货拉拉在逻辑漏洞自动化检测的实践
一、背景
逻辑漏洞包含:
未授权漏洞:未经授权的用户或攻击者可以绕过正常的身份验证、访问或执行未经授权的操作。
垂直越权漏洞:允许用户或攻击者在系统或应用程序中获取比其授权权限更高的权限级别。
水平越权漏洞:允许用户或攻击者在系统或应用程序中获取其它用户相同权限级别的访问权限。
在货运场景中,典型的例子:
未授权漏洞:不需要鉴权参数即可获取数据。
垂直越权漏洞:企业普通用户可以查看企业管理员才能看到的数据。
水平越权漏洞:A 用户使用自己的鉴权参数可以查看 B 用户的订单。
随着纵深防御体系建设的越来越完善,通用漏洞的攻击一般都被被WAF 等拦截,而逻辑类漏洞的利用却无法被拦截,一旦被利用,可能泄露大量的敏感信息。
二、技术调研

三、方案综述
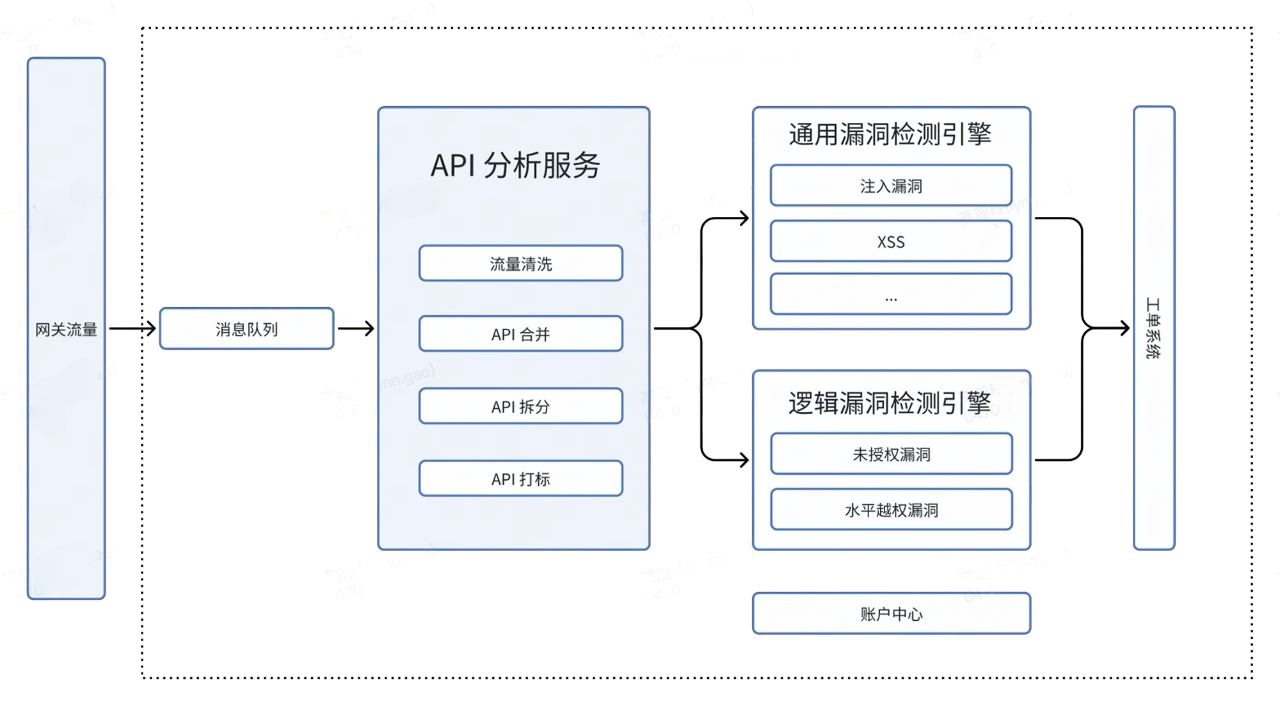
图1 漏洞检测系统-1
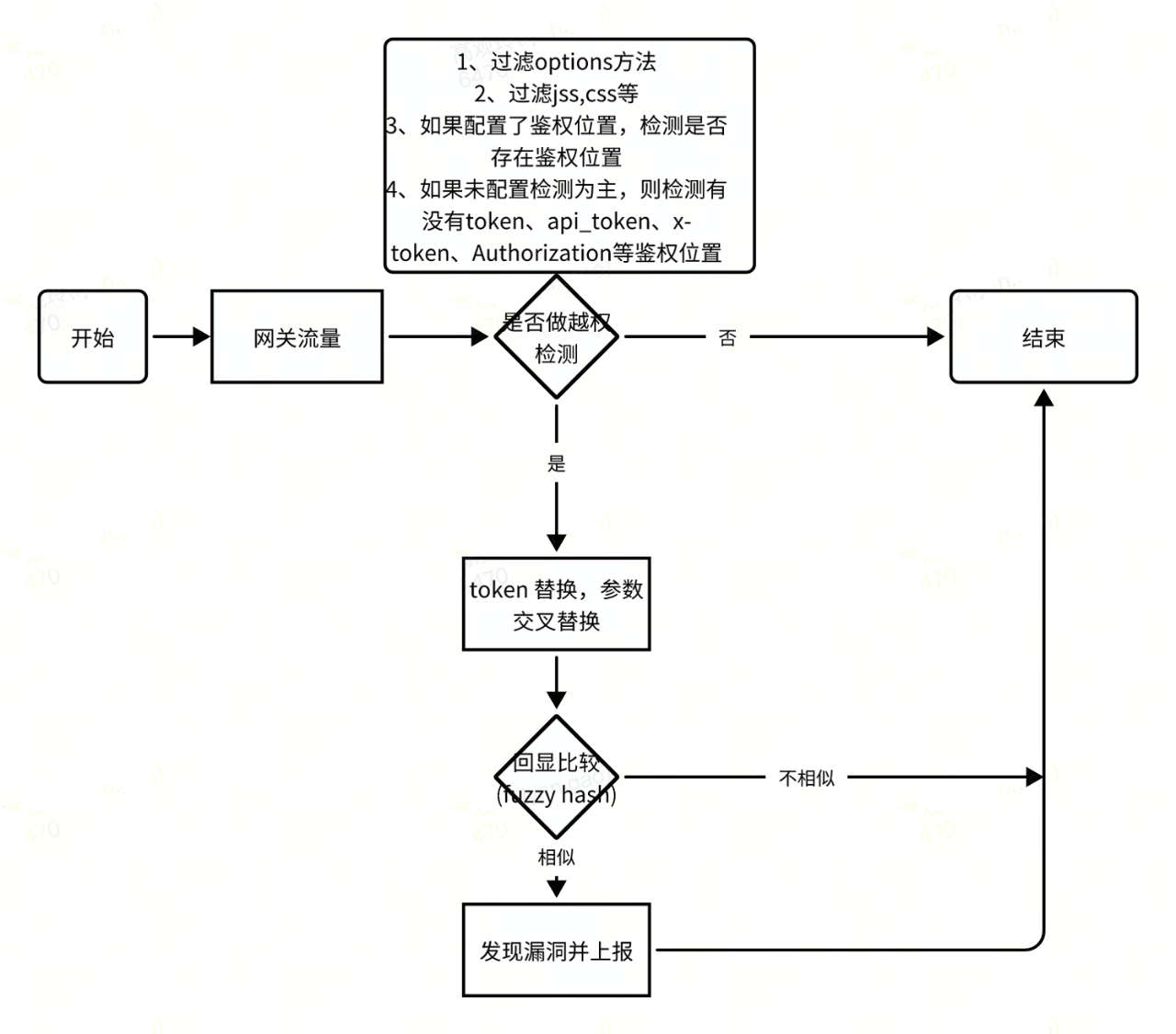
图1 漏洞检测系统-2
四、建设方案
(一) 准备工作
1、API接入
流量的获取一般有基于爬虫的主动获取和基于流量的被动接入。然而基于爬虫的主动获取无法绕过各种页面的登录限制,大部分业务都是前后端分离的,即使使用无头浏览器去爬取 URL,成本比较高,爬到的 API 也不全。所以采用基于流量的被动接入方式。
网关把测试环境的HTTP Request 发到 kafka 。扫描器去 kafka 上消费。
