监控系统原理揭秘——数据运算篇
一、监控系统概览
监控系统在现代技术环境中扮演着至关重要的角色。运营同学每天检查自己的活动数据,研发人员每天检查系统各项指标是否正常,这些工作都少不了监控系统的身影。通常来讲,监控系统包括数据采集、数据计算、数据存储、数据可视化及监控预警等功能。本文主要介绍数据计算部分。
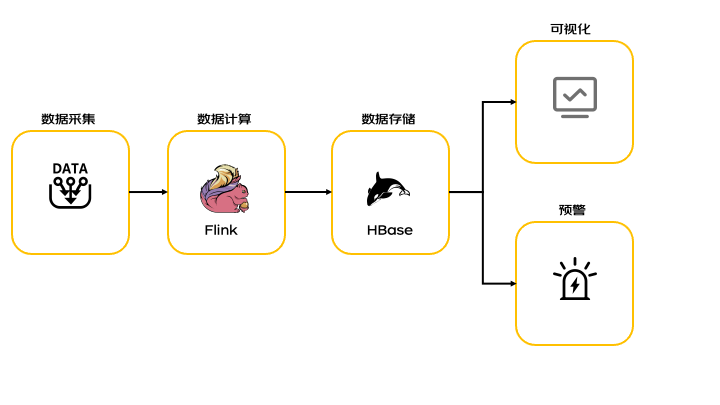
二、实时计算
流数据实时计算是一种处理和分析实时数据流的技术,它允许企业从连续生成的数据(如日志文件、传感器数据、在线交易等)中即时提取价值。这种计算模式对于需要快速决策和响应的应用场景至关重要,如实时监控、在线推荐、欺诈检测等。Apache Flink 是实现流数据实时计算的流行框架之一。
2.1 数据流
数据流(Data Stream)是由连续生成的数据元素组成的序列,这些数据元素可以是来自各种源的记录、事件、或者其他形式的数据点。数据流通常是动态的、无界的,并且高速连续地到达处理系统。
数据流的特点包括:
1.连续性:数据流是连续到达的,没有明确的开始和结束。
2.无界性:理论上,数据流可以无限地持续下去,因此通常被认为是无界的。
3.实时性:数据流通常需要实时或近实时处理,以便及时响应或提取信息。
4.变化性:数据流的特性(如速度、大小、格式)可能会随时间变化。
5.无序性:数据流中的数据可能不按照产生的顺序到达,尤其是在分布式系统中,可能因为网络延迟或其他因素导致乱序。
[数据源] → |元素1| → |元素2| → |元素3| → ... → [数据处理] → [数据存储/输出]
2.2 数据流处理
2.2.1 流处理中的Time和Window
