揭秘字节跳动基于Doris的实时数仓探索
火山引擎 EMR 作为一款云原生开源大数据平台产品,集成了包括 Hadoop、Spark、Flink 等引擎,并做到100%开源兼容。Doris 作为 OLAP 领域中一款极具代表性的开源组件,也被集成到了火山引擎 EMR 产品生态中。
本文来源于山引擎 EMR 团队大数据工程师在 Doris Summit 2022 中的同名主题分享,将为大家详细介绍火山引擎 EMR 是一款怎样的产品,火山引擎 EMR 团队对 Doris 社区做出了哪些贡献,火山引擎 EMR Doris 目前具备了哪些能力优化,以及后续的规划方向有哪些。
火山引擎是字节跳动旗下的云服务平台,将字节跳动快速发展过程中积累的增长方法、技术能力和工具开放给外部企业,提供云基础、视频与内容分发、数据平台 VeDI、人工智能、开发与运维等服务,帮助企业在数字化升级中实现持续增长。
火山引擎 EMR 是一款云原生开源大数据平台产品。首先,从开源大数据平台角度,火山引擎 EMR 集成了开源大数据生态的众多软件栈,包括 Hadoop、Spark、Flink 等引擎,并且做到100%开源兼容。Doris 作为一款 OLAP 领域极具代表性的开源组件,所以我们也将其集成在火山引擎 EMR 生态中。其次,从云原生角度,我们也会基于云的特性做深度的能力增强,例如弹性伸缩、存算分离等。
目前,火山引擎 EMR 已经集成了非常多的引擎,例如我们常见的离线分析领域的 Spark、 Hive,实时计算领域的 Flink、Kafka,等等。
今天分享的主角就是 OLAP 领域中的 Doris ,我们在产品发布之初就已经集成了 Doris 引擎,它也是目前火山引擎 EMR 系统中的主力 OLAP 引擎之一。
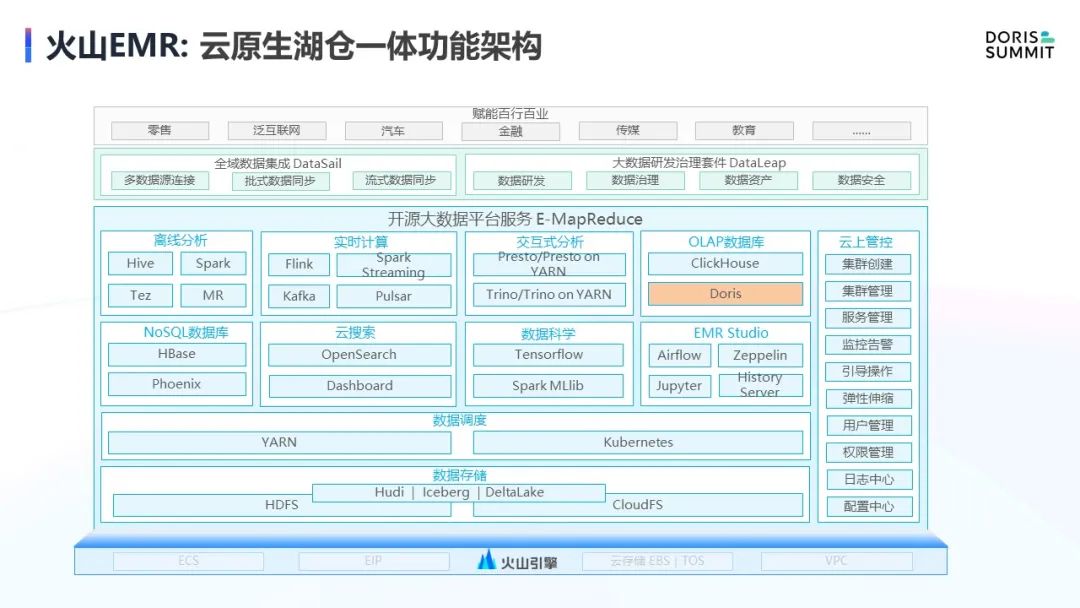
EMR Doris 是一个开箱即用的云端 Doris 服务。支持海量数据的高效导入、实时更新,支持对 10PB 级别的海量数据进行高并发查询。我们认为 Doris 也是一个比较全面的 OLAP 引擎,不像 ClickHouse 可能只能做一些大宽表的聚合。Doris 的能力相对来说比较出众。
首先,它也像 ClickHouse 一样,拥有一个向量化执行引擎。其次,它有 MPP 的计算能力,像 Presto 一样,它能做非常好的多表关联。
