一 背景
在稳定性保证中,重要的一个环节就是故障管理体系建设,故障管理体系的四大核心功能——故障发现、故障触达、故障定位和故障恢复,其中故障发现作为故障管理的第一步至关重要,包含了指标预测、异常检测和故障预测等方面,主要目标是能及时、准确地发现故障。今天主要针对故障发现环节中的异常检测介绍AI异常检测算法在指标检测上的应用。
传统基于阈值的异常检测方法的缺点:
比较依赖个人经验,需要了解指标的历史趋势。
配置比较复杂,有时对周期波动型的时序数据还要针对不同的时间段配置不同的阈值。
随着业务的变更要不断调整阈值,随着时间推移、业务的变更,观测指标趋势也可能发生改变,要对阈值做相应的调整。
受大促或异常值影响比较大,像有些阈值配置同比或者环比,如果上一时刻或者历史同时刻有数据有异常,会影响该时刻的检测判断。
对比固定阈值的检测,AI检测算法在突增、突降等异常检测场景中可以很好地解决上述问题。下面会针对AI检测算法在可观测性产品中的应用做相关的介绍。
二 异常检测算法
AI异常检测算法之前,通常需要对历史数据做预处理,包括异常值的剔除,缺失值的填充等。
异常值剔除
这时可能大家会有疑惑,做异常检测为什么还要剔除异常值,这里的异常值是指作为参照的历史数据中的极值,剔除极值可以减少极值影响,去除异常值有助于提高异常检测算法的准确性。
箱型图
箱型图不需要考虑数据集的分布情况,它是通过将数据分成四分位来衡量统计分散度和数据可变性,是一种简单有效的异常点剔除算法。

下四分位数:25%分位点对应的值(Q1)
中位数:50%分位点对应的值(Q2)
上四分位数:75%分位点对应的值(Q3)
上须:Q3+1.5(Q3-Q1)
下须:Q1-1.5(Q3-Q1)
如上图所示,大于上须的值或者小于下须的值我们认为是异常值。
