解锁潜在价值,智行日志治理的实践之路
一、背景
日志,作为系统运行的忠实记录者,不仅是问题追踪的利器,更是性能调优的指南针。通过深入分析日志,我们可以洞悉系统运行的每一个细节,从而快速定位问题、优化性能。同时,日志也可以作为数据分析和决策的重要依据。研发流程中,如何使用好日志,还是存在着以下难点。
为了排查问题,我们通常需要记录大量的日志。如何关联客户端当次请求的所有日志,确保信息的完整性和连贯性;
日志记录对象过大可能导致频繁GC(垃圾回收),进而造成服务器不稳定;
一些核心日志的丢失会给排查问题带来极大的困难;
尽管日志的发送已经实现了异步处理,但过多的发送仍会占用CPU、内存等资源。大量的冗余日志也会浪费宝贵的存储资源;
针对以上问题,本文提出一个日志治理挖掘方案。该方案旨在通过对系统日志进行标准化、规范化、统一化处理,进一步挖掘系统日志的潜在价值。
二、思考
我们整理了日志的使用场景,大致分为四个方向:指标监控,Trace定位排障,性能分析,数据分析与报表(实时/离线)。
指标监控:指标监控是系统稳定运行的重要保障,它通过对核心业务逻辑、第三方接口响应、数据有效性等关键指标进行实时追踪与分析,确保系统性能始终处于更优状态。
Trace定位排障:在复杂的业务场景中,当遇到请求处理异常、系统响应错误、业务展示逻辑核对等问题时,定位排障成为了关键的一环。当我们已经通过上游定位、CDataportal查询或日常开发调试等手段,确定了具体的问题请求,接下来的任务就是通过日志精准锁定问题所在,并迅速解决故障。
场景问题定位:场景问题定位是一种针对具体场景,通过深入分析、精细排查,以快速找到问题根源的方法。我们会利用日志分析、监控数据、用户反馈等多种手段,对问题场景进行深入剖析。通过对比正常场景与问题场景的差异,我们可以进一步缩小问题范围,确定可能的问题源头。
数据分析与报表:通过日志记录数据分析与报表编制流程,我们能够实时捕捉系统潜在问题,进而实现问题的迅速定位与解决。同时,这一做法也有助于我们更加精准地向团队成员、决策者及BI等相关方展示分析成果与深刻洞察,确保各方能够基于充分的信息作出合理决策。
三、解决方案
3.1 分布式系统日志的整合与串联
分布式系统日志的串联是确保在复杂的分布式环境中能够准确追踪和关联各个组件产生的日志记录,从而实现对整个系统行为的全面理解。以下是关于分布式系统日志串联实现中的关键步骤:
1)唯一标识生成:在每个业务任务请求开始时,生成一个全局唯一的标识。这个标识将贯穿整个请求的生命周期,用于标识和串联与该请求相关的所有日志记录。
2)标识传递:在分布式系统中,请求会经过多个系统或组件。为了确保日志的准确串联,这个唯一标识需要在请求传递过程中被正确携带。
我们通过在请求入口生成全局traceid,并存放在线程安全的context 中。每个组件、线程中,当记录日志时,从线程 `context` 中获取 `traceId`,并将其作为日志记录的一部分。通过这种方式,我们实现了服务内的日志串联。
