新一代数据架构的性能与成本平衡之道
Alluxio 大致可分为两个部分:Alluxio Service 和 Alluxio Local Cache。Alluxio Local Cache 为计算存储分离的计算环节实现了数据本地化,通过这种方式来加速查询,同时减少对 underline 的 FS 的 request 和对应的数据的出口,从而提高性能并节省成本。
NewsBreak 是美国的一家新闻资讯企业。文章将通过该公司案例,介绍Alluxio Local Cache for Presto 的应用。
01 NewsBreak 的架构
首先来介绍一下 NewsBreak 的整体架构。
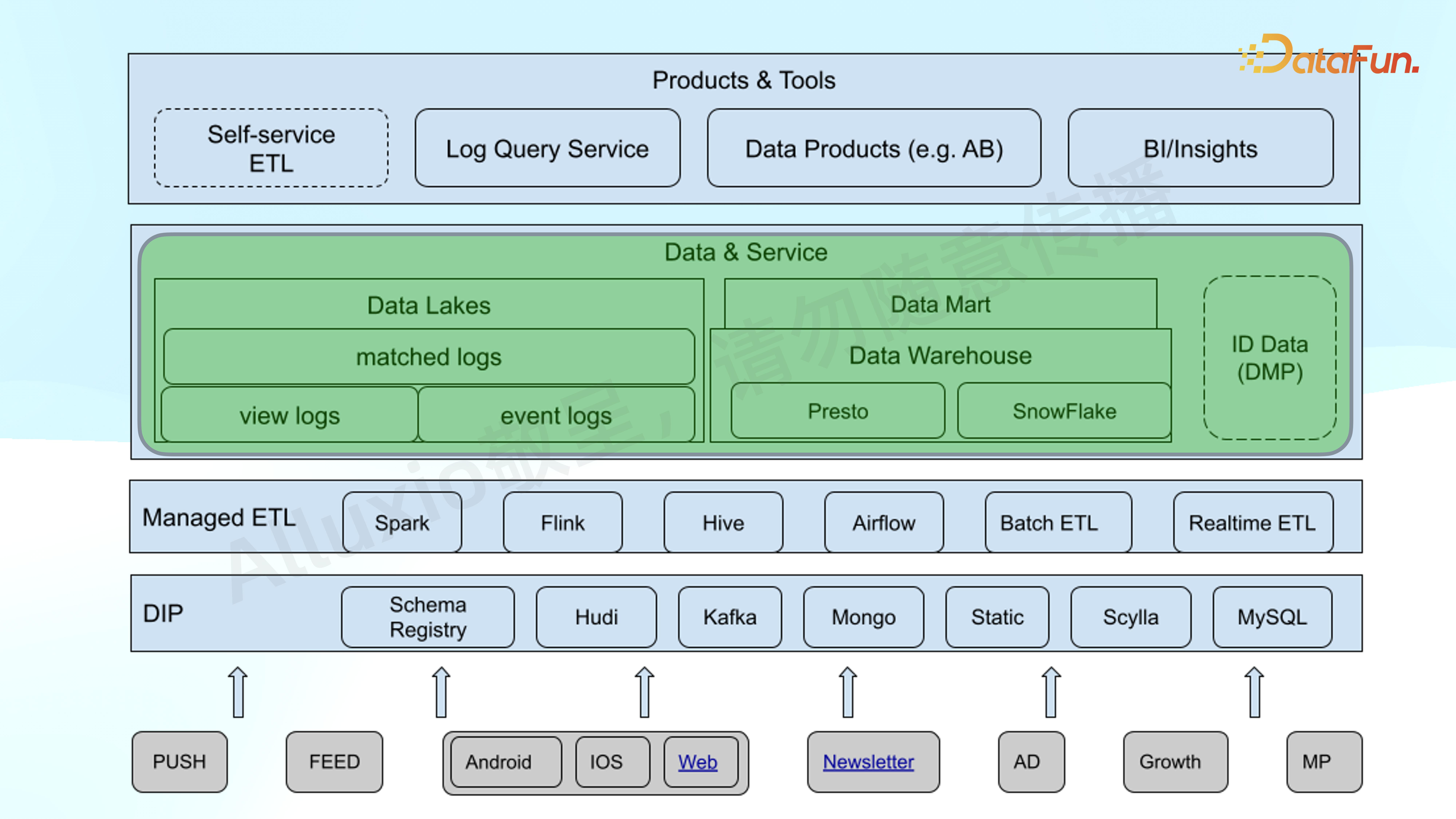
从下往上看,有很多不同的数据源,通过 DIP(Data Engine Pipeline) 的 model 做到数据入湖和入仓。引入了 Schema Registry 来管理大部分的 schema,还有 Hudi 这种流行的 open table format,以及其它如 Mongo、Scylla、MySQL 等不同的 transactional Database。通过 Managed ETL 层,经过 Airflow,load 到 Data & Service。Data & Service 分两大块:偏 raw data 的数据湖和偏 ETL 的数仓。Query engine 是建构在 Presto 之上的,提供 ad-hoc 查询和 BI 分析。同时,对敏感数据,利用 SnowFlake 做更精细化的管理,尤其是对 PRI 的信息。
