货拉拉大数据新一代基础架构实践与思考
导读:货拉拉大数据团队在成立三年内解决了诸多业内难题,取得了一些阶段性成果。在本次分享中,作者将深入探讨大数据基础架构如何实现高钱效、高运维效率和高分析效率,其中遇到哪些挑战以及解决思路。
01 背景与挑战
1. 货拉拉介绍

货拉拉是一家集货运、搬家、跑腿等业务场景于一体的多边线上交易平台,成立于2013 年,在粤港澳大湾区取得了飞速发展。目前业务已覆盖全球 11 个市场,包括中国及东南亚、南亚、南美洲等地区。货拉拉作为一家拥有 1050 万月活用户、90 万月活司机的货运物流交易平台,拥有 8 条业务线覆盖国内 360 个城市,广阔的业务量带来巨量的数据,目前 1000 多台机器的存储量达 20PB+,7 条 IDC 处理日均 20K+ 的任务。庞大业务量能安全、稳定运转离不开大数据基础架构的支撑

目前货拉拉大数据团队已完成三大体系(大数据安全体系、成本管控体系、稳定性保障体系)和四大支柱(平台服务层、计算引擎层、集群管理&存储层、基础资源管理层)的大数据基础架构建设。
平台服务层提供数据治理能力和基础平台能力服务;
计算引擎层包含离线引擎、OLAP 引擎、(规划中的)AI 引擎;
集群管理&存储层包含在线存储(如 ES 和 HBase)、离线存储(HDFS、云存储)、资源管理(YARN、规划中的 K8s);
基础资源管理层包含基础设施管理体系(主要是货拉拉内部连线的各云厂商提供的物理资源,及对其进行本地化管控的体系),和正在进行中的智能运维体系。
2. 问题与挑战
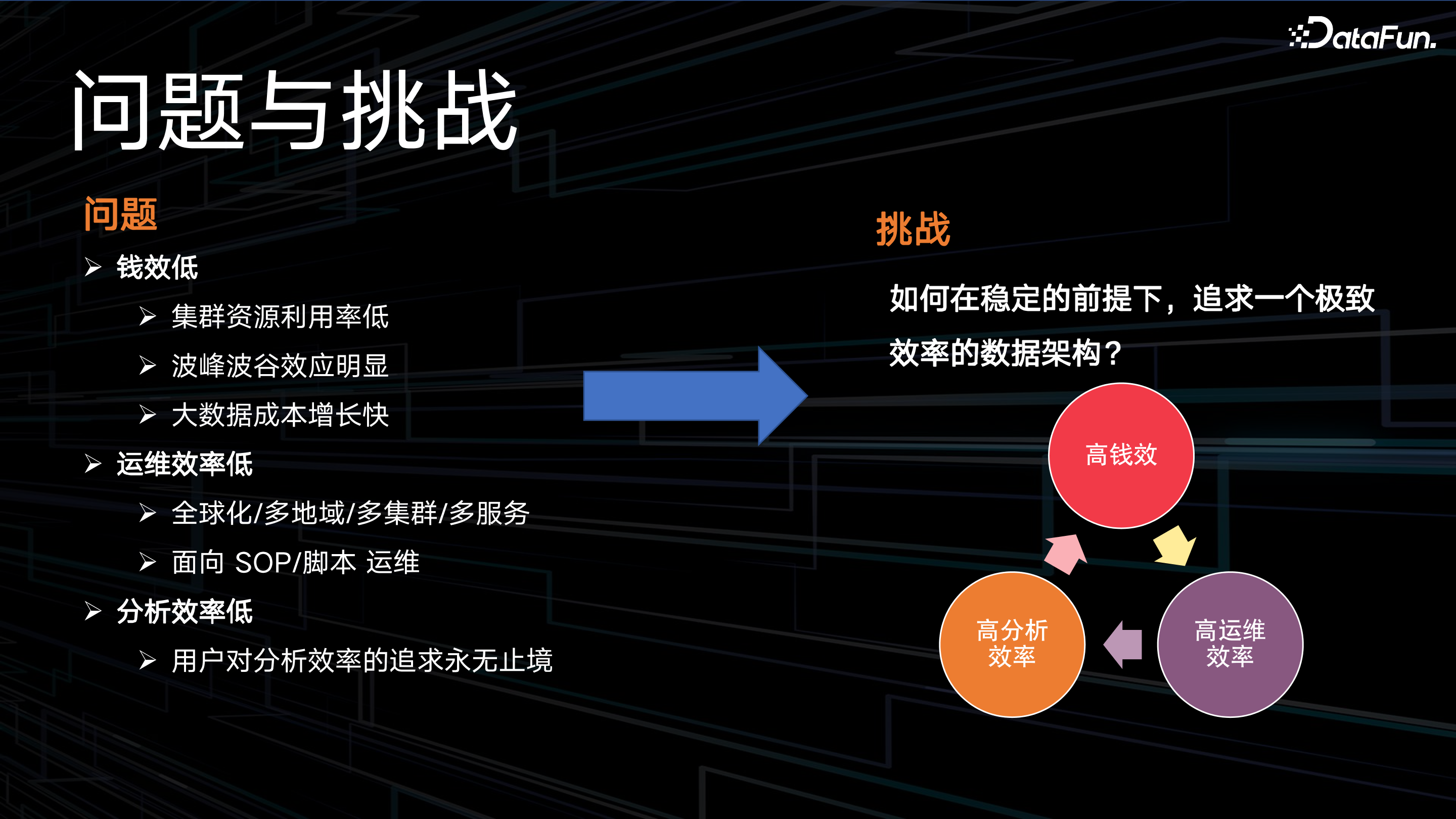
在货拉拉大数据团队建设过程中,面临的问题主要有 3 个:
钱效低,具体表现在:
集群资源利用率低;
波峰波谷效应明显,采用高峰资源保障,带来成本浪费;
大数据成本增长快,缺乏对数据的冷热分层、生命周期的管理;
运维效率低,面对全球化/多地域/多集群/多服务的复杂场景,主要依赖 SOP 和脚本来保障运维,效率低下;同时,运维变更的稳定性比较差;运维人员的工作量繁重,被迫拉长工作时间;
分析效率低,用户经常吐槽查询引擎速度太慢,他们对分析效率的追求永无止境。
那么,如何在保障稳定的前提下,实现高钱效、高运维效率、高分析效率的极致效率数据架构呢?
