多域图大模型在百度推荐系统的实践与思考
01 图背景介绍
图是一种描述复杂数据的常用语言。常见的图结构包括:社交网络、分子结构、知识图谱、商业广告、地图等,其中推荐系统和商业广告是大家更为熟悉的场景。基于图的典型任务包括:
节点分类(node classification),如对于某些节点用户是否会点击或购买
边预测(link prediction),如用户与用户是否相似、用户与 item 之间是否存在连接关系
社区发现(community detection),如特定热门社区挖掘
网络相似度判定(network similarity),如一种分子与另一种分子结构是否相似
图分类(graph similarity),如分子类型判定
结合推荐场景,本次介绍将集中在节点分类与边预测任务中。

02 常用图模型算法
图模型的整体思路是通过机器学习算法,将现实中高维的节点投影到一个低维空间中,并尽量保留节点之间在高维空间中的关系。目前主流算法可大致分为两类:walk-based 的图嵌入算法(GE)和 message-passing-based 的图神经网络算法(GNN)。

1. 图嵌入算法(GE)
图嵌入算法是一种 walk-based 的方法,核心思想是通过某种游走策略生成一系列游走路径,使用 shallow encoder 将路径中的每一个节点投影为低维节点中的 embedding 表示,使低维空间中节点的共现概率与游走路径中节点的共现概率尽可能相近。该方法借鉴语言学经典 word2vec 模型思想。