再次,它也像 Druid 一样,有预聚合表引擎,能方便快速地实现数据的聚合。
最后,它也像 Kylin 一样有物化视图的能力,能够实现查询改写,通过预计算来提高查询 QPS 。
因此,Doris 是一个非常全面的OLAP服务,所以火山引擎 EMR 很早对其进行了集成,进行了大量功能优化,并将其作为主力 OLAP 引擎之一,推向了整个公有云市场。
 字节跳动基于Doris的能力优化
字节跳动基于Doris的能力优化
作为开源大数据平台产品的提供方,我们对 Doris 的研发主要以贡献开源社区为主。下面将为大家介绍下火山引擎 EMR 团队近期对于 Doris 社区的主要贡献。
基于Hudi的数据查询方案
第一个是在 22 年上半年,社区和火山引擎 EMR 团队一起做了基于 Iceberg 和 Hudi 的数据湖查询方案,社区主要做了 Iceberg 的方案,而火山引擎 EMR 团队则是负责 Hudi 的方案。
在此之前,查询 Hudi 需要通过一些导入工具,把 Hudi 的数据加载到 Doris 的内表中进行计算。但这样会带来一个坏处,数据链路相对来说会更长。
因此我们把 Doris 作为一个数据服务层,和下层的 Hudi 做数据打通,实现数据的直接查询,避免数据反复导入导出。
另外,通过打通 Hive Metastore,来直接访问 Hive Metastore 获取库表的元数据,而不是通过表映射来关联字段,从而大大提升了数据开发的效率。
基于这三方面的能力优化,Doris 实现无缝查询 Hudi 表。当然,目前这一方案只支持 Hudi 中 CopyOnWrite(COW) 存储类型的表,对 MergeOnRead(MOR) 表的支持尚在规划中。

Multi Catalog 联邦查询
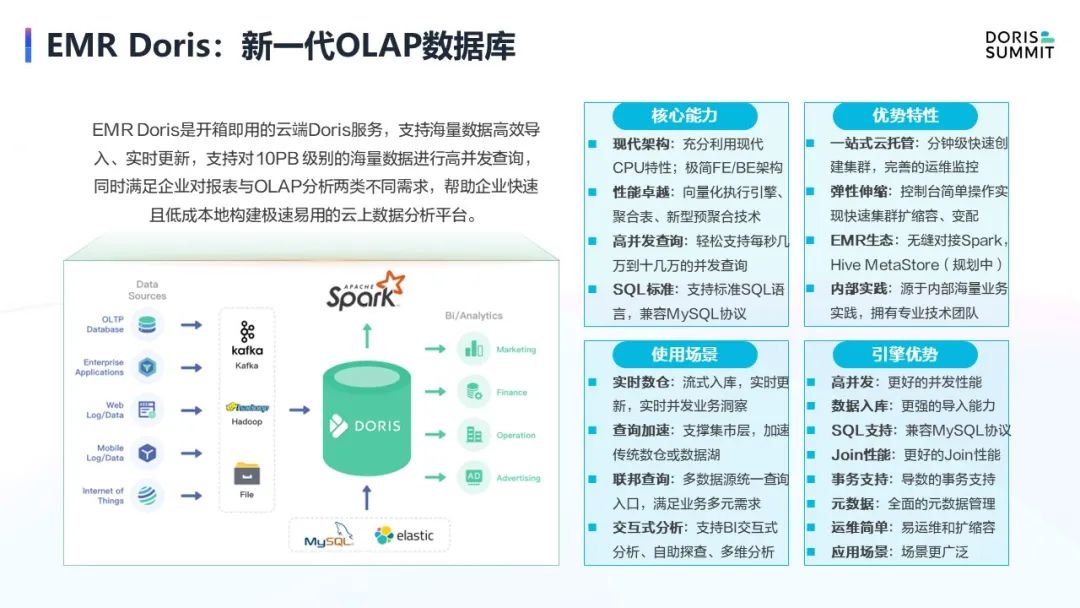
第二个是 Multi Catalog 联邦查询,是在22年6~7月和社区合作的一个项目。当时的目标是想让 Doris 能像 Presto 一样有 plugin 的能力,能做联邦查询,能够查询ES、JDBC等数据源,当然最典型的还是 Hive 、数据湖的这些表。
于是通过 Catalog 直接查询 Hive、Iceberg、Hudi 表。经过了两个月的开发,目前已经支持三大数据组织模式,也支持数据存放在 HDFS、S3 和 TOS 上,数据格式也支持最常见的 Parquet、ORC、TEXT等。