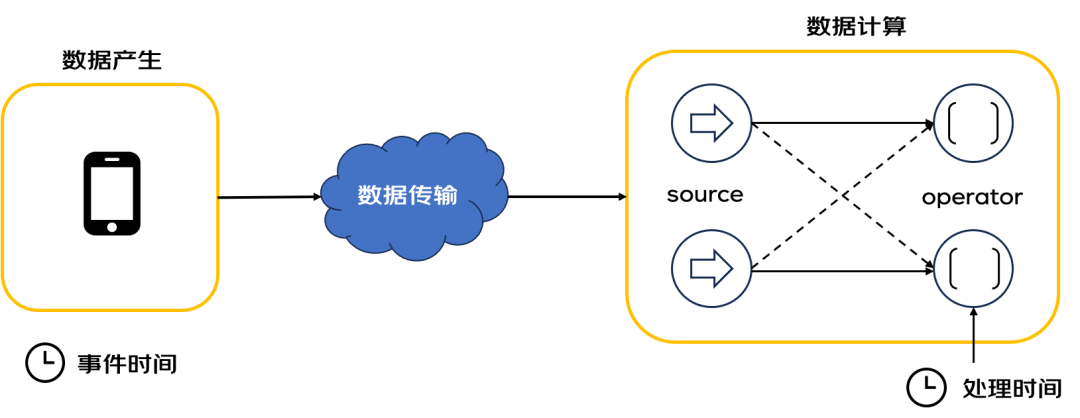
Time
事件时间(Event Time)
事件时间是指每个事件或元素在其生产设备上产生的时间。该时间通常在它们进入Flink之前就已经嵌入在事件中,并且可以从每个事件中提取事件时间戳。
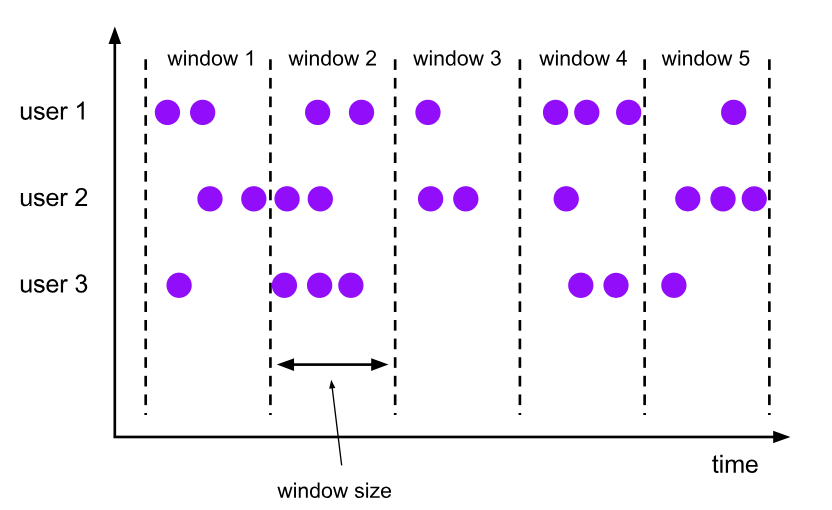
有了事件时间,基于窗口的聚合(例如,每分钟的事件数量)只是事件时间列上的一种特殊的分组和聚合。每个时间窗口是一个组,每一行数据可以属于多个窗口/组(针对滑动窗口,多个窗口可能有重合的数据)。
处理时间(Processing Time):
处理时间是指正在执行相应Flink操作的机器的系统时间。
当流式程序按处理时间运行时,所有基于时间的操作(如时间窗口)都将使用运行相应操作的计算机的系统时间。在分布式和异步环境中,处理时间不能提供确定性,因为它容易受到记录到达系统(例如从消息队列)的速度以及记录在系统内部操作之间流动的速度的影响。
Window
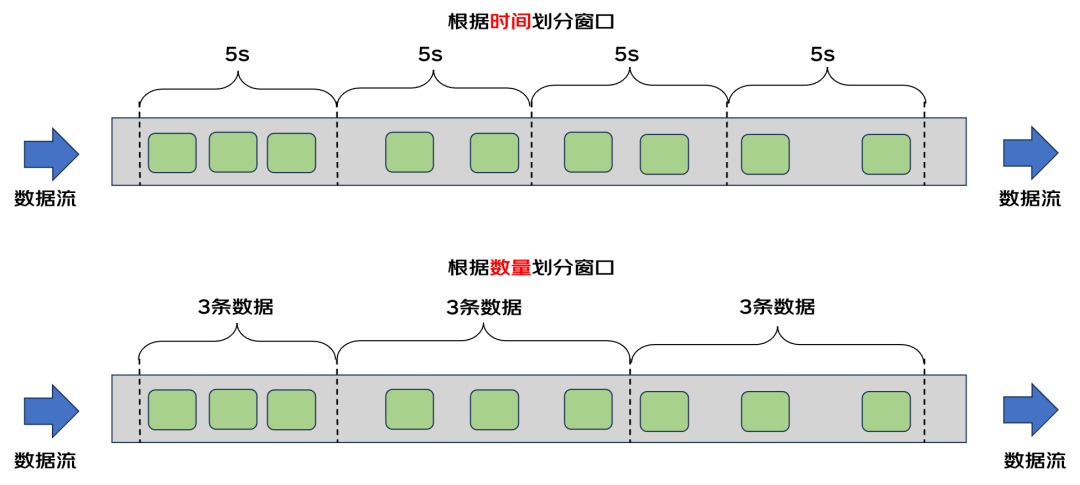
无界数据流本身没有边界,但是对数据流的计算需要一个明确的边界。这就要将无界数据流划分为有界数据流,边界的划分一般有两种方式:时间驱动或者数据驱动,时间驱动就是每隔多长时间就划分一个边界,数据驱动就是每来多少条数据划分一个边界。
2.2.2 窗口的分类
1. 滚动窗口(Tumbling Window)
滚动窗口将数据流分割成不重叠、连续的时间间隔。每个窗口都是独立的,窗口长度是固定的。例如,如果设置了一个5分钟的固定时间窗口,那么数据流会被划分为0-5分钟、5-10分钟、10-15分钟等时间段。每个窗口都会独立处理,适用于需要定期重置计数或计算的场景。
