平安银行智能化数据安全分类分级实践
导读:随着国家对数据安全的高度重视,以及相关法律法规的出台,数据安全领域工作得到了极大的提升。本文将分享平安银行运用智能化手段实现数据安全分类分级的背景、思路和方法。
01 数据安全智能分类分级平台建设背景
首先来介绍一下数据安全智能分类分级平台建设背景。

我国在 2021 年发布了《中华人民共和国数据安全法》和《中华人民共和国个人信息保护法》两大法律,将数据安全提升到了新的高度。随着监管机构发布银行保险机构的安全管理办法,以及人民银行发布《中国人民银行业务领域数据安全管理办法(征求意见稿)》,对银行业数据安全提出了非常高的要求。
在此背景下,平安银行注重数据分类分级,准确识别需要重点保护的高敏感数据,以满足监管要求并确保数据安全。接下来就将介绍平安在数据安全分类分级方面的建设思路和实现方法。
02 数据安全分类分级建设思路和实践

数据分类分级是平安银行开展数据安全工作的基础。要对数据进行安全保护,首先应该知道哪些数据是需要重点保护的,也就是哪些是重要数据、敏感数据。大众认知中的重要数据与监管标准中要求的敏感数据可能并不一致,除了姓名、手机、身份证号等,还有其它一些敏感数据需要重点保护。
平安银行在进行数据安全分类分级建设时,采取了三步走的策略:
第一步做标签:确定数据安全分类标准,即需要一个标准来识别数据的级别。同时,参考法律法规和行业标准进行数据识别和定级,梳理标签体系。此部分工作,先确定数据分类,即数据属于哪个业务类别,确定目录,然后再确定数据级别,根据泄露后造成的影响来确定级别,如密级、绝密级、国密级等不同的安全等级。