基于这些能力,我们在性能上也做了持续的优化。例如,我们做了 table scan 里面最常见的几类优化,包括并发读取、RunTimeFilter、列裁剪、分区裁剪、Parquet 和 ORC 中的谓词下推、数据预取等。做了这些有效的优化以后,相对于 Trino, 在同样的场景下,也就是 Trino + HDFS 或者 Trino + S3 的模式,对比发现整个 Doris 的查询性能相比 Trino 要提升了近一倍左右。
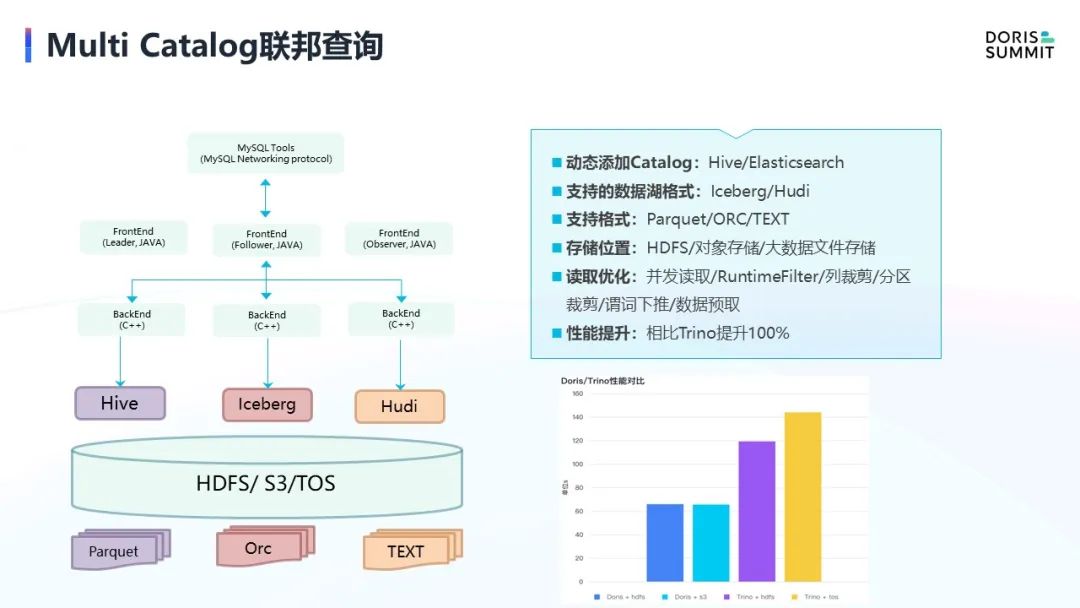
ComputeNode 计算节点
第三个是计算节点,与联邦查询有很大的关联性。Doris 本身是典型的 Share-Nothing 架构,所以在它的 BE 节点上计算和存储是强绑定的,这样会带来几个影响:
第一,扩容,计算资源不够了需要扩容,磁盘不够也需要扩容,只要满足一个条件,就必须要扩容。
第二,弹性能力差,因为每个节点都绑定了数据,一旦扩容就需要做数据的迁移。而一旦涉及到数据的迁移,时间相对来会比较长。而在联邦查询的场景下,因为它不管理数据,或者说数据在外部存储系统中, 所以用 BE 去承载联邦查询的计算相对来说比较厚重。
基于这种假设,我们做了 ComputeNode 计算节点的功能。顾名思义,计算节点只有计算,没有存储,这样就非常适用于联邦查询场景。因为联邦查询本身没有数据存储,数据都是从远端拉过来的。另外它能很好地支持弹性,因为扩缩容的时候也不需要做数据搬迁。只要进程起来可以执行任务,资源过多时也可以在一两分钟之内将资源回收。因此计算节点可以实现非常好的弹性,可以支持分时弹性,这也是最常用的弹性策略。
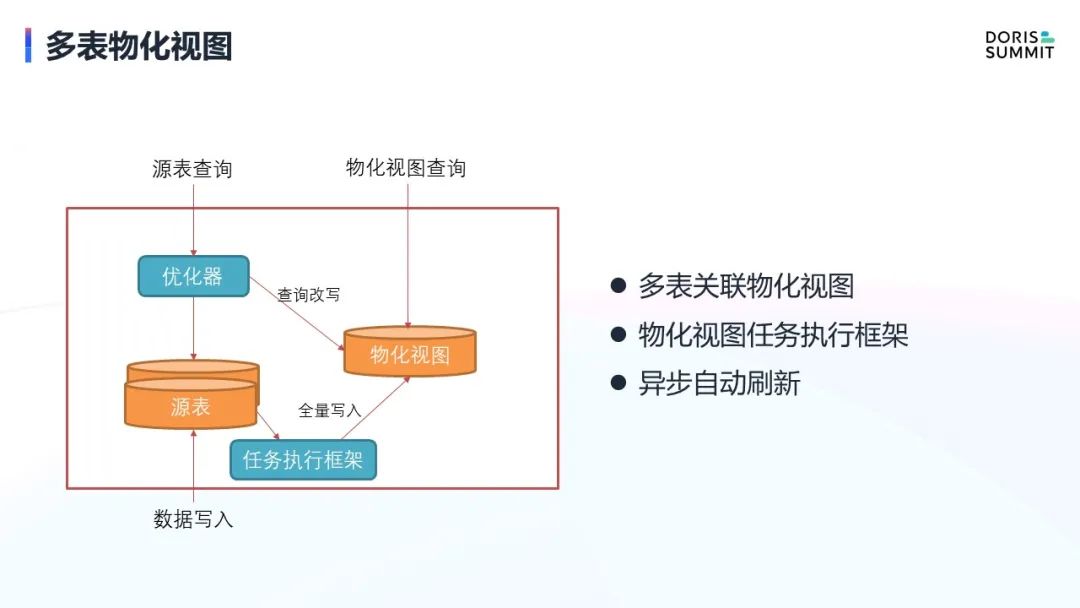
多表物化视图
第四个是多表物化视图,该功能是一个典型的空间换时间策略,通过预计算,配合查询时优化器的改写能力,来直接查物化视图,避免重复查询原表,消耗过多的资源进行计算。
Doris 本身其实也有物化视图能力,但它是针对单表的,它的主要作用是能够对数据做简单的聚合,所以我们也经常把它当做聚合的索引。数据聚合后就不需要查原表,直接查索引性能会快很多,这也是它最大的使用场景。
但该功能目前有一些比较大的限制:
支持的聚合函数相对来说比较简单,比如在sum函数中嵌套的加入 case when 语法, 该功能就无法使用了,这就是目前单表物化视图最大一个限制。