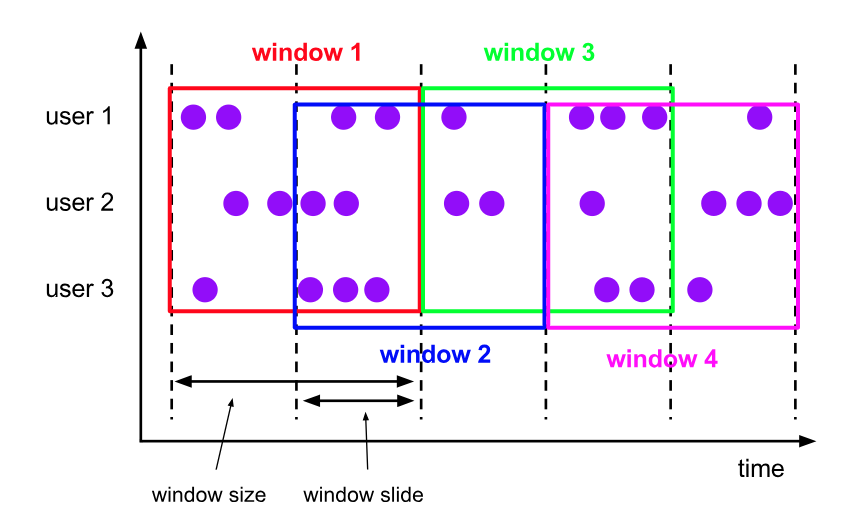
2. 滑动时间窗口(Sliding Window)
滑动时间窗口可以有重叠,它由两个参数定义:窗口长度和滑动间隔。窗口长度决定了数据聚合的时间范围,而滑动间隔决定了窗口更新的频率。例如,如果窗口长度是10分钟,滑动间隔是5分钟,那么第一个窗口是0-10分钟,第二个窗口是5-15分钟,依此类推。滑动时间窗口适用于需要更平滑连续输出的场景。
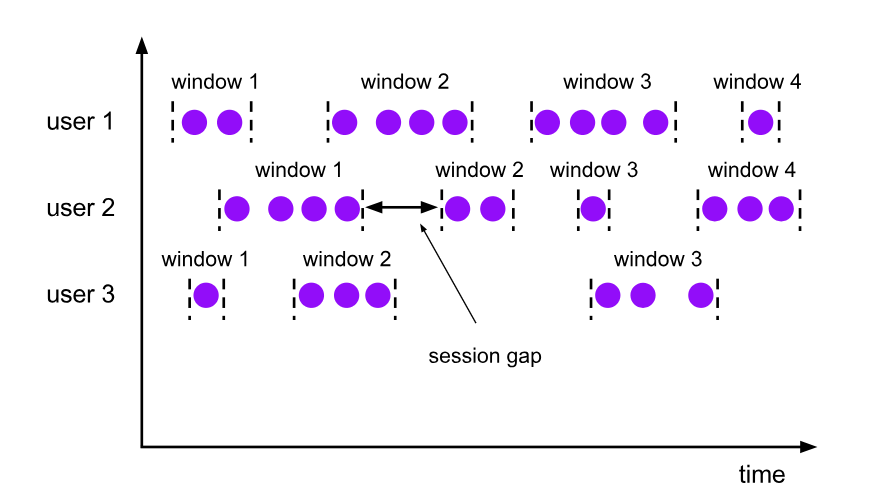
3. 会话窗口(Session Window)
会话窗口是动态长度的窗口,它根据数据流的活动来定义。会话窗口在数据活动(即事件)发生时开启,在一定的不活动时间段(称为超时时间或间隔)之后关闭。这种类型的窗口适用于活动或会话驱动的场景,比如用户的网页浏览行为分析。
4. 全局窗口(Global Window)
全局窗口是一个无限期的窗口,它不会根据时间进行分割。在全局窗口中,数据流的处理通常由其他机制触发,如外部信号或数据数量达到一定阈值。它不常用,因为大多数流处理场景都需要某种形式的时间边界来限制数据处理。

2.2.3 窗口的生命周期
窗口创建
窗口不会预先创建好,而是由数据驱动创建。当第一个应该属于这个窗口的数据元素到达时,就会创建对应的窗口。
窗口计算
对于不同的窗口类型,触发计算的条件也会不同。例如,一个滚动事件时间窗口,应该在水位线到达窗口结束时间的时候触发计算;而一个计数窗口,会在窗口中元素数量达到定义大小时触发计算。
窗口销毁