考虑3sigma跟箱型图算法的特点,箱型图可能更加具普适性,因为它不用考虑数据集的分布情况,在实际应用中我们也是采用的箱型图算法来剔除异常点。剔除异常值后需要对缺失值进行填充,确保数据的连续性,防止后续检测算法在处理时报错,通常缺失值填充的方法有:
前后填充法,使用前一个值填充或者后一个正常值填充。
均值、中位数填充法。
插值法,插值法有线性插值和多项式插值。线性插值就是通过线性回归预测缺失位置的值,多项式插值使用多项式回归预测缺失位置值。
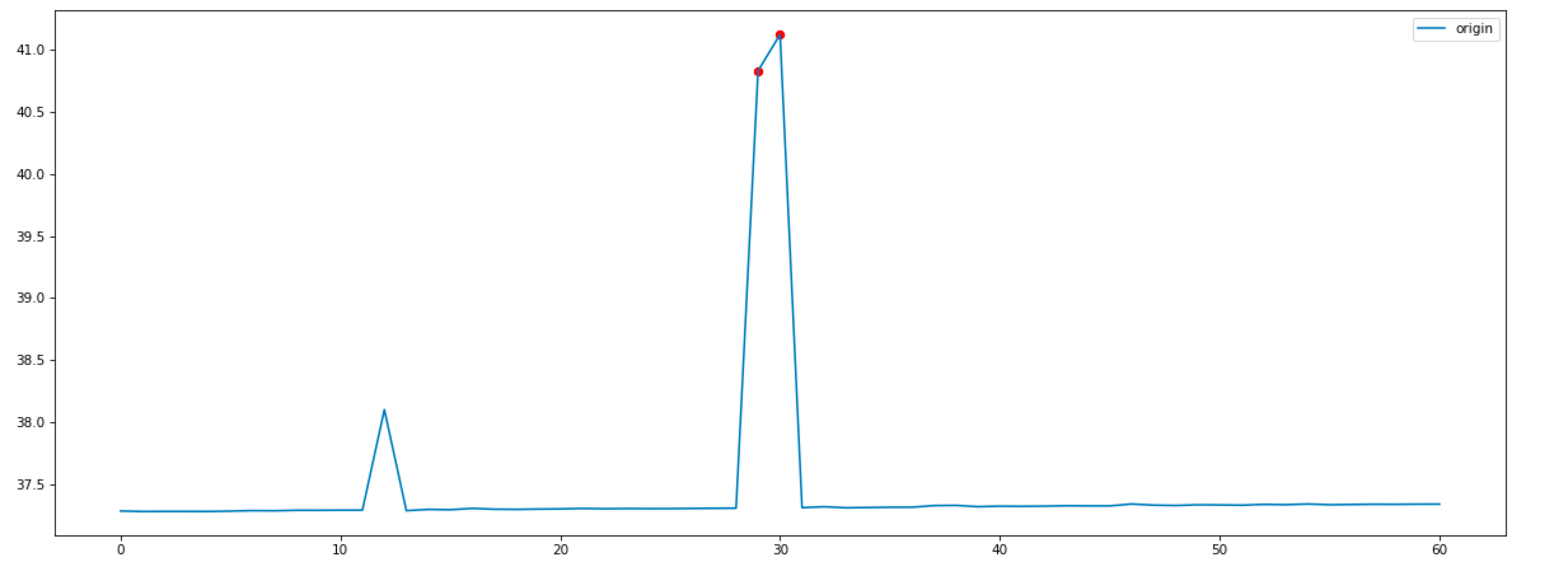
下面是我们采用箱型图剔除异常点并采用多项式插值的效果:

蓝色的线是原始的观测值,红色的点是检测出的异常点,黄色的线是通过插值法填充后的结果。数据预处理后,利用预处理后的结果进行异常点检测。
统计方法的应用
对观测数据进行分析,大部分的指标有周期性和趋势性。

可观测性产品中异常检测主要采用的统计方法,包括3sigma和zscore变点检测算法。
3sigma算法
3sigma算法是考虑如果数据集分布属于正态分布,数据点落在偏离均值正负1倍标准差(即sigma值)内的概率为68.2%;数据点落在偏离均值正负2倍标准差内的概率为95.4%;数据点落在偏离均值正负3倍标准差内的概率为99.6%,意思是数据点落在偏离均值正负3倍标准差之外的概率非常小,可以认为这些数据点为极端异常点。通过下面的标准正态分布的概率密度图可以很好地理解该算法。

通过观察发现,可观测性平台的大部分指标,从时间纬度纵向分析(历史同一时刻)符合正态分布,但横向来看并不符合正态分布。
以创建订单QPS指标为例,获取过去60天同一时刻10点整的QPS观测数据,通过Python绘制直方图,并通过KS算法做正态分布验证:

从直方图上看数据基本符合正态分布,用KS算法验证得到pvalue,pvalue>0.05符合正态分布特征。

