Instagram如何扩展支撑25亿用户的基础架构?
前言:本文概述Instagram如何扩展其基础设施,主要基于笔者研究,可能与实际实践情况有所差异。
从前,两位斯坦福大学毕业生决定制作一款实现位置签到功能的应用程序。然而,他们注意到,该应用中使用最频繁的功能是“照片共享”,所以他们转而创建了一款照片分享应用,并将其命名为Instagram。
随着更多早期用户加入,他们购买硬件来扩大规模,但扩展到一定程度后,垂直扩展的成本就会急剧增加,变得十分昂贵。
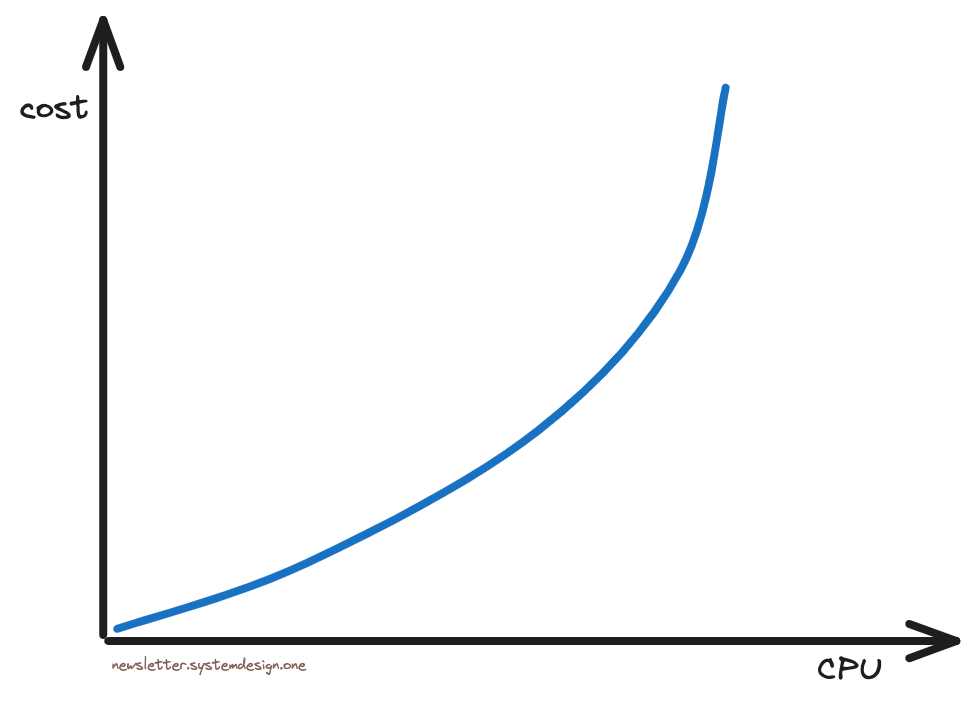
垂直扩展
然而,用户增长飞速,在不到两年时间内,该款应用已具备3000万用户,因此他们通过添加新服务器来扩大规模。
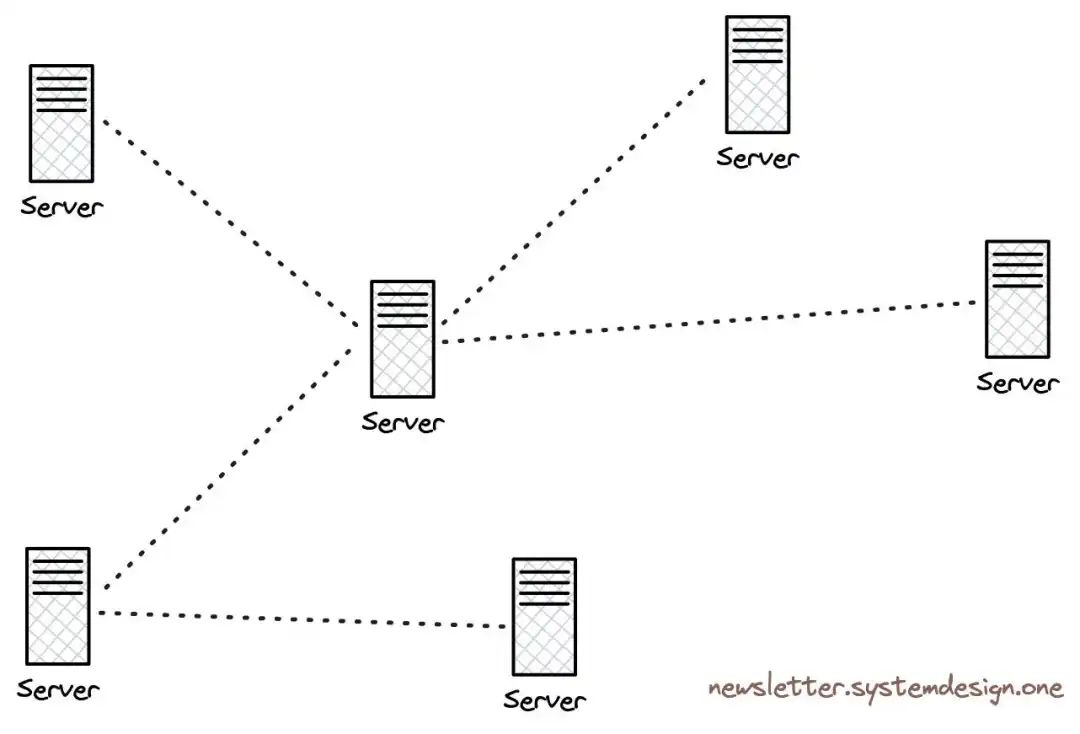
水平扩展
虽然这种方式暂时解决了可扩展性问题,但超速增长又带来了新的问题。
问题包括但不限于:
1.资源使用情况
配备更多硬件以便规模扩展,但是每台服务器的最大容量并未被充分使用。
简而言之,由于服务器吞吐量不高,资源被浪费了。