在此之上构建了不同的数据产品,如内部的 Self-service ETL,偏向产品、工程、数分的 Log Query Service,帮助用户获得公司的原始数据以进行各种分析,还有面向运营或者 CXO 的不同的 data products 和 BI 工具,例如 AB 系统等。
02 Presto at NewBreak
今天主要介绍的是 Data & Service 部分。在不同的 log 之上,通过 Presto 来做计算、存储和查询。我们的数据比较杂也比较多,所以方案需要能够加速 query 的整体性能,同时减少 S3 的 cost。
S3 存储的 cost 跟 query 没有太大关系,最大部分的查询 cost 是按照 request 的请求和数据的出口收费。
1. Presto 在 NewsBreak 的使用方式和架构
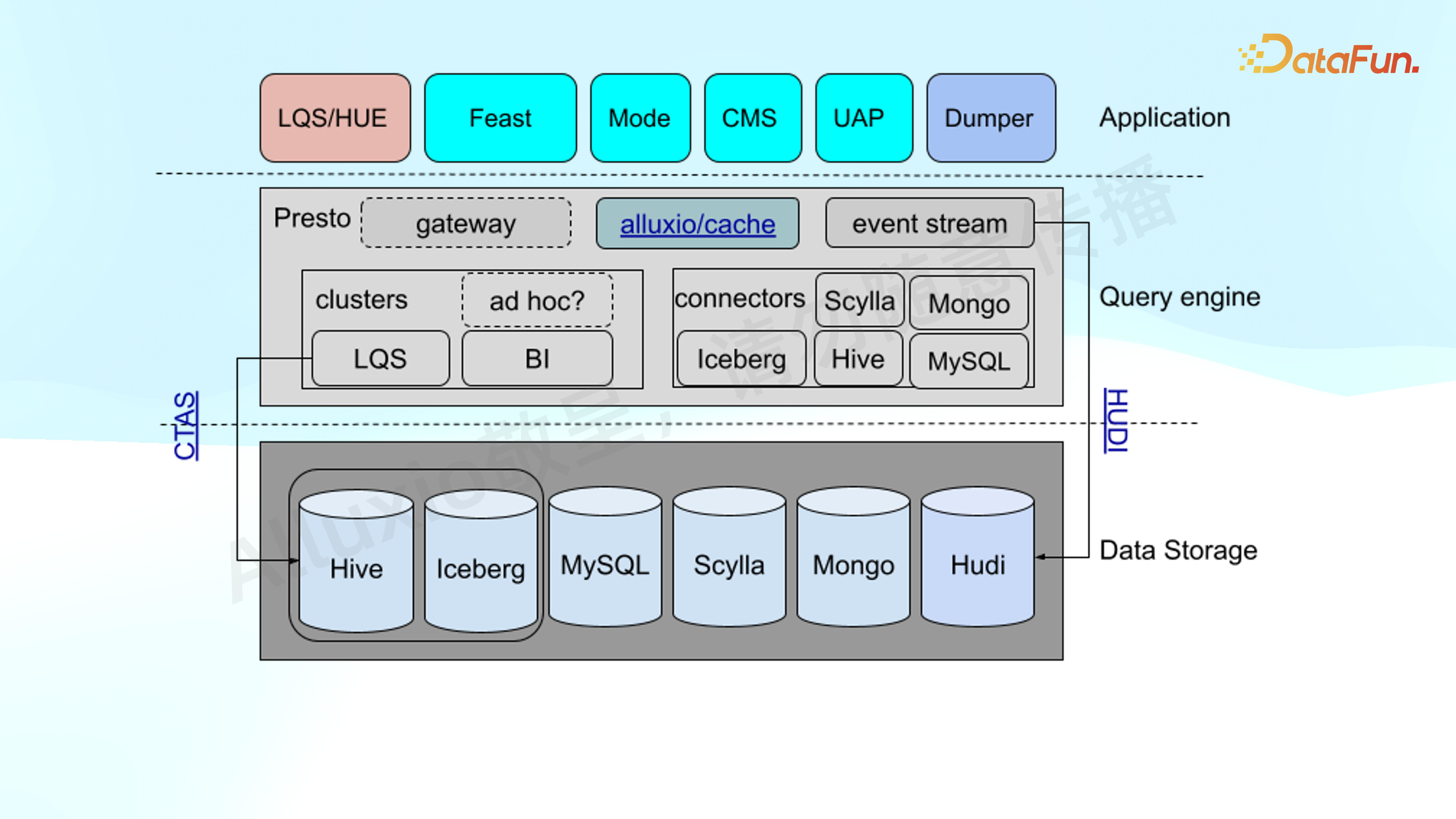
Presto 是典型的计算存储分离,我们使用了其很多功能,比如不同的 connecter,利用联邦查询,连接 Scylla、Mongo、Iceberg、Hive、MySQL、Hudi 等。底下的存储,包括以 S3 为主的 Hive、Iceberg,还有比较偏 OLTP 的 MySQL、Scylla。