根据游走策略的不同,图嵌入算法有多种变种,常用算法包括 DeepWalk、Node2Vec、Metapath2Vec 等。其中 DeepWalk 采用完全随机的游走策略,从上一节点向下一节点的游走过程中无偏。通过调整游走策略,可以产生多种衍生算法以提升最终模型效果。Node2Vec 通过预设的 p、q 两个参数以调节深度优先遍历与广度优先遍历,从而在训练中强调同质性或结构相似。当异构图中包含两种及以上节点时,Metapath2Vec 可以通过预先设定的多种元路径,消除游走过程中节点的 bias。

2. 图神经网络(GNN)
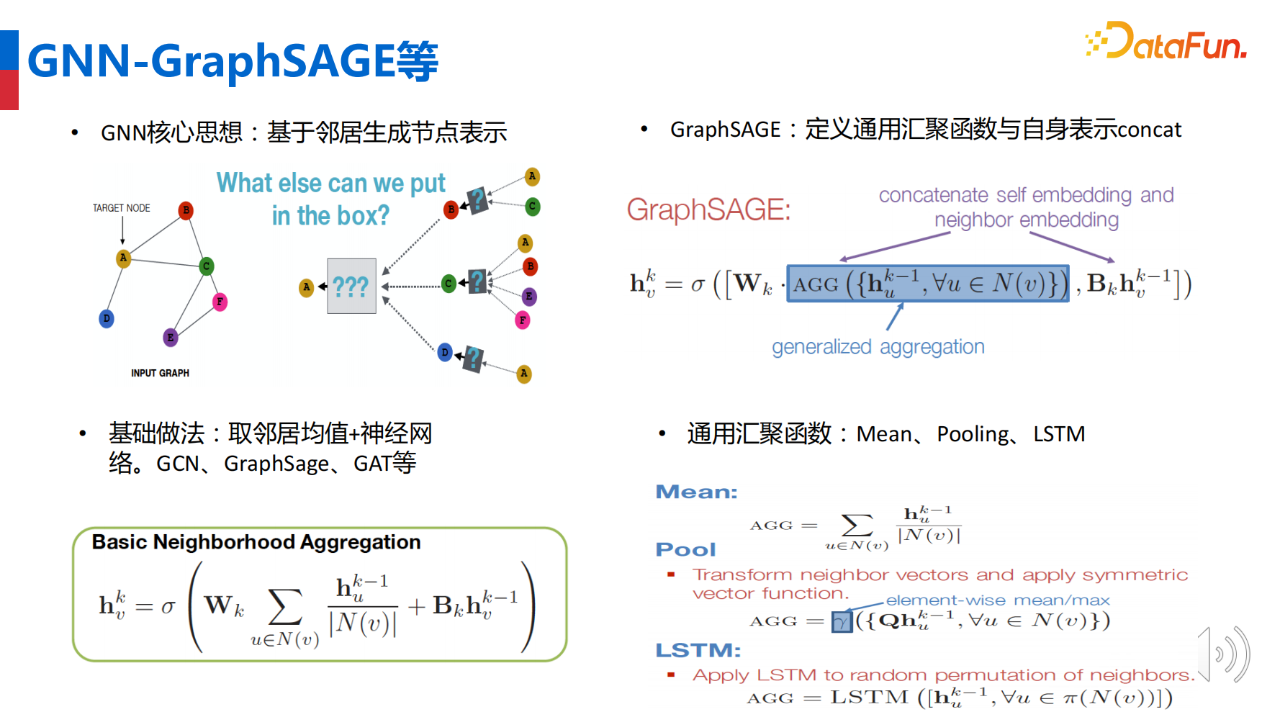
GNN 是一种基于消息传递(massage-passing-based)的算法,核心思路是在生成节点表示时使用 deep encoder。deep encoder 在建模节点时不仅考虑节点自身信息,同时考虑节点多阶邻域的信息,将邻域信息传递至当前节点的表示之中。GNN 的核心问题在于,如何对邻域及自身的信息进行传递及汇聚,最终得到节点自身的表示。如图所示,使用节点A和它的邻居 B、C、D,以及更高阶的邻域去生成节点A的向量表示。
基础做法是将邻域进行平均后通过非线性传递函数,节点自身也通过非线性传递函数,最终通过累加得到节点表示。根据如何汇聚邻域信息与自身表示,GNN存在多种变种,如 GraphSAGE、GCN、GAT 等。GraghSAGE 对邻域进行采样,信息汇聚过程被抽象为一个通用的汇聚函数,可以为取均值(mean pooling)、取最小值(min pooling)、取最大值(max pooling)或 LSTM 等,邻域表示与自身表示进行concat操作后得到最终向量表示。GCN 在邻域汇聚时通过减少度数较大节点的权重进行消偏,邻域节点和节点本身共享非线性传递函数层。GAT 引入 attention 机制,计算复杂度更高,模型精度也更高。
3. 算法比较
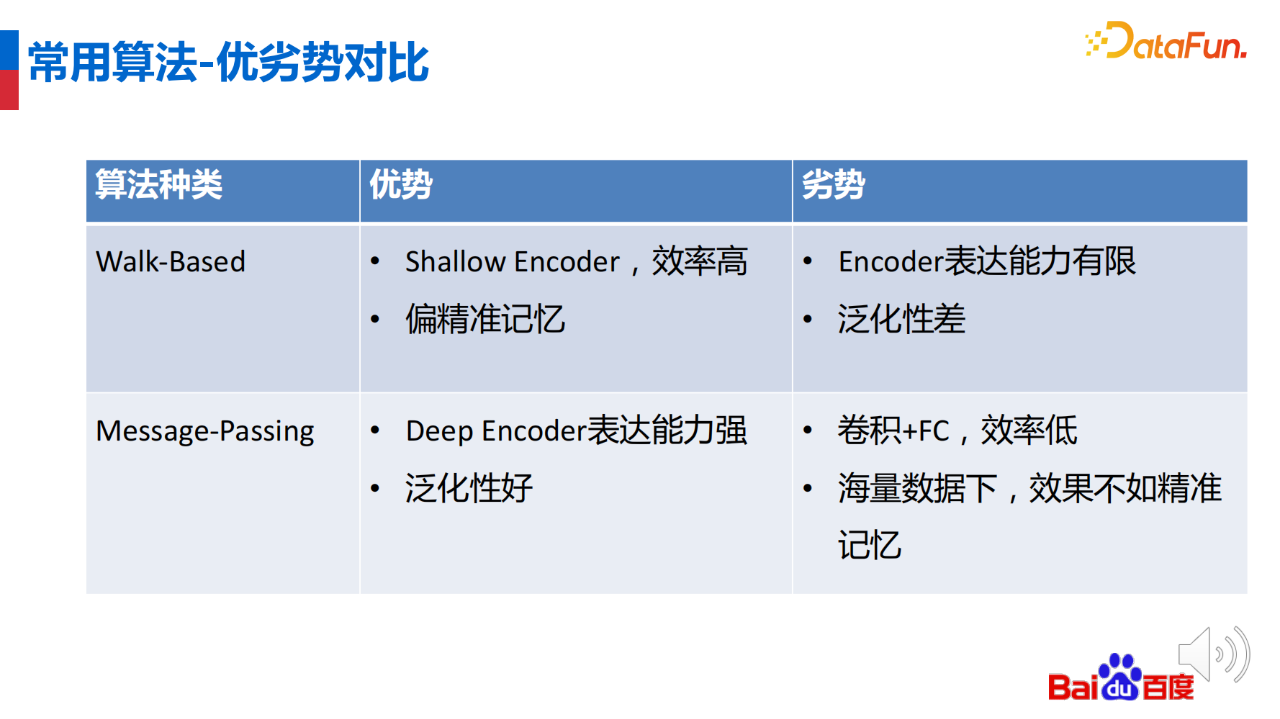