一般情况下,当时间达到了结束点,就会直接触发计算、输出结果,进而清除状态、销毁窗口。这时窗口的销毁可以认为和触发计算是同一时刻。这里需要注意,Flink 中只对时间窗口(TimeWindow)有销毁机制;由于计数窗口(CountWindow)是基于全局窗口(GlobalWindow)实现的,而全局窗口不会清除状态,所以就不会被销毁。
2.2.4 基于窗口机制的流计算
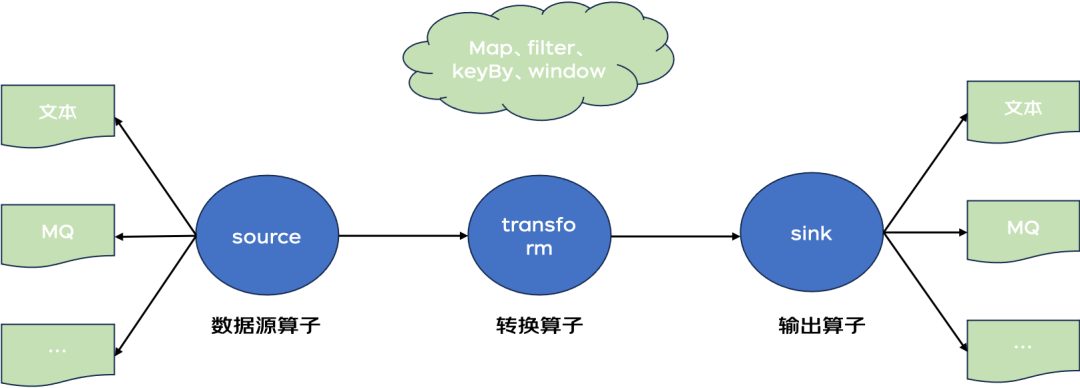
算子模型
Flink中算子分为数据源算子(source)、转换算子(transform)、输出算子(sink),下图为算子模型示意图。数据源算子负责接收运算数据,数据源支持多种:文本、MQ等等;转换算子主要对数据流进行聚合和计算操作;sink算子主要负责将运算结果输出,包括持久化和转发运算结果(MQ)等。
下图展示了用窗口大小为10s的滚动时间窗口处理数据的例子,数据流中所有数据都按序到达,这是最理想的情况。

水位线机制
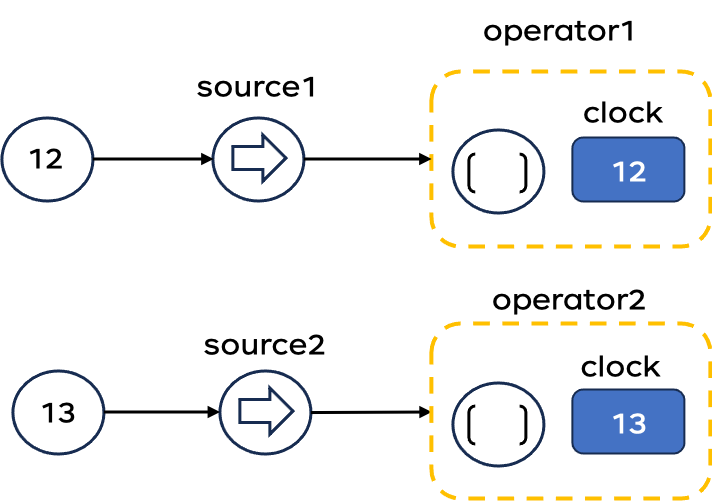
对于分布式系统而言,各个系统节点相互独立,互不影响,这给系统带来了更高的稳定性。但是各个节点之间没有统一的时钟,而是各自维护一个逻辑时钟。数据流在不同节点之间流动,上游节点给下游节点传输数据时,不同的下游节点对于时间的处理也会有偏差。如果要统一各个节点之间的时钟,则需要上游节点给下游节点传递数据时,将事件时间也传递下来。
以下图为例,时间戳为12和13的数据分别进如source1和source2算子。source1算子将基于事件时间的逻辑时钟传递给下游operator1算子,operator1算子将本地逻辑时钟置为12;source2算子将逻辑时钟传递给下游operator2算子,operator2算子将本地逻辑时钟置为13。这就造成了不同下游节点之间逻辑时钟不统一的问题。
