彻底解决网络哈希冲突,百度百舸的高性能网络HPN落地实践
GPU 的通信性能对于大模型的训练有着至关重要的影响。在 HPN 网络工程实践中,我们的核心关注点是如何充分利用网络硬件资源的能力,将通信性能最大化,从而提升大模型端到端的训练性能。
1 HPN 网络 — AIPod
下图是百度百舸的高性能网络 HPN — AIPod 的架构示意图。AIPod 使用 8 导轨网络架构,以 GPU A800 服务器为例,它配有 8 张网卡,然后每张网卡分别连到一个 TOR 汇聚组的 8 个 TOR 上。在 TOR 和 LEAF 层面,我们是通过 Full Mesh 的方式进行互联。如果是三层 RDMA 网络,我们在 LEAF 和 SPINE 层面也是采用 Full Mesh 的互联方式。
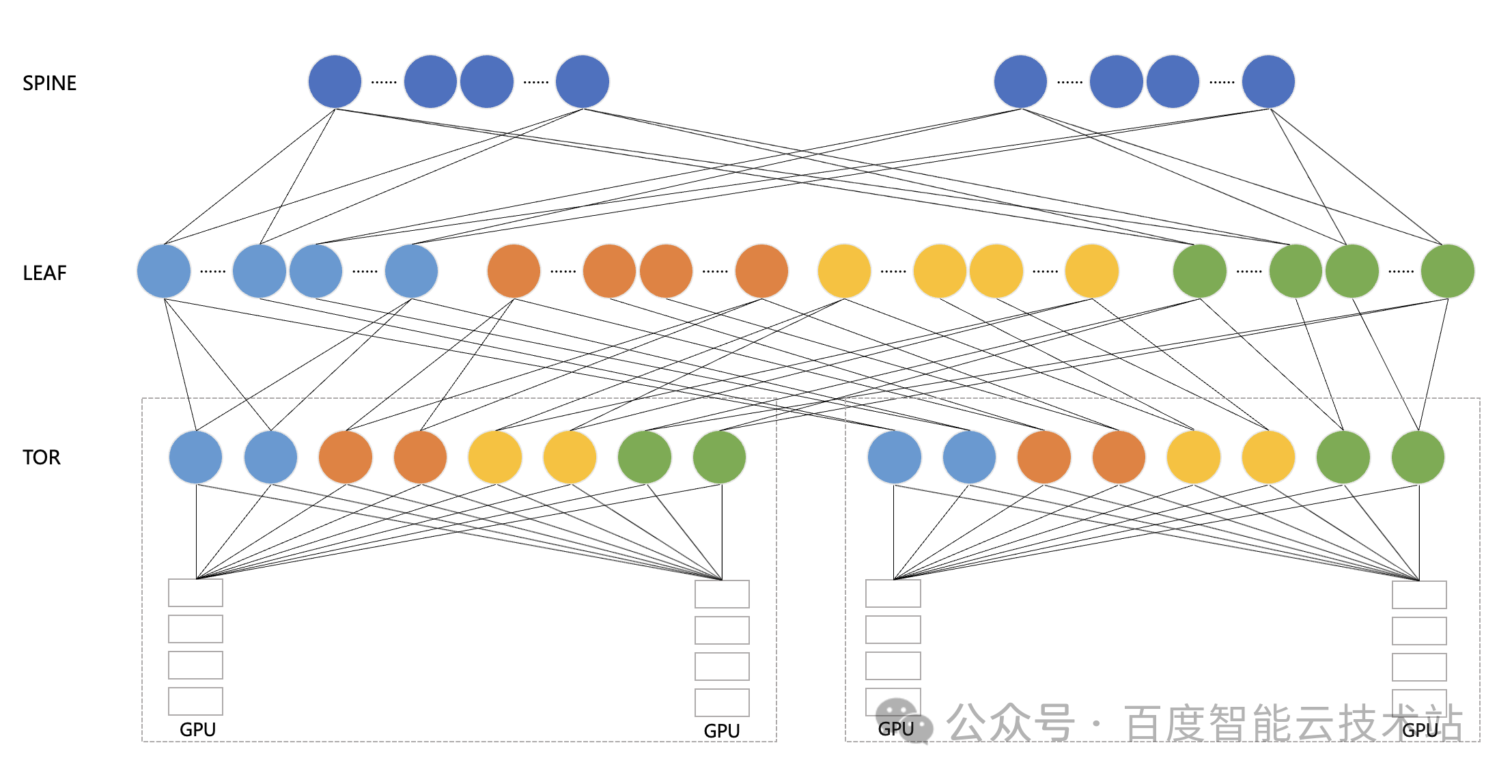
值得一提的是,在大模型训练场景下,考虑到不同的并行策略,我们在跨机通信组产生的大多数都是同号卡流量。同号卡通信情况下更优情况可以只经过一跳 TOR,最差情况只经过 LEAF。只有异号卡流量才可能经过 SPINE 中转。
我们的多导轨架构已经尽可能的把跨机流量放在同 TOR 下进行通信,期望将网络尽可能地打满。但是在实际过程中,我们发现 100 Gbps 的网络链路经常只能达到 70 Gbps 左右。
