精简代码实战:核心系统缩减80%代码
我们对精简代码做了一些创新尝试,在核心发券系统alsc-pc实践落地,取得不错的效果。希望能给大家带来一点参考价值。
精简代码是系统重构的一种手段,其目标在通过量化手段,辅助删减无效代码。通过减少无效代码来减轻系统的复杂度,提升系统的可读性、可运维性,从而减轻研发人员的理解、开发、运维的成本。
背景
软件系统会随着时间不断的成长,随着功能的添加和修改,代码数量不断的增加,函数之间的调用关系也越来越庞杂,最终导致代码复杂性增加、可读性下降,进而影响开发效率和软件质量。从某种角度来说,越是关键系统,承担的业务变化越频繁,其熵值增加的也就越快。因此,代码精简是一个重要的事情,体现在日常工作中,就是一个个小型的技改,很多时候,它们常驻to do list,目送其它需求一个个的发布。
“代码的阅读时间比写代码的时间多十倍以上。所以,让代码易于阅读至关重要。” --Robert C. Martin
1+6+N后,系统交割、数据独立运维,本地平台承接了几十个核心系统,千万行代码量级。这类系统特点是:演进多年,功能强大、逻辑复杂,保持了底层逻辑高度抽象、通用的同时,上层充分开放、灵活定制,以此支撑了多种形态的业务。团队接手后,需要快速的进入研发和运维状态。面对系统数量多、复杂度高,上手难度大的挑战,考虑到系统本身有很多代码,本地业务其实用不到。于是乎,代码精简成为一个重要且紧急的事情。
基于此,我们做了一些创新尝试,聚焦精简代码这个点,在核心发券系统alsc-pc实践落地,取得不错的效果。希望能给大家带来一点参考价值。
方案
这一章节主要围绕三个核心的难点展开:决策难、投入高、风险高,结合案例,给出实践方案。
1. 决策难
我们知道需要优化系统代码,但是怎么评估ROI是一个难题。减少系统10%的代码行,需要投入多少人力?减少20%的代码,能节省多少其他人阅读的时间,能提升多少的吞吐?以上问题,都在本文的射程范围之外(非常抱歉),需要根据实际的情况进行分析。以人力投入为例,其跟系统复杂度、变更频率、代码结构、历史负载、编程规范等均有关系,没有统一量化的标准,因此也就没有统一的方案。本文的意义在于,通过量化数据,给出定性的判断,辅助决策。
量化可以量化的部分:以生产流量来度量当前系统中,有效代码的占比(具体来说,是有效函数占比)。

如图所示,经过一个月的随机采样,采集到46万流量,以此来对系统代码进行染色,得到有效函数占比为~5.5%。
函数覆盖(有效函数) = 回放流量覆盖到的函数数量 / 系统的总函数数量
我们没有办法给出一个固定的门槛值:当一个系统的有效函数占比低于XX%时,就要开展代码精简专项。但是,我们不难判断,当该比例 <10%时,精简代码会取得不错的效果,是开展专项的良好时机。
Fowler、Bob大叔等人都在强调要重构、要优化系统代码。
但要是问他们:什么时候应该优化?
估计他们会答:任何时候。
问他们:优化能带来哪些好处?
估计会答:好处很多,自行体会。
2. 投入高
事中的部分,往往是最难的。正式进入删除代码的阶段,我们通过深入代码,从入口处逐层解读,分析每一个分支的业务含义,最终在脑中构建出一张函数调用的大网。大网以外,孤立的类、函数,很容易解决,IDE和静态代码扫描都能帮到我们。大网以内的部分,就需要结合业务场景进行人工的逻辑分析,并做出判断。
注意,在这里需要明确区分:精简代码和常规重构两个目标。精简代码,在走读过程中,需要时刻聚焦在:这个函数是不是必要的,能不能删除?而后者,聚焦在这个类、这个函数是否符合SOLID原则、是否符合命名规则,需不需要重写?
