 0,所有从节点的同步状态是否state=online 且 offset != 0
逐个检查每个从节点,通过从节点视角,判断节点角色为 slave、且当前同步的主节点与新主节点信息(ip 和 port)一致、并且与主节点的同步状态 master_link_status:up 且 master_repl_offset != 0
只有通过主从节点视角分别确认都正常,才认为整个迁移过程是正常的。
删除待迁移节点
待主从切换完成(或者待迁移节点本来就是一个从节点)且同步状态检查正常后,进入删除节点流程,下线待迁移节点。
下线节点前,仍然会二次确认做一些必要的检查,包括分组的主节点是否正常、从节点同步是否正常等。
调用节点下线逻辑对待迁移节点进行下线操作,下线节点操作本身也会有一些必要检查,比如如果有业务连接访问 Proxy 和节点有数据的情况下,不允许删除主节点。
消息通知
如果节点迁移因为宿主机不足导致新节点分配失败等原因失败后,会发送一个消息通知,方便DBA了解迁移结果情况。
五 迁移任务管理展示
等待迁移和迁移中的任务管理展示,等待迁移的任务可以取消、修改执行时间、或者立即执行。
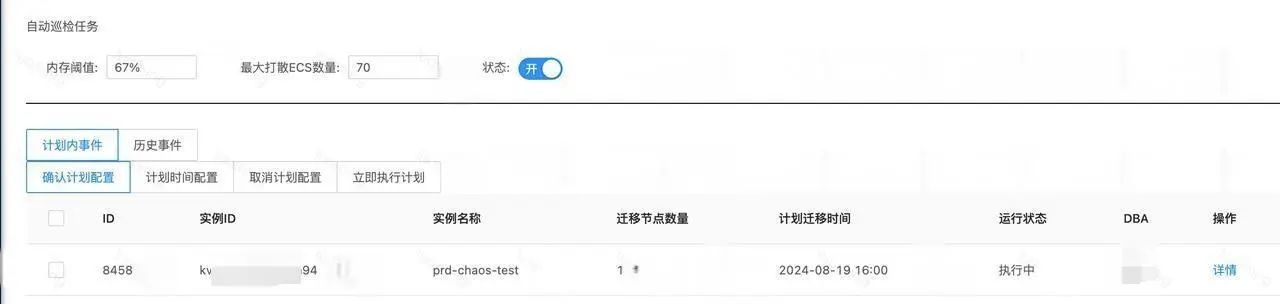
迁移任务可以查看生成的待迁移节点详情列表。

查看已完成的历史任务
六 总结
目前,得物 Redis 管理平台管理着几千台 Redis-server 宿主机,通过每日智能自动化均衡资源迁移,宿主机内存资源平均使用率和内存分配率均达到一个合理且较高的水位,所有宿主机内存使用率都动态控制在设置的阈值以下,保持宿主机内存资源处于一个高使用率水平的同时,给每台宿主机也预留有充足的内存余量,支持我们的业务突发的内存增长从而快速垂直扩容。
自动迁移过程中会优先选择同一集群在同一宿主机上节点数较多的节点,新节点分配挑选机器过程中会尽量分散同一集群的节点,有些集群由于早期资源较小可能分配的机器比较集中,随着自动迁移过程,也会逐步打散到尽可能多的不同机器上,减少机器故障时对单个集群的影响。
节点自动迁移功能也可以用于机器下线中,提高机器下线效率。机器下线前也需要迁移上面所有节点,Redis 管理平台也提供了运维选中节点后,生成迁移任务功能。
Redis 管理平台一直在优化和完善系统的自动化运维水平,提高自动化运维程度,尽量减少运维工作的人力投入,除了本文中提到的自动化资源均衡调度外,已经支持或者在规划开发中的自动化运维操作还包括有自动部署集群、节点自动垂直扩容、宿主机宕机自动启动节点、宿主机宕机自动恢复节点主可用区等,敬请期待后续更详细的介绍。