2.数据一致性
为了处理大量流量,Instagram在世界各地建立了数据中心。
而数据一致性影响着用户体验良好与否,随着数据中心数量增加,确保数据一致性变得越来越困难。
3.性能
Instagram的应用服务器上运行Python,这意味着由于全局解释器锁(GIL),它们拥有进程而非线程,因而存在一些性能限制。
Instagram基础设施
机智的Instagram工程师们用简单的方式解决了这些难题,它们提供的极端可扩展性方式如下:
1.资源使用情况
Python很优雅,但C语言更快,因此它们用Cython和C/C++广泛使用的稳定函数替换了它们,以此减少了CPU的使用率。
即使没有购买昂贵的硬件来扩大规模,也减少了完成任务所需的CPU指令。
这意味着代码运行良好,从而增加了每台服务器能够处理的用户数量。
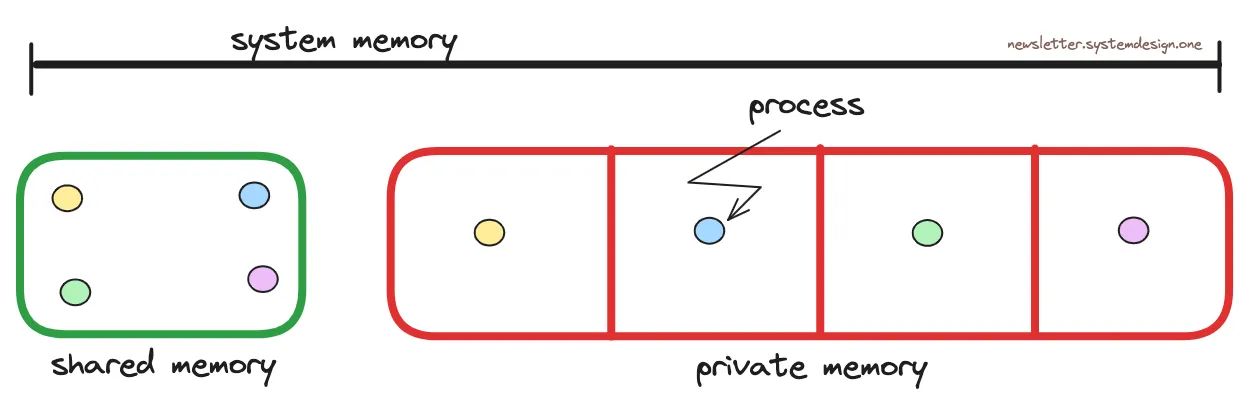
共享内存 VS 私有内存
此外,服务器上的Python进程数量受到可用系统内存的限制。同时,每个进程都有一段私有内存和一段可以访问共享内存的权限。