Doris 有比较好的 MPP 的能力,所以经常会被用来做多表的计算,单表的大宽表场景相对少。因此如果只有一个单表物化视图能力,能做的场景就不够多。
基于需求背景,我们提出了多表物化视图。目前这一功能实现还处于前期开发阶段,现在已经完成了多表物化视图的一些语法规则,也实现了物化视图的任务异步框架。
有了这个框架,数据就可以每天定期定时的从源表写入物化视图了。另外它也支持了数据的异步自动刷新,原表的数据已经能按照物化视图的建表 SQL 定义将数据自动写到物化视图中了。但目前还只支持全量的写入,暂不支持增量的写入,查询改写能力也尚不具备,所以项目还处于相当早期的阶段,大家如果有兴趣也可以加入我们一起完善。
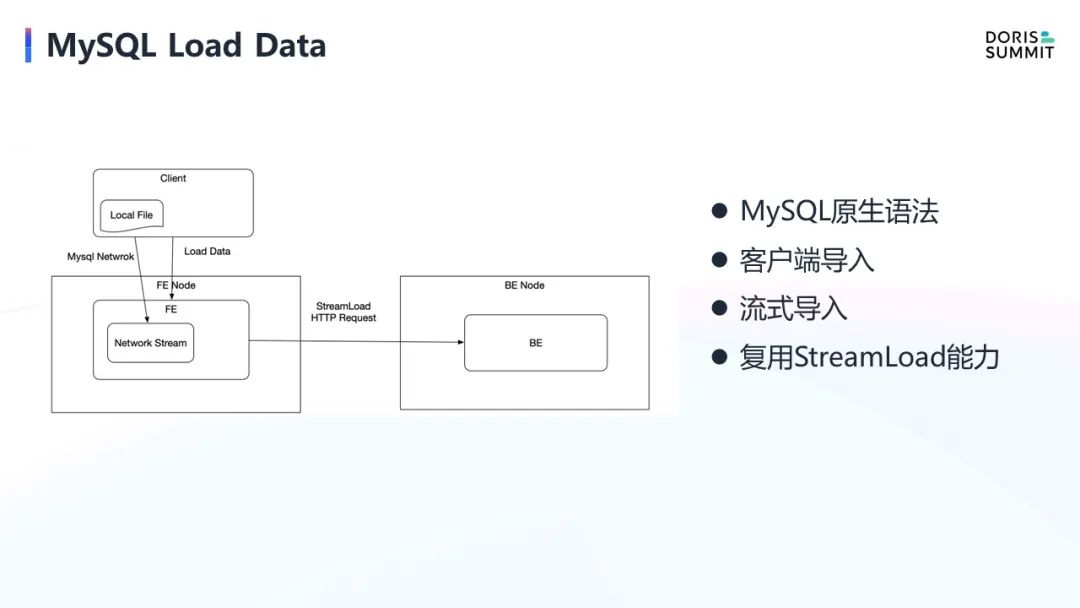
MySQL Load Data
第五个是 MySQL Load Data。Load Data 是 MySQL 里面的一个原生的语法,就是把数据从客户端加载到服务端的 SQL 语法,在 MySQL 生态里面用的比较多,基本上所有的 MySQL 生态都支持该语法,因为它也是一种标准的数据导入方式。
但是在 Doris 中能导入本地数据的方式只有 Stream Loader,它本身是 Shell 命令行,跟 MySQL 的语法有些差距,因此用户就需要做很大的改写。
基于这种背景,我们希望能支持 SQL 语法导入客户端本地文件的能力。在具体实现中,我们按照 MySQL 网络协议,通过客户端包发送方式,把在本地的数据通过 MySQL 客户端直接发送到 FE 节点,再通过流式的方式封装成 Stream Load HTTP Request 发给 BE,然后 BE 调用原来 Stream Load 的逻辑把数据导入进去。这个功能实现 MySQL 生态的 Load Data 能力,也是 Doris 支持 MySQL 生态比较大的一个点。
多流 Upsert
第六个是多流 Upsert。这也是比较大的一个功能点,它源自于 Flink 里面做多流 join,要维护比较大的状态,会导致集群不太稳定。所以现在很多 OLAP 引擎都支持部分列更新的能力,支持多流 Upsert。
我们也是基于原来的 unique key 表引擎实现了部分列更新的能力。具体能力如下图右侧所示,有两个 Stream,它的主键就是K1、K2,数据也有可能是乱序的。在要进行 merge 的时候,会根据 key 值把数据按照它的顺序合并起来。