接下来将分享货拉拉大数据团队展开的探索,以及其中的思考与经验。
02 基础架构实践
1. 高钱效
主要从资源弹性、异构计算两方面实现。
(1)资源弹性
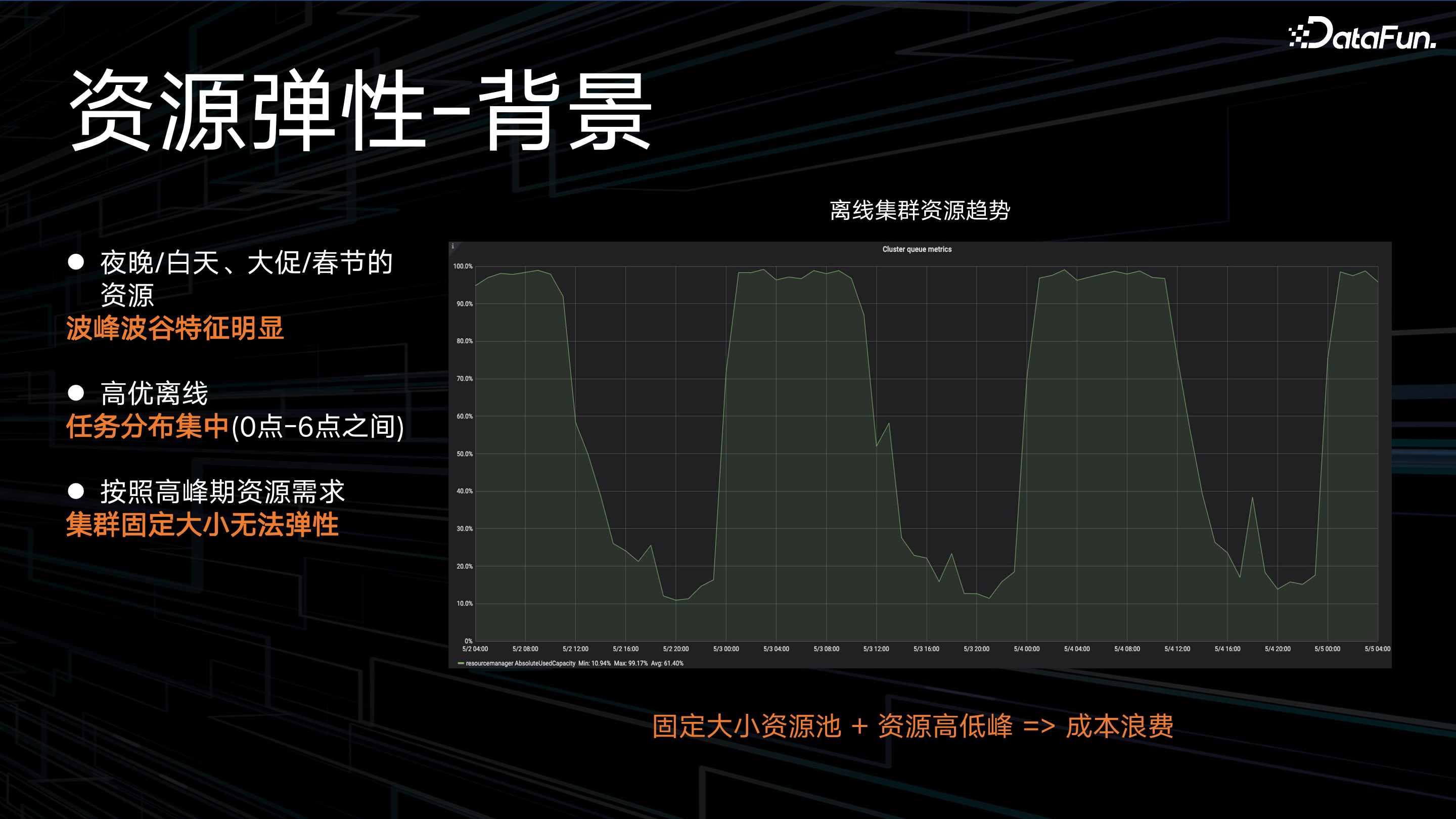
离线计算资源在夜晚/白天、大促/春节等场景下,呈现明显的波峰波谷特征,离线高优任务的分布也比较集中,主要在凌晨到早上 6 点之间。如果按照波峰的资源水平提供保障,就会造成波谷时段的资源成本浪费。如何让固定大小的资源池提供弹性的计算资源成为了当务之急。
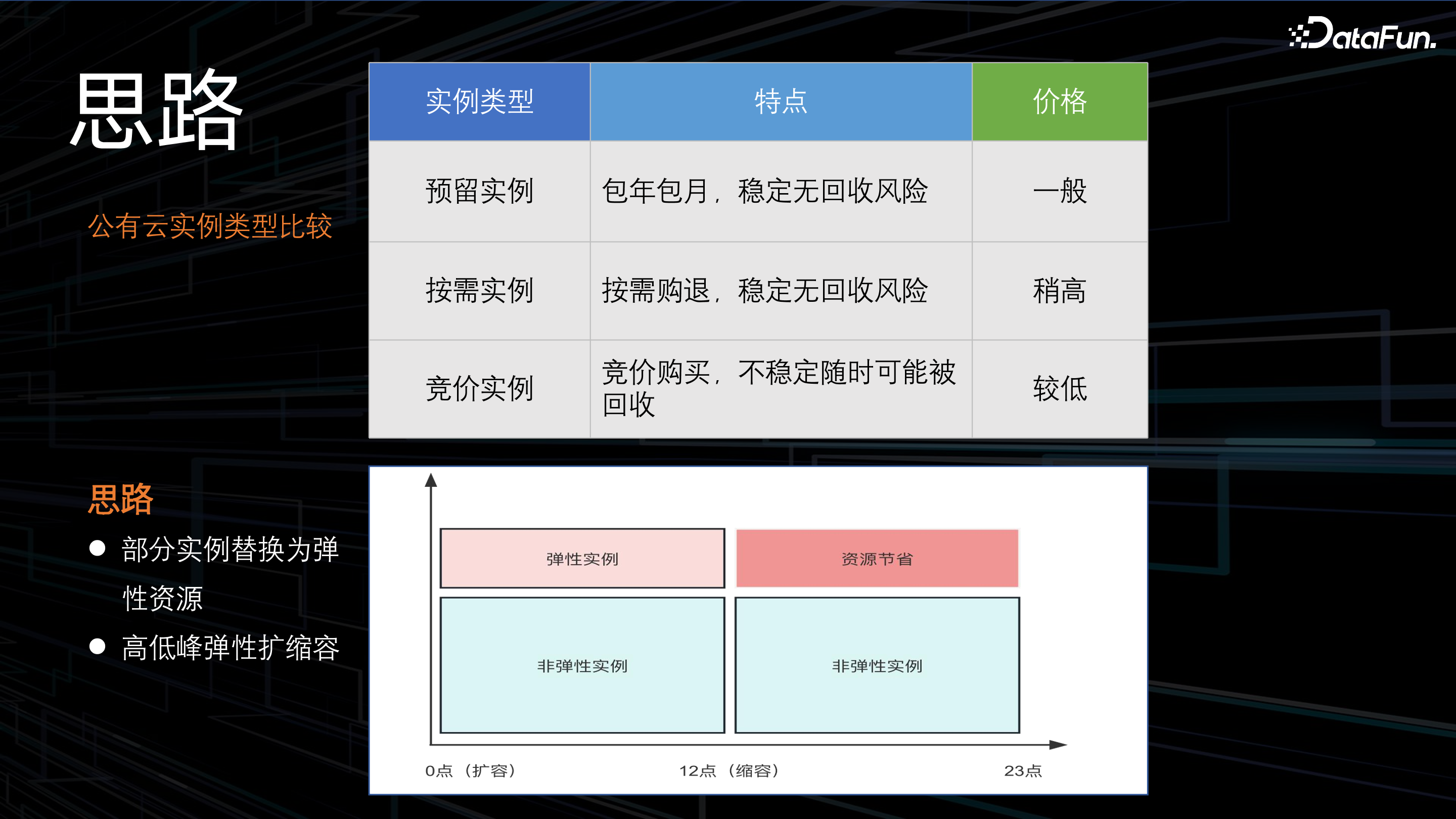
现有公有云能提供的实例主要分为:预留实例、按需实例、竞价实例,相应特点及价格如上。根据各云厂商能提供的实例特点及价格,货拉拉大数据团队将一部分资源实例替换成弹性实例,形成高低峰弹性扩缩容的策略机制。在凌晨至 12 点交易高峰期扩容弹性实例,12 点过后,回收部分弹性实例,进而节省资源。