引起降速问题发生原因有很多,其中一项主要因素就是「哈希冲突」。接下来,我们就讲一下百度智能云的 AIPod 是如何解决网络哈希冲突,最终实现 95% 的「物理网络带宽有效性」。
2 哈希冲突
哈希冲突其实是 HPN 网络(高性能网络)中非常典型的问题,主要是因为 LEAF 和 SPINE 层都是通过 ECMP 来进行报文的转发。然而 RDMA 本身采用 Kernel Bypass 和 CPU Bypass 等操作,它很容易瞬间打满物理网络的硬件带宽。在这种情况下,很容易产生哈希冲突。
我们对哈希冲突进行了深入的分析,主要分为上行冲突和下行冲突两种情况。
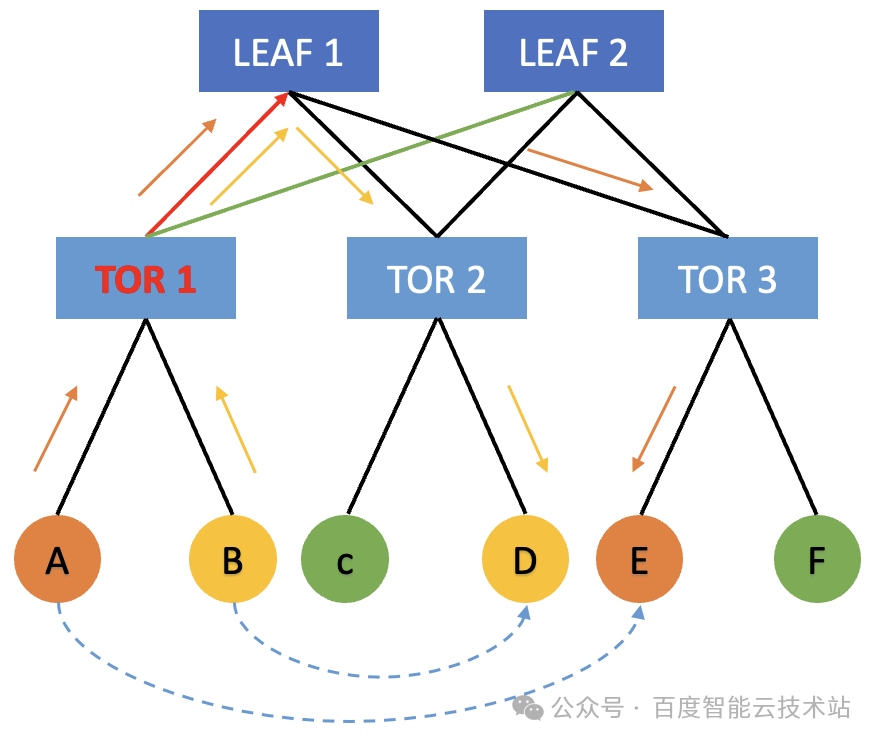
上行冲突
机器 A 发起了一个集合通信操作,在网络上发送 message 的时候,它会尽可能以满带宽 100 Gbps 发送给 TOR 1。当 TOR 1 将流量转发给 LEAF 层时,会根据哈希策略去随机选择 LEAF 1 和 LEAF 2。