所以我们可以采用3sigma算法对绝大部分指标做纵向的异常点检测。
接下来我们横向分析数据的分布情况,首先分析完整一天的数据是否符合正态分布,以订单QPS为例:

按照上述的方法绘制直方图,并通过KS算法验证是否符合正态分布。

从直方图上看横向看QPS指标并不符合正态分布。用KS算法验证得到pvalue,pvalue<0.05所以不符合正态分布。

接下来分析连续30个点的数据,看是否符合正态分布。还是以创建订单QPS为例,获取11:31:00~12:03:00时间点的数据绘制直方图。

从图形上看基本符合正态分布情况,KS算法检测是否是正态分布,可以看到连续30个点数据集符合正态分布。

结合上述分析,我们对观测指标的检测分为两步:
纵向,获取历史同一时刻30个点的观测值,通过3sigma算法来检测异常。
横向,zscore算法进行变点检测,横向获取某个时刻往前历史30个点的观测值。
最后,借助纵向和横向检测结果联合决策某个点是否异常。
zscore 算法
横向异常检测我们采用zscore算法,横向检测我们采用过去30个点的数据,具体做法:
过去30个点数据按窗口做平滑处理,窗口大小为3;
平滑后的数据前后做差值;
对差值数据集计算zscore,zscore的计算公式为:
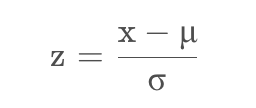
使用正态分布生存函数计算zscore的右尾概率,判断概率是否大于0.01,小于0.01则为异常。
以创建订单QPS为例,获取2024-01-15 14:00:00点历史30天同一时刻的值使用3sigma检测逻辑为:
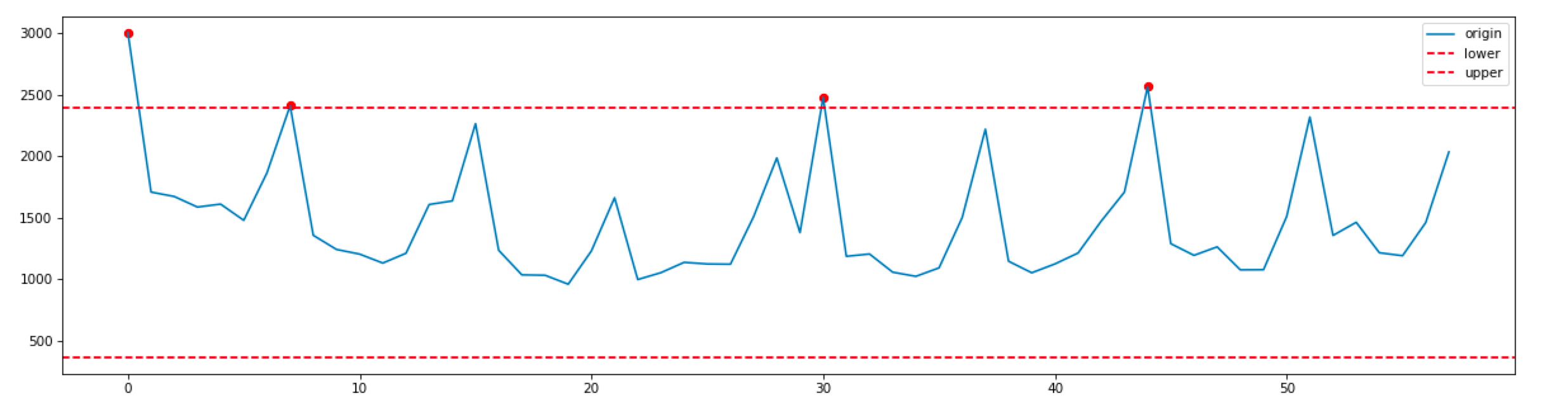