基于上述策略,通过系统架构实现弹性扩缩容服务,系统包含弹性扩缩容策略和机制的管理,并对弹性实例进行购退对账,防止因遗忘退订弹性实例而造成的资源浪费;结合自动化运维平台,对弹性实例进行购退和上下线;对 YARN 进行优先级调度的改造,调整实例优先级、队列优先级,出现问题时进行调度降级,保证任务稳定性。

通过资源弹性的管理,集群成本节省 20%~30%,并且保证高优作业的稳定性,同时,也提高了弹性资源的利用率。
(2)异构计算
在计算降本方面,除了资源弹性、计算超卖、计算资源治理外,还有什么可优化的手段吗?我们将计算节点机型由 x86 替换为了 ARM,以下是 ARM 和 x86 的优劣势对比:

ARM 在成本和功耗上具有显著优势:ARM 的单核成本相较 x86 至少低 15%,且功耗较低,大量应用于移动端。
但 ARM 的整体软件兼容性较差,部分需要适配;同时业内服务端使用较少。
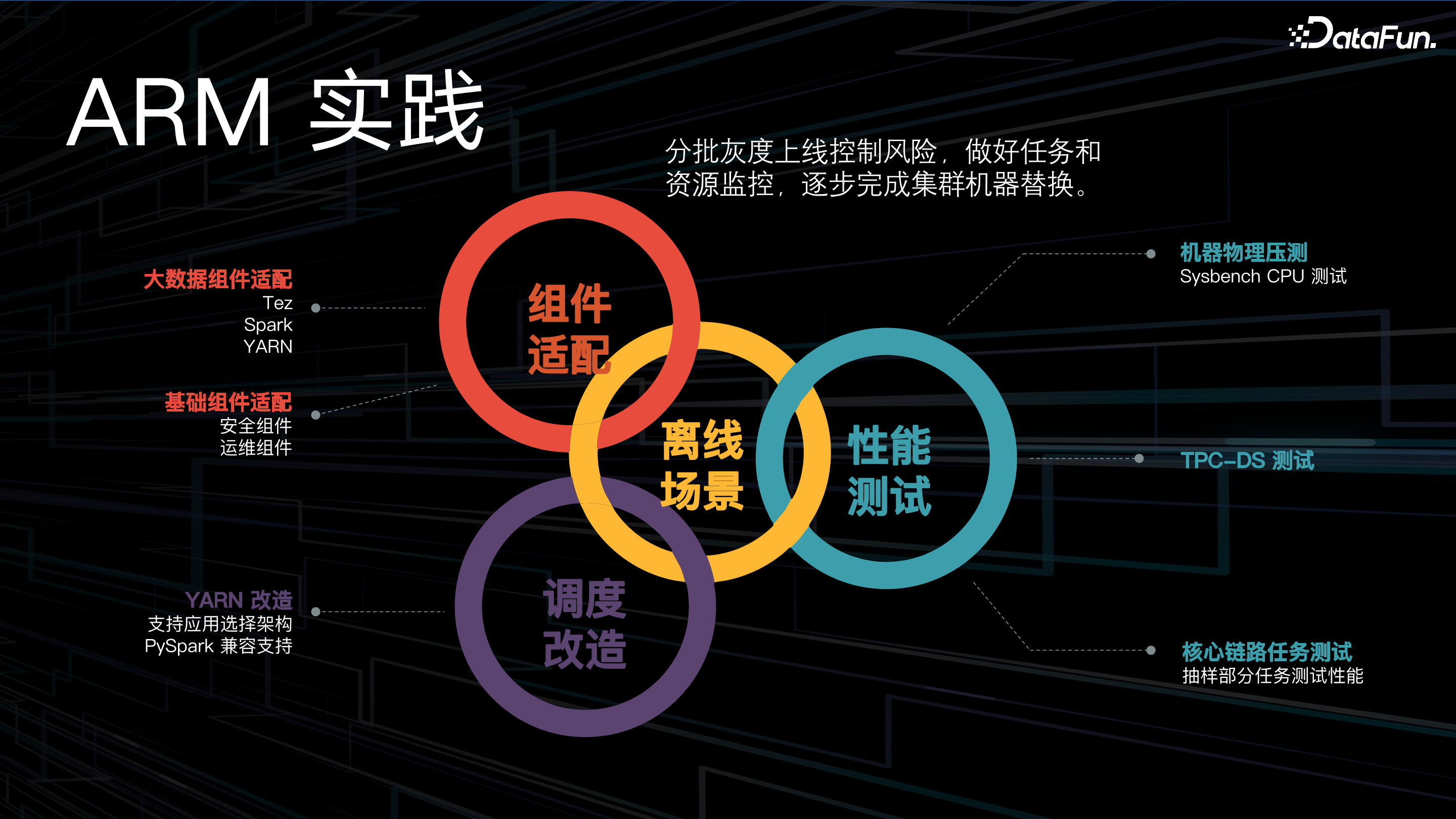