2、鉴权参数收集
鉴权位置就是 Cookie 或者 token,需要提供收集核心业务的鉴权位置是在 URL 的参数、Request header、或者在 Request 的 body 里面。 后面都以 token 来指代鉴权参数。
对于一些特殊的业务,可以通过个性化配置的方式对其进行配置。
3、账号中心接入
做越权漏洞检测时需要不同的账号去做测试,从而生成需要不同的账号对应的 token。
不同的业务系统的鉴权参数生成方式不同,核心业务的鉴权参数是从账号中心统一生成,接入账号中心后即可自动生成 token。
申请测试账号,用于安全测试。
4、回显判断相同
在判断水平越权时,如果越权成功,回显就是相同的,但是回显中可能包含一些时间戳、traceid 之类的信息,影响判断。不能完全使用 rsp1.body==rsp2.body 的方式来判断。
这里我们采用了模糊哈希(fuzzy hash)算法,可以参考http://ssdeep.sourceforge.net/。模糊哈希算法是基于哈希算法的,和哈希算法的不同点在于,哈希算法是将整个文件作为定义域来求算结果,而模糊哈希算法则是先对文件进行分块,计算每一块的哈希值,然后将得到的一系列哈希值利用比较函数与其他哈希值进行比较,来确定相似程度。运营一段时间后,取一个最优的相似度即可。
5、相同 API 定义
API 的去重,关系到扫描测试的周期和推送漏洞时的去重。