这意味着,如果公共数据对象被移动到共享内存,则可以运行更多进程。
因此,如果单个副本足够的话,它们就会将数据对象从私有内存移动到共享内存。
同时删除未使用的代码,以减少内存中的代码量。
2.数据一致性
使用Cassandra支持Instagram用户反馈。
每个Cassandra节点可以部署在不同的数据中心,并通过最终一致性实现同步。
然而,在不同大洲运行Cassandra节点会导致延迟更加严重,实现数据一致性更加困难。
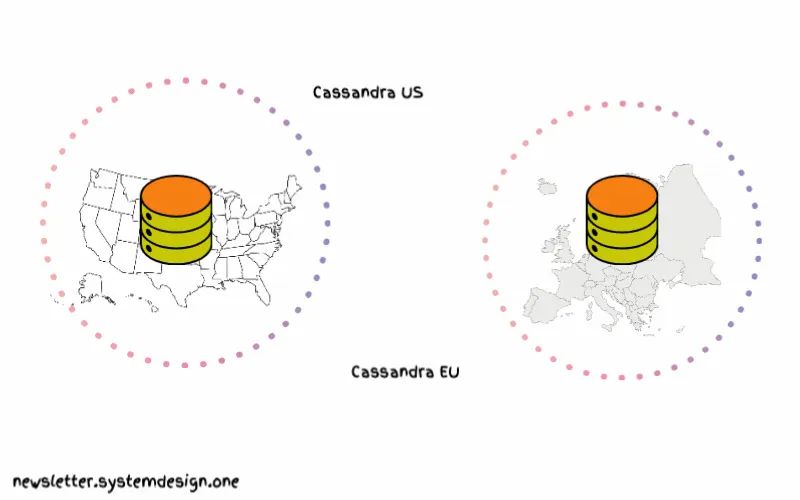
使用独立Cassandra集群实现更优数据放置
因此,他们没有为全世界运行一个Cassandra集群,而是为各大洲分别设置不同的集群。
这意味着欧洲的Cassandra集群将存储欧洲用户的数据。而美国的Cassandra集群将存储美国用户的数据。
换句话说,副本的数量并不等同于数据中心的数量。
然而,如果每个地区都有独立的Cassandra集群,就存在宕机的风险。
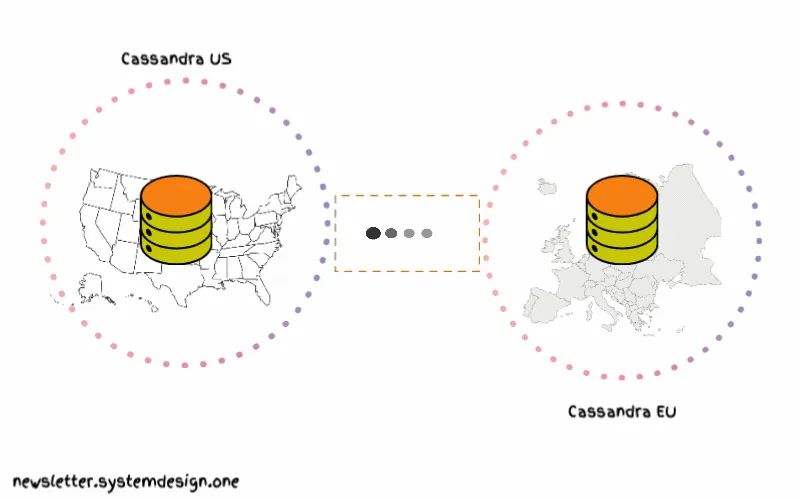