上面是一些比较常见的产品,如 Feast 支持 feature store,还有自建的 CMS以及 Mode 等第三方 SaaS 系统。
通过 Presto 的 CTAS 对数分或者偏内部的开发,对数据回流处理,再导入数据库。
另外,引入了 Presto 的一个插件 event stream。它是一个 listener,将所有的 SQL 结果、运行状态等发给 Kafka stream,通过 Hudi 落回到存储。
底部存储以 S3 加上一些 OLTP 的方式为主。
我们期望在整个数据生命周期内得到性能加速,数据无论是通过 CTS 产生,还是通过传统 ETL 产生,能够自动支持 Cache。
2. Cache Considerations
这里列出了 Cache 相关的主要考虑点:

首先,需要支持 Presto On S3。Alluxio Local Cache 很早就有,在Facebook 和 Uber 都有实践,但支持的是 Presto on HDFS,On S3 是在今年 3 月份刚刚发布的 2.2.9.3 版本中才支持。
第二,希望能最小化对现有系统的影响。
第三,提速 query,同时通过减少 S3 request 来减少 S3 的 cost。
第四,由于康威定律,我们的架构比较复杂,因此希望支持 multiple 的 Hive metastores。
第五,cache 的 storage 是非常小的,只有整体的 1% 左右,所以希望支持 cache filter,来指定哪些表或哪些形式的内容需要被 cache,从而提高整体的命中率。