如 admin/index.php?id=1 和admin/index.php?id=2 会判定为 相同 API。
但是如 index.php?_m=index&_a=push 和 index.php?_m= index&_a=pull 则要判定为不同 API。
如 admin/1/push 和 admin/2/push 要判定为 相同 API。
(二) 基于DAST的黑盒检测
基于不同的越权逻辑,需要采用不同的重放逻辑。(如图3)

图3 检测判断逻辑
1、未授权访问
测试未授权访问的逻辑相对比较简单。
无鉴权参数
发包逻辑:
原始数据包req0重放
判断逻辑:
如果原始请求本身未包含 token,但是响应中确包含敏感数据,就判定为是一个未授权访问漏洞(无鉴权参数)。
如果原始请求本身包含 token,且响应包包含敏感数据,进入其他检测逻辑。
无效的鉴权参数
发包逻辑:
删除 token 的数据包req1重放
判断逻辑:
如果 req1的响应包包含敏感数据,就判定为一个未授权访问漏洞(无效的鉴权参数)(如下图4)
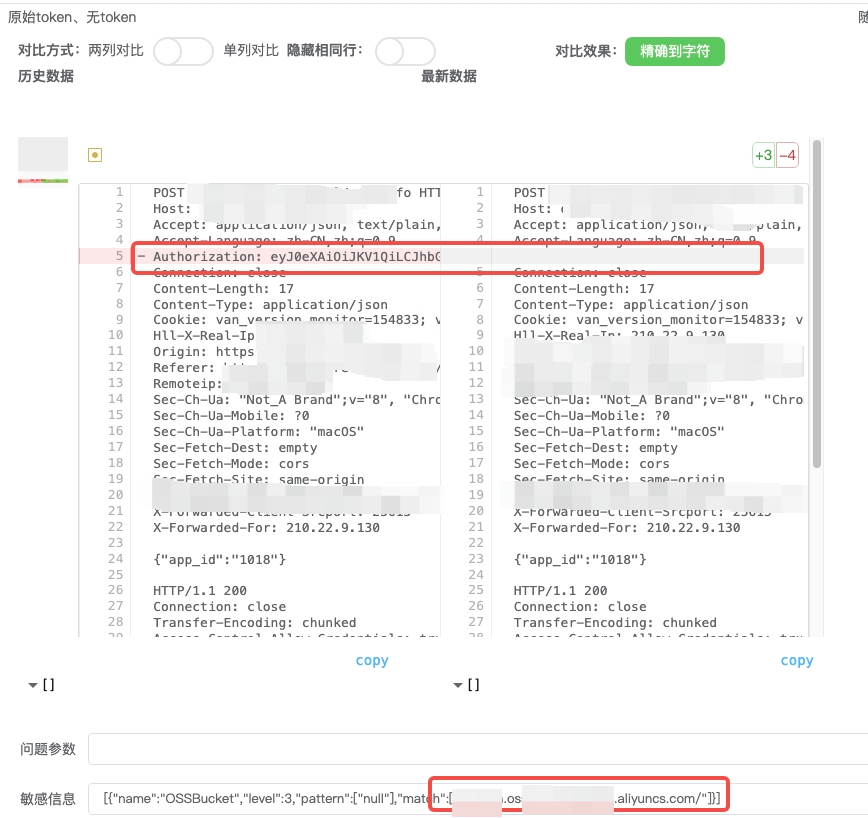
图4 无效的鉴权参数
2、多账号水平越权测试
发包逻辑:
使用测试账号生成的 token 替换原始 token 做重放req2
判断逻辑:
如果 rsp0.body 与 rsp2.body 相似度达到一定的阈值,就判定为一个水平越权漏洞(如图5)