有该特性以后,数据的 joining 就变得比较简单。性能相对于原本使用 Flink 也有较大提升,因为它省去了大量的回撤操作,所以在存储引擎去做这个能力还是非常不错的一种选择。
我们有位客户,他有 8 表做 join 的一个案例,因为他之前是用 flink 写到 PostgreSQL中的,PostgreSQL天然支持这种多流 Upsert,所以如果在 Flink 里面改写为 join 方式会非常困难。而 Doris 支持多流 Upsert 后,用法就跟 PostgreSQL 的用法完全一致,效果也会好很多。
在性能方面,如果数据量不太大的时候,性能也是非常好的。当然如果是数据量特别大的时候,可能目前的这套实现还不是特别好, 因为读取时要做大量的合并操作。我们这个功能还没和社区合并,社区现在最新版本的 unique key 实现有了很大的优化,我们还是基于老版本去实现的。后续我们也计划基于新的 unique key 模型,将多流 Upsert 能力也贡献到社区中去。
 基于Doris实时数仓的核心能力
基于Doris实时数仓的核心能力
以上是火山EMR对社区的贡献,下面将介绍我们基于 Doris 到底做出了一个怎样的产品。
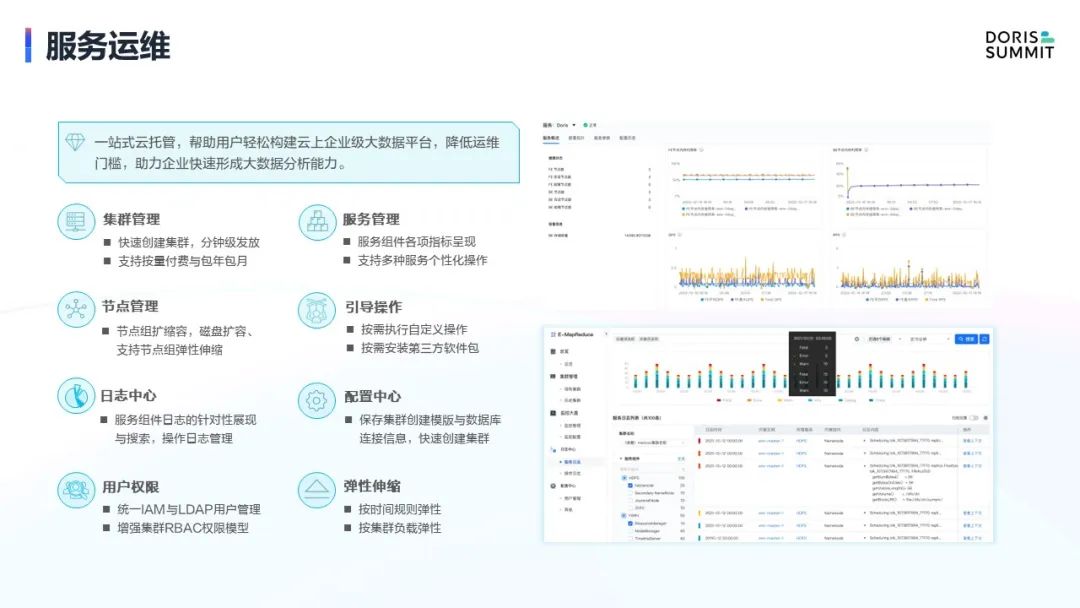
首先我们对客户提供的是云服务,所以除了引擎本身,引擎周边相对来说是我们重点布局的方面,例如下图右侧监控告警。如果是 IDC 用户,监控告警一般需要自己基于 Grafana 搭建。
而作为云上的一款产品,提供完善的运维监控体系就可以大大简化用户的搭建成本。我们将相关的运维相关的功能直接在控制台页面透出,例如日志查询,以前日志需要自己去采集,现在也是完全不用户操心,直接在日志中心里面看到所有的服务器日志,用户只要在这个页面上查询,跟原来用 ES 去做搜集和用 Kibana 做展示 的效果差不多的。
除了监控、日志以外,还有集群的扩缩容能力,这也是云上的这种服务化能力优势的体现。对于集群节点配置,用户也不需要手动管理,而是直接使用配置中心,通过控制台页面很方便的进行配置更改。
接下来的几个点,我们要谈谈火山引擎 EMR 相对于其他云上 EMR 产品, 在 OLAP 引擎有哪些差异点。