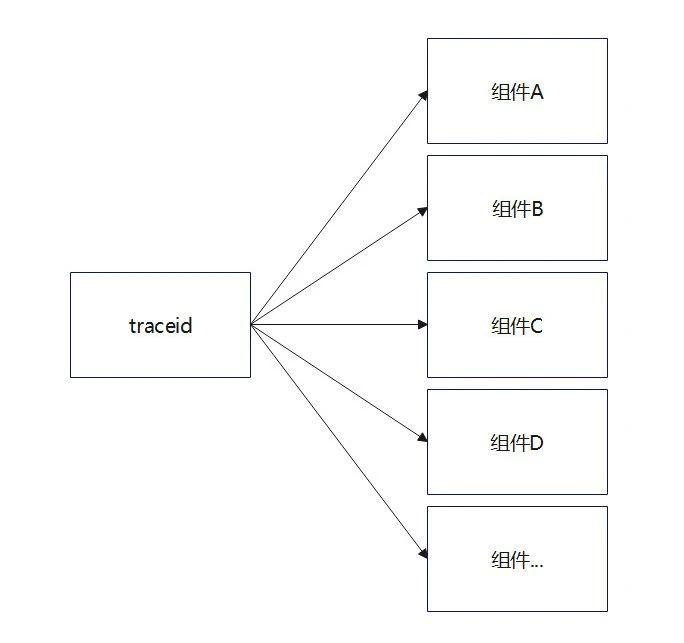
在调用下一级服务时,将当次请求的`traceId` 作为自定义头的一部分添加到请求头中。这样,下一级服务或组件就能够从请求头中提取 `traceId`,并将其存放到自己的线程 `context` 中,通过这种方式,我们实现了系统间日志的关联。

3.2 前后端日志信息的整合与贯通解决方案
前后端日志串联打通方案主要涉及前端和后端产生的日志能够按照特定的规则进行关联和整合,以便能够追踪和分析用户操作的生命周期。以下是前后端日志串联打通方案的关键步骤:
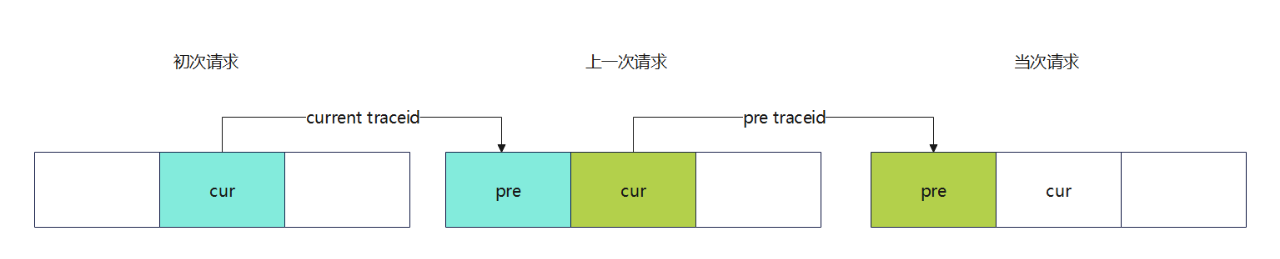
1)生成唯一标识:在请求的入口点(如API网关或负载均衡器),为每个请求生成一个全局唯一的标识,如`traceId`。这个标识作为用户上一次操作的traceid将用于串联前后端的日志记录。
2)传递`traceId`到前端:当后端响应前端请求时,将生成的`traceId`包含在响应头中返回给前端。前端接收到响应后,提取`traceId`,并将其存储在合适位置。
3)前端回传`traceId`:前端在发起下一次请求时,将存储的`traceId`作为请求的一部分传递给服务端。这样,当次请求就可以与上一次请求实现串联。
3.3 统一标准日志管理与模块化解决方案
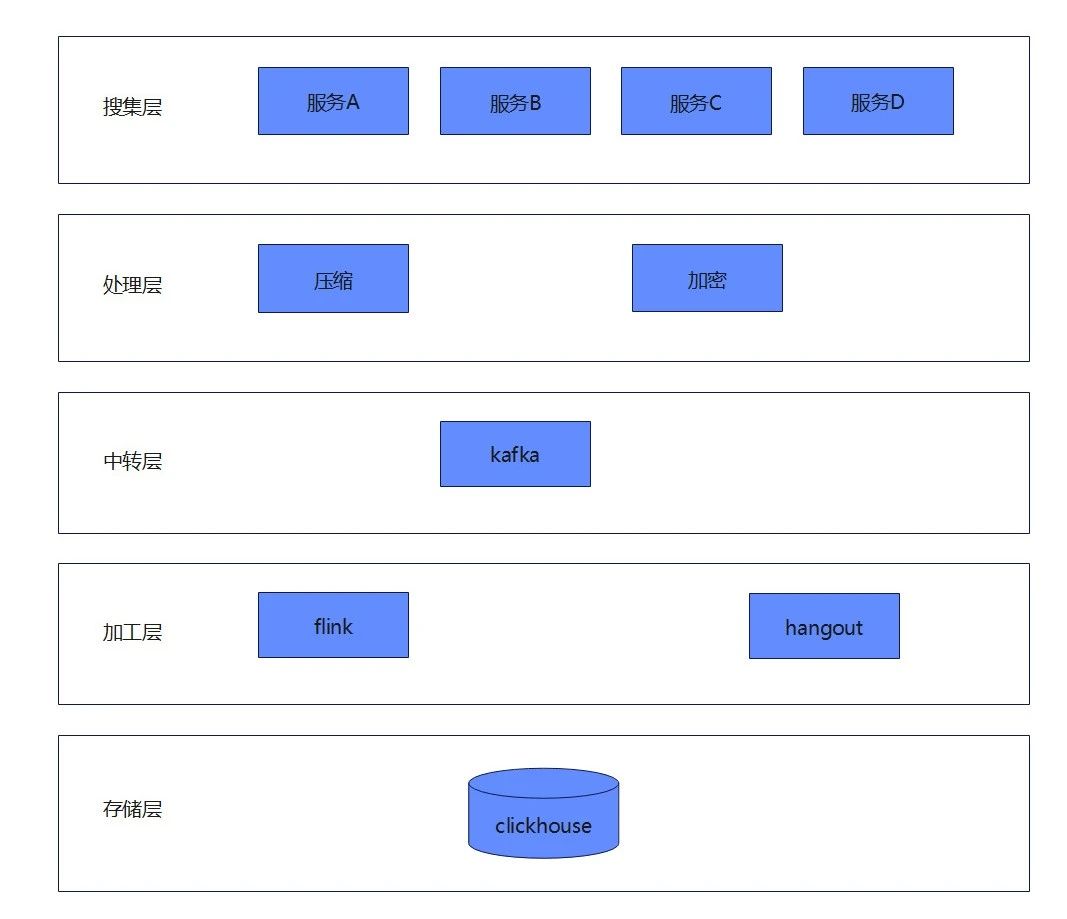
统一标准日志管理与模块化解决方案旨在构建一个统一、可维护且可扩展的日志记录、查询体系,以提升系统的可观察性、问题追踪能力,为系统的稳定运行和持续优化提供有力支持。以下是关于日志标准化与组件化的关键步骤:
1)同一日志分层标准:根据系统的不同功能和组件,将日志划分为不同的层级,如应用层、业务逻辑层、数据访问层、外部接口层等。每个层级应记录与该层级相关的关键信息和事件,以便于问题定位和性能分析。
2)统一日志格式:定义一套标准的日志字段,包括但不限于时间戳、traceId、日志级别、日志来源、请求信息(如请求方法、URL、参数等)、响应信息(如状态码、返回数据等)、异常堆栈等。确保所有系统和组件产生的日志都包含这些标准字段,以便于日志的聚合和查询。
3)统一接入方式:制定日志接入的统一规范,包括日志的收集、传输、存储等流程。明确日志数据的数据格式(如JSON、XML等)、传输方式等。
4)日志分析工具:开发日志分析工具,对收集到的日志数据进行加工处理,统计分析、可视化展示和异常检测等功能。
5)安全与性能优化:对敏感数据进行加密处理,确保存储过程中的机密性。对日志数据进行压缩处理,减少存储空间的占用和网络传输的开销。
3.4 大报文日志的精细化管理与处理方案
大报文日志的处理过程中,确保日志的完整性和可读性,同时保证不影响服务性能,是至关重要的。以下是处理过程的关键步骤:
1)大报文日志的判断