图嵌入算法与图神经网络算法各有自己的优劣势。图嵌入算法使用浅编码器(shallow encoder),建模效率高、偏精准记忆,但 encoder 的表达能力有限,泛化性差。图神经网络使用深编码器(deep encoder),表达能力强、泛化性好,但卷积+FC的模式计算效率低,在海量数据下效果不如精准记忆。
03 Feed 图模型演进历史
1. 模型演进
Feed 图模型共经历三个阶段。在 Item2Vec/User2Vec 第一阶段,用户表示为其一阶邻居,即用户点击过的 item 近邻的聚类中心。孪生网络第二阶段在第一阶段基础上引入度量学习,有监督地学习用户相似度,但其本质仍是使用用户的一阶邻居,尚未扩展到高阶。第三阶段使用基于图嵌入模型,在链接预测任务中注入高阶连接关系,提升整体连通性。

传统表示学习以原始数据作为输入,通过特征工程得到结构化数据,并通过启发式学习任务获取节点的向量表示,最后进行后续的应用。主要存在以下两点问题:
①建模多种关系需要多种启发式学习任务:以 User2Vec 和孪生网络为例, Item2Vec 通过学习用户的点击共现得到 item 的向量表示,user 的表示则需要将用户的点击进行汇聚,孪生网络 UCF 将用户点击随机划分构建正负样本学习用户表示。孪生网络的核心思想在于认为用户与自身相似,与其他用户不相似,因此可将用户的 readlist 切分两部分并输入左右两侧,认为左右两侧输出相似作为正样本;将其他用户的 readlist 作为当前用户的负样本。左右塔参数共享故称孪生网络模型。
②局部信息建模,高阶信息丢失:上述方法只使用用户的一阶邻居信息进行学习,样本为完整点击二部图的局部采样,在采样过程中仅保留低阶信息,高阶关系丢失。
因此,是否存在一种算法可以一次建模多种关系,并包含更全面的高阶信息?