想要解决这个问题,需要上游算子将逻辑时钟以广播形式传递出去,并且该逻辑时钟的传递不会受到当前算子作业进度的影响。
水位线可以看做是一种特殊的数据记录,该记录中包含了逻辑时钟,其主要内容就是一个时间戳,并且只能递增。其表示该时间戳之前的数据都已经到达,结束时间小于该时间戳的窗口都可以触发计算和关闭窗口。
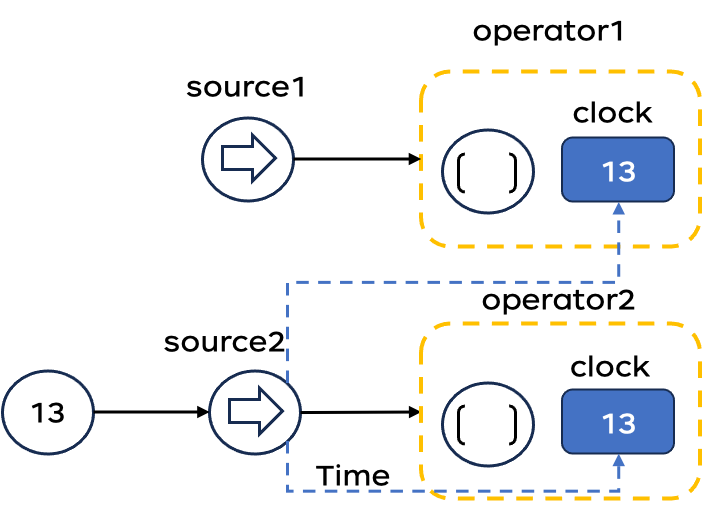
水位线传递机制
有序流的水位线传递比较简单,数据和水位线全部按照自身顺序进行传递,下游依次处理,当水位线到达了某个算子任务,这个任务会将内部时钟设置为当前时间戳。
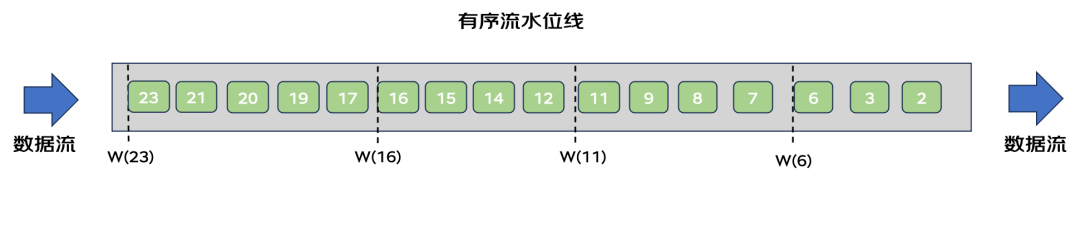
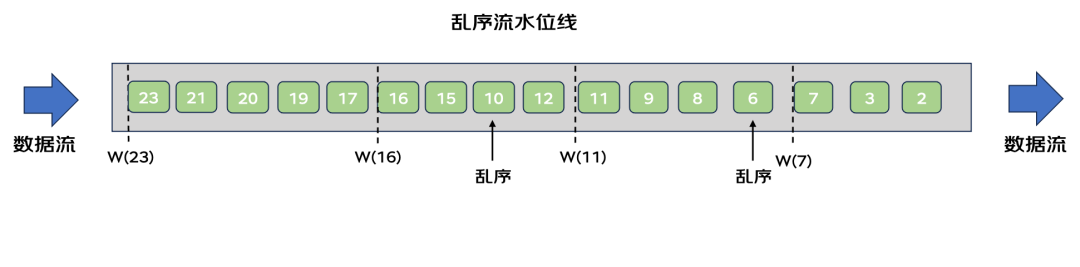
数据流并不总是有序,由于网络延迟等原因可能会造成数据流乱序。水位线周期性生成时,以当前周期内的最大事件时间进行计算。
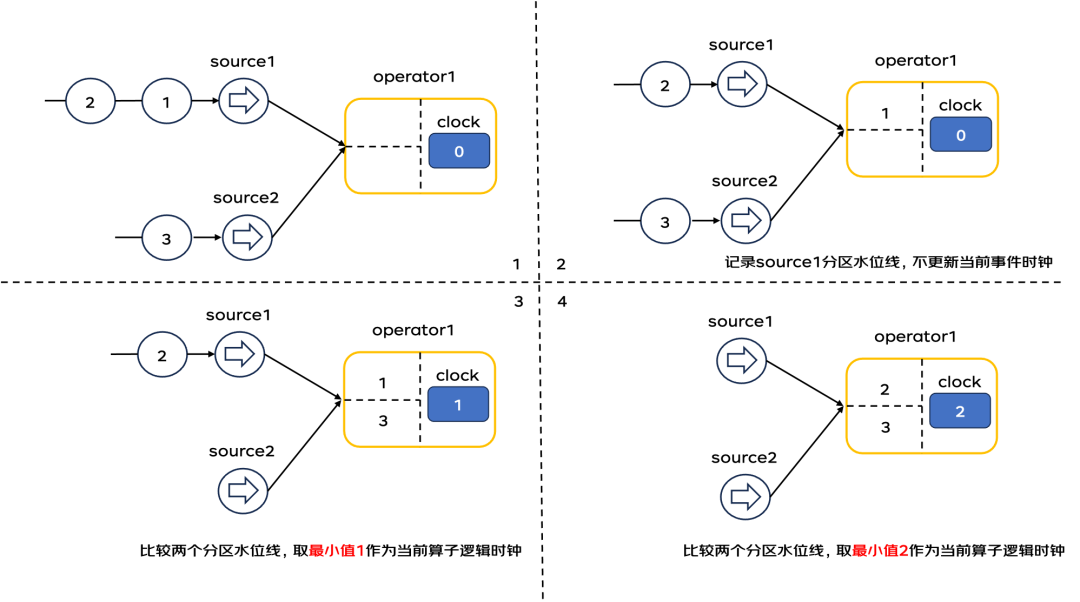
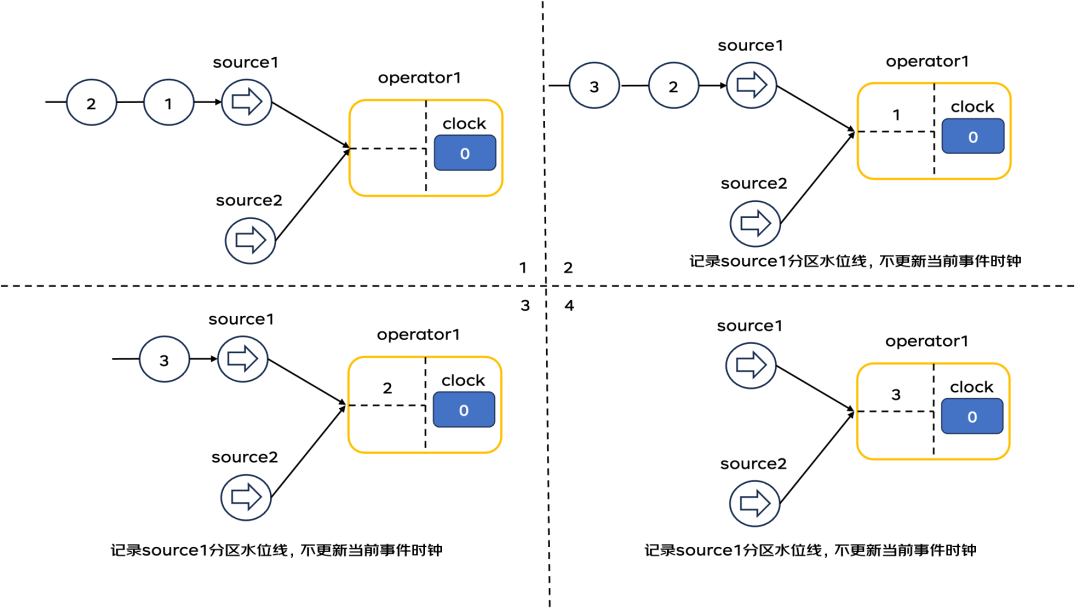
一旦算子任务开启了并行,水位线的传递就会变得复杂。以下图为例,并行任务间的水位线传递。
1)operator1算子初始化内部逻辑时钟为0,其接收两个并行上游算子source1、source2的结果。
2)source1算子处理事件时间为1的数据,并将水位线1传递给下游operator1算子,operator1算子接收到source1的水位线之后,不更新自己的逻辑时钟。需要等待source2算子发送水位线,并进行比较后才能更新自己的逻辑时钟。
