播放全链路压测实践之路
01 背 景
播放链路是爱奇艺最重要的业务,链路稳定性极其重要,随着爱奇艺用户的不断增长和热播剧集的推广,播放链路往往面临着难以预估的用户流量的突增,考验着链路中各个服务系统的稳定性和性能,这也直接影响着大量用户的观影体验,实施全链路压测已经成为重要且必要的课题。
为什么要进行链路级的压测,单机、单系统压测为何不可达成目标?
线上容量 ≠ 单机容量 * 数量:线上运行环境是复杂多变的,即使配置相同的机器也不能保证性能的完全一致,并且,除机器本身性能外,线上容量还受制于机器间的网络通信、资源争夺、数据库交互、集群管理、缓存效率、负载不均等等多方面的影响,任何一点都有触发性能瓶颈的可能,从而不能单纯的只通过单机 * 数量去评估线上容量。
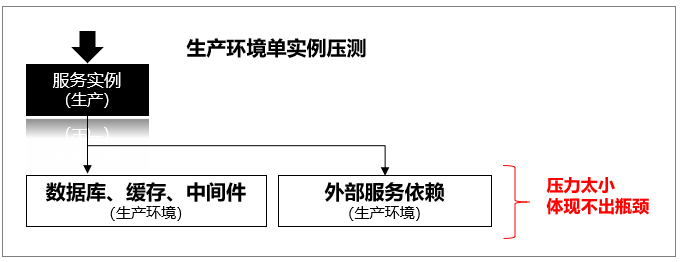
单系统无法体现用户角度的性能:用户请求是链路级的,而链路中各个系统的容量规划往往不对齐的。受不同的用户场景,用户来源,路由策略等影响,流量在链路上的分布情况不是一成不变的,整个链路上的瓶颈点非常不易发现和预测。因此需要进行全链路的多地域多来源的测试,并构建各种流量参数比例的流量场景模拟不同业务场景的用户行为等。
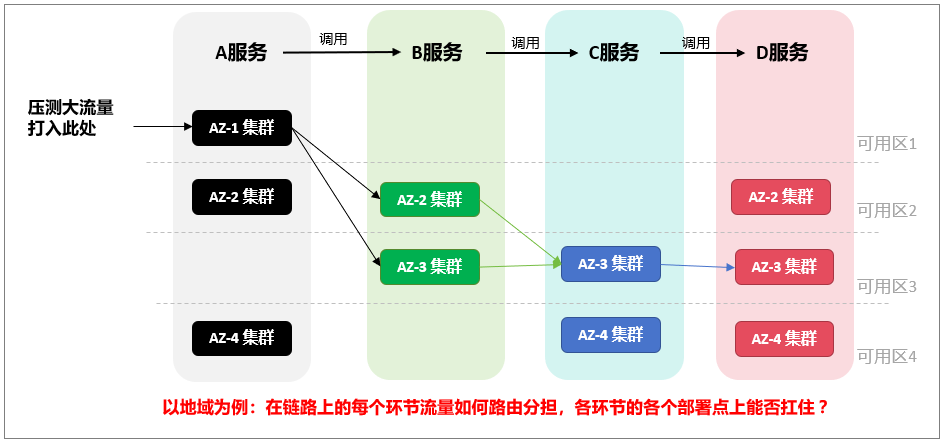
基于线上环境 or 测试环境进行链路级压测?
线上压测更准确:线上环境更加复杂,测试环境无法保证搭建效果与线上一致,任意一个配置的不一致都可能导致容量的差异,而无法体现真实用户使用效果,且搭建可用于链路级压测的测试环境资源需求量巨大,可行性不高。
对线上环境进行压测的风险如何规避?
例如防止压测数据污染线上数据,污染缓存,干扰线上指标统计,误触线上的熔断降级,避免没做好准备的外部依赖方被压测打挂等等。
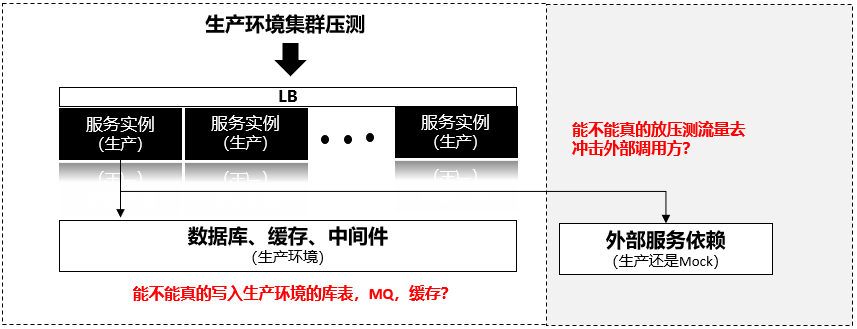
方案review+脑暴很重要:规避风险的措施需要在实践过程中反复分析、讨论、解决/规避。
以下以【播放-点播链路】为例阐述压测实践过程。
02 实践过程
全链路压测所能达成的效果往往依赖于施压能力的仿真程度,主要包括链路仿真和用户仿真
链路仿真:用户链路 vs 施压链路,考验施压链路环境的模拟能力
用户仿真:用户请求 vs 施压QPS+词表,考验施压压力及词表构造的模拟能力
梳理播放链路拓扑
为什么先做链路拓扑梳理?是后续工作的基础,重中之重
识别链路系统,明确核心链路,协作目标更聚焦
识别链路风险,明确对用户的影响,包括用户数据、业务指标、监控数据等
识别技术依赖,明确业务系统和基础平台的改造、升级目标,寻找最折中方案,降低不确定性的同时,工作量最低
识别关键数据,便于压测场景(即压测词表)的构造
以链路入口应用进行系统间调用、数据库、中间件读写的逻辑梳理,进而继续延伸至上游系统,最终绘制出完整的链路拓扑图