货拉拉大数据团队将 ARM 成功应用到大数据架构中,主要做了三部分工作:
首先,组件适配,包括大数据组件适配,例如目前主要使用的计算引擎 Tez、spark、YARN(某些 java 包等);和基础组件适配,例如公司级的安全组件、运维组件等。
第二,在调度改造方面,支持用户在应用层选择架构,同时也完成了对 PySpark 的兼容支持;
最后在机器物理资源压测、TPC-DS 压测、核心链路任务的抽样测试后发现,使用 ARM 节点后集群性能没有明显下降。
整体 ARM 实践的上线策略遵循分批灰度上线,控制风险,并对任务和资源进行监控,最后逐步完成了集群机器替换。
这里分享一个问题:在灰度上线的过程中,团队发现带窗口函数的 SQL 在物理资源使用正常的情况下,task 的运行时长会被拉长 10 倍。
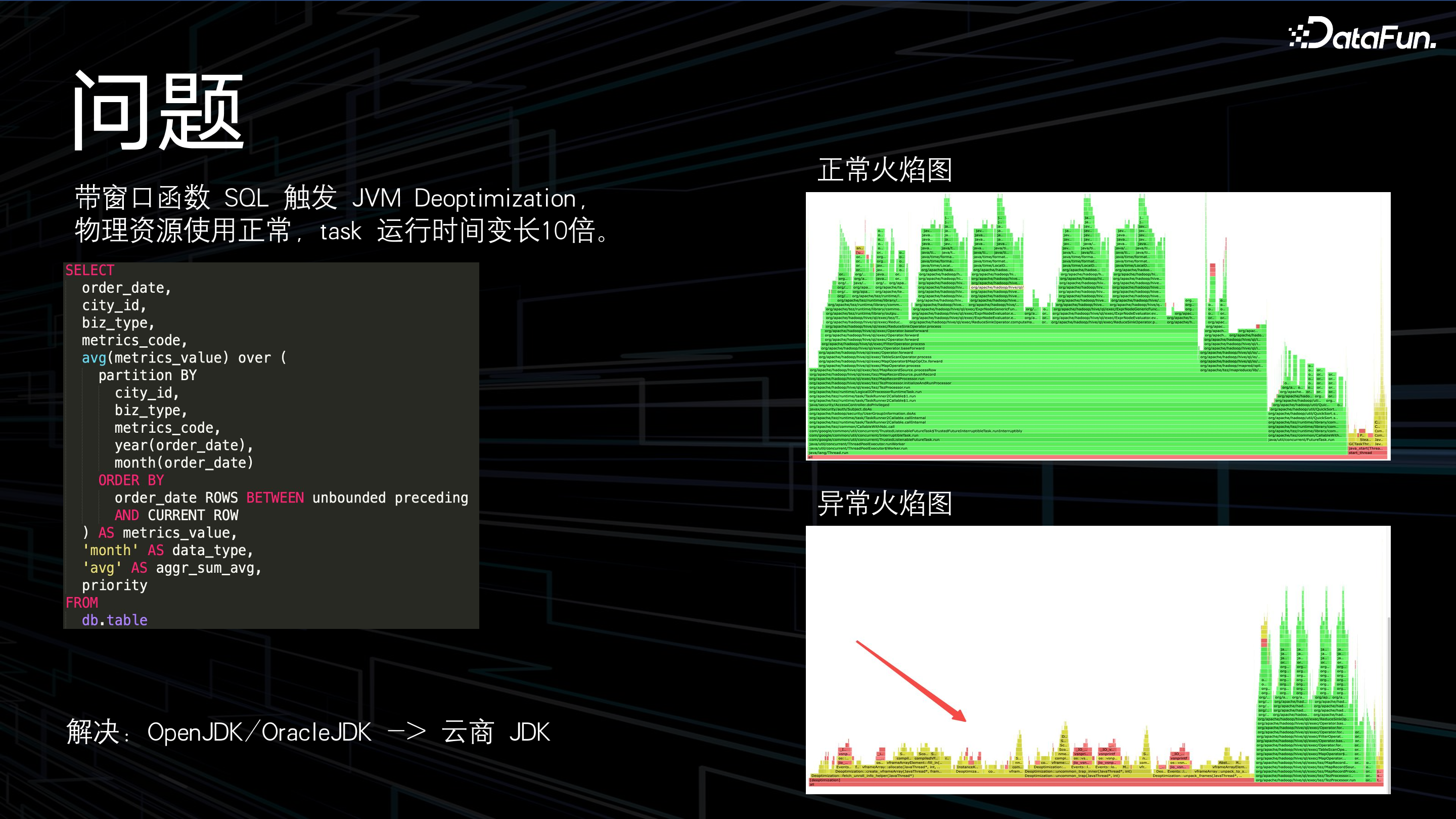
通过对比火焰图,发现这种 SQL 触发了 JVM 的逆优化,导致大部分 CPU 时间消耗在 JVM 的代码中。对于此问题的一个解决方案是,将 ARM 的资源版本替换为云厂商的版本。