第二步打标签:探索智能化手段替代人工识别以降低成本。因为,平安银行的数据量是个天文数字,数据库有几百万张表、几千万个字段之多,所以,我们在识别不同级别的数据时,需要运用智能化的手段,利用工具平台代替人工来实现。
第三步用标签:根据打标签结果制定保护措施,例如对姓名进行脱敏掩码、对身份证号和手机号进行数据脱敏、加密存储等工作,并遵循相关标准进行数据保护。
下面详细介绍每一步中的重点内容。
1. 做标签– 数据安全标签体系
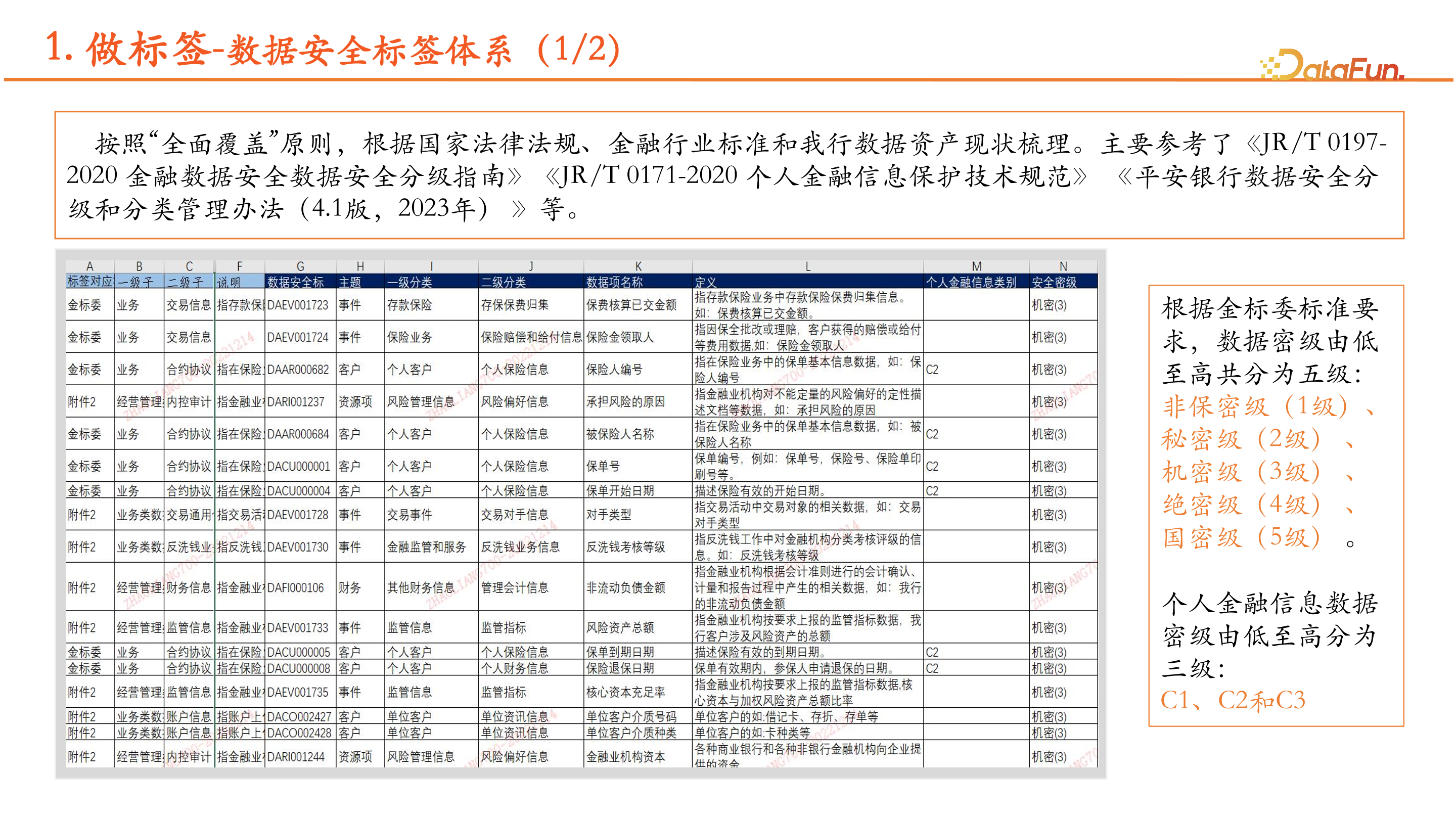
参考国家法律法规、金融行业标准和平安自身数据资产现状来建立数据安全标签体系。
根据金标委标准要求,数据密级分为五级,由低到高分别为:非保密级(1 级)、秘密级(2 级)、机密级(3 级)、绝密级(4 级)和国密级(5 级)。个人金融信息分为三级,由低到高分别为 C1、C2 和 C3。其中 C3 为虹膜、指纹、密码等用于个人身份鉴别的信息。C2 比如身份证号、银行卡号等。
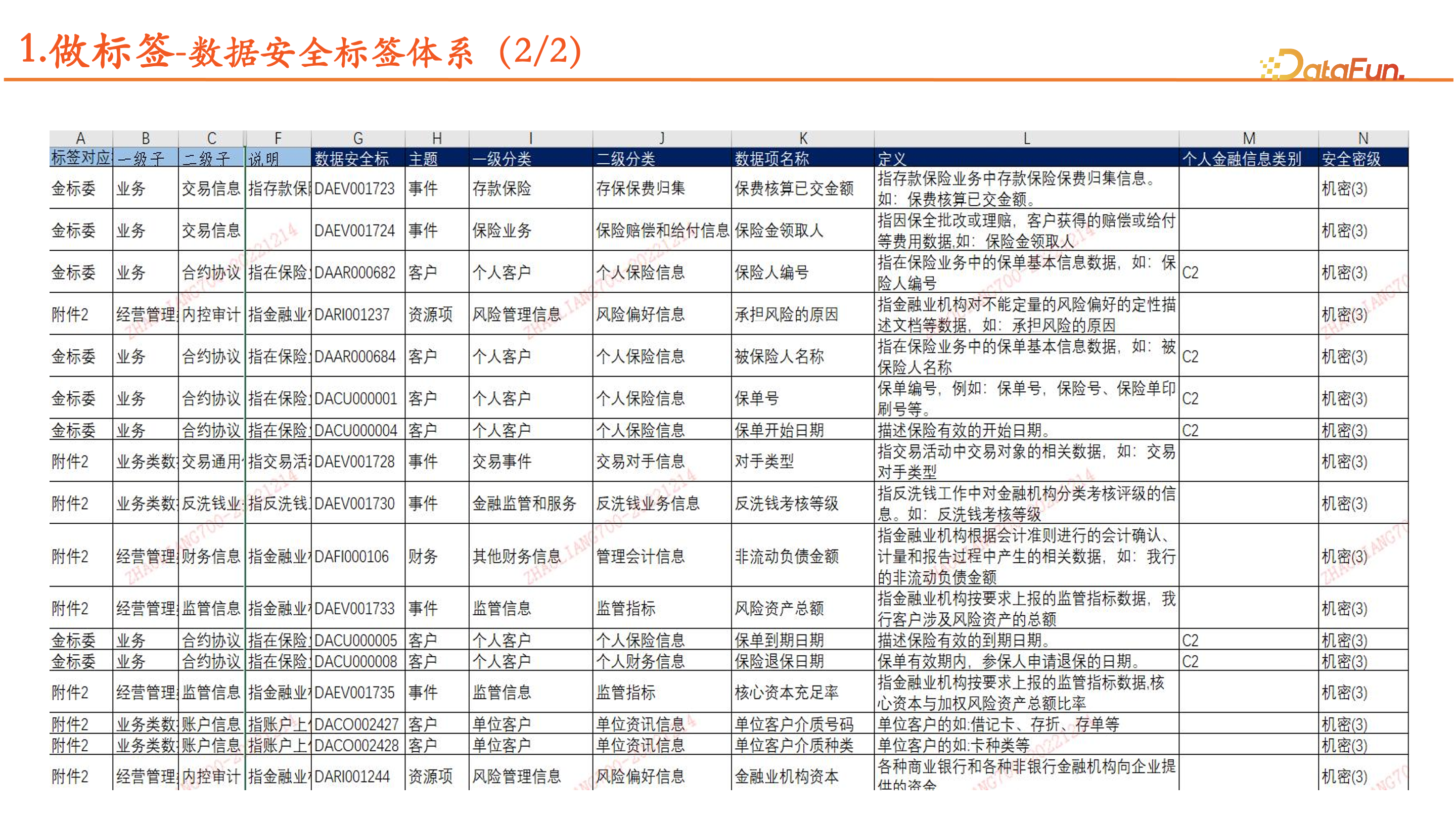
上图中展示了部分案例。平安还开展了数据安全保护措施的标准化工作,公司系统众多,需要统一标准,如姓名、手机号、身份证号等信息的掩码的统一性要求。
2. 打标签– 鹰眼智能打标平台 3.0

第二步——打标签。平安银行自研了鹰眼数据安全智能标签打标平台,已从 1.0 版本发展到目前的 3.0 版本,覆盖了越来越多的数据安全标签,准确率从 83% 到 91%,再到 95%,逐步提高。人工达标准确率常在 80%~90%,因此该平台可以完全代替人工工作。3.0 版本的智能打标平台具有以下功能和特点:
数据完善性:剔除冷冻表、备份表和临时表,对表进行区分和梳理,引入母子表概念来识别数据表之间的关系。
数据安全分类分级识别:对母表进行打标后,子表可以继承其数据安全分类分级的打标结果,从而降低工作量。
技术手段:采用了内容正则、元数据正则以及深度学习技术,包括循环神经网络进行训练,以提高准确率。
血缘继承:实现了上游表和下游表之间的血缘关系,使下游表可以直接继承上游表的打标结果,进一步降低工作量。
提升准确率:通过多轮训练优化调优,最终将准确率提升至 95%。
高效率:能够取代人工打标,实现自动化的数据安全分类分级识别,提高工作效率。

鹰眼智能打标平台的逻辑架构分为三个层次:
扫描层,主要包括三个引擎,分为正则引擎、AI 引擎和血缘引擎。其中,正则引擎主要是针对一些数据内容和元数据做了一些正则条件;不适合做正则扫描的情况,就根据 AI 模型进行智能打标;血缘引擎通过继承的方式识别每一张表的上下游表,并保持标签的一致性。
整合层是将三套的引擎的打标结果做统一,整合成全行统一的数据安全分类分级打标结果。
服务层提供多种形式的访问方式,如通过 API、查询/下载、离线等。利用打标结果,支撑数据生命周期的六大环节,即采集、传输、存储、使用、删除、销毁,提供统一的服务。
在扫描层下面数据主要来源有业务系统数据库、数据资产管理平台和大数据平台三部分。
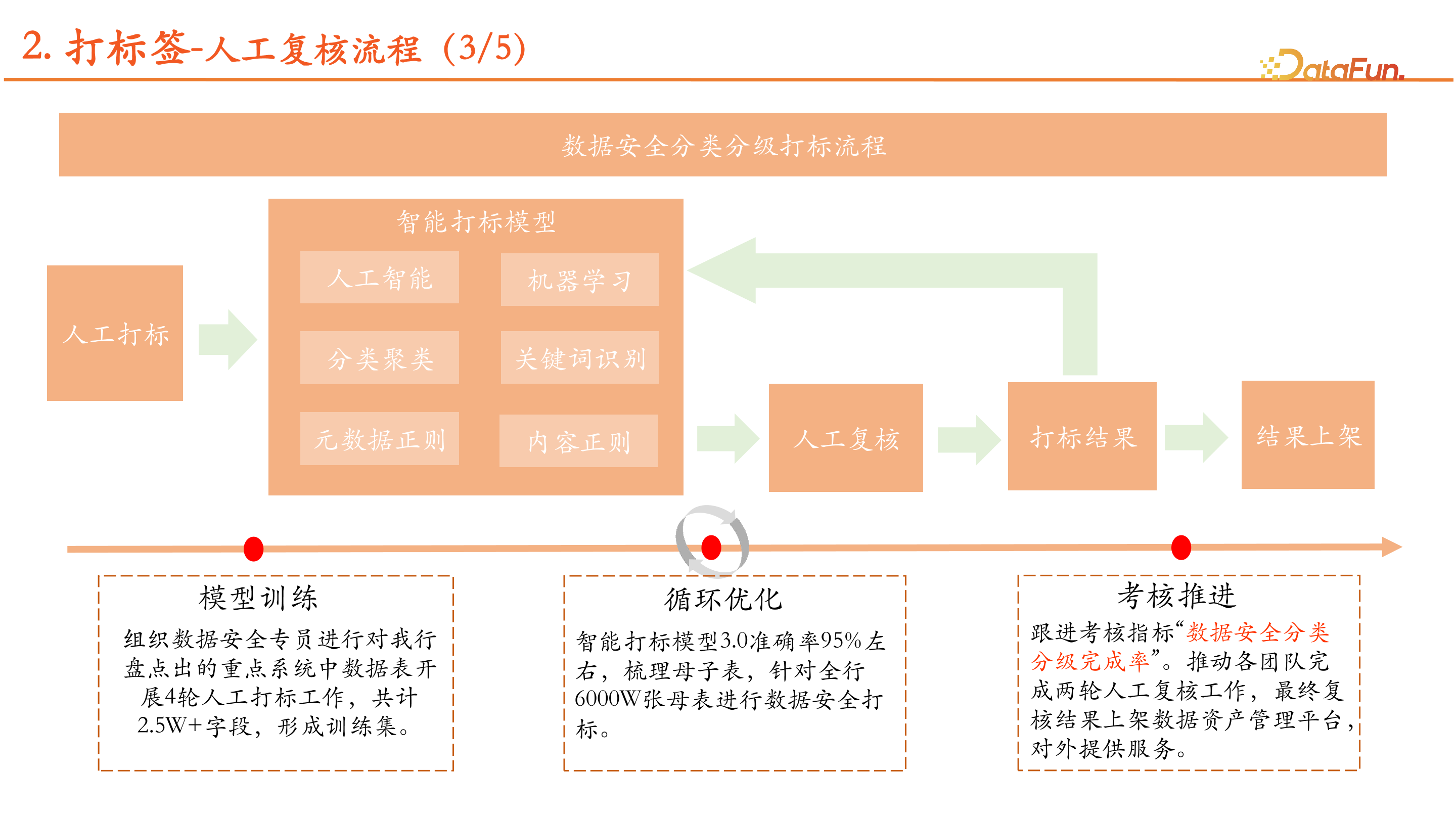
打标流程包括人工打标、智能打标模型训练和人工复核,形成最终打标结果。
