百度集合通信库BCCL万卡集群快速定位故障
1 集合通信对分布式训练至关重要
在分布式训练中,每一块 GPU 只负责处理部分模型或者数据。集群中不同 GPU 之间通过集合通信的方式,完成梯度同步和参数更新等操作,使得所有 GPU 能够作为一个整体加速模型训练。
如果有一块 GPU 在集合通信中出了状况,将会导致其他 GPU 处于等待状态,直到这块 GPU 完成数据同步,集群中所有 GPU 才会开始后续工作。
所以,集合通信性能直接影响了分布式任务的速度,决定了集群中所有 GPU 能否形成合力加速模型训练。
为了最大提升集合通信的性能,在基础设施层面,集群通常采用基于 RDMA 的高性能物理网络,在任务运行时使用集合通信库进行加速。
2 大模型对系统的运维能力和稳定性提出新要求
我们知道,大模型的训练任务时长以周或月为周期,集群规模在千卡甚至万卡以上规模。这导致在整个任务过程中会发生各种故障,导致资源利用率不高或者任务中断。这使得大模型的训练任务,不能只看重集群规模和性能,更需要关注系统的运维能力和稳定性。
如果系统的运维能力和稳定性不够好,将会降低集群的「有效训练时长」,延长项目时间产生昂贵的时间成本。比如完成整个训练任务花了 30 天,结果有 10 天是在排除各类故障,这是不可接受的。
在分布式训练任务中,作为系统核心组件之一的集合通信库,同样需要面向大模型场景,在系统的运维能力和稳定性上进行优化。
3 百度集合通信库 BCCL 概述
百度集合通信库 BCCL(Baidu Collective Communication Library)是百度智能云推出的一款面向大模型训练场景优化的集合通信库,是百度百舸 3.0 中的重要组件。
BCCL 基于开源的 NCCL 进行了功能扩展和能力增强,针对大模型训练场景在可观测性、故障诊断、稳定性等方面进行优化,进一步提升集合通信库的可运维能力。同时,BCCL 针对百度智能云的特定 GPU 芯片进行了集合通信性能优化,进一步提升资源利用率。相比 NCCL,BCCL 的关键特性如下:
可观测性:新增集合通信带宽实时统计能力;
故障诊断:新增集合通信 hang 时的故障诊断能力;
稳定性:增强网络稳定性和故障容错能力;
性能优化:提升大模型训练主流 GPU 芯片的集合通信性能。
接下来,我们将介绍 BCCL 在以上 4 个方面的能力。
4 可观测性:集合通信带宽实时统计
4.1 背景
在训练过程中,有时候会出现任务正常运行,但是集群的端到端性能下降的情况。出现这类问题,可能是集群中任一组件导致的。这时候就需要运维工程师对集群进行全面的检查。