最终在团队的努力下,完成了离线计算 50%ARM 机型的替换,集群成本节省 10%(大概百万/年的水平),之所以替换 50%,是因为受限于云厂商的供给。上线 ARM 机型后,未出现高优作业的延迟故障。
2. 高运维效率
主要从大数据自动化运维、大数据云原生两方面实现。

(1)大数据自动化运维
团队内部大数据运维复杂度很高,面对的是 3 个业务线、30 多套集群、20 多个服务组件、上千个节点的复杂环境,且组件之间的运维流程不能复用;在如此复杂的场景下,运维主要依赖大量的 SOP,步骤复杂、人工操作、脚本不灵活;使 SRE 方向的同事超过 70% 的工作时间投入到事务型的运维工作场景中,员工幸福感很低。
根据下图可以感受一下运维场景的复杂度,如 HBASE 版本发布的工作流:
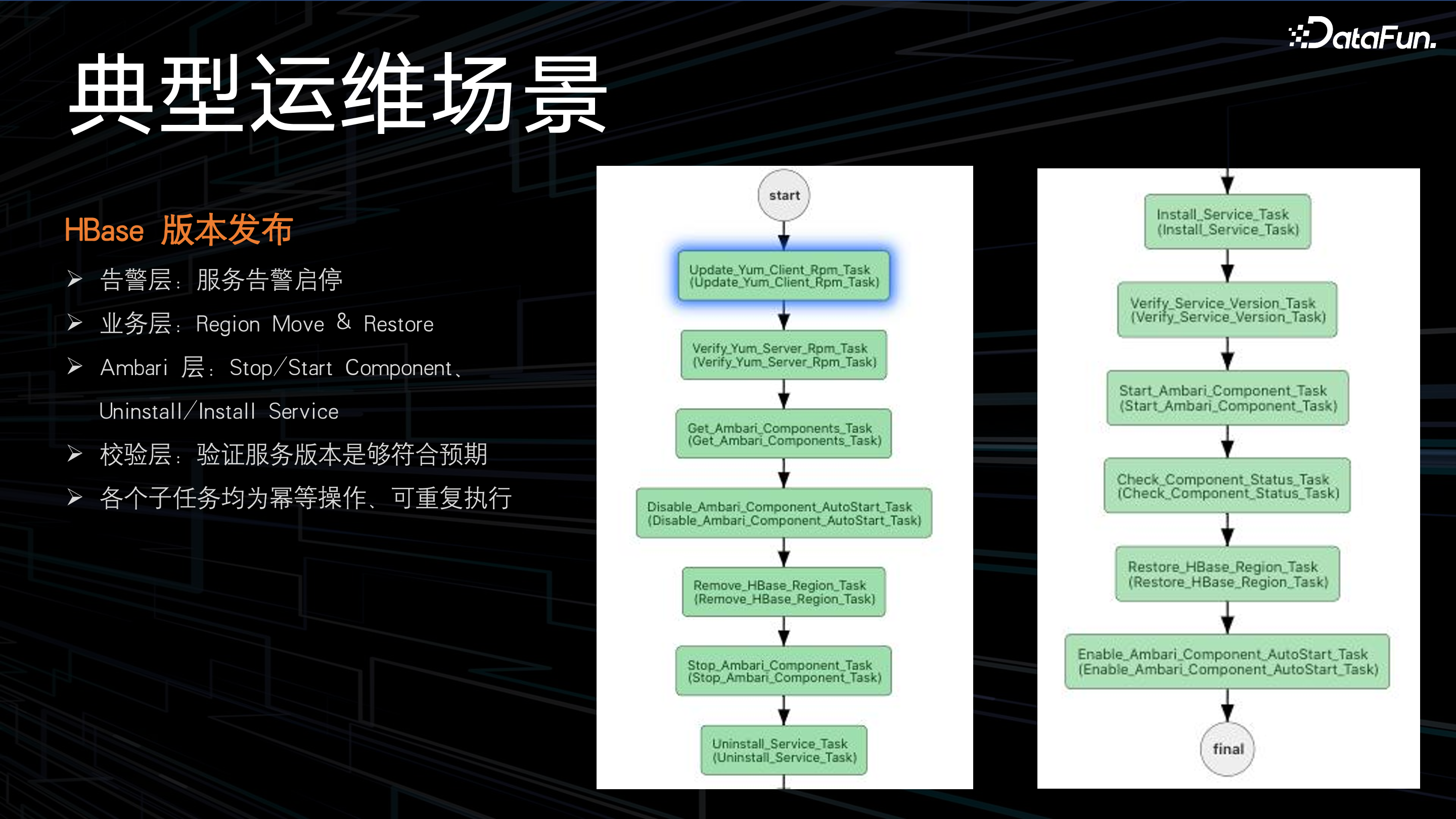
在如此复杂、低效的场景下,如何尽快实现自动化运维呢?