将单个副本保存在另一个区域以备灾
因此,他们在另一个区域保留了单个副本,并使用法定人数来路由请求,减少额外的延迟。
此外,他们还使用Akkio(译者注:由Facebook开发的数据布局服务,即data placement service)来优化数据放置,Akkio将数据分割成具有强定位性的逻辑单元。
将Akkio想象成一种服务,它知道何时以及如何移动数据以降低延迟。
他们通过全局负载平衡器路由每个用户请求。以下是他们为请求找到合适Cassandra集群的方法:
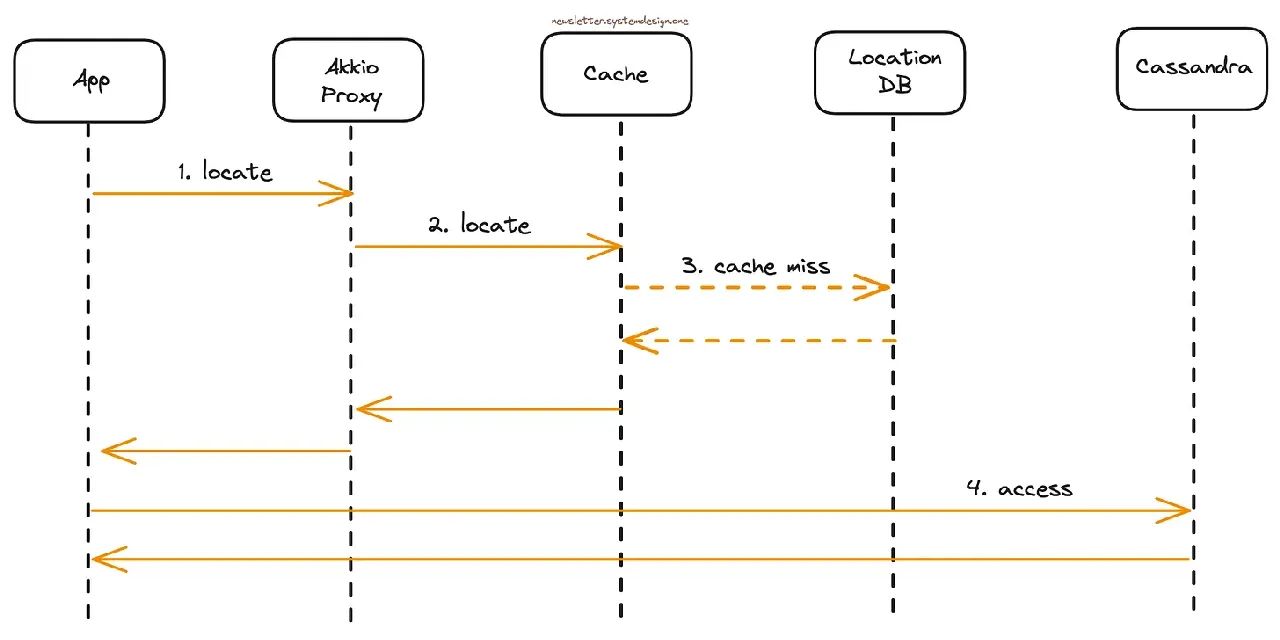
根据用户请求查找正确的Cassandra集群
用户向应用程序发送请求,但应用程序不知道用户的Cassandra集群
应用程序将请求转发给Akkio代理
Akkio代理询问缓存层
Akkio代理会在缓存未命中时与位置数据库通信。由于数据集较小,因此会在每个区域进行复制
Akkio代理将用户的Cassandra集群信息返回给应用程序
应用程序根据响应直接访问正确的Cassandra集群
应用程序缓存信息以供后续请求
