PART 01 数据质量两个典型场景
1.1
数据传输结果校验
业务系统数据一般需要经过数据传输/同步进入到大数据平台开展后续的加工。数据经过传输后是否和源表数据一致?中间有没有丢失?一般发生这种情况,首先要比对业务系统和大数据平台两个表的数据。在这个场景下,手工的处理成本非常高:需要两边按同样的逻辑计算,人工进行比对。
1.2
业务系统重构
严选的供应链采购系统是比较老的业务系统,随着业务量的增长和业务逻辑的演进,原有的产品功能和系统架构越来越吃力:高峰的时候,业务方一天反馈的问题十个以上,产研投入一个产品+两个开发在问题排查和反馈上,新需求基本做不到及时响应。在这种情况下,产研不得已启动了采购系统的重构。重构分5块工作展开:业务梳理、架构设计、QA、数据迁移和外部依赖联动。其中数据迁移将直接影响数据仓库的数据:业务系统重构会涉及到历史数据的处理&增量数据的映射,数据仓库不会保留两套处理逻辑。

PART 02 两套处理方案
2.1
人工处理方案
针对第一章节中提到的场景二:业务系统重构非常常见,在没有产品加持的情况下,纯投人处理成本非常高。主要工作如下:
业务梳理:数据文档的丰富程度,极大影响业务梳理的难易程度。如果数据是随着业务系统一点一滴的建设起来的,文档基本没有,那基本是从头再来;
数据依赖梳理:识别数据依赖的业务源库源表,为切源和后续数据验证做准备;
源端数据质量保障:源端数据质量的保障至关重要。源端数据的准确性、完整性和及时性直接影响后续数据加工链路的数据质量,从而影响数据处理和分析的可靠性和准确性;
结果数据质量保障:这是此种场景下数据工作的重头戏,通过以下几个手段来验证:
整体比对:全表数据量、分段数据量、采购金额、采购单数量、主键唯一性、枚举值数量等定制化校验
全文比对:整体比对通过后,针对核心字段做全文比对
重点来了:在没有产品支持的情况下,以上所有比对都需要手工定制SQL来完成校验!如果再叠加上数据重构,工作量翻了好几倍。
贴一张图给大家评估下硬写SQL比对的工作量:

2.2
产品处理方案
数据质量中心有相对应的产品功能:数据比对,支持Hive和Hive,以及Hive和其他数据源之间的数据全文比对。可以非常完美的解决类似的问题。

PART 03 数据比对功能实践
第一步:新建数据比对任务
选择源表和比对表,当前任务选择了数据源和比对数据源都为Hive的不同库之间的全文比对。产品会自动识别是否分区表,针对分区表默认勾选分区,也可以执行全表比对。
产品支持对数据权限做鉴权:没有当前表读权限的会给出提醒,但是任务还是可以保存的,只是不能执行。

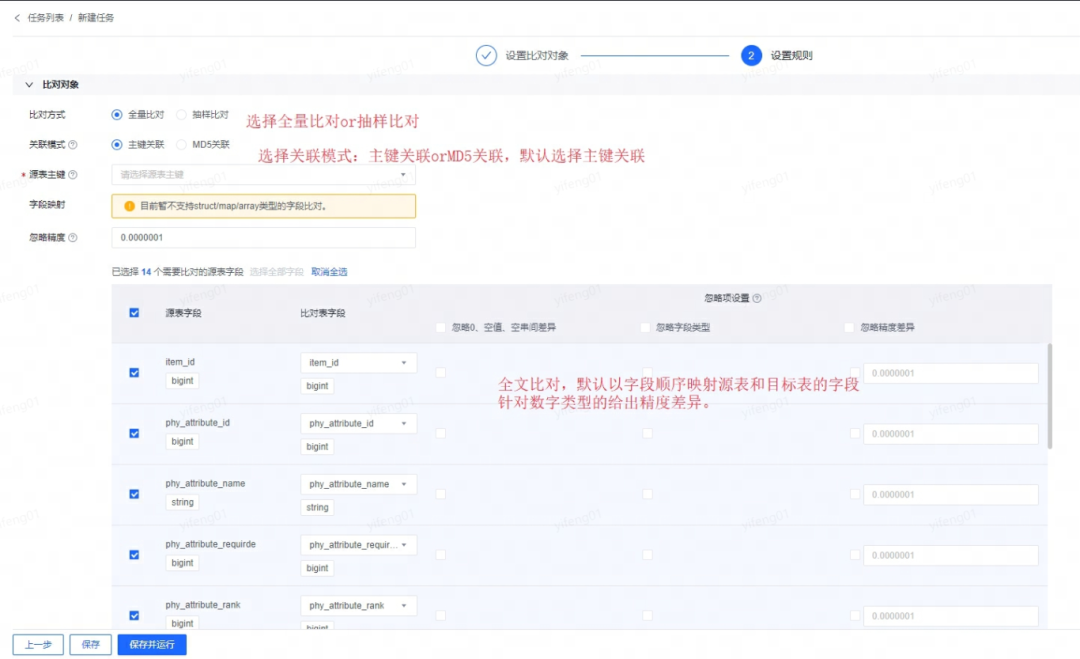
第二步:设定比对方式和关联模式,以及字段映射关系
比对方式:全量比对or抽样比对,抽样比对支持设定抽样比例
关联模式:支持主键关联和MD5关联
第三步:调度策略
此处需要选择全文比对结果暂存库,可以选择保存并立即执行,也可以保存后在列表页面选择执行。当前产品功能只支持手工触发执行,正在规划调度执行功能,未来全文比对可以在数据传输任务后自动执行,也可以配置调度定期执行。

第四步:执行
新建数据比对任务后可以选择立即执行,也可以直接保存后在列表内执行。列表内执行会做鉴权操作:只可以操作自己是owner的全文比对任务。

第五步:查看结果
查看结果在执行实例的列表内,针对执行成功的实例,高亮查看结果操作。可以看到本次执行的结果,包含表级和字段级的结果两类。

PART 04 质量中心介绍
4.1
数据比对总结
通过产品功能极大的释放了数据开发工程师的工作。再回顾一下文章开头的采购系统重构场景。
业务梳理:数据文档的丰富程度,极大影响业务梳理的难易程度。如果数据是随着业务系统一点一滴的建设起来的,文档基本没有,那基本是从头再来;
数据依赖梳理:识别数据依赖的业务源库源表,为切源和后续数据验证做准备;
源端数据质量保障:源端数据质量的保障至关重要。源端数据的准确性、完整性和及时性直接影响后续数据加工链路的数据质量,从而影响数据处理和分析的可靠性和准确性;
结果数据质量保障:这是此种场景下数据工作的重头戏,通过以下几个手段来保障
其中的3和4:源端和结果数据质量保障可以通过数据比对完美解决!
4.2
质量中心介绍
数据比对&形态探查是质量中心的2个很重要的功能,目前可以较好的解决数据质量的两类问题。用户在使用的过程中对产品提出了更高的要求:不只是比对Hive和其他数据源之间的数据,还要比对MySQL和MySQL的数据,还要能够支持调度,数据传输任务可以唤起数据比对等等。这些都需要在后面产品迭代中逐渐丰富。