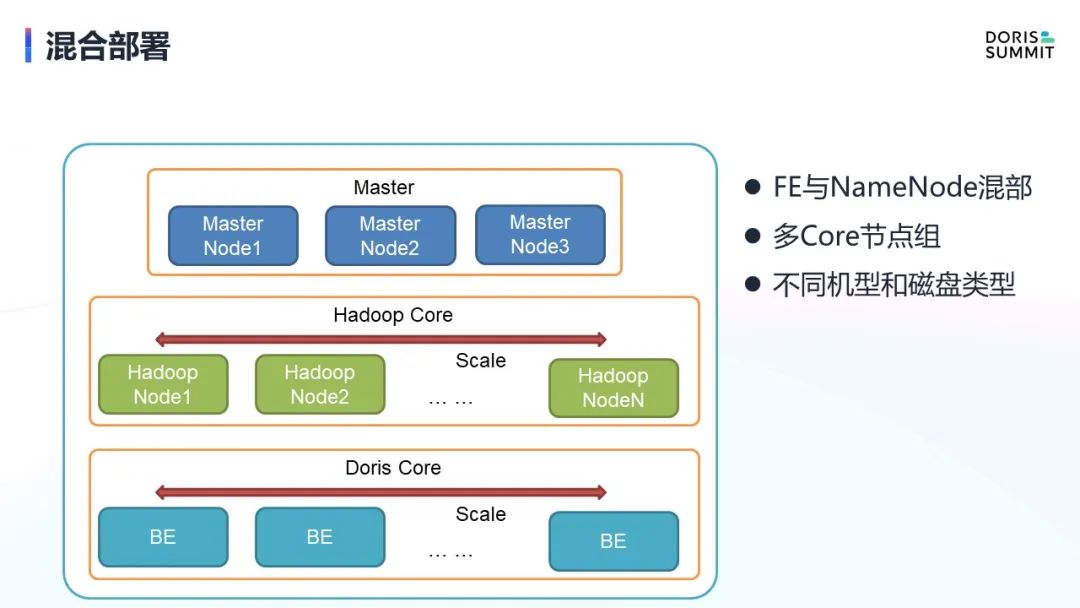
混合部署
第一点,混合部署。在下图场景中,FE 和 NameNode 是在 Master 节点中混部的。实际上在计算的时候,只需要用到 BE 节点,但 FE 这三个节点又必须部署,不部署就无法正常工作。如果部署在 BE 中,又会受到隔离性的挑战。我们很多用户也有这种方面需求,希望能把 FE 节点和 Master 节点混部在一起。Hadoop 的NameNode 也与之类似,它不参与计算,只是作为一个 RPC 的响请求响应,做一些主备功能,或者做元数据管理等。由于不承载数据的大规模吞吐,所以 NameNode 和 Doris FE 的定位比较像。
因此我们做了这样一个优化, 将 FE 都部署在 Master 节点上,完成了一个混部。但计算节点目前我们不推荐用户去混部,因为 Doris 和 Hadoop 对磁盘、机型的要求不太一样的。Hadoop 比较合适使用本地的 HDD 盘,但是 Doris 就是推荐本地 SSD 盘。
所以我们做了这样的多 Core 节点组策略,也就是 Hadoop Core 和 Doris Core 节点组, 两者可以选择不同的机型和不同的磁盘类型,他们彼此独立的扩容节点,互不影响的情况下实现弹性能力。Master 节点是混部的,随着业务增长 Master 节点也支持升配,实现垂直扩容能力。
弹性节点组
第二点,弹性能力, Doris 本身不具备弹性的,而是有状态服务。但由于我们做了 ComputerNode 能力,也就使 Doris 支持了弹性能力。
有了 ComputerNode 后,CN 节点就可以按照要求就去做弹性策略了。我们可以完按照时间力度去做弹性,比如早上需要计算的数据多,就进行扩容,其他时间段, 数据处理量不大就进行缩容。这也比较符合联邦查询的特点,一般都是白天负载会相对高一点。
另外一个是基于集群负载的弹性能力实现自动的扩缩容。我们也支持基于时间和基于集群负载的弹性策略混合使用。

自适应配置
第三点,自适应配置。Doris 目前的默认配置都是基于 IDC 的模式,一般都是按照大规格机器(128G 以上)去推荐设置的。这对于一些云上比较小的客户,比如 30G 以下的小规格的集群,会带来很多问题,我们之前遇到了很多 OOM 问题。
因此我们基于不同的数据规模,设计了不同的集群规格,并针对每种规格地进行不同的配置优化。