根据系统的内存限制、日志的生成频率以及业务需求,设定一个合理的内存占用阈值。对指定日志报文对象做内存空间占用分析,如果超过阈值,则视为大对象。
2)异步压缩、发送
使用线程池,创建专门负责压缩和发送日志的后台任务。当有大报文日志产生时,将其传递给后台任务队列,由后台任务异步处理,确保主服务能够继续处理请求。
3)选择合适的压缩算法
使用如Gzip、ZSTD等高效的压缩算法,这些算法能够在压缩率和解压缩速度之间取得良好的平衡。确保所选的压缩算法能够处理大报文,并且不会导致内存溢出或其他问题。
通过以上关键步骤的实施和监控,可以确保大报文日志在处理过程中的完整性和可读性,同时尽可能减少对服务性能的影响。
3.5 高效日志清洗与多维度分析解决方案
日志清洗与分析方案,旨在实现日志的有效清洗与分析,通过提取有用信息、转换结构化数据,为后续的分析、监控和故障排查工作提供坚实基础。方案主要包括日志处理、关键字段提取、维度聚合和可视化展示等步骤,以确保日志数据的准确性和分析的高效性。以下是该方案的主要步骤:
1)日志处理:从各个系统和应用程序中收集原始日志数据,对需要进行加密或压缩处理的日志信息进行解密和解压缩操作,还原出原始的日志内容。根据业务需求,筛选出需要分析的日志数据,排除无用或重复的日志信息。
2)提取关键字段:通过Aviator 引擎运行提取脚本,识别并提取出日志中的关键字段,如接口名、是否成功等。对提取出的字段进行格式化和标准化处理,确保字段的一致性和可比性。这些字段是后续分析的基础。
3)维度聚合:根据业务需求和分析目标,定义合适的维度,如时间维度、事件类型维度等。按照定义的维度对日志数据进行聚合统计,计算出各个维度的统计指标,如计数、平均值、最大值等。将聚合后的结果存储到clickhouse中,以便于后续的查询和分析。
4)可视化:根据业务需求和分析目标,设计合适的看板,展示关键指标和统计结果。生成详细的报表,包括各个维度的统计数据和趋势分析,以供业务人员查阅和分析。在看板和报表中提供交互功能,如筛选、排序、钻取等,方便用户进行深入分析和探索。

四、未来规划
组件化:通过组件化,我们可以为系统提供零入侵的接入方案。这意味着在接入日志治理系统时,无需对原有系统进行任何修改或侵入,只需将日志组件集成到系统中即可。这种零入侵的方式不仅保证了原有系统的稳定性和安全性,还大大简化了接入流程,提高了效率。
配置化:通过对关键流程接口进行扩展化处理,我们可以实现组件的灵活配置和定制。用户可以根据实际需求,对日志组件进行个性化的配置,以满足不同的业务场景和需求。
抽样化:核心日志往往包含了大量的关键信息,但其数量也非常庞大,如果全部存储,将带来巨大的存储成本。抽样化技术可以解决这个问题。通过对核心日志进行抽样输出,我们可以只保留部分具有代表性的日志数据,从而大大降低存储成本。
降低资源消耗:通过自定义序列化方式,我们可以优化日志数据的传输格式,减少数据传输量。其次,采用日志批量发送的方式,可以将多条日志合并成一次发送,减少发送次数和网络开销。