4.2 问题
其中,存储系统、RDMA 网络、GPU 卡等通常都配有实时可观测性平台,可以在不中断任务运行的情况下判断是否存在异常。相比之下,针对集合通信性能的判断,则缺乏实时和直接的手段。目前,若怀疑集合通信存在性能问题,只能使用如下 2 种手段:
使用 RDMA 流量监控平台进行故障排查。这种方法仅能间接推测出跨机集合通信性能是否有异常。
停止训练任务释放 GPU 资源,使用 nccl-test 进行二分查找,最终锁定出现故障的设备。
虽然第 2 种方法可以完成集合通信异常的诊断,但是测试场景比较有限,只能判断是否有常规的硬件异常问题。同时整个过程中会导致训练中断,产生昂贵的时间成本。
4.3 特性和效果
BCCL 的实时集合通信带宽统计功能,可以在训练过程中对集合通信性能进行实时观测,准确地展示集合通信在不同阶段的性能表现,为故障诊断排除、训练性能调优等提供数据支撑。即使在复杂通信模式下,BCCL 通过精确的打点技术依然能提供准确的带宽统计的能力。
在集合通信性能异常的故障排除方面,可以进一步根据不同通信组的性能缩小故障范围。在混合并行模式下,可以通过多个性能异常的通信组的交集进一步确认故障节点。
在训练性能优化方面,可以评估该带宽是否打满硬件上限,是否有其他的优化策略,为模型调优提供更多的监控数据支撑。
5 故障诊断:集合通信故障诊断
5.1 背景
设备故障导致的训练任务异常停止,也是大模型训练任务时常发生的状况。故障发生后,一般都会有报错日志或者巡检异常告警,比如可以发现某个 GPU 存在异常。在训练任务异常时,我们只需要匹配异常时间点是否有相关异常事件或告警,即可确认故障 root cause。
除此之外,还存在着一类不告警的「静默故障」。当发生故障时,整个训练任务 hang 住,无法继续训练,但是进程不会异常退出,也无法确认是哪个 GPU 或哪个故障节点导致训练任务 hang。然而,此类问题的排查难点在于,该类故障不会立刻发生,训练任务可以正常启动并正常训练,但是在训练超过一定时间后(可能是几个小时或者数天)突然 hang 住。排查时很难稳定复现该故障,导致排查难度进一步提高。
5.2 问题
由于集合通信的同步性,当某个 GPU 出现故障时,其他 GPU 仍会认为自己处于正常地等待状态。因此,当通信过程中断时,没有 GPU 会输出异常日志,使得我们很难迅速定位到具体的故障 GPU。当上层应用程序在某一多 GPU 的集合通信操作中 hang 时,应用程序也只能感知到某个集合通信组(故障 comm)出现了问题,却无法精确地判断是哪个 GPU 导致了此次集合通信的异常。