针对小规格,我们就将 page cache 关闭,把 buffer pool 调小,并调低 index cache 和 Load 内存配置,调小 Session 内存。
针对大规格,我们主要是调大默认 session 内存和默认 batch_size 大小。
中规格相对来说比较中庸,我们调小了 page cache,调低了 load page 内存配置和 index cache。
通过这些配置的调整,我们完成了大中小规格的建设,减少用户的使用成本,也提高了整个集群的鲁棒性。
 未来规划
未来规划
最后,介绍一下后续规划。云产品最核心的价值是弹性能力,而 Doris 最初是基于 IDC 场景设计,弹性需求相对来说较低,所以短期内我们还需要对其进行大量的改造,来实现高弹性化。
首先是在数据存储方面,因为 Doris 数据是自身进行管理,通过 Tablet 副本实现数据的高可用性。但在云时代,Doris 仍旧自己管理数据其实没什么太大的必要,因为云上有 S3、 TOS 这些对象存储产品,它们能保证非常高的可用性,能达到了十几个 9 级别,这是通过 Tablet 副本很难实现的,这也是我们做存算分离的一个初衷。
存算分离,是把数据放到远端持久化存储中,通过缓存缓解一部分的查询性能压力。在此之上,我们整个集群就有了更好的弹性,剥离开数据之后的扩容也变的更加灵活方便,相当于做了一个 stateless 的 BE。存算分离也能帮助用户进一步降低成本,因为 S3 和 TOS 等对象存储产品相对于 SSD 存储要便宜太多了。
另外在稳定性方面也有了提升,因为不需要自己通过 Tablet 副本实现高可用能力了,可用性可以直接交给 S3 和 TOS 等对象存储产品来实现。整体系统复杂度也会大大降低,这也是存算分离能带来的一个非常大的优势。
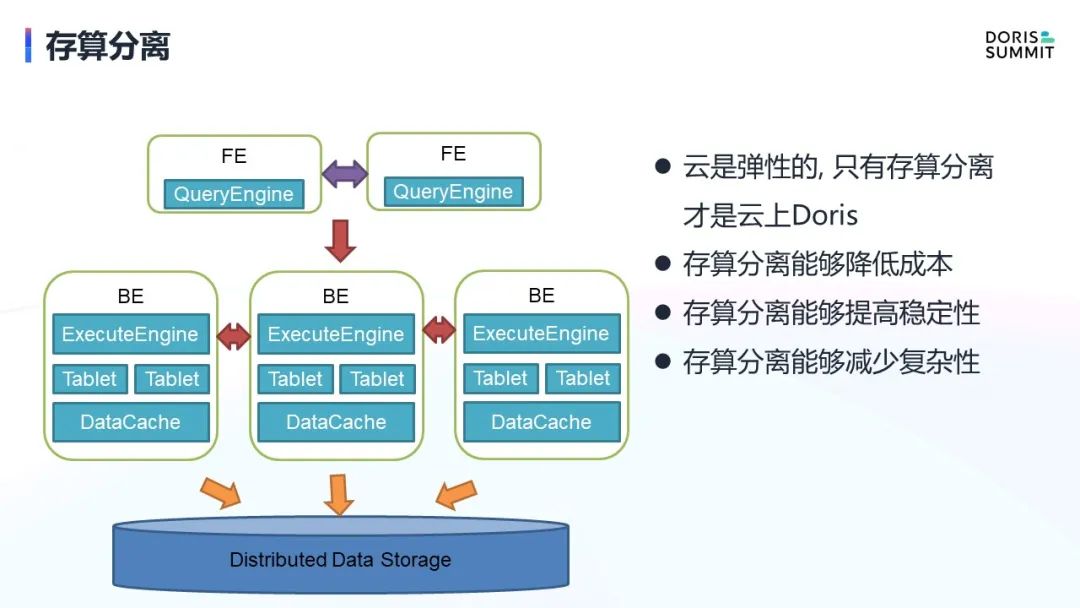
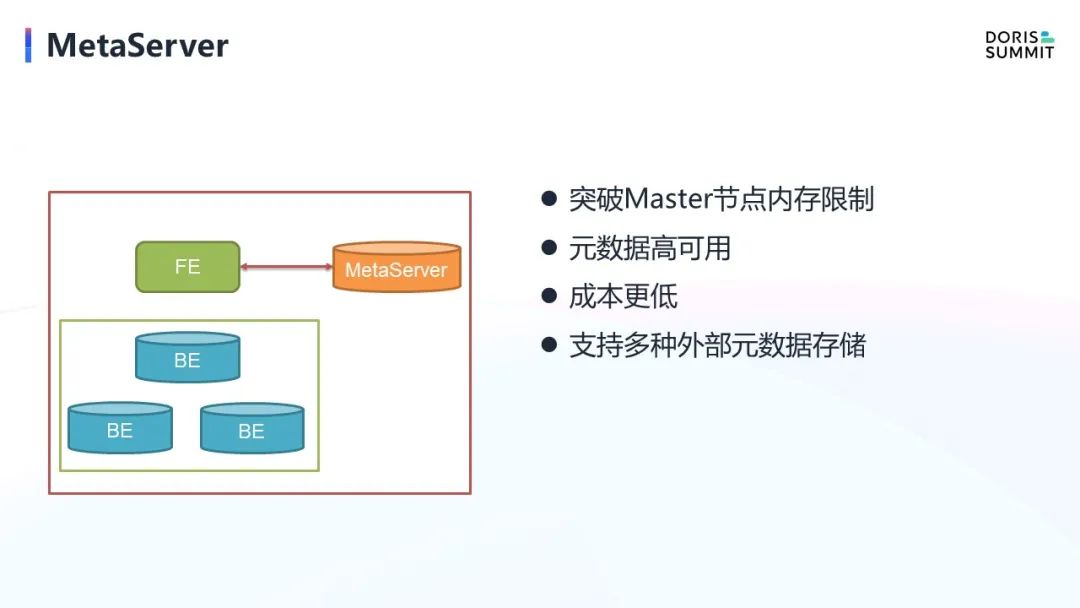
完成了数据的存算分离,数据弹性问题得到了解决,但元数据问题依旧存在。现在 Doris 的源数据是通过 bdb 做选主, 通过本地做数据持久化, 通过3副本做高可用,这种模式依然依赖于3节点来实现高可用. 我们希望能做一个 MetaServer,把元数据接到这样一个外部 MetaServer 中去,这样有几个好处。