Akkio请求大约需要10毫秒,因此额外的延迟是可以忍受的。
此外,如果用户搬到另一大洲定居,他们还会迁移用户数据。
当用户跨大洲移动时,数据迁移方式如下:
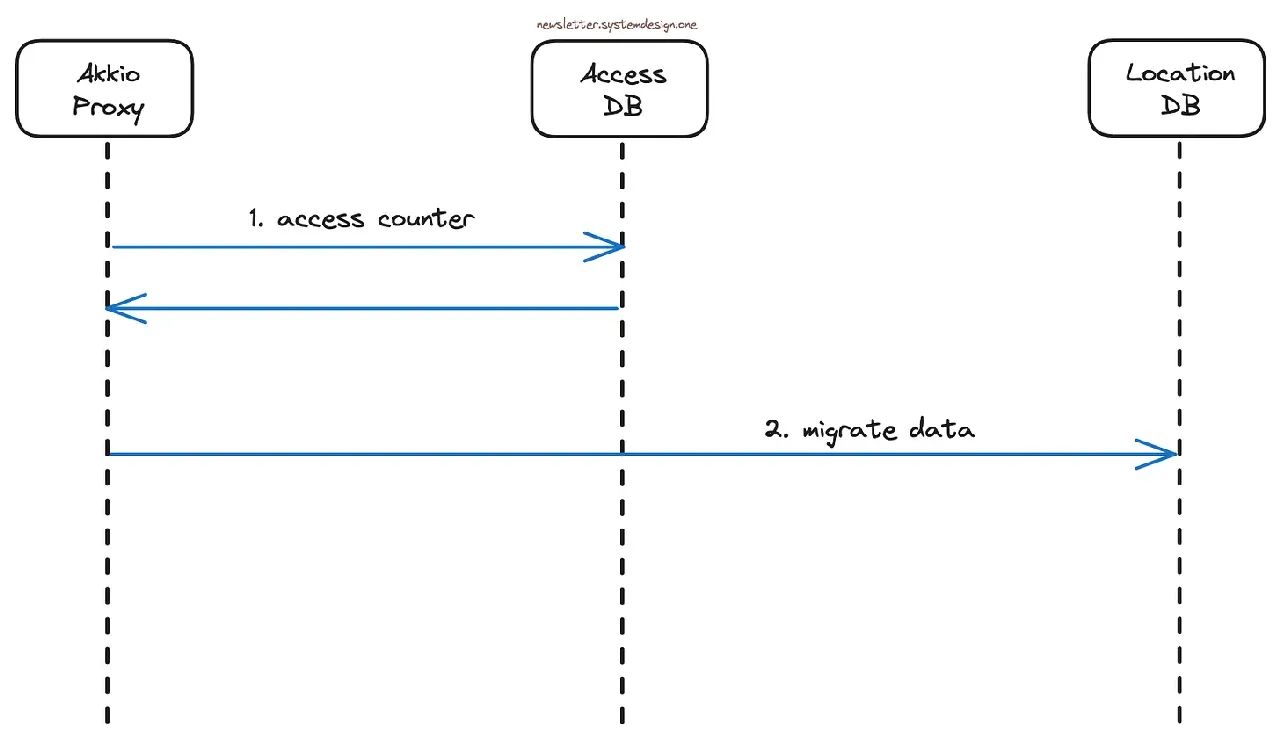
当用户迁移到另一大洲时的数据迁移
Akkio代理从生成的响应中知道用户的Cassandra集群位置。
他们会在访问数据库中维护一个计数器,以此记录了每个用户从特定地区访问的次数。
每次请求时,Akkio代理都会递增访问数据库计数器,可以根据IP地址找到用户的确切位置。
如果计数器超过限制,Akkio会将用户数据迁移到另一个Cassandra集群。
此外,他们还在PostgreSQL中存储用户信息、好友关系和图片元数据。
然而,他们收到的读取请求却多于写入请求。
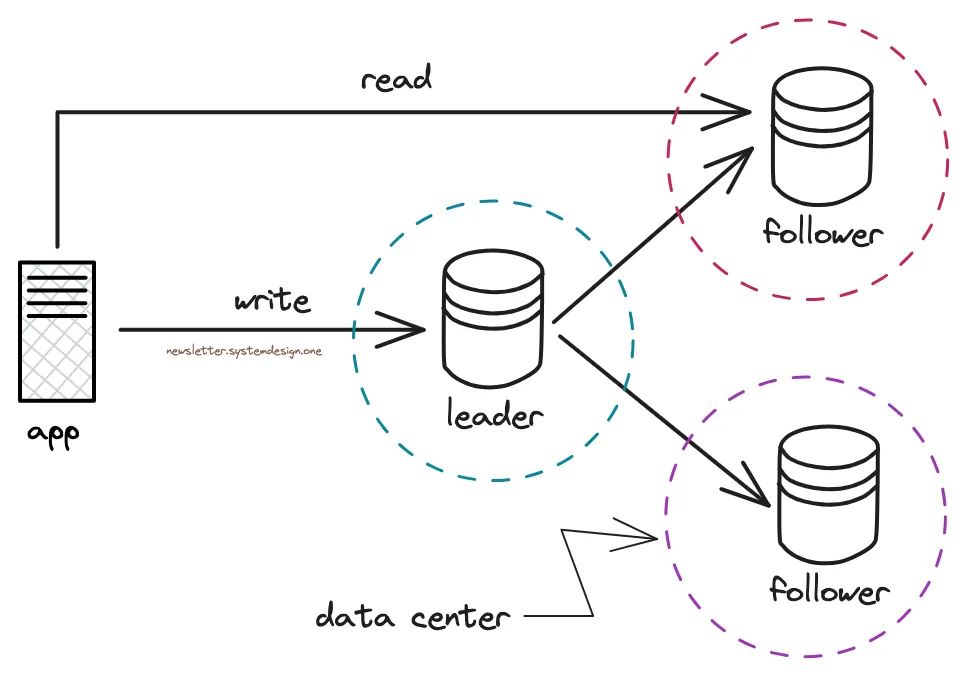
扩展PostgreSQL
因此,他们在领导者-追随者复制拓扑中运行PostgreSQL,并将写入请求路由到领导者,读取请求则被路由到同一数据中心的跟随者。
3.性能