首先,需要构建集群的资产管理能力,可以统一资产管理入口,并对资产进行全生命周期管理;
然后,在工作流编排能力上,将 SOP 和运维脚本固化成工作流,使其具备分布式调度执行的能力;
最后,优先完成高优高频场景的自动化改造,快速提升运维效率。

通过实现大数据自动化运维在典型的场景上提效非常明显。
(2)大数据云原生
大数据领域主要关注的问题就是容器化和 DevOps,相对应的就是成本和效率。在成本方面,将 YARN 替换成 K8s,统一在离线资源池,为在离线混部打下基础;运维效率方面,面向 K8s 的运维比面向传统机器的运维要方便很多。
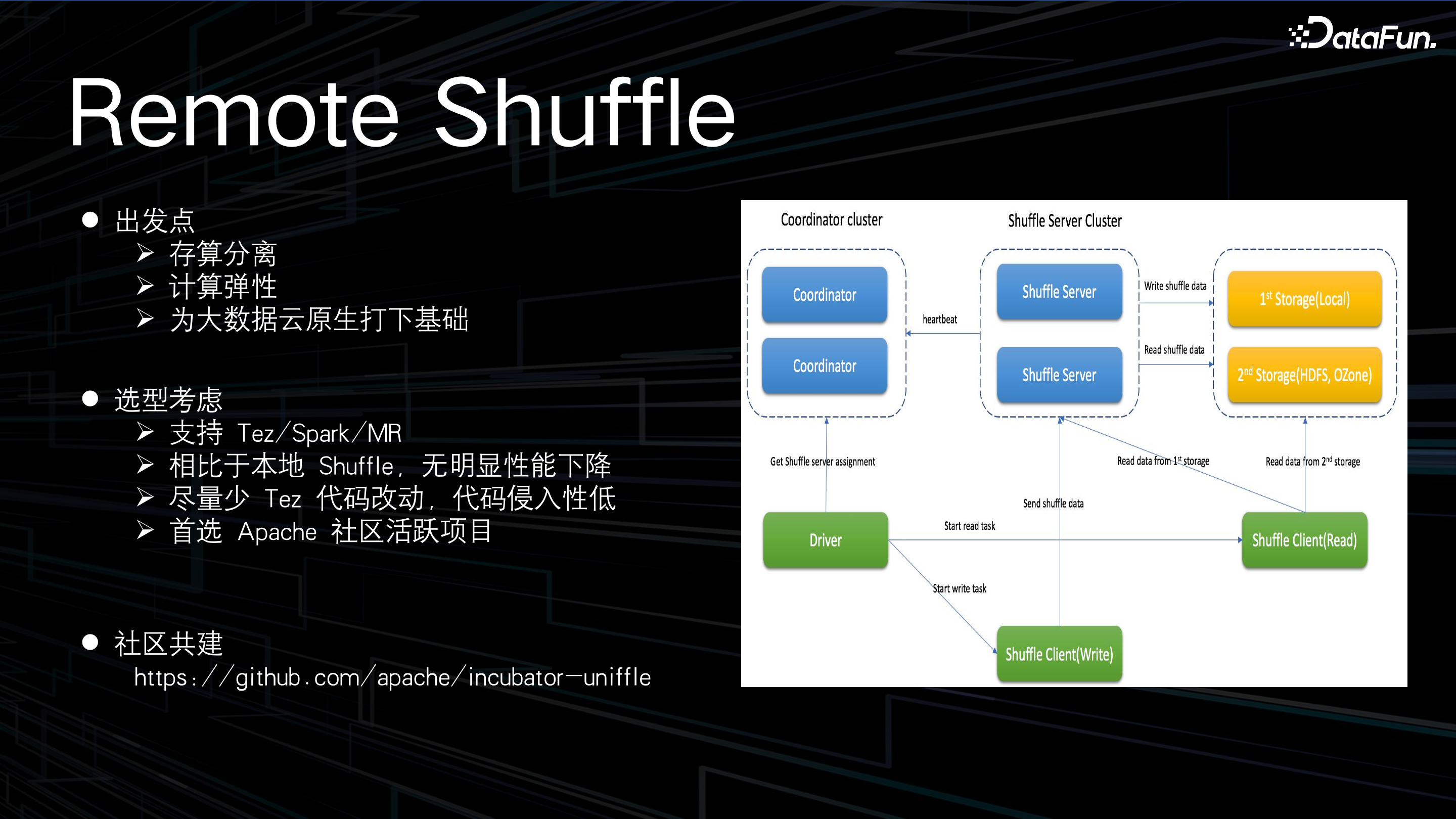
之所以做 Remote Shuffle 框架,主要基于以下考虑:
出发点是将计算节点本地的 shuffle 数据保存到远端,本地的计算节点就可以实现无状态化,计算节点便可进行容器化部署,为大数据云原生打下基础。
因为货拉拉使用 Tez 计算引擎,在选型方面主要考虑:通用性,能支持 Tez、Spark、MR;相比本地 shuffle,无明显性能下降;提供高可用的能力,且对 Tez 源码尽量少改动、侵入;首选 Apache 社区活跃项目。