第六,支持 Hudi,或有版本的文件。
最后,希望有详细的 monitor 可以监控和衡量整个系统的效果。
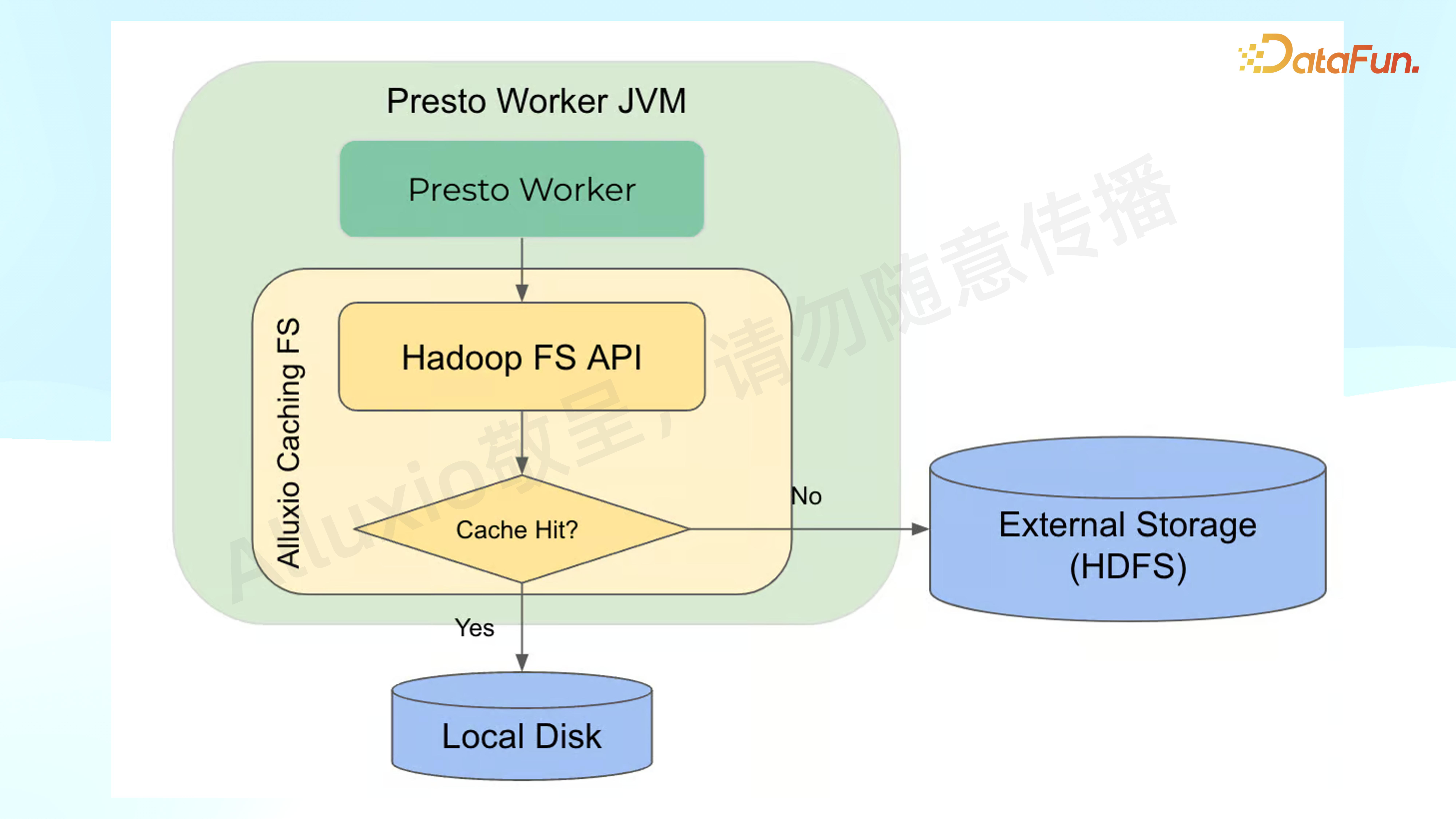
经过评估,我们借鉴了 Uber 去年的类似实验。在 Uber 的架构中,Alluxio 部分整体向外提供了一个 HDFS 的 API,在访问远程文件的时候会判断是否有 cache 能被 hit,如果有,就直接走 local disk,如果没有就到外部找 external storage。
这样做的优点在于其强一致性,如果 local disk 没有到远程去找,或者远程的文件已经被修改,被改的信息会传递到整个系统当中,会认为这个文件是不命中的。
在此之上我们做了几点简单的改动:
首先,支持了 S3。这是通过修改 Presto 0.275,再结合最新的 release 0.292 的 Alluxio code 实现的。
第二,将 cache filter 从 global 的粒度降低到 catalog level,因为是由于公司架构原因导致的,因此要支持 multiple catalog。
第三,在最下面为整个 Alluxio Cluster 配置了一个 shadow cache 来衡量整体的性能效果。
03 ALC4PS3 at NewsBreak
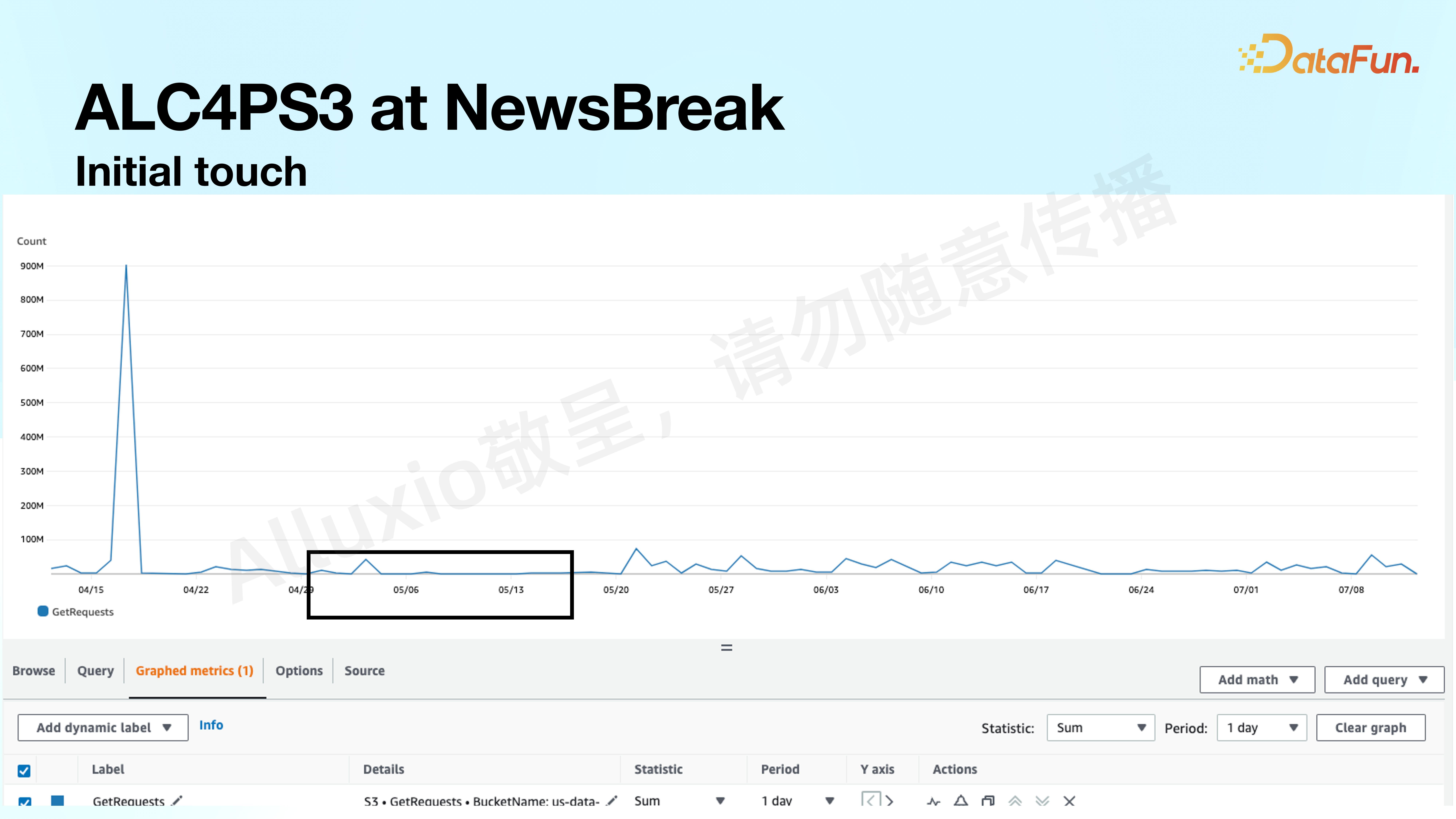