使用zscore算法检测2024-01-14 11:31:00~2024-01-14 12:03历史32个点的异常情况如下:

以上横向和纵向的算法可以解决大部分的观测指标的异常检查,但是像有些指标波动一直都特别小,如内存指标,见下图:
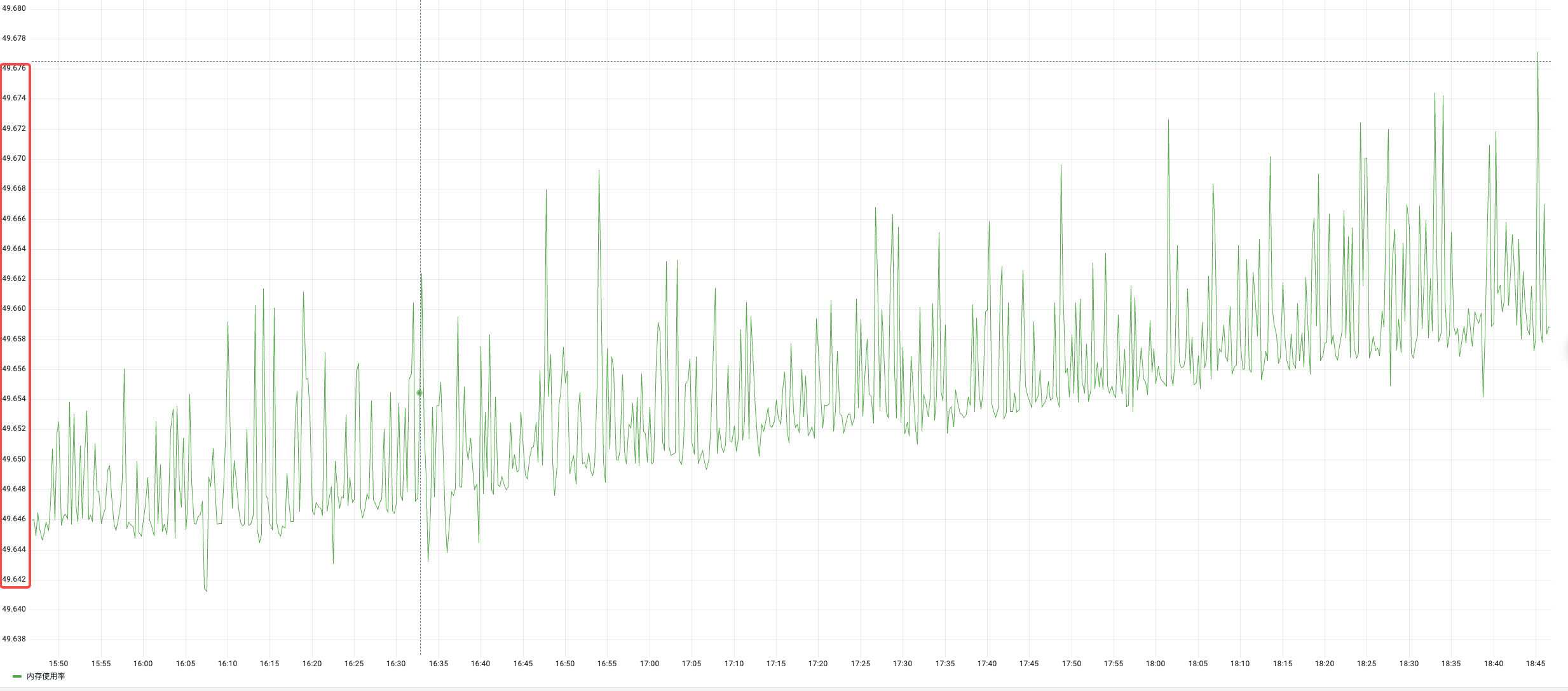
使用3sigma统计方法检测异常点得到如下结果:
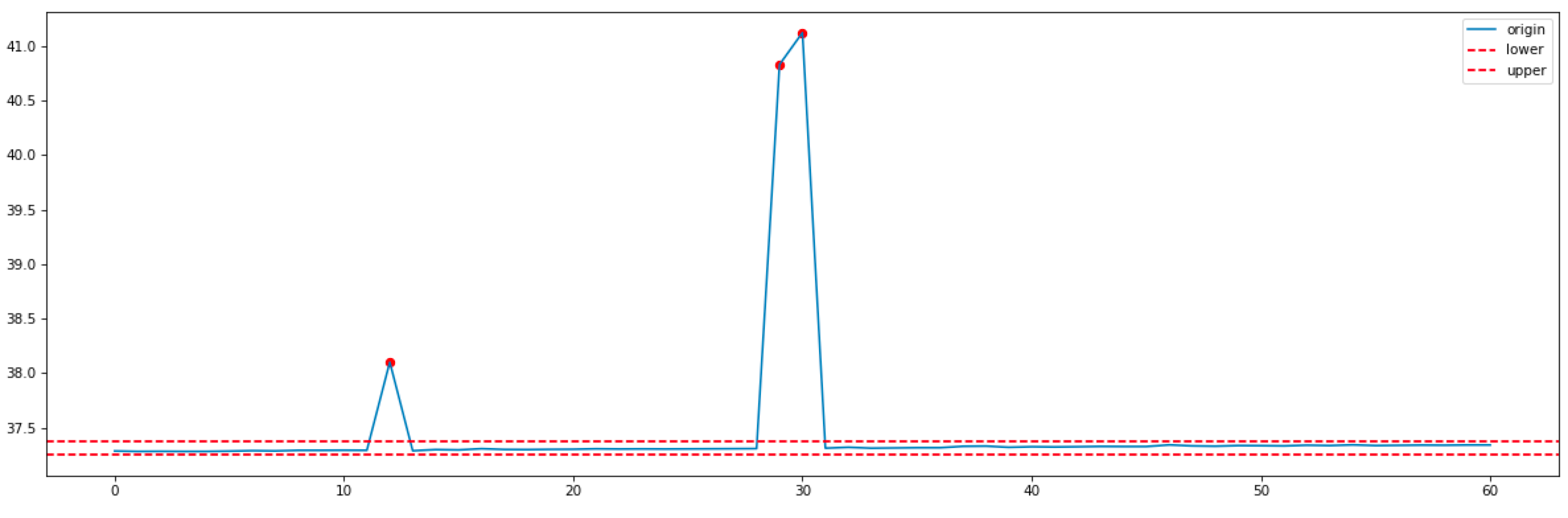
可以看到3sigma计算的上下限非常小,上下限接近1左右,这导致这种指标的检测异常点非常多。因此,我们探索使用其他复杂的算法,比如机器学习的算法来解决。
机器学习方法的应用
异常检测统计方法对于某些特殊场景可能存在检测误差大、噪音多等问题,所以我们探索了机器学习检测算法,考虑到观测数据大多是没有标注的,而且获取标注的成本也比较高,我们主要考虑无监督的算法,针对孤立森林做了研究和应用。
孤立森林
孤立森林算法,一种适用于连续数据的无监督异常检测方法。该算法不借助类似距离、密度(LOF,K-means)等指标去描述样本与其他样本的差异,而是直接去刻画所谓的疏离程度(isolation),因此该算法简单、高效。而且该算法鲁棒性高且对数据集的分布无假设。
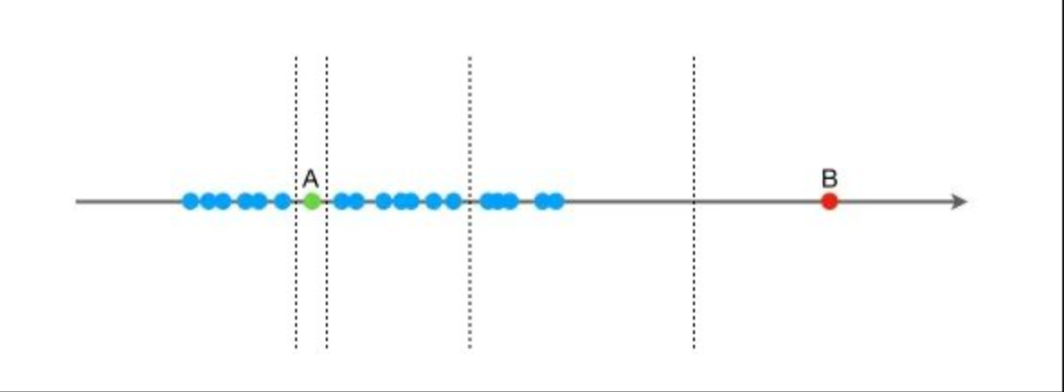
孤立森林算法的思想:假设现在有一组一维数据(如下图),我们要对这组数据进行切分,目的是把点A和B单独切分出来,先在最大值和最小值之间随机选择一个值X,然后按照=X可以把数据分成左右两组,在这两组数据中分别重复这个步骤,直到数据不可再分。点B跟其他数据比较疏离,可能用很少的次数就可以把它切分出来,点A跟其他数据点聚在一起,可能需要更多的次数才能把它切分出来。那么从统计意义上来说,相对聚集的点需要分割的次数较多,比较孤立的点需要的分割次数少,孤立森林就是利用分割的次数来度量一个点是聚集的(正常)还是孤立的(异常)。
