GPU利用率:一个被误解的性能指标
摘要:AI团队经常会使用GPU利用率来代表GPU性能。但一项最新报告表明,即使GPU显示100%的利用率,实际上可能还有大量未被充分利用的计算能力。一些与基础模型公司合作的研究人员发现,他们在优化LLM训练过程中,尽管GPU利用率达到了100%,但实际的模型浮点运算使用率(MFU)仅为20%,远低于行业平均水平。
GPU利用率:一个令人困惑的现象
即使只有一个任务在GPU的一小部分上运行,由工具如nvidia-smi或其他基于nvml的工具报告的GPU利用率指标可能表明设备完全被占用,这对用户来说相当困惑。
为了提供更清晰的理解,先看一个来自NVIDIA开发者论坛的示例:

此代码片段将在一个流多处理器(SM)上启动指定的内核(线程)。正常来算的话,GPU的“利用率”应该计算为1/num_sm*100%。例如:
● 如果GPU上有10个SM,那么“GPU利用率”应该是10%。
● 如果有20个SM,那么“GPU利用率”应该是5%。
但是观察到nvidia-smi可能报告GPU利用率为100%,如下例输出所示:
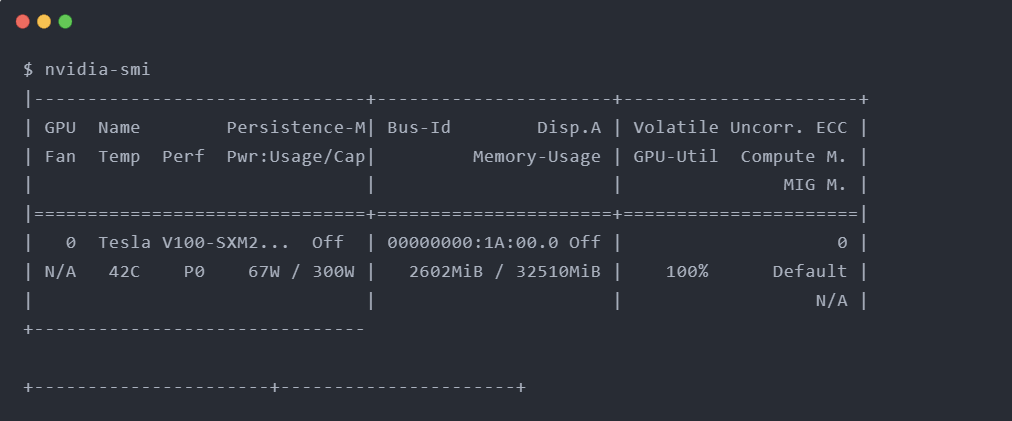
一些与基础模型公司合作的研究人员遵循了几乎所有关于Pytorch性能调优指南中提到的基本步骤,以扩展并提高其大型语言模型(LLM)训练的效率。
●通过更改数据加载器默认值(num_workers,batch_size,pin_memory,预取因子等)来充分利用GPU。
●通过使用混合精度(fp16,bf16)最大化使用张量核心
●使用来自apex/deepspeed(例如 FusedAdam、FusedAdamW 等)的融合优化器
●使用专为训练(H100SXM、A100SXM)设计的实例/网络。同时,可能的话,使用更新的实例H100 > A100 > V100
然而,他们在优化LLM训练过程中,尽管GPU利用率达到了100%,但实际的模型浮点运算使用率(MFU)仅为20%,作为参考,目前大多数LLM训练达到了大约35%-45%的MFU。因此,问题变成了:我们如何只使用了GPU计算能力的20%的理论最大值,同时GPU利用率却达到了100%?