3)source2算子处理事件时间为3的数据,并将水位线3传递给下游operator1算子,operator1算子接收到source2的水位线之后,和source1分区的水位线1进行比较,取最小值[1]作为自己的逻辑时钟时间。
4)source1算子处理事件时间为4的数据,并将水位线4传递给下游operator1算子,operator1算子接收到source1的水位线之后,和source2分区的水位线[4]进行比较,取最小值[3]作为自己的逻辑时钟时间。
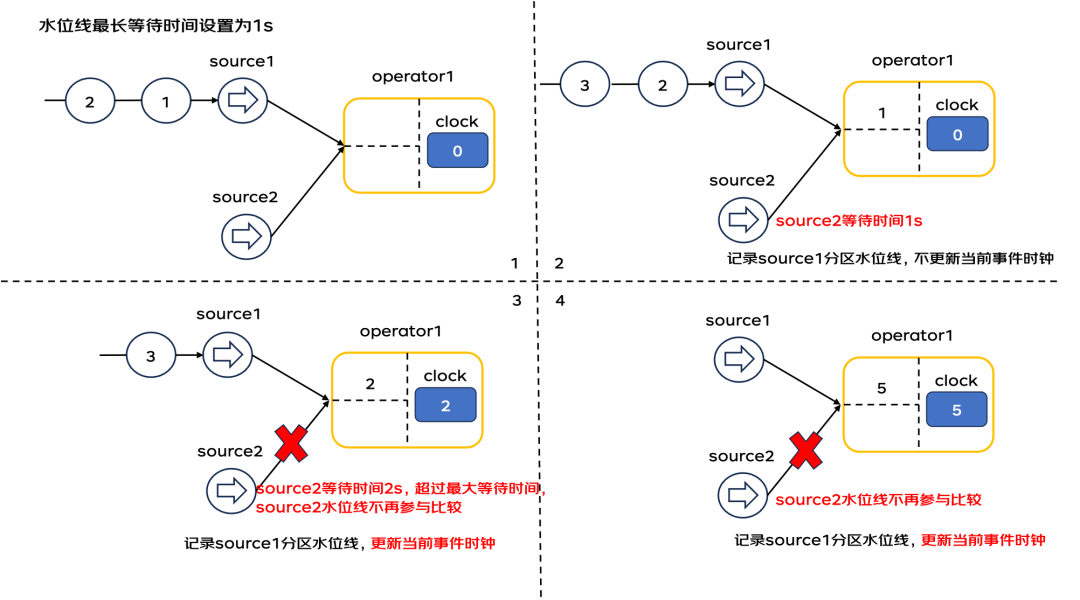
水位线最长等待时间
也就是说,下游算子依赖所有上游算子的水位线来设置自己的逻辑时钟。假如有一个上游算子一直没有发送水位线,下游算子的逻辑时钟则无法更新,这时下游算子无法正常执行自己的计算任务。
此时,需要设置水位线最长等待时间,超过最长等待时间还是没有接收到某个上游算子的水位线信息,则排除该上游算子,即该上游算子的水位线不再参与比较。这样下游算子的逻辑时钟就能够正常推进。
迟到数据处理
对于数据流而言,数据并不总是按序到达。如果某些数据因为网络原因导致乱序甚至延迟,这些数据就有无法正确计算的风险。
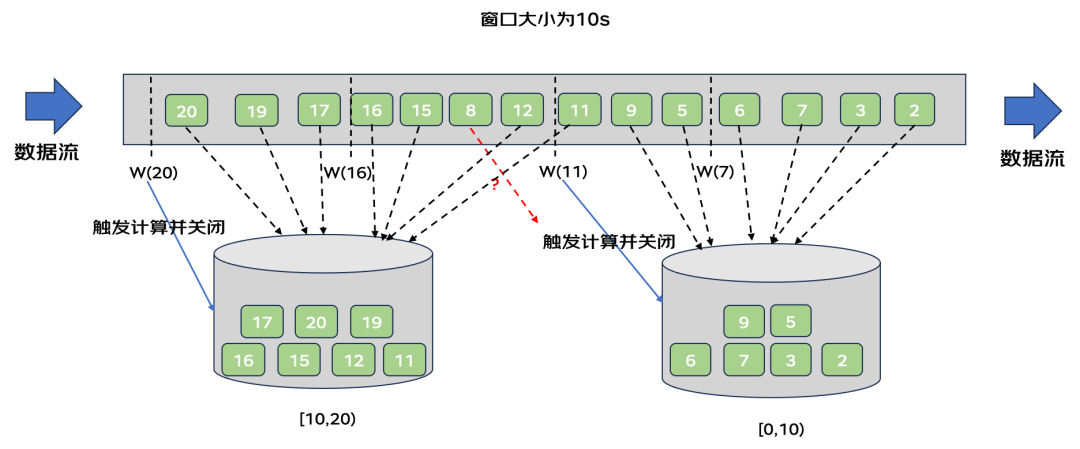
下图展示了一个窗口大小为10s的滚动窗口处理数据流的过程:
1)2-6这些数据进入到[0,10)窗口内,此时触发水位线计算,水位线为w(7),没有触发窗口操作。
2)5-9这两个数据进入到[0,10)窗口内,11进入到[10,20)窗口内,此时出发水位线计算,水位线为w(11),当前水位线大于[0,10)窗口的结束时间,触发该窗口的计算和关闭操作。