与此同时,机器 B 它如果也需要向其他机器进行通信,它也会把相关的流量发送给 TOR 1。此时,TOR 1 也会根据哈希结果来选择把流量转发给 LEAF 1 或者 LEAF 2。在这种情况下,在 TOR 1 的上行方向就会产生概率性的哈希冲突。比如双方都哈希到了 TOR 1 到 LEAF 1 这条链路,TOR 1 到 LEAF 2 这条链路相对空闲。此时机器 A 和机器 B 就会因为出口流量哈希不均的原因,导致各自只有 50 Gbps 的网络带宽,这样就会对通信的性能乃至端到端的性能产生很大的影响。
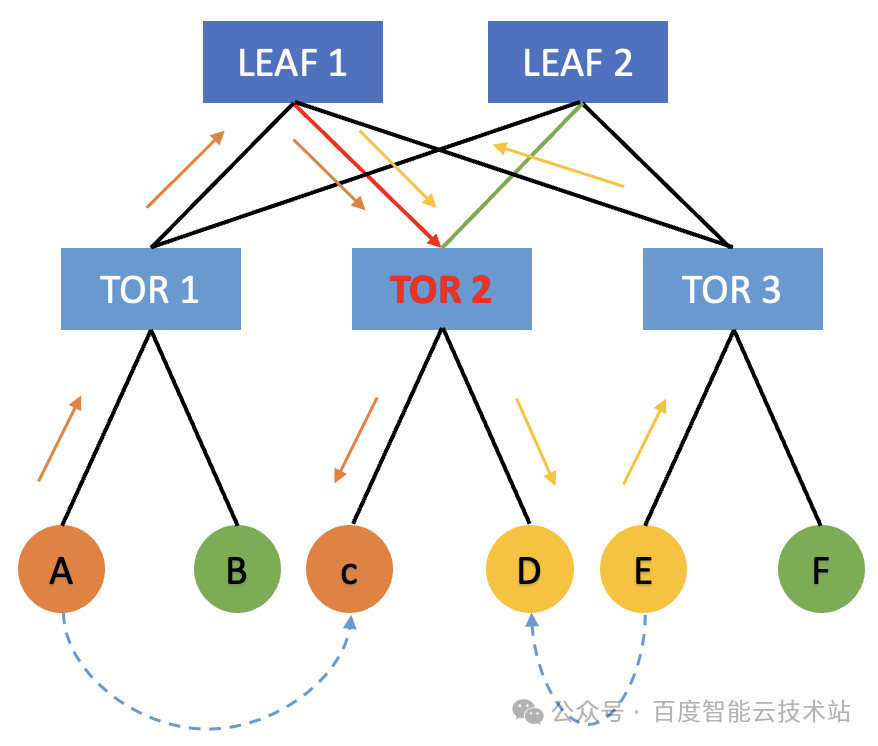
下行冲突
机器 A 如果要向机器 C 发送数据,同时机器 E 要向机器 D 发送数据。在哈希过程中,如果 A 机器走了 TOR 1 -> LEAF 1-> TOR 2 -> C 的链路 ,而机器 E 走了 TOR 3 -> LEAF 1 -> TOR 2 -> D 的链路,那么也会导致这两条流出现下行冲突,也会导致网络流量减半,让端到端的集合通信的性能下降。
在大模型训练的场景下,集合通信具有典型的同步特征,如果一个 GPU 通信降速,会导致同通信组的其他 GPU 同步等待,进而导致全集群的 GPU 通信降速。这种同步特征会导致哈希冲突的影响被进一步放大。
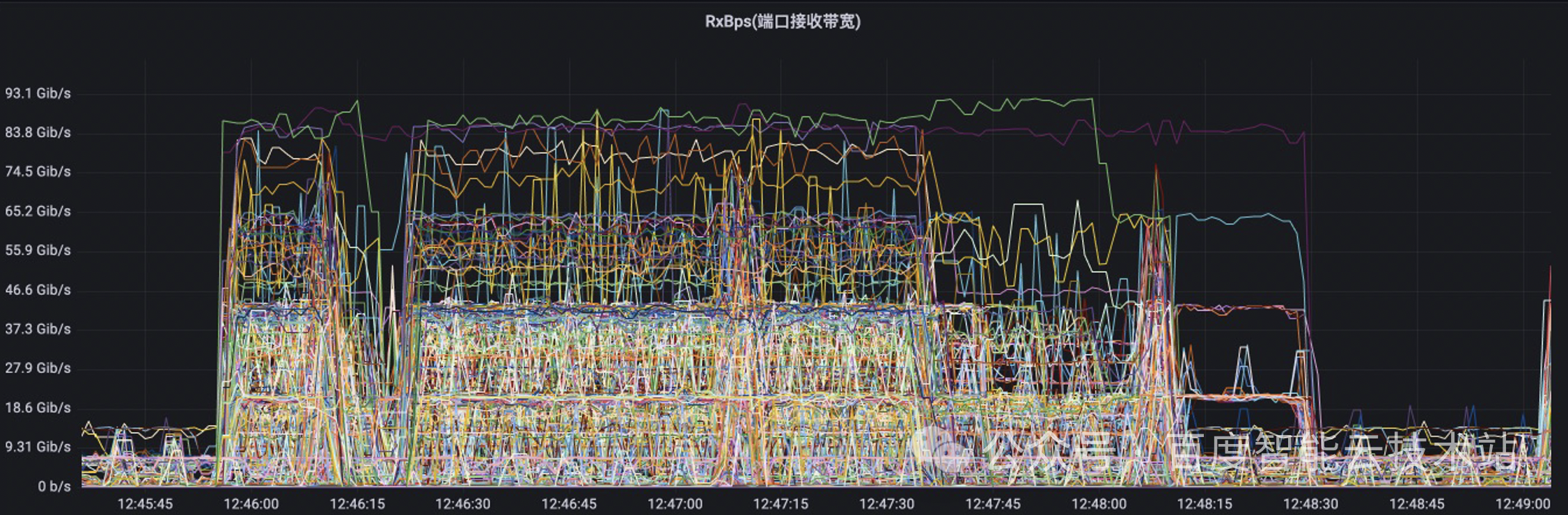