运维工程师通常使用 nccl-test 来尝试复现和定位问题,但是由于压测时间短、测试场景简单,很难复现集合通信 hang。
在百度集团内部排查此类问题时,首先停止线上的训练任务,然后进行长时间的压测,比如对于现有训练任务模型进行切分,对集群机器进行分批次压测,不断缩小故障范围,从而确认故障机。排查代价通常需要 2 天甚至更多。这类故障排查的时间,将带来巨大的集群停机成本。
5.3 特性和效果
为了应对这一挑战,在训练任务正常运行时,BCCL 实时记录集合通信内部的通信状态。当任务 hang 时,BCCL 会输出各个 rank 的集合通信状态。运维工程师可以根据这些数据特征来进一步缩小故障 GPU 的范围。通过这种方法,BCCL 通过一种近乎无损的方式实现了故障机的快速定位,大幅度提高了问题排查的效率。
6 稳定性:网络稳定性和容错增强
6.1 背景
在模型训练过程中,单个网络端口偶发性的 updown 会导致当前进程异常,进而引起整个训练任务退出。然而,单端口的偶发性 updown 在物理网络是不可避免的。
6.2 特性和效果
BCCL 针对此类偶发性的异常场景,进行了故障容错以避免任务退出,提升训练任务的稳定性。
控制面容错能力提升:在训练任务启动时,通常会由于偶发性的网络故障或其他故障导致训练任务启动失败。BCCL 针对常见的偶发性异常故障增加相应的重试机制,确保训练任务正常启动。
数据面容错能力提升:在训练任务正常运行时,偶发性的网络抖动可能导致 RDMA 重传超次,从而导致整个训练任务异常。BCCL 优化了 RDMA 重传超次机制,提升训练任务的健壮性。
7 性能优化:集合通信性能优化
针对大模型训练场景的主流 GPU 芯片,集合通信性能还存在继续提升的空间,进一步对任务进行加速。
BCCL 针对百度智能云提供的主流的 GPU 芯片进行了深度优化。以双机 H800 测试环境为例,BCCL 相比 NCCL 带宽利用率可提升 10%。
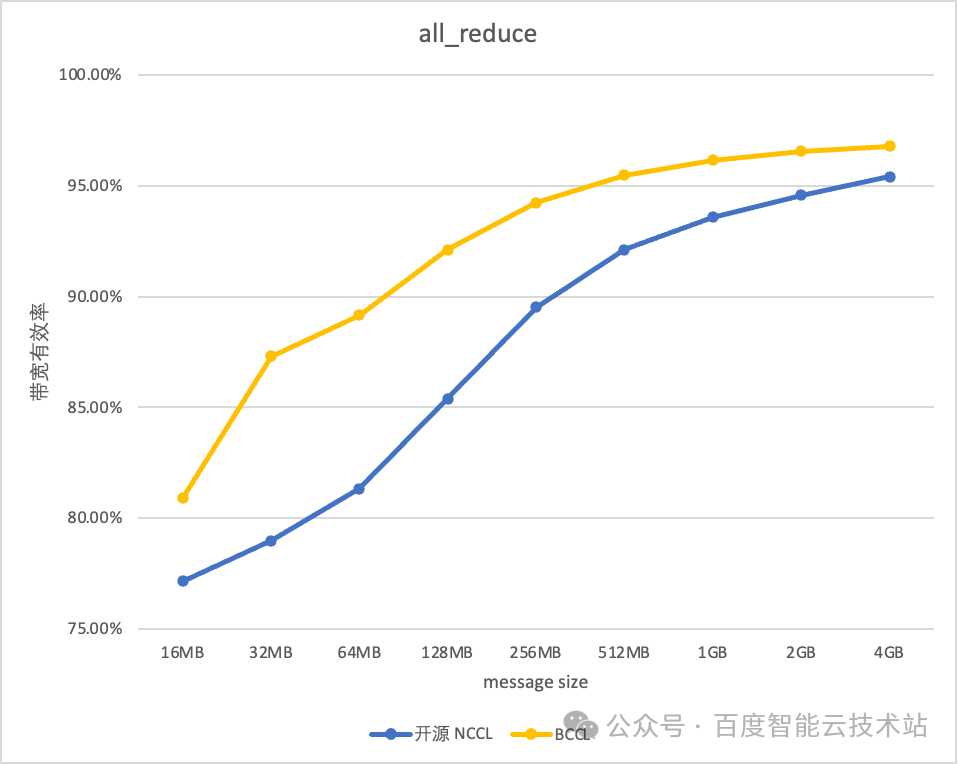
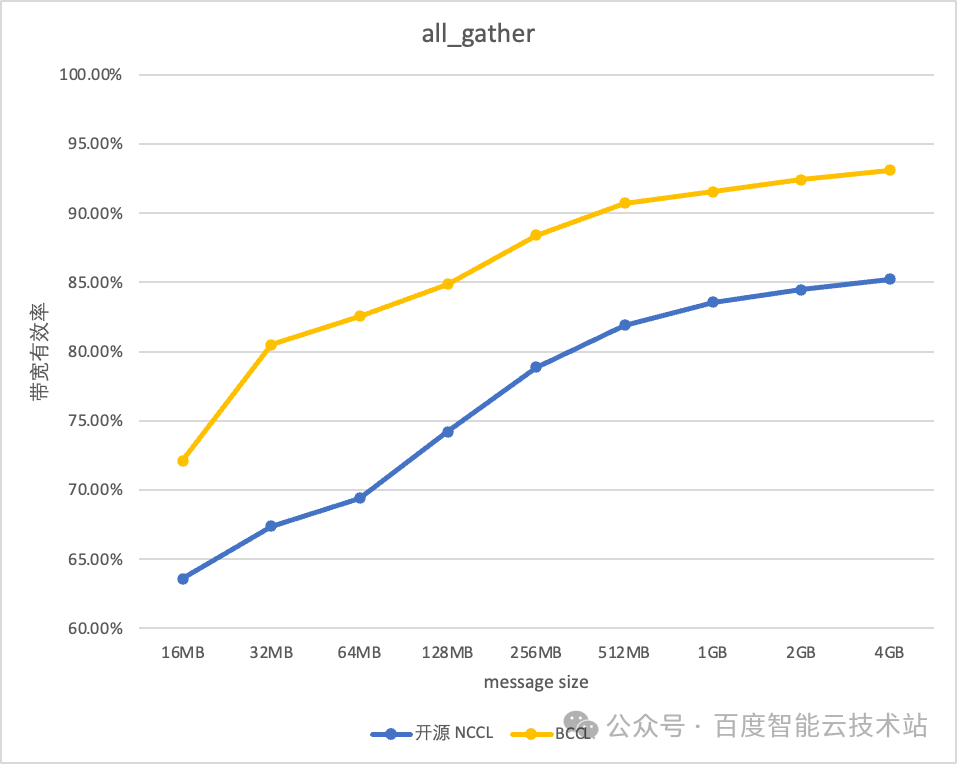
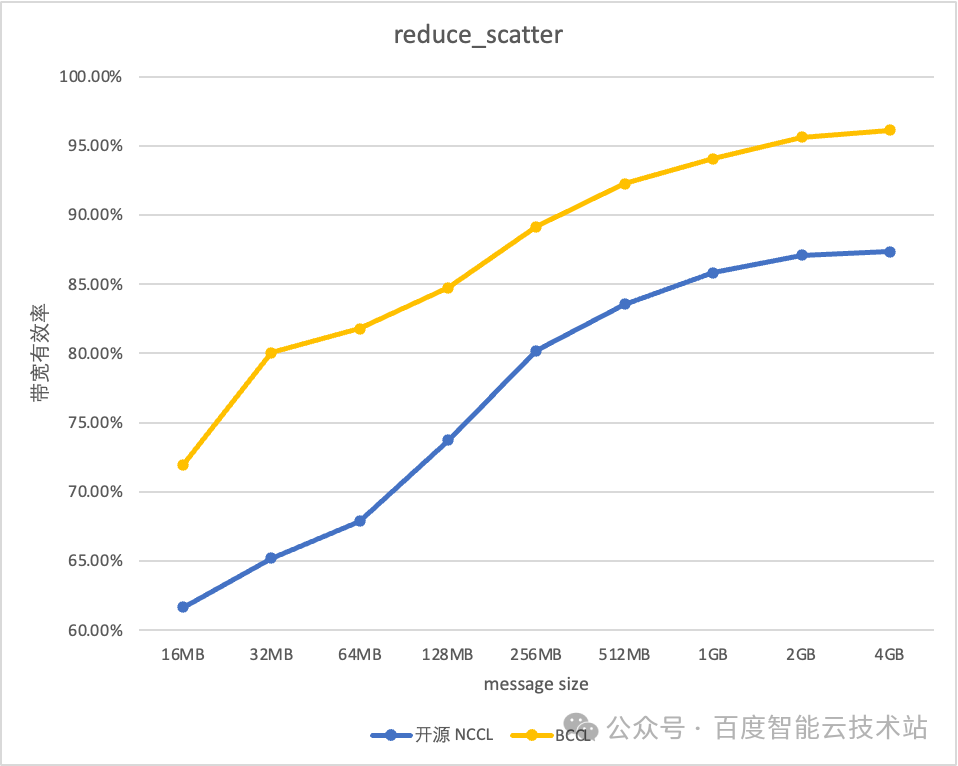
8 总结
2023 年 12 月 20 日,百度百舸·AI 异构计算平台 3.0 发布,它是专为大模型优化的智能基础设施。
借助 BCCL 在运维能力和稳定性进行的优化,使得百度百舸平台的有效训练时长达到 98%,带宽的有效利用率可以达到 95%。