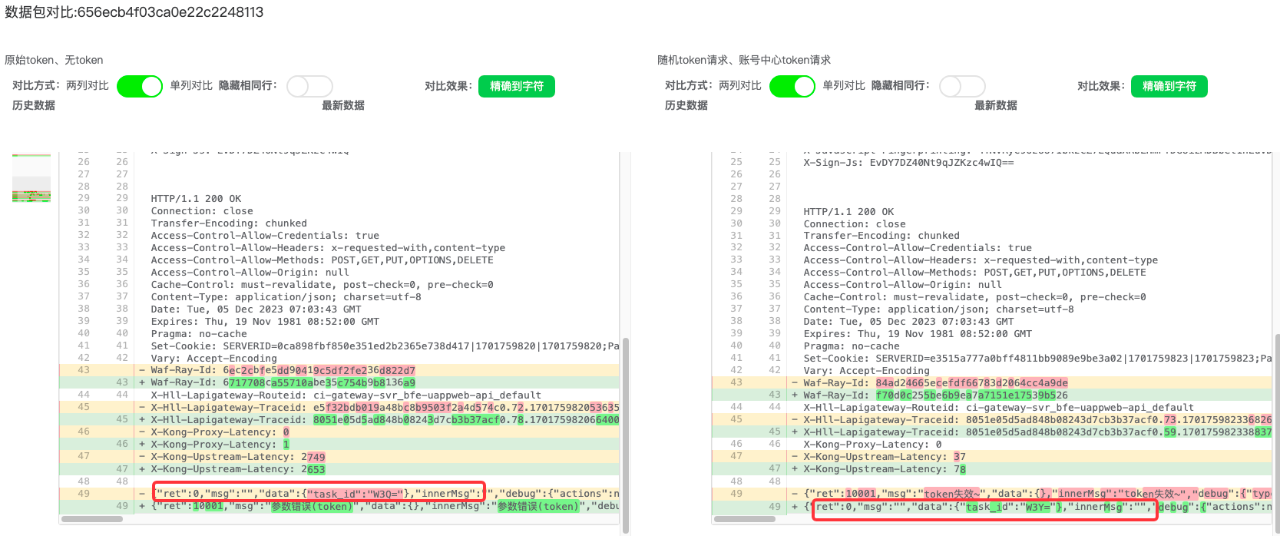
图5 水平越权漏洞测试
3、单账号参数交叉越权测试
多账号水平越权测试,需要我们有测试账号,并对接 token 生成的接口,需要大量的开发工作。核心业务接入后,对其他的业务我们采用 FUZZ 测试的方式。
前期工作
req0请求时将其参数缓冲到 redis
req1 第二个请求来到,如果和 req0属于相同 API,如果属于不同的 token 下的则进行检测
发包逻辑:
id=1&user=b 作为req2
id=2&user=a 作为req3
假设 req0的参数是 id=1&user=a,req1 的参数是id=2&user=b。需要对参数做一个去重的笛卡尔积计算,然后去掉原始的参数,最终得到这些组合。
判断逻辑
先比较 req1 和 req2 ,如果它们的响应体的框架结构相同,且不是空结果如{"ret":1,"success":true},则判定为漏洞,问题参数是 id。否则进入下一步。
接着比较 req1 和 req3 ......
如果参数多的情况下,可能 user 参数有问题,然后 user和 pwd 同时存在时也有问题,则冒泡取参数多的参数上报。(如图6)
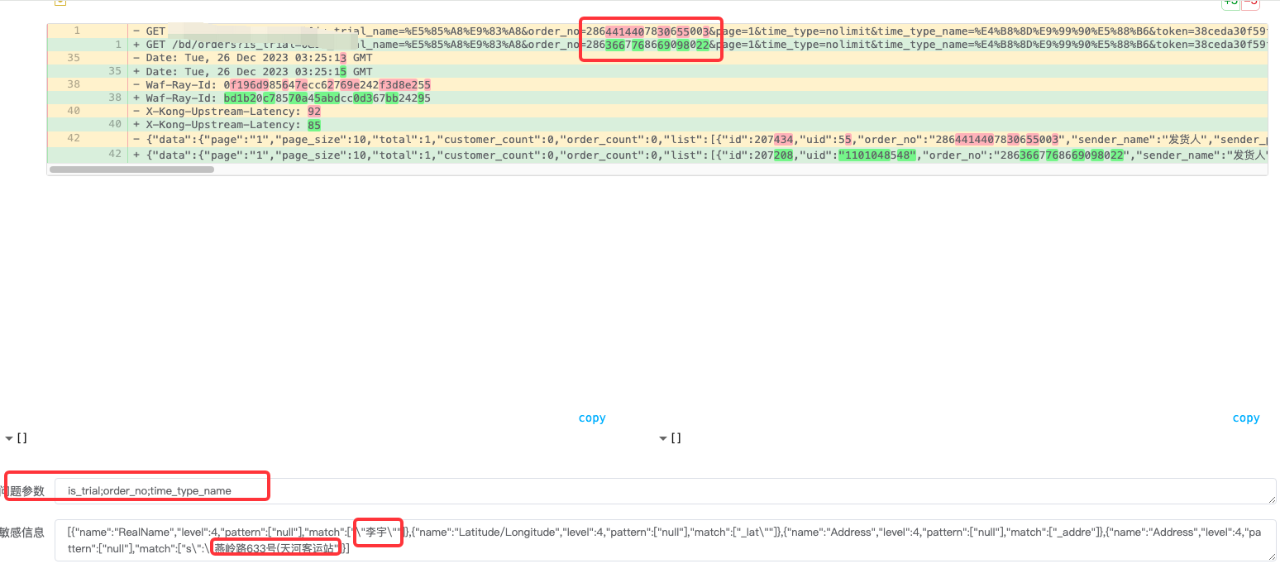
图6 交叉越权测试
4、总结
在黑盒检测结果运营过程中发现,最大的误报来自于公共API,如配置接口、文案接口、公开数据查询接口等?如何去识别公共 API?