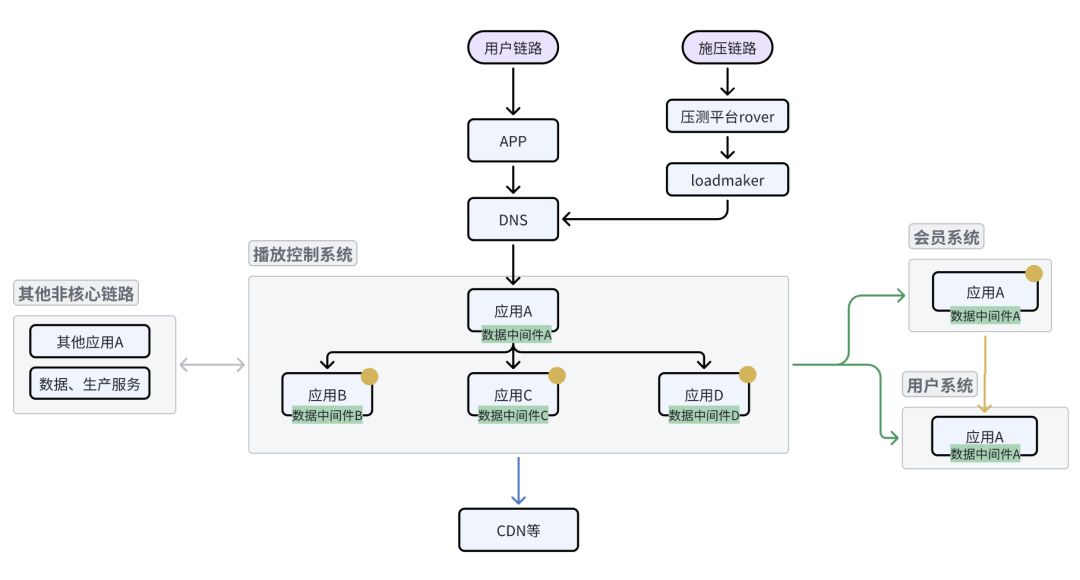
做了哪些工作:
推动各系统研发梳理各自业务内拓扑文档
与研发脑暴梳理结果,分析关键性能影响点、挖掘问题及风险
基于文档绘制交互拓扑图
达成的效果:
明确压测核心链路:播放、会员权益系统、会员权益监控系统等
识别脏数据风险:数据统计的影响等
明确压测工具需求:
流量控制:拦截统计消息
数据隔离:支持mysql、redis等的影子库、影子表,规避线上写入脏数据
流量监控:QPS、响应耗时、CPU、内存、中间件监控、上游服务监控等
明确核心性能影响因素:
片源时长、付费类型、会员身份
明确核心场景:
春晚:免费超长视频(历史峰值占比50%,非真实数据)
热剧:付费视频(付费流量历史峰值占比60%,非真实数据)
为什么不直接使用单url or 录制线上流量进行压测?
定制流量更贴近性能目标:单url不具代表性,且链路不全,不利于性能影响点的分析;录制流量在特定场景下有一定意义,比如春晚流量等,但由于难以分析出各场景比例,比如不同时长片源占比,付费片源占比,难以精准判断性能影响点,从而无法有效说明压测目标及效果
明确压测目标
压测目标:在 不同场景 下,综合评估 播放链路 的 容量(QPS)
需根据实际容量评估情况调整目标容量(以下数据仅供说明使用,非正式数据)
压测链路:播放、会员、用户链路
压测环境:线上各机房+全网
压测场景:春晚(>4h超长视频占比50%,非真实数据)、热剧(付费流量占比60%,非真实数据)
容量目标:不低于历史峰值n倍容量目标
压测工具调研
施压能力(LoadMaker):
单机房高压QPS的发压能力:可针对施压集群进行扩容
单机房亿级词表的调度能力(根据施压QPS+时长制定):多任务并发实现
梯度增压、暂停增压能力:用于压测过程观测,及时止损
链路控制(Rover):
流量控制:拦截数据统计:支持,Rover平台配置即可,同时构造测试设备双重规避
数据隔离:支持影子库、影子表,规避写入脏数据:不支持场景可通过构造测试账号规避
流量监控:QPS、响应耗时、CPU、内存、中间件监控、上游服务监控等:支持,并结合业务自身监控观测数据更全面
工具性能(Rover agent):
对服务性能0/低影响
施压入口(LoadMaker):
支持外网网关:一期优先使用内网网关
构造压测场景
场景:不同类型 用户 播放 不同类型 视频
举例如:

测试数据入库:测试账号、测试设备ID、视频信息(时长、付费类型等)
明确不同维度下的属性比例:

词表生成-支持不同属性占比的配置化生成方案:
交叉组合:支持多层属性的组合,可灵活配置不同属性及下一级属性的占比配置
遇到的问题:
词表生成耗时过长:亿级词表单机模式已无法满足效率需求,评估单纯通过优化生成脚本已无法有效提升效率
解决方案:
词表生成容器化:依托内部jenkins服务,基于iks进行容器化部署,实现多容器并行生成词表,大大提高效率
压测方案及规划
梳理各系统现状:各机房当前及历史峰值流量

明确按目标QPS及现有词表流量配比下,各系统能否达成预期流量,是否需要扩容,并给出扩容完成时间
压测过程:线下单机演练 -> 线上集群(逐步增加压测范围)演练
压测规划:
根据关键时间节点进行时间倒排,保证压测前各项准备事务全部ready
制定压测场景规划,明确压测时间点、各业务负责人、紧急预案,为尽可能规避对用户的影响,大QPS压测需控制在低峰时段,并提前进行邮件审批和周知

制定压测实施checklist,尽可能详尽说明每一步操作和确认项,避免遗漏
压测前一天进行一轮线下验证,确认施压能力、环境连通性,保证压测顺利实施
容量评估标准:包括但不限于以下几点
CPU、内存占比:<=70%
响应耗时:根据业务而定
请求错误率:0.01%
业务错误率:0.01%
压测执行
压测checklist

施压策略:
明确并发数及步调时间:提前与研发沟通确认,并可在执行过程中调整优化
阶梯施压:缓慢增压、流量突袭
实时反馈观测结果,如有问题,随时暂停或停止施压,及时止损
压测执行过程中数据观测:
Rover平台观测压测流量:QPS、耗时、CPU、内存、上游服务QPS
各业务内部监控平台观测整体流量:QPS、耗时、CPU、内存、上游服务QPS、业务错误率、降级/熔断等灾备流量、缓存命中率等
数据库/中间件性能监控
分析观测数据,评估链路容量
容量评估:应用、数据库、中间件,最终QPS是否达成,瓶颈在哪里
灾备能力评估:降级、熔断策略,阈值是否合理,在多大QPS下触发了灾备策略,是否仍有优化空间
给出压测结论及待解决问题
03 实践效果及收益
播放链路首次线上压测,且实现对真实用户0影响
完成历史峰值n倍QPS下播放各系统服务的容量评估
协同各业务完成7次扩容、5次灾备策略优化、4次性能问题修复等等
支撑春晚、热剧期间大流量下播放不出故障
04 总结和展望
在公司多个团队、两个季度的协作下,共同完成了播放全链路压测0-1的建设,并实现了首次超大QPS的线上环境全链路压测,具有里程碑意义。
但目前压测能力仍有许多不足,未来仍需进一步提升仿真能力,以更好的评估性能及影响瓶颈点:用户仿真,词表能力升级,支持更多维度;链路仿真,支持外网施压、多链路联动、多场景联动等。