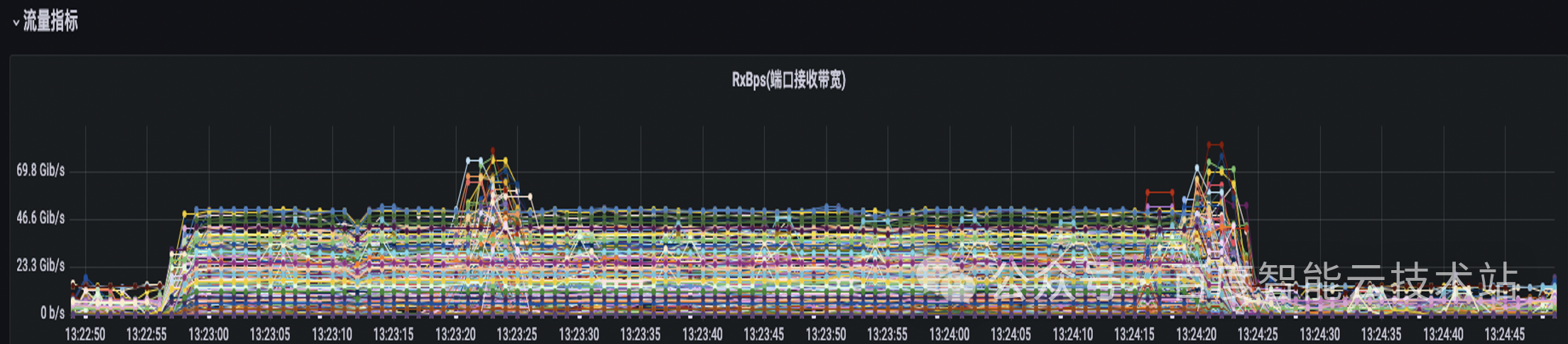
我们用大模型的流量特征图来举个例子。在下图中的每一根线代表的是交换机上的某一条物理链路的流量特征。在该 case 中,端到端的扩展效率从 90% 以上降到了 70% 左右。我们可以看到,物理交换机上面的物理链路的流量负载情况有很大差距。有些链路的带宽非常的低,有些链路的带宽非常的高。这也意味着我们物理网络的带宽没有得到充分的利用。
这一些流量负载非常高的物理链路,说明从 TOR 到 LEAF 的方向上出现了哈希冲突,导致集合通信的性能下降。
3 解决方案 1 — 增加 RDMA 流数
针对上述哈希冲突的问题,我们自然而然想到的一个解决方案是:增加 RDMA 的流数。
比如说目前的网络中只有 2 条流,那这 2 条流可能很容易就哈希到同一个链路上。如果我们增加 RDMA 的 QP 数,比如说 16 条流、64 条流,那相应的哈希冲突的概率就会减少很多,从而减少交换机哈希冲突的现象。
下图是一个开启多 QP 之后的网络监控图。可以看到 RDMA 的流量相对均匀地哈希到不同的网络链路上,哈希冲突概率大大降低。