3)11进入到[10,20)窗口内后,又有一条数据8来到。此时属于它的窗口已经触发计算并关闭,不处理该条数据。
4)15-16这些数据进入到[10,20)窗口内,此时触发水位线计算,水位线为w(16),没有触发窗口操作。
5)17-20这些数据进入到[10,20)窗口内,此时触发水位线计算,水位线为w(20)。当前水位线大于[10,20)窗口的结束时间,触发该窗口的计算和关闭操作。
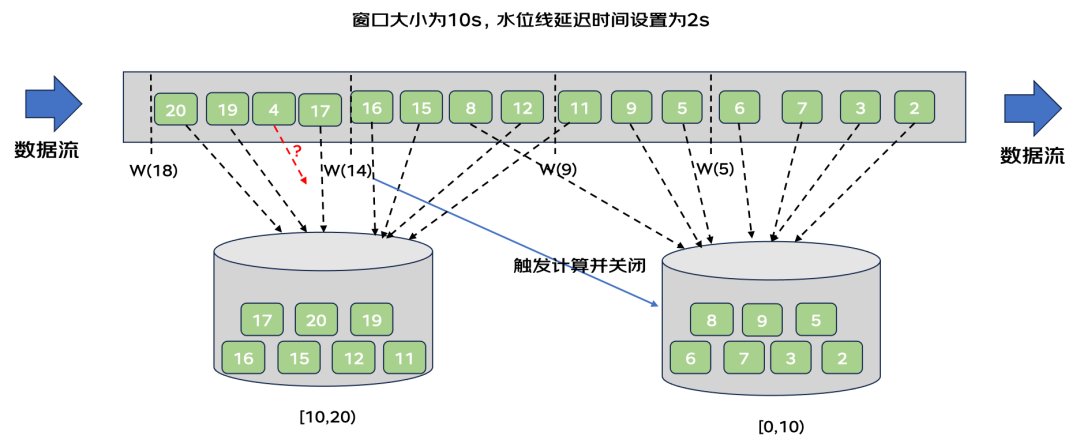
为了解决乱序流中延迟数据的处理问题,提出了水位线延迟时间的概念。例如,想实现水位线延迟两秒,则只需要将当前事件时间减去两秒作为当前的水位线即可。以上图为例,时间窗口大小为10s,将水位线延迟时间设置为两秒,再次进行数据流处理。
1)2-6这些数据进入到[0,10)窗口内,此时触发水位线计算,水位线为w(5),没有触发窗口操作。
2)5-9这两个数据进入到[0,10)窗口内,11进入到[10,20)窗口内,此时出发水位线计算,水位线为w(9),没有触发窗口操作。
3)11进入到[10,20)窗口内后,又有一条数据8来到,该条数据进入到[0,10)窗口内。
4)15-16这些数据进入到[10,20)窗口内,此时触发水位线计算,水位线为w(12),当前水位线大于[0,10)窗口的结束时间,触发该窗口的计算和关闭操作。
5)17-20这些数据进入到[10,20)窗口内,此时触发水位线计算,水位线为w(18),不触发窗口操作。其中乱序数据4无法处理。
通过设置水位线延迟等待时间,可以处理一些轻微延迟的数据。如果数据延迟非常严重,在水位线等待时间内还是没有等到对应窗口的数据,又该怎么办呢?