在实际应用中Python sklearn已经对孤立森林算法做了支持,我们只需要对算法中的参数做些调整就可以。sklearn IsolationForest算法的参数包括:
n_estimators:int,optional(default=100),iTree的个数,指定该森林中随机树数量。
max_samples:int or float,optional(default="auto")构建子树的样本数,整数为个数,小数为占全集的比例,用来训练随机数的样本数量。
contamination:float in(0,0.5),optional(default=0.1)表示异常数占给定数据集的比例,数据集中污染的数量,其实就是训练数据中异常数据的数量,定义该参数值作用是决策函数中定义阈值。
max_features:int or float,optional (default=1.0)构建每个子树的特征数,整数位个数,小数为占全特征的比例,指定从总样本X中抽取来训练每棵树iTree的属性的数量,默认只使用一个属性,如果设置为int整数,则抽取max_features个属性;如果是float浮点数,则抽取max_features * X.shape[1]个属性。
bootstrap:boolean,optional (default=False)采样是有放回还是无放回,如果为True,则各个树可放回地对训练数据进行采样。如果为False,则执行不放回的采样。
n_jobs:int or None,optional (default=None) 在运行fit()和predict()函数时并行运行的作业数量。除了在joblib.parallel_backend上下文的情况下,None表示为1。设置为-1则表示使用所有可用的处理器Random_State : int, RandomState instance or None, optional (default=None)每次训练的随机性,如果设置为int常数,则该Random_State参数值是用于随机数生成器的种子;如果设置为RandomState实例,则该Random_State就是一个随机数生成器 如果设置为None,该随机数生成器就是使用在np.random中的RandomState实例。
verbose:int,optional (default=0)训练中打印日志的详细程度,数值越大越详细。
warm_start:bool,optional (default=False)当设置为True时,重用上一次调用的结果去fit,添加更多的树到上一次的森林1集合中;否则就fit一整个新的森林。
我们主要调整contaimination来控制异常检测算法的阈值大小,实际应用中我们定义contamination值为0.01,相对比较严格的检测阈值。针对统计算法中检测波动比较小的内存使用率,再用孤立森林做检测得到的结果如下:
对比3sigma统计算法,孤立森林相对检测更加严格,像index为12的突刺异常噪音点没有被检测出来。
统计算法相对机器学习算法算法复杂度低,检测速度快,而且具有比较强的解释性,而机器学习算法跟统计算法比鲁棒性更强对数据集的分布没有要求,但是解释性比较低。结合两类算法的优缺点我们通用的异常检测策略中会结合两种检测算法做联合决策,来提高检测的准确性。
深度学习方法的应用