但是在实际的集合通信过程中,增加 QP 会带来一些额外的开销。比如网卡侧可能会因为多 QP 带来额外的调度上的开销。在完全没有哈希冲突的情况下,多 QP 的性能其实是不如单 QP 的。但是因为哈希冲突问题存在,在这种场景下,我们只能选择多流来减轻哈希冲突问题。
4 解决方案 2 — 亲和性调度
前一种方案的核心思路是围绕交换机展开的,此时网络流量已经送到了 LEAF 交换机上。如果出现了哈希冲突,交换机通过多流的方式来减轻哈希冲突的概率。
第二种方案的思路则是围绕减少流量上送 LEAF 展开的。
通过前面的分析,我们知道哈希冲突主要是在 TOR 到 LEAF 的上行链路和 LEAF 到 TOR 的下行链路中产生的。所以我们可以通过减少流量上送到 LEAF,或者上送到 SPINE 的方式,从而减少交换机哈希冲突的概率。
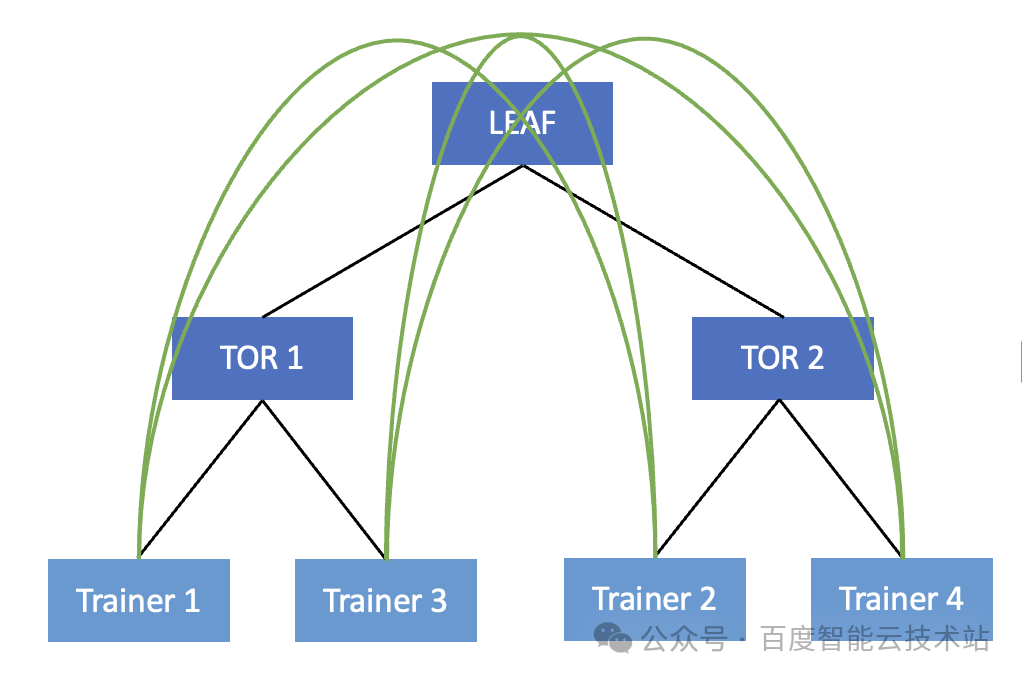
我们以一个简单场景为例。在下图中我们将 4 个 Trainer 建立为一个通信组 。在当前通信组内,实际的通信顺序为 Trainer 1 -> Trainer 2 -> Trainer 3 -> Trainer 4 -> Trainer 1 。