参数在 URL Path中的场景怎么去测试?如 xxx.com/user/1/push 。1表示 id=1,该参数可以被遍历。
对于简单的查数据(GET)的场景,DAST可以基本可以覆盖。但是对于增、删、改的场景,接口返回的数据都比较简单,只有简单的 success 等。那如何识别哪些接口是增删改的呢?如果判断增删改是否成功呢?所以接着建设了 API安全分析平台和 IAST 。API 分析平台负责资产的梳理和打标,IAST 的调用链路可以辅助判断增删改是否成功。
(三) 公共API识别
经过一段时间的运营,我们发现公共API返回的数据大小比较相似。在日常的网络安全事件运营中,运营的同学有将请求数据入到 HIVE 库,包括 http 响应的数据大小即body_bytes_sent。
标准差,是离均差平方的算术平均数的平方根在概率统计中最常使用作为统计分布程度上的测量。标准差是方差的算术平方根。标准差能反映一个数据集的离散程度。
通过对一段时间内不同 API 的body_bytes_sent 做标准差计算,获取标准差为 0 的 API,则这部分API 被判断为公共 API。(如图7)
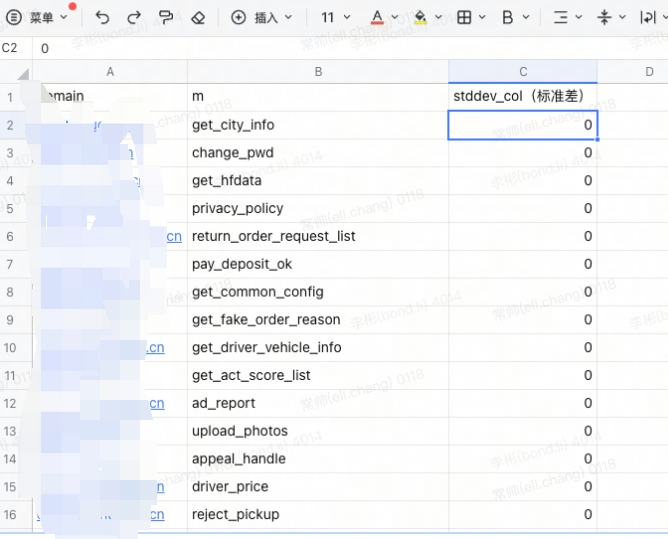
图7 标准差计算
(四) API安全分析平台
1、建设目标
(如图8)
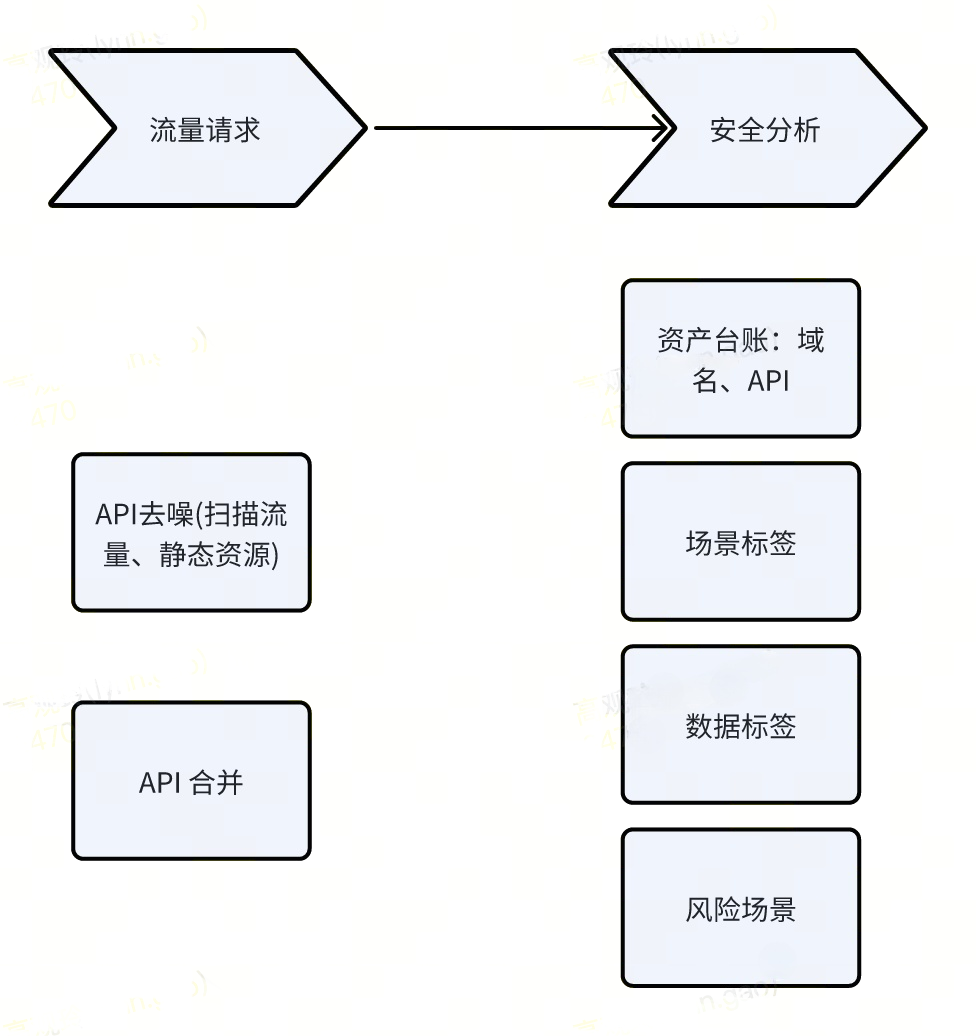
图8 建设目标流程图
2、接口去噪
接口去噪主要针对扫描探测、爬虫的流量过滤、静态资源范围过滤。使用 WAF 的 DAL,实现灵活配置。部分配置规则:
http.response.code <400and not (http.response.code == 307)and not (http.user_agent matches "scaninfo@paloaltonetworks\.com")and not (http.request.method matches "HEAD|OPTIONS")and not (http.request.uri.path matches "\.js\.map|\.css|\.png|\.jpg|\.jpeg|\.ico|\.pdf|\.svg|\.bcmap|\.woff|\.ttf|\.xlsx|\?|\*|\.\.|@|:|;")and not (http.response.headers["location"] matches "sso.xxx.cn|in-sso.xxxx.com")and not (http.host matches ".*@.*oastify\.com.*")
3、接口合并
接口合并针对的是参数在 URL PATH 的场景,如下
api.example.com/login/238
api.example.com/login/392
这两个 API 需要合并为一个api.example.com/login/{id}
工程实现接口合并时可以参考gin等框架的route生成算法,或者使用一个简单的前缀树即可。重点是如何识别到API 是属于这种场景的。
自动识别
参数在 URL PATH 的场景有一个共同点就是 path 中的参数会频繁变化,而一般我们写 API 时,PATH 中的字段基本都是固定的,变化不会特别频繁。
在自然语言处理中,TF-IDF(Term Frequency–Inverse Document Frequency)是一种常见的统计方法,它主要用来评估一个词语在文档(document)中的重要性,如果一个词语在一篇文章中出现的频次(TF)很高,同时又在其他文档中出现的次数很少,那么可以认为该词语是文档的关键词。TF-IDF的计算公式为:(如图9)

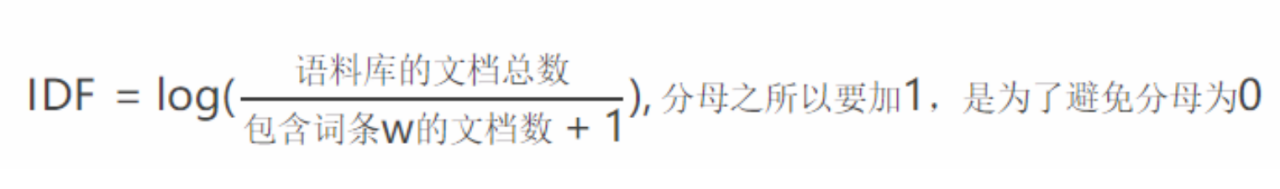
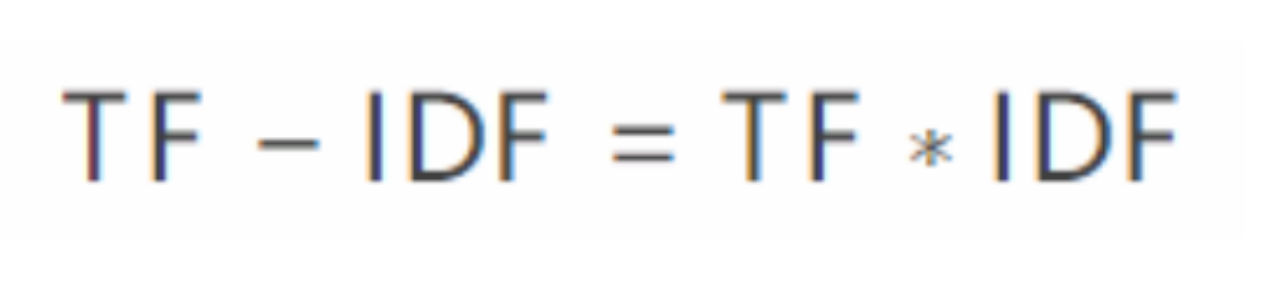
图9 TF-IDF的计算公式
在该思路的指导下,我们可以将客户端向服务端某个时段发送的所有URL条请求视为文档(documents),然后将计算单条的URL文档下的关键词。以某个登录API为例:api.example.com/login/238,其中/login/238是URL组成部分中的path,定义了资源在服务器上的路径,“238”是本次请求所携带的可变参数。
首先,我们将该文档做分词处理,切分为[‘login’,’238’]形式的列表,在本方案中为了简化计算,所有列表[w1,w2,...,wn]中每个w的词频TF默认为1。并对该API下N个文档均做分词处理得到N个列表,然后参考IDF值的算法计算列表下每个词语的IDF值,每个列表中IDF值最大的词语为该文档的关键词。一般的,如果文档下的关键词数量越多,说明该接口下的请求中有大量不同的可变参数,如果关键词比例(关键词数量/文档数量)超过了预先设定的阈值比例,我们可以认为该API接口属于参数在 URL PATH 的场景。