首先,进行人工打标,向智能打标模型提供训练集,进行训练;然后,智能打标模型生成打标结果;最后,再进行人工复核,随着准确率提升到 95%,人工复核不再进行大批量、全部的复核,而是仅做小部分抽样的人工复核。最终,打标结果有两个方向,一个是结果直接上架提供给各个数据平台使用;另一方面,将人工复核发现的错误反馈给模型进行优化,实现循环优化。

智能打标结果放到数据安全管理平台进行人工复核,初稿复核通过后流转到业务人员进行复核。如果初稿未通过,结果直接结束,但错误结果会重新整理反馈给模型优化。复核确认后,结果可以上架使用。错误结果也会反馈给模型进行优化。

双向打标方案包括控增量和盘存量两个方面:
盘存量:对全量字段进行打标并上架到数据资产管理平台。
控增量:将智能打标能力嵌入银行内建模平台,实现数据标准的落地和建模结合。
数据安全打标能力直接放到建模平台,使得数据在设计阶段就能智能推荐和打标,伴随全生命周期流转。这样可以避免返工和保护措施不到位的问题,实现双向打标方案。
3. 用标签– 全行统一“数据安全打标签结果”服务提供
使用标签对银行敏感信息进行屏蔽基线保护,比如根据保护措施要求,对客户姓名只保留姓,其余掩盖,性别全部掩盖等等,并在智能打标平台识别出全行的敏感字段数量和位置,一旦查询或展示这些数据,保护措施就能直接落地。
当前数据资产管理平台共计上架了 300 多万个机密级以上的敏感字段,已对接的平台包括数据安全保护伞平台、数据模型设计平台、大数据查询平台、数据权限审批平台、行内测试-生产数据交换平台及行内数据作业调度平台等,这些平台可以实时调用数据安全分类分级的打标结果。