但是由于当前的接线顺序,Trainer 1 和 Trainer 3 连在同一个 TOR 下,Trainer 2 和 Trainer 4 连在同一个 TOR 下。那么实际 Trainer 1 产生的流量,需要上送到 TOR 绕行 LEAF 才能到达 Trainer 2,然后 Trainer 2 的流量再次绕行 LEAF 来到 Trainer 3,Trainer 3 再绕行 LEAF 转发给 Trainer 4。
我们可以看到在物理网络层面这是一个无序的调度,很有可能导致集合通信产生的流量都要上送到 LEAF,这就大大增加了交换机产生哈希冲突的概率。
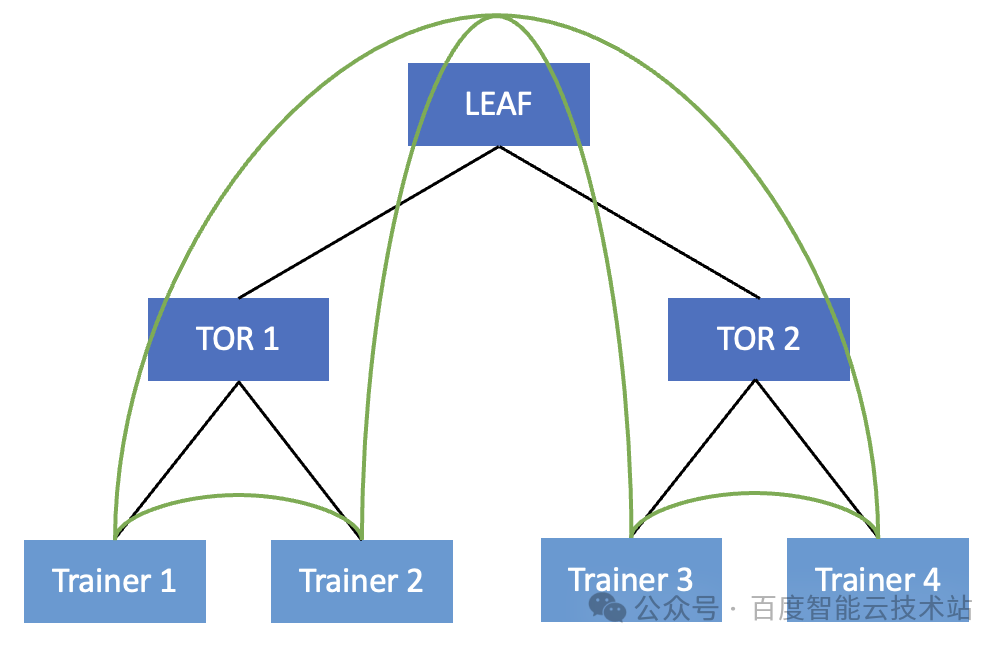
为了解决该问题,我们可以采用一种很简单的方式。在组建通信组的时候,让 Trainer 1 和 Trainer 2,Trainer 3 和 Trainer 4 在同一个 TOR 下,做为相邻的 Trainer。
此时,只有 Trainer 2 发给 Trainer 3 的时候需要绕行,有一半的流量都可以直接在 TOR 内进行转发。这其实就启发了我们在做任务 Trainer 排序的时候要尽可能做好 TOR 亲和性的调度。具体我们可以从两个方面入手:
在提交任务的过程中,尽可能在同一个 TOR 上去调度机器,来提交相应的训练任务。
在启动任务的时候,尽可能的把相邻的 Trainer 调度到同一个 TOR 上面。