经过对业界 RSS 框架的对比,与社区进行深度共建,最终选择腾讯开源的 Uniffle 框架,团队牵头设计 Tez Client 方案,向社区贡献了近 2 万行代码,成功让 Uniffle 框架支持 Tez。目前 RSS 在公司内部逐步灰度上线中。除了 RSS 外,团队还实施了 Flink on YARN 替换成 Flink on K8s 的方案。
3. 高分析效率
即引擎提效。
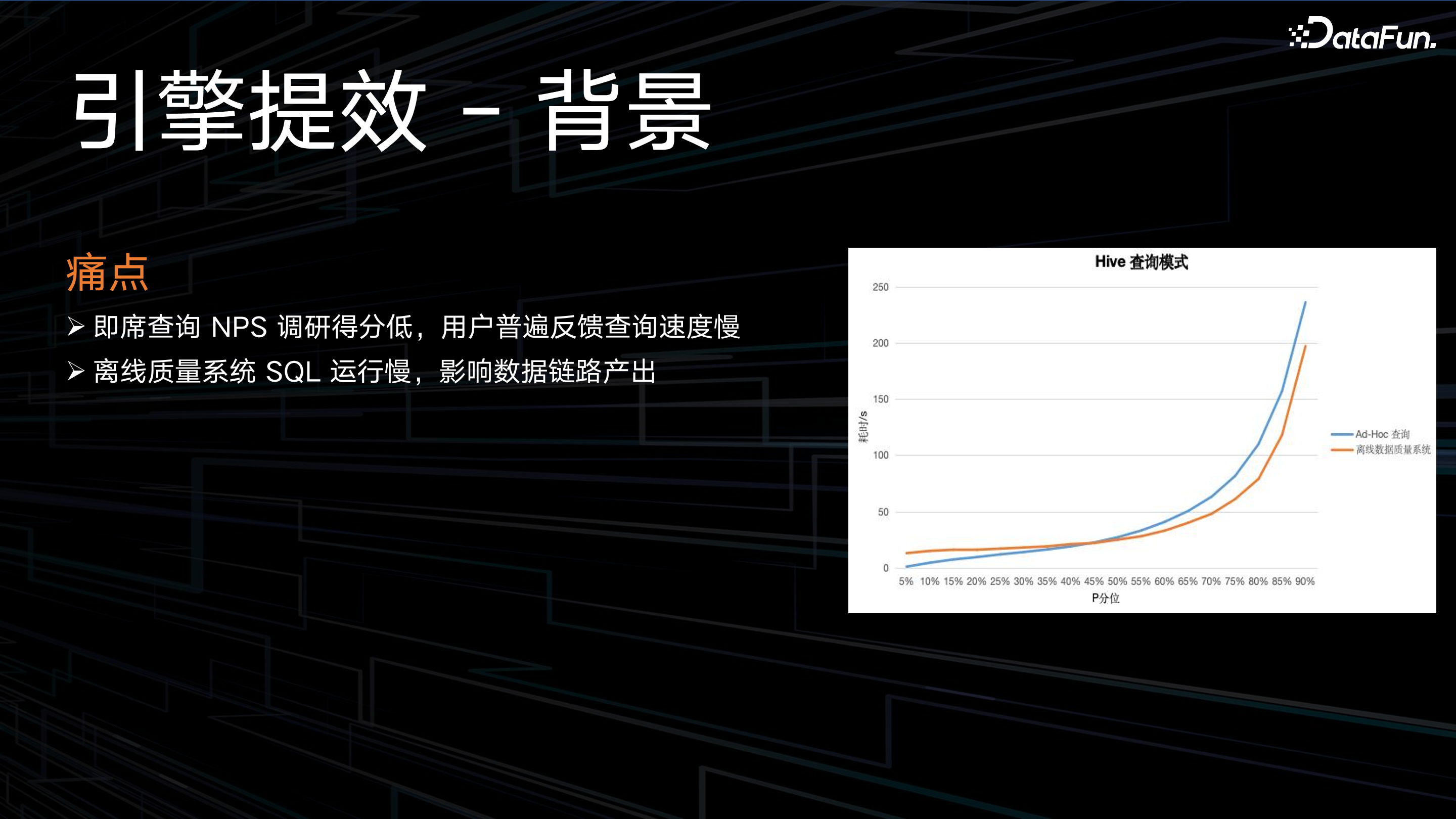
用户在即席查询过程中,经常遇到的一个痛点就是查询速度慢。在离线 ETL 链路中,团队会对一些库表进行数据质量的校验,如果 SQL 运行慢,也会影响数据链路的产出。
针对用户的痛点,团队开发了离线混合引擎服务。
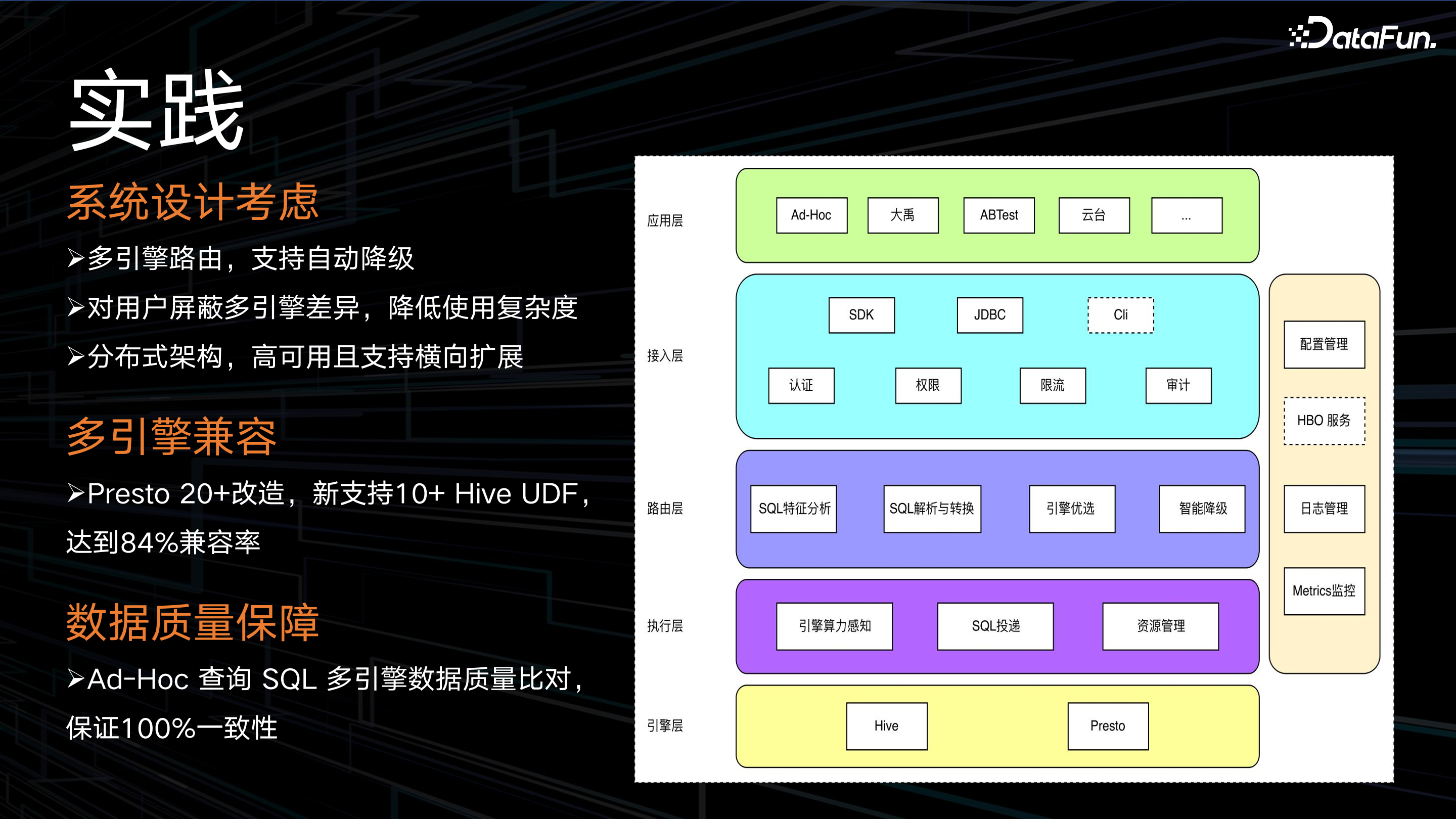
在系统设计时,主要考虑以下三点:
多引擎路由,支持自动降级。主要思想是根据各引擎优缺点,将 SQL 路由到最适合它的计算引擎上。通过观测 SQL 的执行计划,查询数据扫描量和算子分布,匹配路由策略,最终分配到合适的计算引擎上。如果 SQL 执行失败,将自动降级到其他引擎。若所有引擎都执行失败,由 Hive 做兜底,保证执行成功。
对用户屏蔽多引擎差异,降低使用复杂度。不会更改用户使用习惯,用户以 Hive 语法编写 SQL,后台进行 SQL 转化,对用户屏蔽多引擎语法的差异。
分布式架构,高可用且支持横向扩展。为了应对未来的大规模需求。