我们用实体数据进行了测试。上图展示了 S3 的 prefix 效果:
可以看到,在某一天有一个非常大的 burst,从平时不到几十 million request,burst 到 900 million request。通过 SQL 方式访问数据容易产生重复的访问数据,也就带来了更多的 cost,我们希望尽量避免这种情况。
通过与 Alluxio 的集成可以基本上把数据量控制在每天 10 million 以下。因此得出 Alluxio 符合我们的场景需求,一方面可以降低整体的平均 access 的 request,同时还可以砍掉异常的峰值。
1. Cache filters

接下来的问题是,如何从选中的几个 bucket 或几个 prefix,scale 到整个公司的十几个 PB 的数据量之上。这里就用到了 cache filter 机制。
Uber 提供了比较复杂的机制,可以根据 database、namespace 上的 table partition 来进行配置。但这不适用于我们的场景,因为我们是数据湖+数仓的复杂模型,用户有比较多的 ad-hoc 需求,因此我们需要更通用的方法。
最终选择了最原始的、对 cache 最基本的需求,采用了 mtime 这种 genernal 的方式来做处理,通过 monitor 的方式来看最终的效果。整体机制为,对当前的时间给一个 lookback window,通过 window 的数据才放到 cache 上。
Alluxio Local Cache 提供了 cache filter 的 overwrite 的机制。这里简单定义一个 Latest21DayCacheFilter,可以得到每一个文件的 modified time,跟 window time 做对比。
另外,我们发现小文件比较多,而小文件会浪费 local cache 的 disk,所以增加了进一步的过滤机制,文件大小要大于 patch size,默认 patch size 是 2MB。
2. Multi HMS
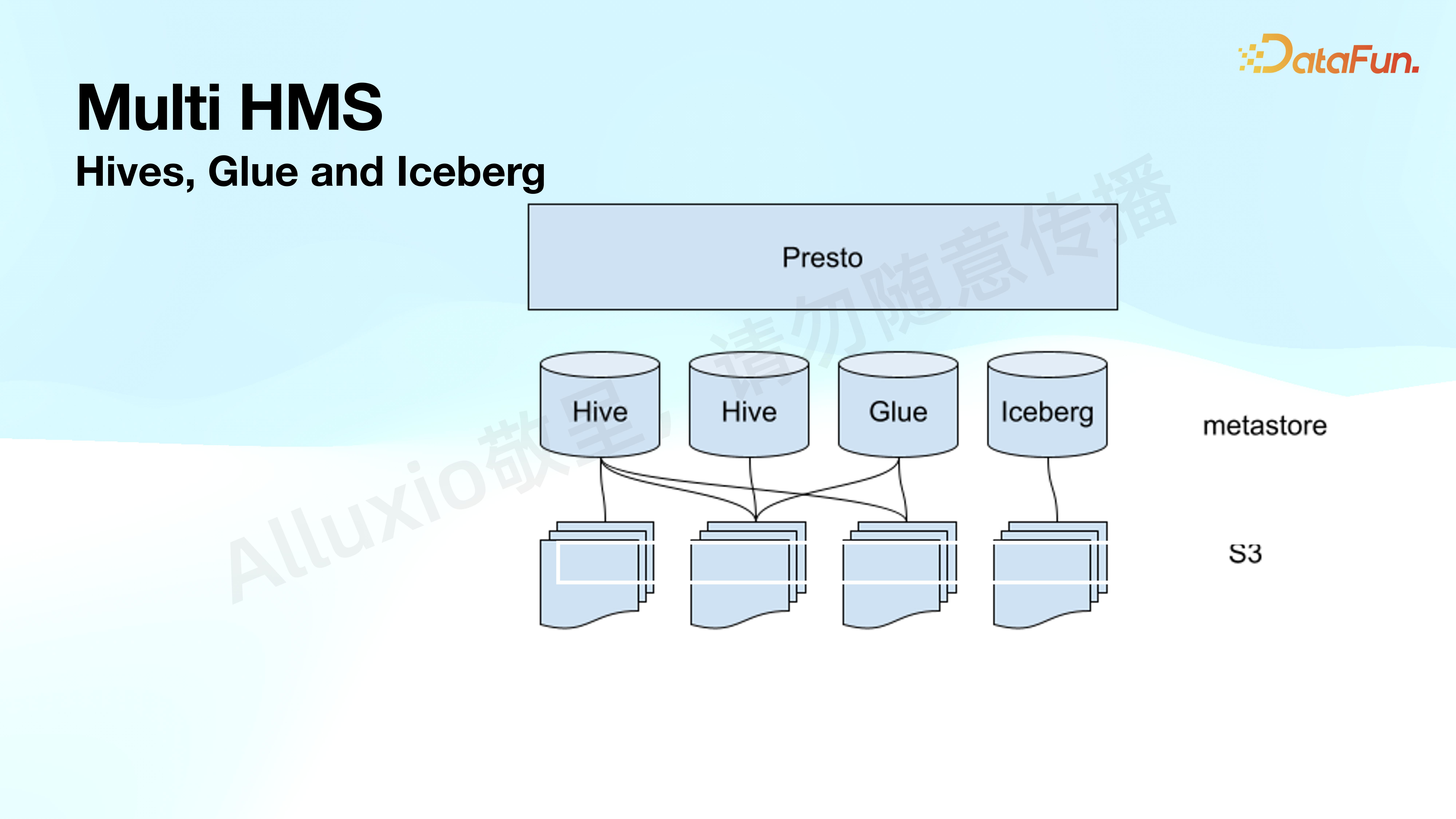
第二个场景是支持 Multiple Hive Meta Store。由于公司组织架构复杂,业务繁多,造成了比较多的 Hive metastore,包括 Glue、Iceberg 等,各业务线处理自己的数据时需要跨 catalog 做 Spark 或 Flink 的处理,需要把元数据重新在 remote 注册一遍。
Alluxio 假设自己是 Singleton,在初始化 manager、monitor 的时候是 singleton 的,但在 filter 级别支持 per catalog 的配置,所以利用这一特性,在每个 catalog 上面都设置一模一样的配置,除了 cache filter 之外。这样做的好处是,由于文件是共享的,因此只要在任何 catalog 被 cache 后,其它查询也会得到相似的数据。