5 解决方案 3 — DLB 动态负载均衡
上述两种方案都是从概率的视角来解决哈希冲突,某种意义上来说都是在撞运气。网络哈希冲突不可避免,我们只能减少发生的概率。那有没有什么终极办法能够从根本上去解决交换机的哈希冲突呢?
第三种方法就是 DLB 动态负载均衡。
哈希冲突产生的根源在于如果某一条流根据其五元组特性,哈希到了某一条链路中,后续如果产生了其他五元组的流哈希到同一条链路来争抢物理带宽,每条链路的流量将会减半。如果可以允许同一条流的报文转发到不同的物理链路中去,交换机根据链路实时负载来转发报文,那么就可以解决上述的问题,这也是我们 DLB 的核心思路。
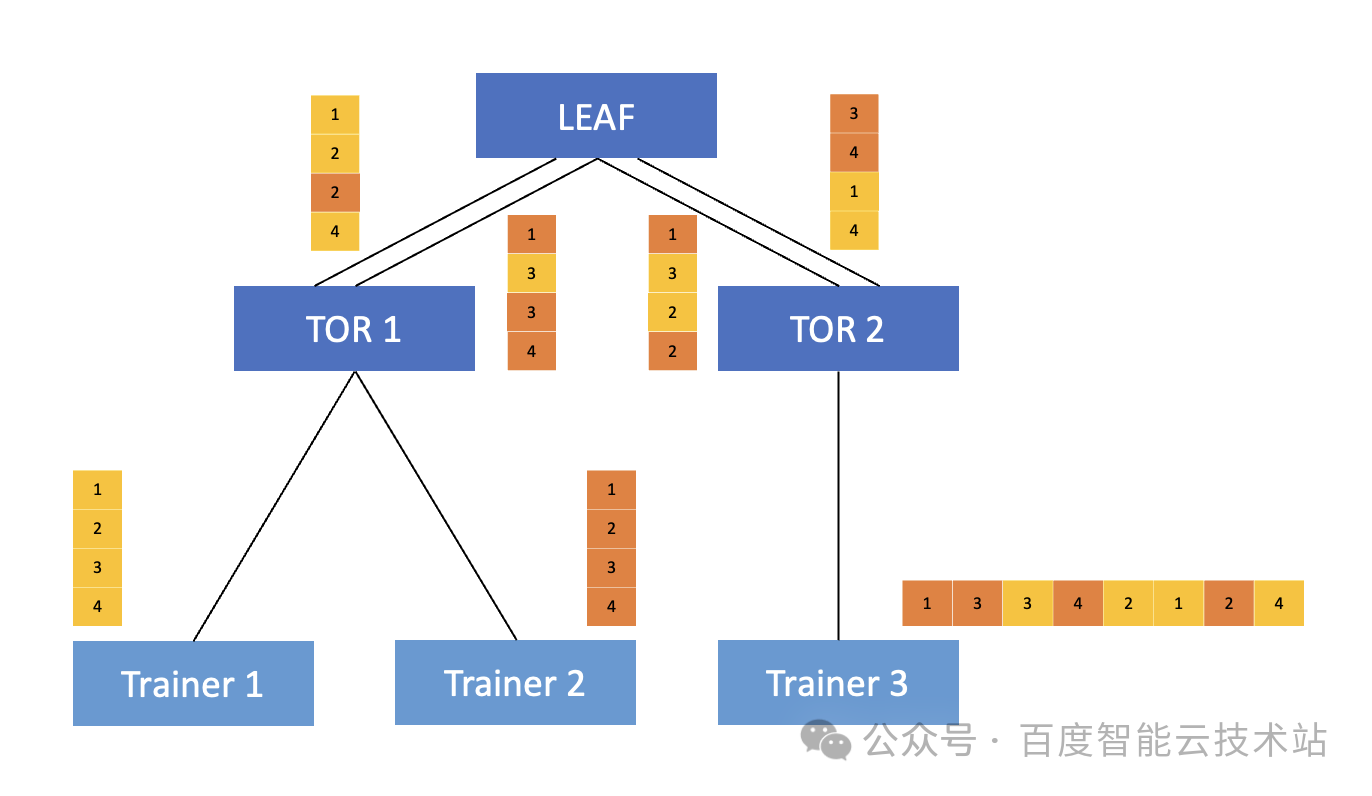
我们看下面这个例子。Trainer 1 和 Trainer 2 要发送数据给到 Trainer 3,在 TOR 到 LEAF 上存在两条物理链路,其中,Trainer 1 中需要通信的报文为黄色的 1234,Trainer 2 中则是为橙色的 1234。
接下来,我们介绍下在 DLB 场景下的完整的转发过程。DLB 功能本质上是基于 InfiniBand 的 AR 扩展实现的。