本文的方案依旧是,量化可以量化的部分:通过函数称重,以生产流量来量化每一个函数的重要程度。
函数权重 = 该函数被调用的次数 / 流量总数
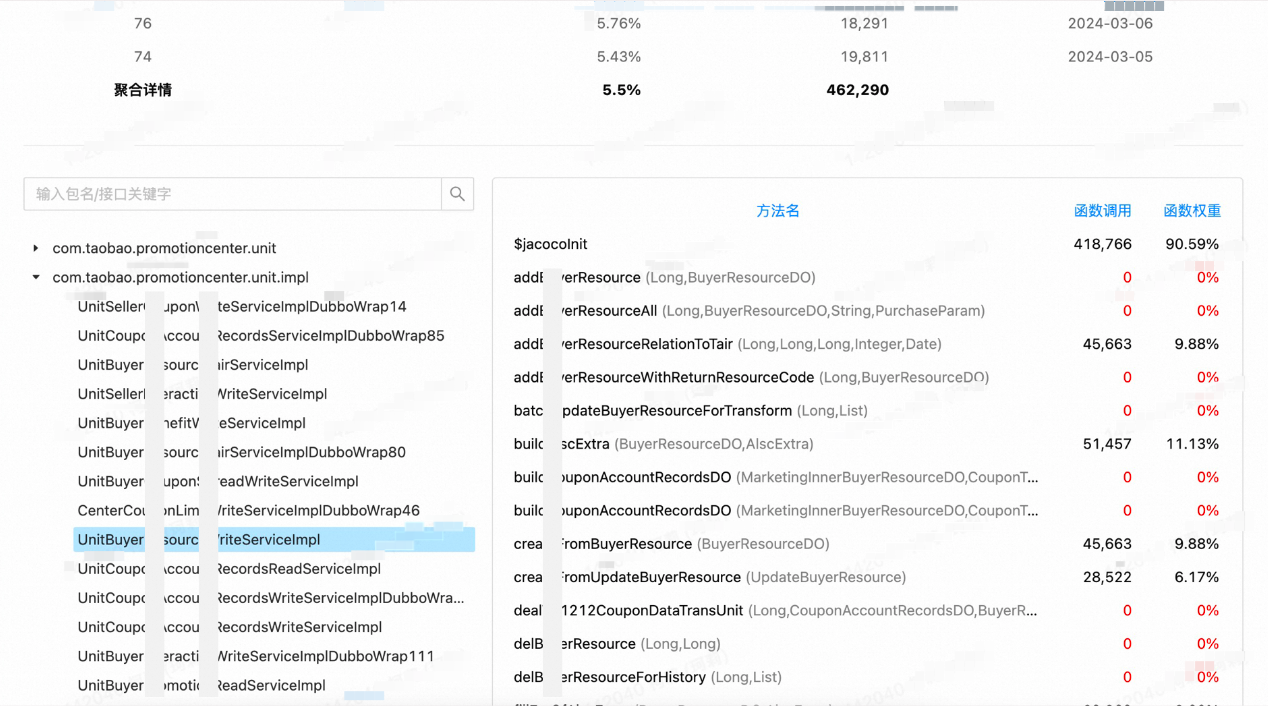
如上图所示,左侧是类列表,右侧是选中的类下面的所有函数列表。右侧部分,每一行是一个函数,后面的数据就是其被调用的次数、函数的权重。
这部分数据,会帮助到开发同学,用以印证脑中的函数调用大网。在代码走读的过程中,实时的查看量化数据,形成快速的反馈机制,有助于理清思路、减轻脑负担,同时也能有效的防止分析遗漏。
IDE插件内部提示:
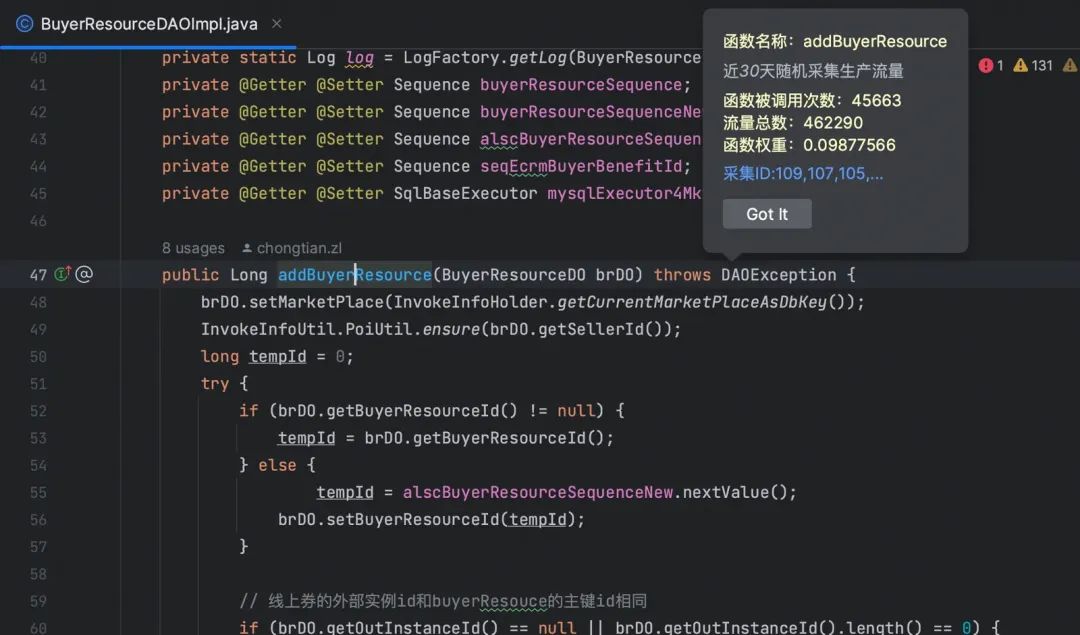
重点说明:由于流量是采样的数据,虽然通过随机、长时间采样,从统计上可以无限毕竟全量数据分布,但是对于核心系统来说,不能完全依赖统计分析。因此,精简代码的过程,需要以数据为辅,最终由人工来决策。
根据实践情况统计,以上的函数权重反馈机制,可以帮助开发同学有效减少30%-40%的代码走读成本。
20世纪初,福特公司有一台电机出了问题,导致整个车间生产停转,大批内部工人、专家反复查看都无法找到原因。后来,公司请来了斯坦门茨。斯坦门茨仔细检查了电机,然后用粉笔在电机外壳画了一条线,对工作人员说:“打开电机,在记号处把里面的线圈减少16圈。”人们照办了,令人惊异的是,故障竟然排除了!生产立刻恢复了!福特公司经理问斯坦门茨要多少酬金,斯坦门茨说:“不多,只需要1万美元。”1万美元?就只简简单单画了一条线!斯坦门茨看大家迷惑不解,转身开了个清单:画一条线,1美元;知道在哪儿画线,9999美元。
真正的难题不是培养斯坦门茨,而是技术化的解决“知道在哪儿画线”。
3. 风险高
毋庸置疑,删除代码是一件极其高危的操作,一不小心就会删在“大动脉”上。精简代码是一个典型的重构类项目,其质量保障的重点是确保:功能无损、性能无损、应急能力无损。对应的手段主要有:回归、灰度、压测、演练。