另外,实现了多引擎兼容。通过对 Presto 进行 20+ 改造,包括 Hive 隐式转换的适配、Hive 视图的适配、对齐 Hive 的 UDF 语义等,最后达到了 84% 的兼容率。
数据质量保障方面,系统在灰度上线之前,将线上真实的 Ad-Hoc 的 SQL 查询进行多引擎数据对比,保证 100% 通过数据质量校验。

目前 Presto 路由率 * Presto 成功率能够达到 70%,并且在重点场景提效明显。
03 总结与思考
高钱效、高运维效率、高分析效率这三大目标驱动了货拉拉大数据基础架构的演进。
实践证明,要通过明确的收益驱动基础架构演进,引入新技术前多思考,不能贸然引进一些火热的新技术。目前货拉拉还未引进湖仓一体,因为其收益尚未明确。在成本和稳定性的基础上,只要领先业务“半步”即可,不需要过度演进。
04 未来展望
最后,对未来工作的规划主要包括以下几大方面:

1. 引擎提效
离线计算引擎由 Hive 迁移到 Spark。
2. 极致弹性
根据负载压力更精准、及时地弹性伸缩。
3. 大数据智能化运维
继续完善对云原生场景的支持,实现数智化运维(AIOps),做到故障自愈、全链路诊断。
4. 离线混部
完善大数据全面云原生化,继续探索符合业务场景的在离线混部策略。
5. 流批一体&湖仓一体
进一步探索符合业务需求的落地场景。