04 Presto event stream
1. Query level monitor
以上介绍了整体的机制。接下来看是如何对效果进行评估。
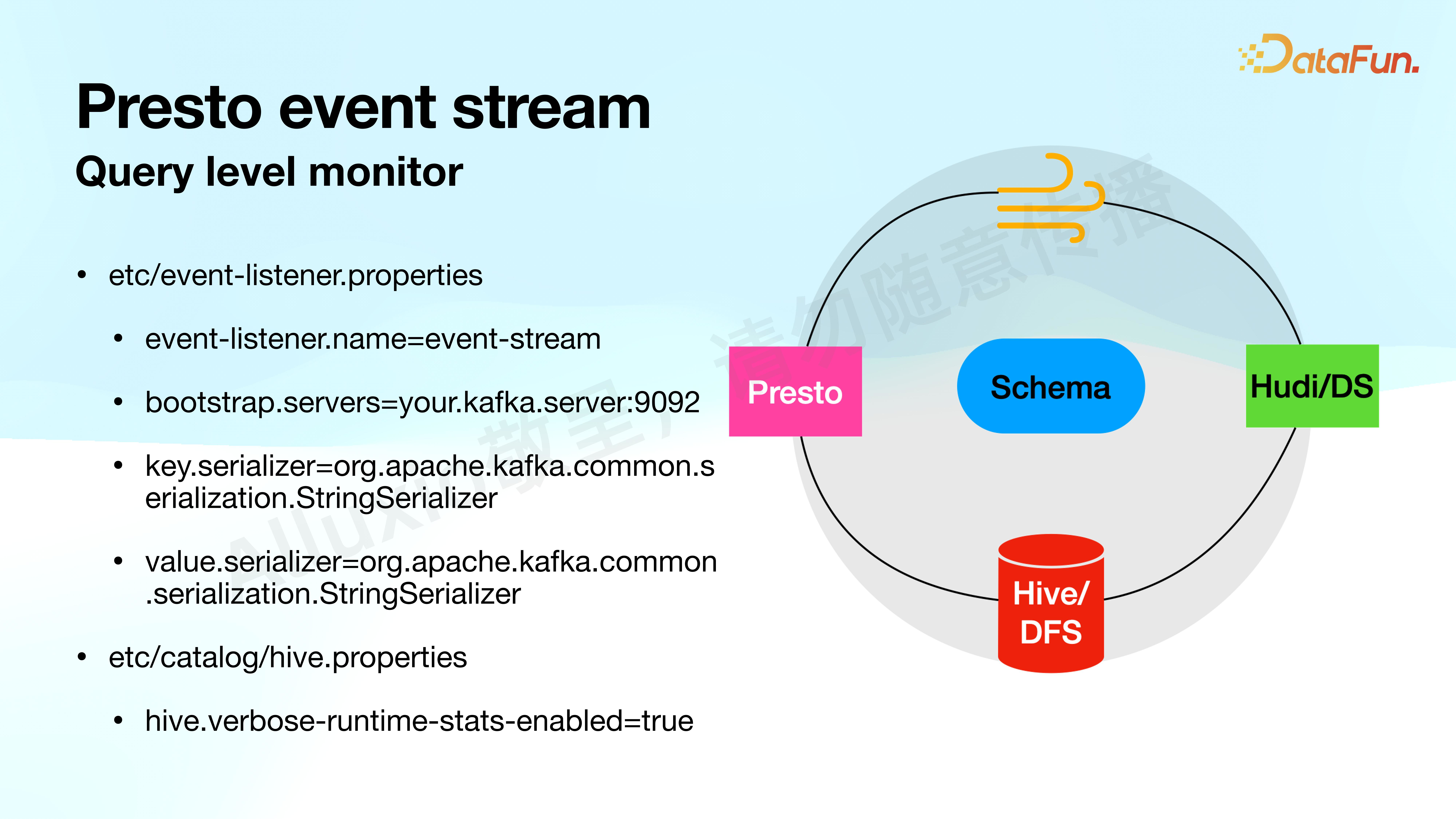
Alluxio 原有的 monitor 数据是比较粗的,只有 cluster 级别的最基本的信息。我们引入了块 level 的 monitor,利用了 Presto event stream 组件。它借鉴了 Trino event stream 的基本想法,Presto 产生的 query event 都会发到 Kafka 里,通过 Hudi 把所有数据重新引入到数据平台,再通过 Presto 查询,中间通过简单的 Schema 管理起来。
有了这个组件,在 Presto cluster上面就可以简单配置,加一个 event listener,指定名字到 Kafka 中简单配置即可。
需要强调的是,要把运行时的 detail 信息暴露出来,因为 Alluxio 的 cache 命中率、命中 cache size 等都会通过这个配置 enable。
2. Query/storage coverage and hit rate
有了 detail 的 query level 的 monitor 后,就可以拿到很多的 metrics。这里列出了一些常用的 metrics:

第一个是块级别的命中率,最开始时是 70~80%,后来加上简单的过滤条件,比如只 cache 最近几十天的数据、只 cache 文件大小大于某个 size,可以降到大约 20~30%。但整体的 storage 的 coverage 还是比较高的,在 70~80% 左右。
第二个是每个 query 涉及到的 storage 有多少命中率。
第三个是 storage 中多少是从 Alluxio cache中读取,多少是从 underline remote 中读取。
3. Metrics

在 2 clusters、1600 核,针对 P95,整体从 9 秒减少到了 8 秒。每月 scan 的 storage 约 6PB,其中大约有 3PB 从 Alluxio 读取,后续有可能会更高。
05 ALC4PS4 Next

性能提升其实并不是特别明显,但我们目的是提升性能的同时减少 cost,在过程中我们也发现了很多问题,比如 SQL 命中率大约只有 30%,系统中还有很多小文件,甚至很多文件不是列存。因此要进一步提升性能,还需要做一些传统的 data governance,如列存、压缩、处理小文件等等。Local cache filter 还需要 fine tuning,比如,现在storage 比较小,每个 worker 上只配置大约500GB。Cache filter 也要继续调优。后续也考虑将用在 Presto 的这种机制扩展到 Flink、Spark、Hudi、Iceberg 等。