其实水位线触发窗口计算和关闭是两个动作,触发窗口计算之后如果窗口不进行关闭,那么延迟严重的数据还可以通过侧输出流进入到该窗口再次出发计算。Flink也支持设置窗口关闭延迟时间,将窗口关闭延迟时间设置为5s,以上图为例,再次进行数据流处理。
1)2-6这些数据进入到[0,10)窗口内,此时触发水位线计算,水位线为w(5),没有触发窗口操作。
2)5-9这两个数据进入到[0,10)窗口内,11进入到[10,20)窗口内,此时出发水位线计算,水位线为w(9),没有触发窗口操作。
3)11进入到[10,20)窗口内后,又有一条数据8来到,该条数据进入到[0,10)窗口内。
4)15-16这些数据进入到[10,20)窗口内,此时触发水位线计算,水位线为w(12),当前水位线大于[0,10)窗口的结束时间,触发该窗口的计算但不关闭该窗口。
5)数据17进入到[10,20)窗口内,此时又来了数据4,由于当前已经超过了水位线延迟时间,数据无法直接进入[0,10)窗口内。通过侧输出流进入到窗口内再次触发窗口计算。
6)19-20进入到[10,20)窗口内,此时出发水位线计算,水位线为w(18),当前水位线大于[0,10)窗口的延迟关闭时间,关闭该窗口。
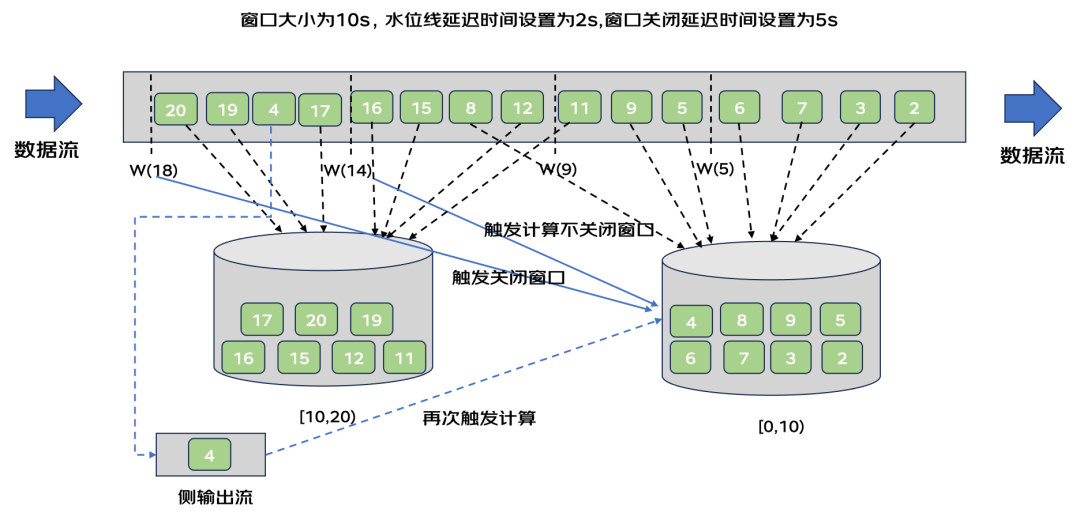
通过设置窗口延迟计算和延迟关闭在一定程度上可以解决数据迟到的问题,在实时计算场景,窗口计算延迟设置不宜过大,否则会失去结果的实时性。
写在最后
由于篇幅有限,这篇文章只介绍了数据计算中的一部分,要想实现容错性高、计算精准的数据计算服务,需要考虑很多场景。例如,算子并行计算时,某个算子突然不可用,如何恢复数据的计算结果?并行算子间,每个算子的计算负载不一致又该如何处理?欢迎大家一起讨论~