用 Trainer 1 来举例,网卡在发送报文的时候,对发送的报文做了特殊的 AR bit 标记。当 TOR 识别到了该标记之后,就会对该报文走 DLB 转发逻辑,在转发给 LEAF 的时候会根据链路的实际负载来进行转发,将报文送到相对空闲的物理链路上,从而保证两条链路上的流量相对均衡。在这种情况下,由于同一条流的不同报文走了不同的转发路径,自然会发生乱序,因此当 Trainer 3 收到后,需要收到的乱序的报文进行重组。
以上就是整体 DLB 的实现策略。核心思想是基于链路负载选择相应的转发路径,支持对报文的 per-packet 转发逻辑。
目前 DLB 方案基于百度自研的交换机实现。我们可以实现均衡的把所有接收到的流量分发到不同的物理链路中,从根源上解决哈希冲突的问题。在百度内部的大模型训练场景中,网络带宽有效性可以提升 10% 左右。
在百度智能云 HPN 集群 AIPod 中,使用「亲和性调度」配合「DLB 动态负载均衡」的方案,可以彻底解决物理网络集群哈希冲突的难题,这使得物理网络「带宽有效性」达到了 95% 。
此外,我们推出的自研的百度集合通信库 BCCL ,联合框架层做了进一步的性能调优。针对特殊的业务流量特征,比如局部二打一等问题,进行通信层面的深度优化,大模型训练任务的端到端性能提升 1.5%。