GPU利用率到底是什么
Nvidia文档中对GPU利用率的定义相当模糊,它被定义为“报告GPU的计算资源和内存接口的当前利用率”。
在Datadog的NVML文档中可以找到一个更好的定义:“在过去的采样周期内,执行一个或多个内核的GPU上的时间的百分比”。
内存利用率:这代表了全局(设备)内存在被读取或写入的时间百分比。
换句话说,NVML 定义的“利用率”可能与我们常规理解不一致。它仅度量设备在给定采样周期内的使用部分时间,而不考虑该时间内使用的流多处理器(SM)数量。
为了确定为什么这是具有误导性的,我们需要快速了解一下GPU的工作原理。
在NvidiaGPU中,这些多处理管理器被称为流多处理器(SM),在AMD硬件中,这些被称为计算单元(CU)。下面是GH100GPU的插图,它有144个SM。
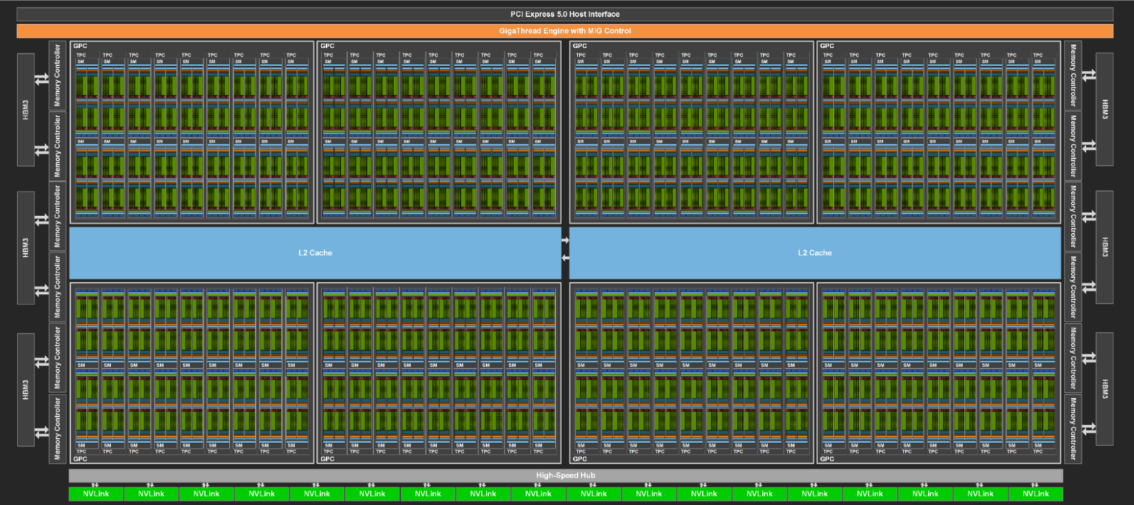
这些多处理管理器可以被视为一组工人的领班,在这种情况下,这些工人就是核心。当您启动CUDA内核时,工作由CUDA核心通过一个或多个SM执行。正如您在下面看到的,GH100芯片上的一个SM有许多CUDA核心。
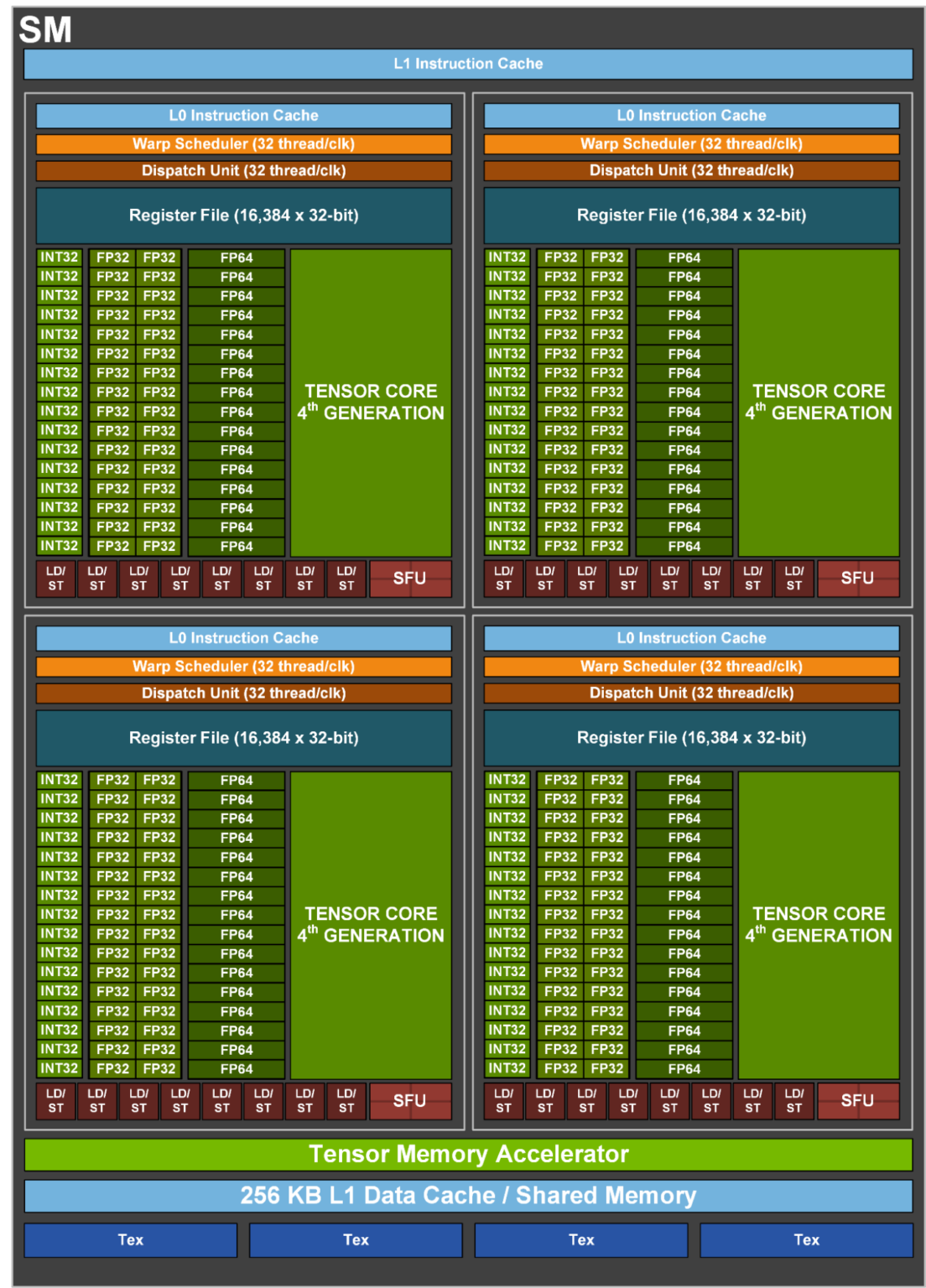
这意味着GPU利用率只是测量在给定时间内是否有一个内核在执行。它没有任何迹象表明您的内核是否使用了所有可用的核心,或者是否将工作负载并行化到GPU的最大能力。在极端情况下,您可以在进行0 FLOPS的情况下仅通过读写内存就能达到100%的GPU利用率。
需要澄清一下,我们不确定为什么 NVIDIA 以这种非传统方式定义“ utilization”。但这可能与“USE”(Utilization/Saturation/Error)方法论中的“ utilization”定义有关。
深入挖掘下一步当然是剖析模型的训练循环。
正如您在下面看到的,Softmax内核的GPU利用率很高,但对于称为SM效率的指标来说却很低。
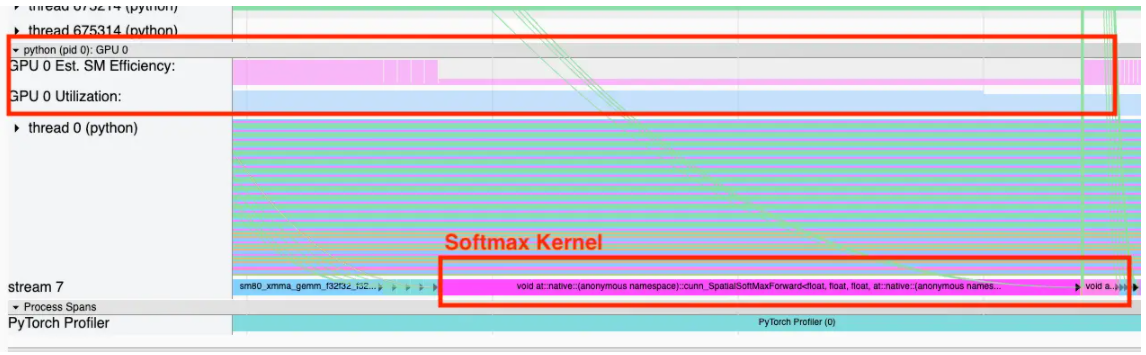
这已经让我们警觉起来,因为简单的softmax是LLM的一个臭名昭著的瓶颈,许多内核融合,如FlashAttention,都是为了解决其内存受限的性质。因此,SM效率统计可能指出了我们模型执行中的低效问题。