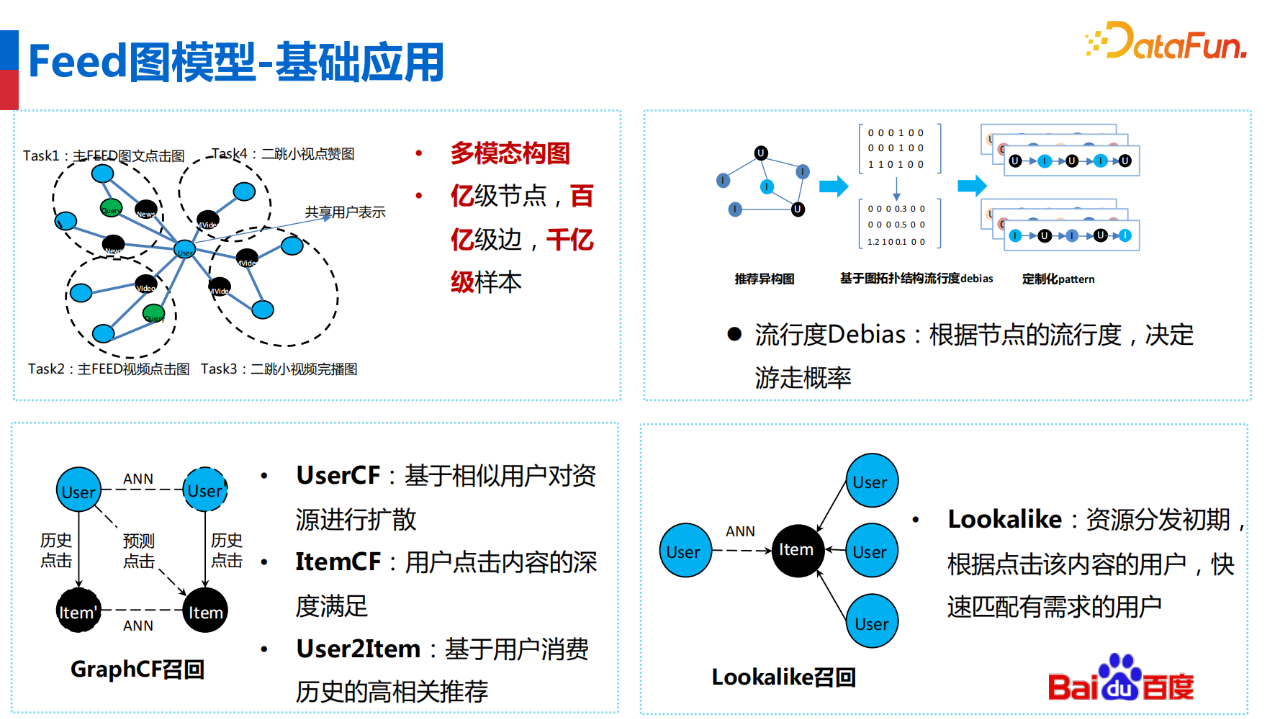
Feed 图模型于2019年在 Feed 召回完成的首次落地,并在后续相继推广的不同任务中均取得了很好的效果。图模型采用多任务学习的方式,统一学习多个场景和多个模态。多个场景包括单列、双列、视频沉浸式,不同资源类型拆开进行分别构图,如图文、动态、视频、小程序等,可更好地建模用户在各个场景、各个资源类型的行为,并将不同资源类型映射至同一个向量空间,为图模型应用打开更大的想象空间。
为了解决资源冷启动和低频资源冷启的问题,在资源侧引入 SideInfo 特征。由于推荐系统存在马太效应,部分节点占据大部分分发,导致一些节点频繁与其他节点共现并使推荐相关性变差。而另一部分节点出现频次过低,导致训练不充分,进一步降低后续曝光度。为解决该问题,引入流行度 Debias 策略,根据节点的流行度,决定游走概率。最后,图模型将多种节点类型,包括用户、item、query 等,映射至同一向量空间,很好地统一了多种召回模式,包括 UserCF、ItemCF、User2Item 等召回模式。Lookalike 召回关注在资源分发初期,根据点击该内容的用户,生成该资源的向量表示,在预热节点快速分发并匹配有需求的用户。
2. 模型推广
后续该模型进一步推广至原生广告、贴吧等产品线。
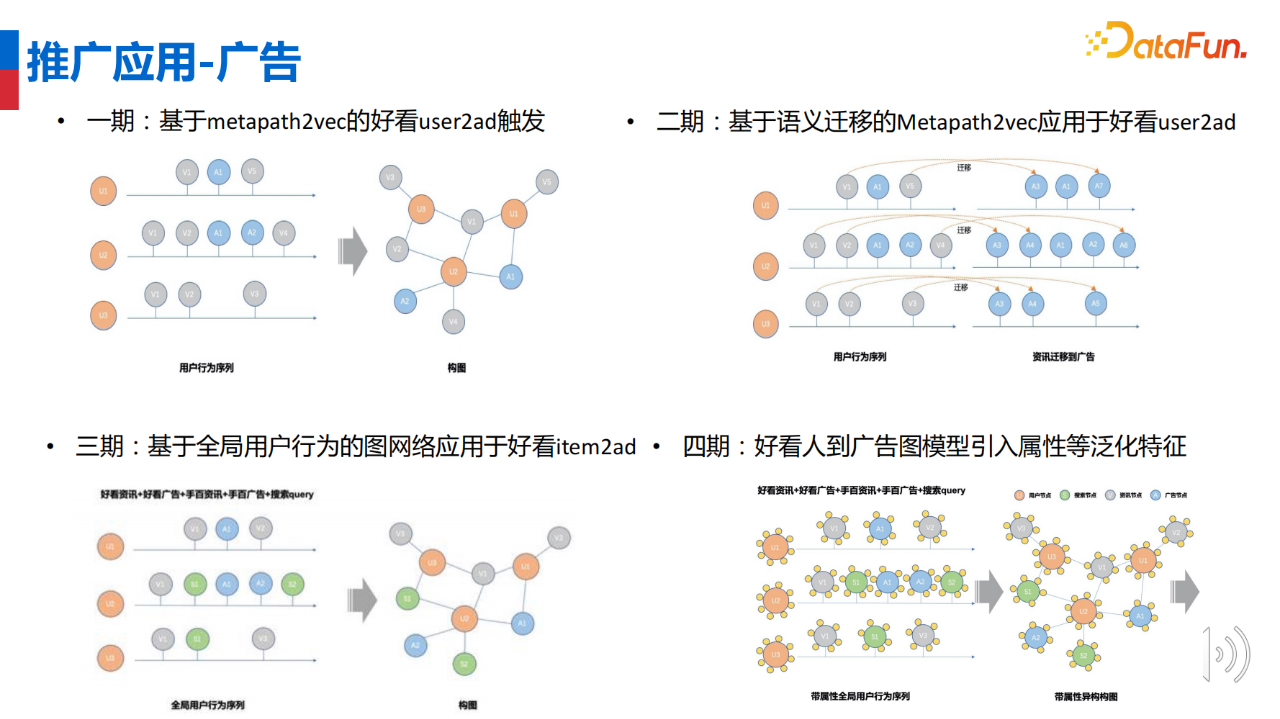
图模型推广至原生广告共经历四期阶段。