应用层是同步的,必须等待外部服务做出响应。
这意味着执行的CPU指令会减少,并且服务器资源匮乏。
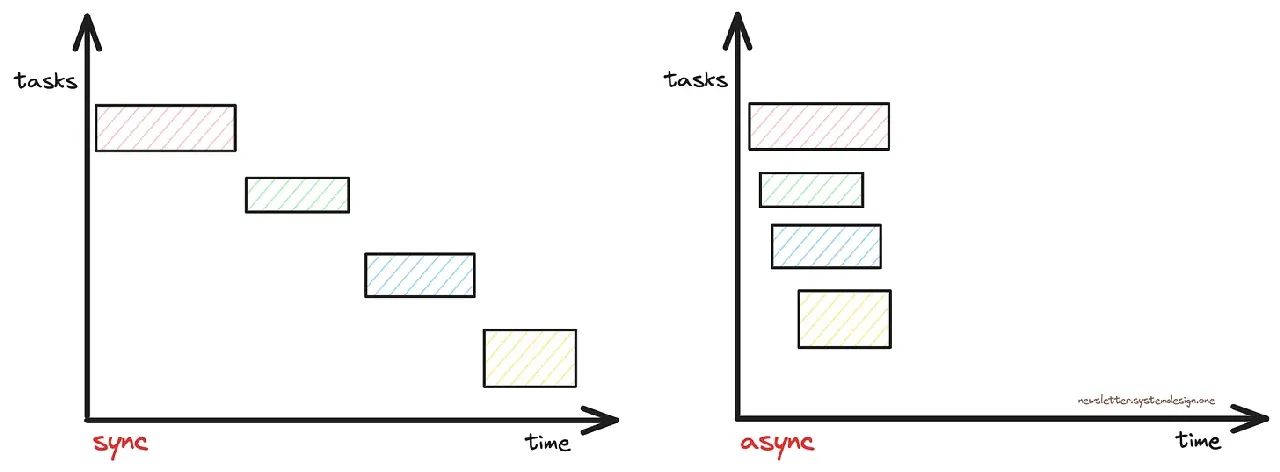
同步执行与异步执行
因此,他们使用Python异步IO与外部服务进行异步对话,并且,他们使用Python进程而不是线程。
换句话说,如果一个请求需要更长时间才能完成,服务器的容量就会被浪费。
因此,如果一个请求的完成时间超过12秒,他们就会终止该请求。
此外,他们还使用Memcache来保护PostgreSQL免受大量流量的影响,并将读取请求路由到Memcache。
Memcache用作键值存储,每秒可处理数百万个请求。
然而为了降低延迟,他们不会跨数据中心复制Memcache。
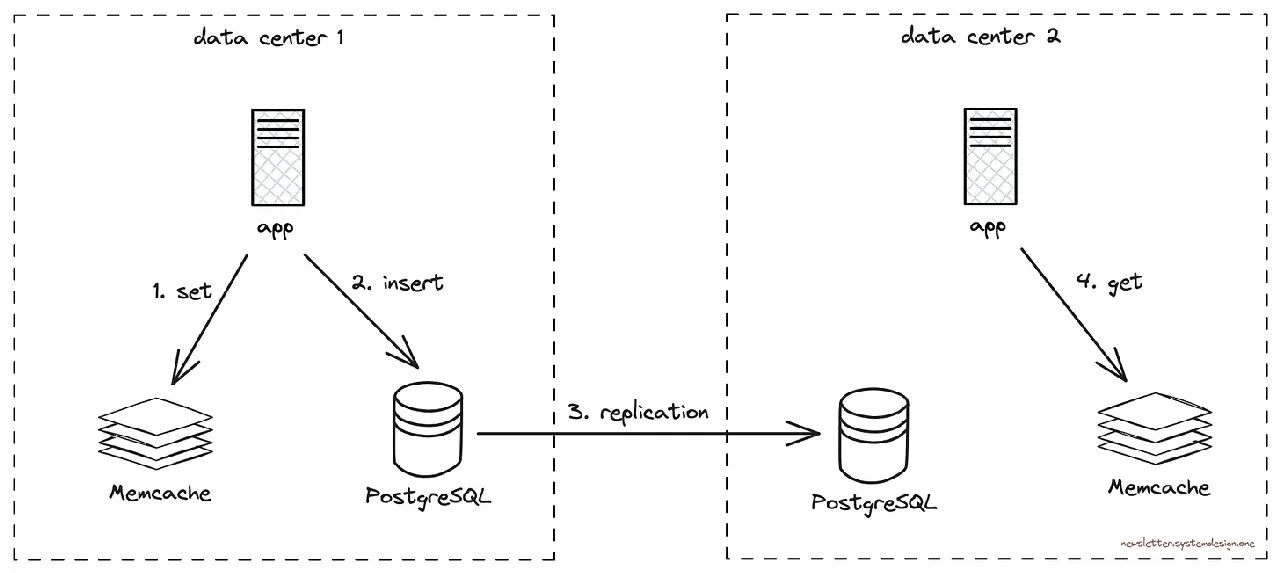
由另一个数据中心的缓存提供的陈旧数据
因此存在数据过期的风险。
例如,在一个数据中心收到对某张图片的评论,对于另一个数据中心查看同一图片的人来说是看不见的。
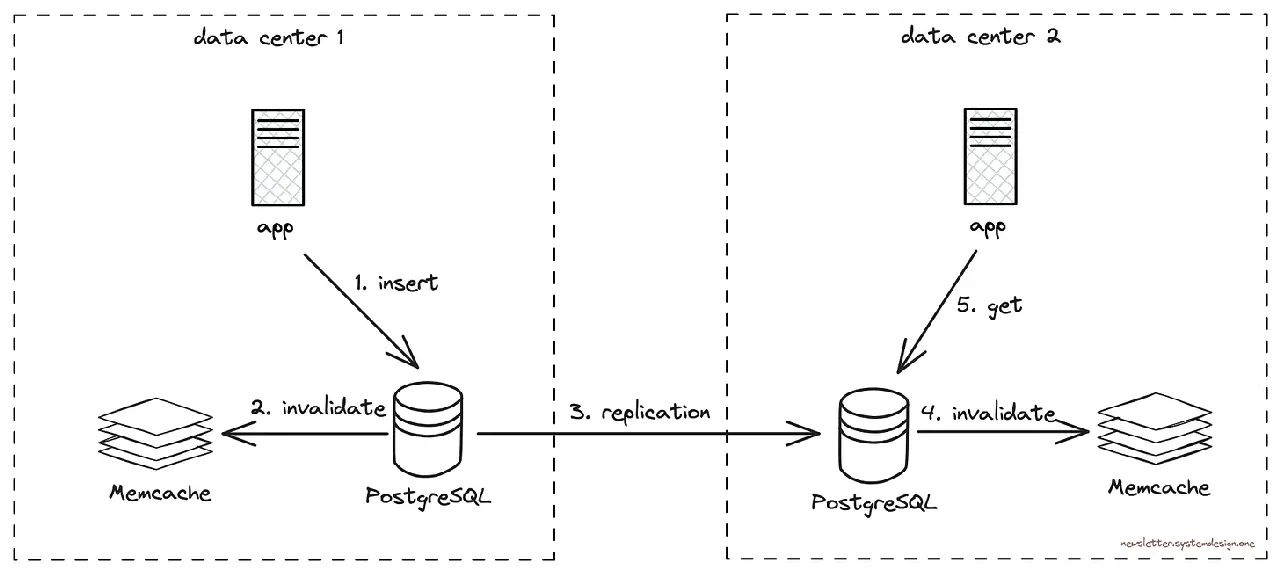