人工合并
对于一些接口请求量小的,可能无法达到预定阈值的,可以通过人工添加合并规则的方式进行 API 合并。(如图10)
图10 人工API合并
4、接口打标
标签类型:(如图11)
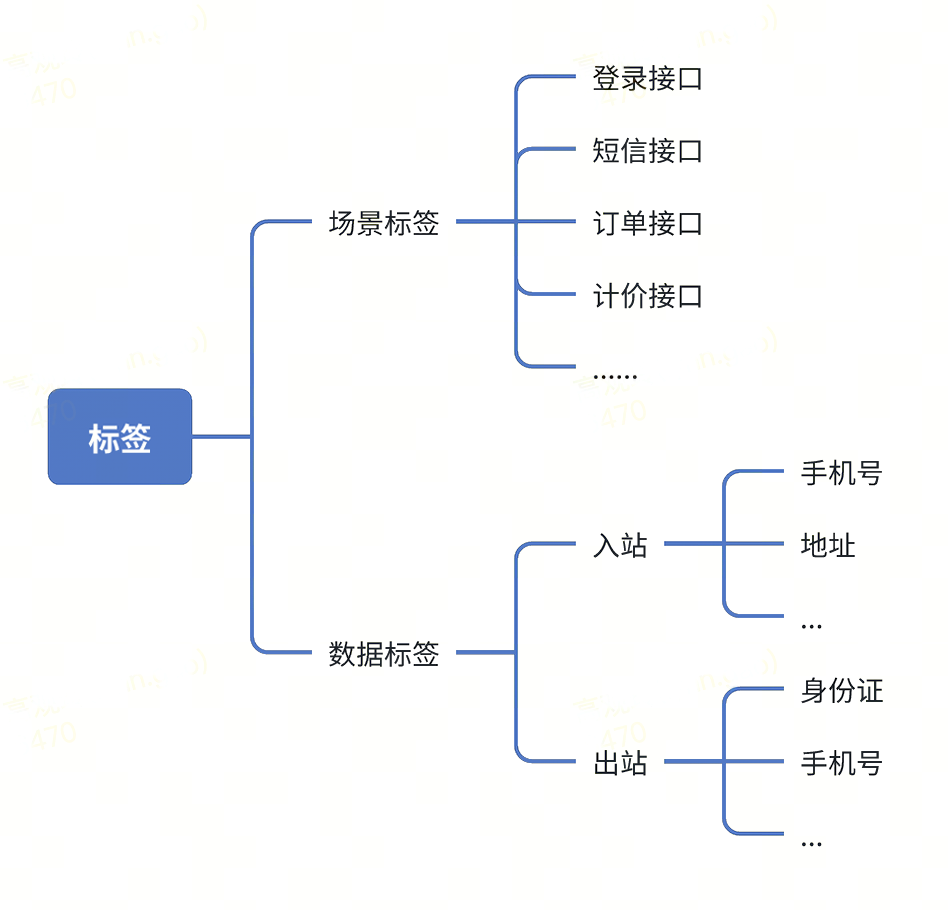
图11 标签分类
5、运营
新增API监控:第一时间 发现新增API,进行风险 评估
僵尸API监控:一段时间内 PV持续为 0 的接口,排查是否下线,减少暴露面
API 清单:可以更加方便的做横向排查和渗透测试
推进防护能力接入:SIEM、签名等
(五) 结合IAST的调用堆栈
此处只是使用了 IAST 的插桩原理,并未部署 IAST。CI 的监控系统运行比较稳定,插桩覆盖率也比较高,也有 traceid 可以做全链路的追踪。如图12是一个完整的链路信息,包含埋点的调用堆栈、执行的 SQL。
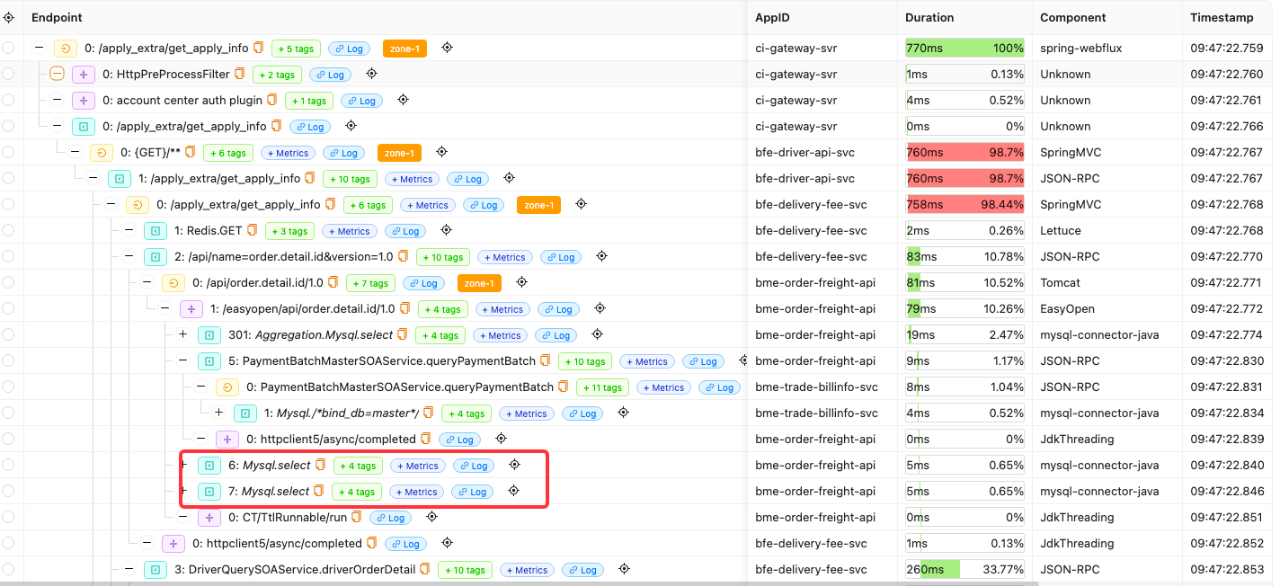
图12 完整链路信息图
再回到基于 DAST 的黑盒检测中,结合上 API 分析服务的标签和IAST 的调用堆栈,如果两次请求对应的调用堆栈相同,则可以判定为是有逻辑漏洞。
五、不足与改进
API覆盖率不全
基于流量的接入方式,对于一些僵尸 API 可能无法发现,需要结合主动触发或者分析 swagger 等分析完善 API。
自动化程度有待提高
目前全自动化的场景需要做很多的加白操作,垂直越权场景还未覆盖
复杂的场景无法自动完成,如需要多个接口配合完成的场景
目前对不含敏感数据的越权漏洞还不支持检测