第一期使用“好看”用户的资讯与广告的点击数据构建异构图网络,通过高阶联通图结构隐式刻画用户和广告的关系,并使用 skip-gram 模式学习用户和广告的向量表达,最终使用 user 的向量直接召回广告。在现实世界中,用户对资源的点击数远远大于广告点击数,将导致网络中广告节点非常稀疏;同时网络中存在大量没有商业价值的资讯,对模型训练造成干扰。
第二期将用户点击资讯行为迁移到广告点击上,并丢弃无法迁移的资讯,使广告行为大为丰富,得到仅包含用户与广告的图网络,提升了训练样本的纯净度,使模型学习的 embedding 更精准,进而提升广告系统整体变现能力。
第三期将图网络应用于“好看”视频广告的召回上,即将用户侧行为直接用于召回广告。为进一步丰富用户行为、提升网络表达能力,将数据进一步扩充,在原有“好看”资讯与广告数据的基础上增加用户搜索行为数据、用户资讯点击数据、用户广告点击数据等。通过构建基于全局用户行为的图网络,进一步提升图模型对用户潜在兴趣和意图的提取能力。
第四期中为应对模型特征较单一、泛化性差,使得新用户和新广告无法生成向量表示的问题,在图模型中引入用户、广告、资讯的泛化式属性特征,使用图模型同步学习图节点的 id 和属性的 embedding 表示。聚合节点以上的属性表示,得到最终的向量表示。通过引入节点的属性特征,图模型的表达能力和泛化能力都得到进一步提升。
在贴吧应用场景中,除用户资源以外,贴吧节点类型同样重要。Metapath2vec方法在游走过程中可以比较好地消除节点类型的bias,所以为了更充分地利用节点类型信息,设计多种游走策略的metapath,包括:贴子-贴吧-贴子、用户-贴子-贴吧-贴子-用户等。通过离线测试,发现引入更多合理的metapath,可带来准确率和召回率的提升。