在更新PostgreSQL时使缓存失效
因此,他们不会直接将数据插入Memcache。取而代之的是由一个单独的服务来监视PostgreSQL更新,然后使Memcache失效。
这意味着缓存失效后的第一个请求会被路由到PostgreSQL。
然而,PostgreSQL存在超载的风险。
例如,查找热门图片获得的点赞数可能会变得很昂贵:
取而代之的是一个单独的服务,它负责监视PostgreSQL的更新,然后使Memcache失效。
这意味着缓存失效后的第一个请求会被路由到PostgreSQL。
然而,PostgreSQL有超载的风险。
例如,查找热门图片获得的点赞数可能会变得很昂贵:
selectcount(*)fromuser_likes_mediawheremedia_id=42;
因此,他们创建了非规范化表来处理昂贵的查询:
selectcountfrommedia_likeswheremedia_id=42;
这样就能以更少的资源消耗提供更快的响应。
但是,一次性失效所有缓存可能会给PostgreSQL带来惊群问题(译者注:Thundering herd problem,当事件发生时,大量等待该事件的进程或线程被唤醒,但只有一个进程能够处理该事件,就会发生惊群问题。当进程被唤醒时,他们将各自尝试处理该事件,但只有一个进程会获胜。所有进程都会争夺资源,可能会导致计算机死机,直到群体再次平静下来)。
因此,他们使用了Memcache租赁。
Memcache租赁工作流程
工作原理如下:
第一个请求被路由到Memcache。但这不是普通的GET操作,而是租用GET操作。
Memcache将请求转发给PostgreSQL,并要求客户端等待。
如果第一个请求尚未完成,Memcache会要求第二个请求等待。
Memcache提供过期数据作为第二个请求的替代选项。在大多数情况下,例如查找图片的点赞数,这就足够了。
对第一个请求的响应会更新Memcache。
待处理的和较新的请求从Memcache获取新数据。
结语
扩展应用程序需要持续努力。
每一种架构决策都是一种权衡。
而Instagram能够凭借这些技术为25亿用户提供服务,这个例子说明Python和其他成熟的技术足以处理互联网规模的流量。