第一,突破 Master 节点内存限制。现在的元数据全在内存中,当 Tablet 个数超过几千万的时候,内存消耗比较大。我们之前测过差不多 2000 万个 Tablet 的时候,内存达到将近 20G,这 20G 的数据完全在内存里,没办法用磁盘去做溢出。如果有了 MetaServer,比如基于 MySQL RDS,那就只将一些热点缓存在 FE 中,其他的有需要的时候再去拉取,时延也和现在的模式不会有太大差别。
第二,元数据的高可用性。MetaServer产品可以做到跨 AZ 级别,甚至跨 region 级别的高可用,但通过 FE 来说实现是非常困难的,这也是云上和云下的一个巨大的差异点,云上可以通过依赖标准的云产品的能力来实现自己能力, 而在云下这些都需要自建。
第三,节约成本。现在 FE 要通过三节点实现高可用,如果有了 MetaServer,只要一节点就可以,成本也就随之降低。
第四,支持更多类型的外部元数据存储,比如RDS,KV 数据库等。
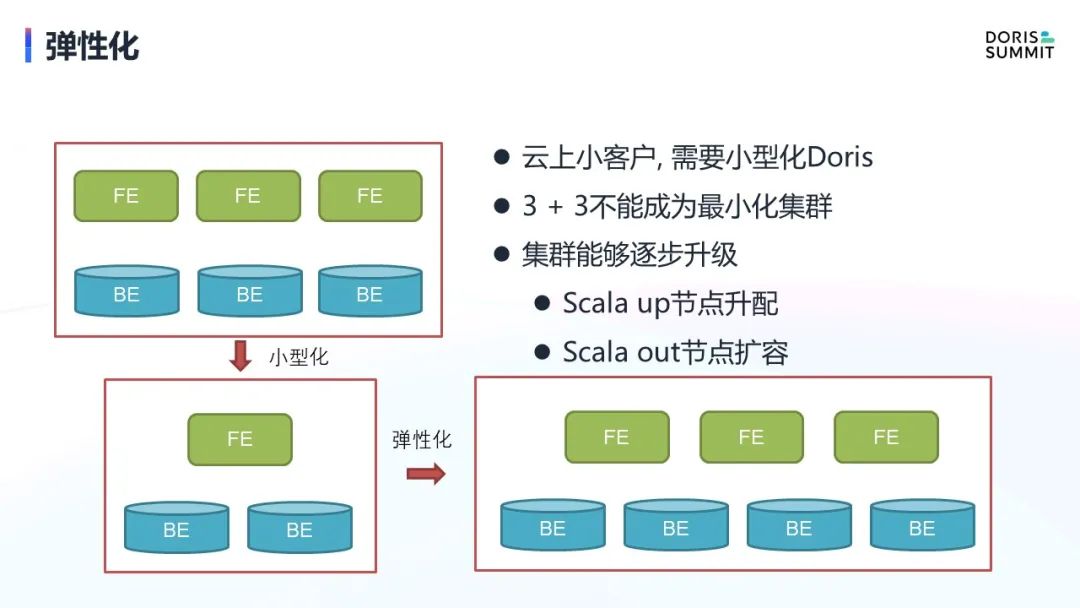
最后是弹性化。如果说前面提到的存算分离、MetaServer 都是手段,那我们真正的目的是希望做到 Doris 的极致弹性化。
目前 Doris 的最小部署必须是 3+3 配置,3个 FE 做元数据的高可用性,3个 BE 做数据的高可用性。3+3 配置对于一些大客户其实没什么问题,但是对于一些小客户是很痛苦。3+3 配置过高,小客户希望通过1个 FE 和1个 BE 就可以实现。
这时候我们可以通过前面两个手段解决了高可用的问题,更好地实现节点的小型化。有了小型化以后,就可以做到一个 FE,两个 BE 来部署一个集群,甚至是一个 FE 和一个 BE 部署一个集群。这样我们可以满足大中小客户的各类需求。
针对弹性化,集群规模可以跟随业务发展不断升级,这也是个云的基本能力。扩容有两个方向,一个 scale up,节点升降配都是比较常规的能力了。另外一个 scale out,这是本身 Doris 就有的,但是如果做了存量分离和 MetaServer 后, scale out 能力会进一步加强。有了这两个能力,我们才可以说 Doris 成为了一个真正意义上的云上 Doris。
火山引擎 EMR 团队将持续不断的针对云上 Doris 能力进行持续优化,也欢迎大家来试用火山引擎 EMR 中的 Doris 集群。