另外,针对一些核心场景,比如登陆、商品详情、下单、供应链等这些场景,要求预测的准确性要特别高,同时告警噪音小,我们在深度学习算法领域也做了些探索,像LSTM、transformer,其中主要针对近期热门的transformer模型以及变种进行了探索和实验,最终通过实验采用了效果相对比较好的pyraformer。pyraformer使用了金字塔结构的注意模块,可以很好地捕获长期依赖性,同时有较小的时间复杂度和空间复杂度,具体关于pyraformer的理论介绍,感兴趣的可以参考pyraformer相关论文或文章,这里只介绍我们对pyraformer做的一些小改动。
我们采用pyraformer做指标预测的方式主要是基于预测值计算上下限,开源的pyraformer是不支持上下限预测的,具体的做法是:
通过预测历史时刻的预测值,同观测值做差值计算,计算结果作为一个新的误差指标写入到时序数据库中。
预测未来某个时刻的值时,通过第一步的误差指标获取最近的30个点误差值,计算30个误差点的标准差作为sigma,然后该时刻的预测值加减3倍的sigma就计算得到了上下限。
下图为某个核心场景的预测效果:
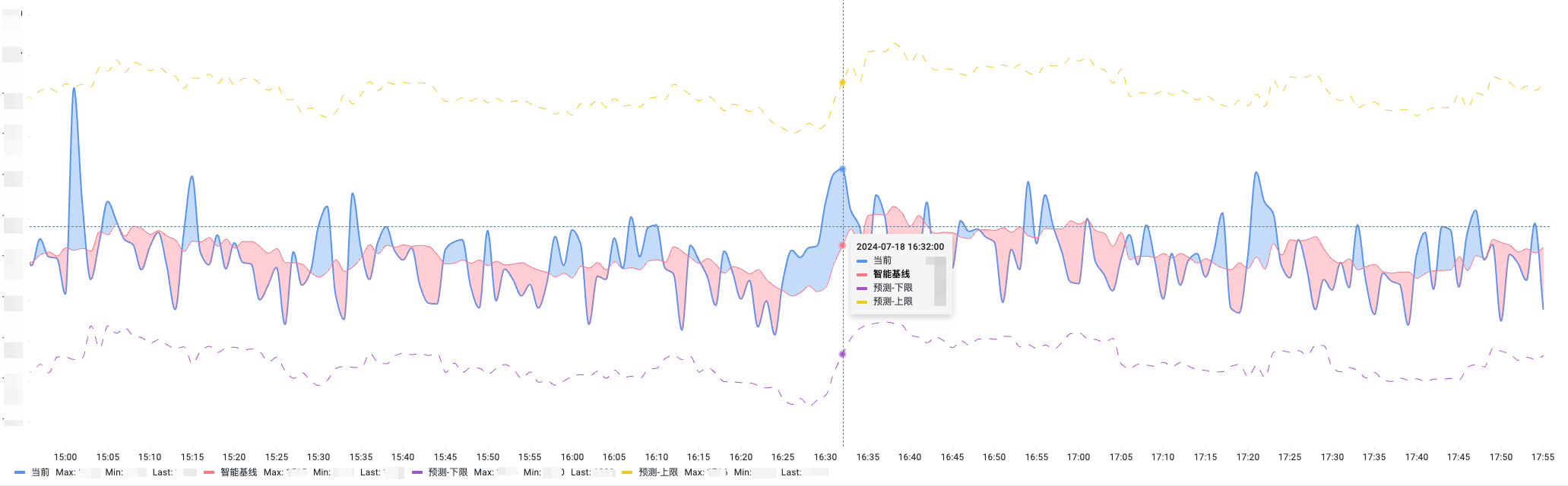
目前该算法已经应用到了50+个核心场景的日常告警中,算法应用之后,核心场景的告警误报减少了 50%以上。
三 总结和展望
目前,异常检测算法主要应用在两个方面,一个是核心场景风险感知场景,主要检测应用的QPS的突增&突降检测、RT、错误率、错误码、异常数、CPU、内存的突增检测场景中,异常检测准确率达90%以上;另一个是在应用发布变更的风险感知场景,在发布批次结束,针对变更后的实例检测、RT、错误率、异常数等有无突增异常,防止问题代码发布上线造成更大的影响。未来我们会持续在AI检测算法和预测算法上进行研究,并在更多场景落地。另外,我们在故障触达、故障定位方面也在做探索,在一些场景上取得了较好的效果,后续会单独拿出来做分享。