SM效率是什么?
SM效率是NvidiaGPU上的一个指标,描述了在给定时间间隔内活跃的SM的百分比。正如我们之前提到的,SM可以被视为CUDA核心的一组领班。例如,NvidiaH100GPU有132个SM,每个SM有128个核心,即总共16,896个核心。通过测量SM效率,我们可以确定我们的CUDA内核是否使用了我们的流多处理器。如果我们有一个CUDA内核连续运行10秒,但只使用了一个SM,在H100上,这将记录为100%的利用率,但SM效率却是1/132=0.7%。
如何提高GPU的执行率?
现在,我们可以轻松地识别哪些内核在GPU上没有被充分利用,我们可以开始优化这些层。由于这是一个变压器堆栈,大部分收益将来自于在变压器块定义中的层获得。下图总结了我们优化的内容。
这里的融合是不使用PyTorch定义的一组层,而是用CUDA或Triton实现的GPU内核替换它,将所有层合并为一个内核。速度的提升来自于每个内核读取/写入GPU内存的时间少于某些层(例如Softmax)进行数学计算的时间。Flash Attention就是这样一种融合内核的例子。其他需要融合的内核是MLP和dropout层规范残差加法操作。
最大的挑战是确定在代码中需要交换适当层的位置。虽然torch.compile试图自动完成这项工作,但截至撰写这篇文章时,torch compile并不与新发布的分布式策略(如FSDP)很好地配合,并且由于图断裂,实际上并没有提供很多承诺的速度提升。希望在未来,torch编译器可以为我们完成这些工作,但目前我们仍然需要手动添加融合实现。
在结果方面,我们实现了4倍的速度提升, MFU从原来的20%提升到了38%的。
结论
我们强烈建议大多数AI团队在GPU集群上以及GPU利用率上跟踪SM效率。它能提供更准确的性能指标,表明你从GPU中榨取了多少性能,而GPU利用率可以衡量机器是否处于闲置状态。当然,计算MFU也很好,但它并不是一个您以随时和逐层监控的指标。同时,NvidiaDCGM默认提供SM活动。
还有更细粒度的指标,如SM占用率(或Pytorch Profiler中的已实现占用率Achieved Occupancy),这些指标告诉我们每个SM正在执行多少工作。然而,理解这些指标比尽可能提高SM效率要复杂得多。