当然,以上手段需要根据实际情况进行选型和调整,以alsc-pc重构为例,经过综合考量,决策新建系统alsc-coupon(迁移alsc-pc的有效代码),并逐步完成上游流量的迁移。基于此,带来了一些新的挑战:
天启用例不能直接使用,需要人工修复流量、mock子调用、mock配置等。而这部分的复杂度极高,导致ROI极低,我们最终放弃了天启回归方案。进一步,引发了回归覆盖的挑战。
新系统,新的配置,需要专门验证。对于一个演进多年的系统,往往有大量的switch, diamond配置,如何高效的验证是一个难题。
新建的部署结构,重点关注高可用风险,性能、限流、单元化等。
风险及应对策略

由于灰度、压测、演练等各个保障手段,有已经有大量的文章专门介绍,不再具体展开。万象仿真是基于场景的E2E回归方案,场景背后是DB数据特征抽取;配置一致性检测,是一个繁锁和重复的过程,我们沉淀了镜铃平台;VIP已经是一个老朋友了,由于其能力在持续演进,跟文章中描述已经是面目全非了,计划“重构”文章中。
以上,希望对大家有所帮助。
"任何值得追求的目标都会涉及风险。成功的关键是学会管理风险,而不是回避它。" --赫伯特·欧特尔
后记
颗粒度对齐一下:精简代码为什么全篇都在聊函数粒度,不是行粒度?
嗯,函数和代码行的关系,有点类似原子和内部粒子的关系。原子决定了物理性质,如质量、体积、温度、密度等。对应于函数决定了功能、性能。原子间建立连接组成各种分子和物理世界。对应于函数之间相互调用,组成了接口服务,支撑了业务。因此,函数是完整的功能原子,是人工分析极其合适的粒度。同时,原子中,删减质子,会改变原子本身,可能使金原子变成氢原子,在此基础上搭建的分子、物质都会坍塌。同理,精简函数内部的代码行,可能使函数、系统服务“坍塌”。
好吧,最主要的原因是,我们还没从技术上解决轻量级的代码行称重的难题。

